







CUDA学习入门(三)
前言
本篇接着上一篇,本仍然是对CUDA入门作一个宏观的概述,并不涉及具体编程细节,是关于CUDA基础信息的科普性文章,适用于想简单了解什么是CUDA,以及对CUDA工作流程感兴趣的小伙伴。
五、CUDA的线程索引
由前篇可知,我们的GPU计算解决的是并行数据问题,那我们有一堆数据后,如何确定他所在的线程是哪一个呢?
举个例子,如下图所示,我们共有32个数据(位于32个方格内)需要处理,如何确定红色方框数据所在线程的位置呢?

要在GPU中计算上面的32个数据,我们首先需要的就是调用Kernel函数,将上面的数据分好块和线程数。
在调用内核函数的时候,会在 <<< >>> 内设置两个参数,分别代表线程网格的维度和线程块的维度。
这里我们需要回忆一下在上一篇中我们提到的几个概念:
-
threadldx.[x y z]
是执行当前kernel函数的线程在block中的索引值 -
blockldx.[x y z]
是指执行当前kernel函数的线程所在block, 在grid中的索引值 -
blockDim.[x y z]
表示一个block中包含多少个线程 -
gridDim.[x y z]
表示一个grid中包含多少个block
有了以上几个概念,我们就需要确定我们该怎么给32个数据分配线程块了。其实32个数据刚好是一个Warp(线程束),但是咱们数据量很少,就简单分成四个线程块,每个块八个线程: <<< 4 , 8 >>>。
然后我们可以引入一个 index 索引值,用来标记线程索引。
结合上面几个概念,当我们把32个数据分成四个线程块,每个块八个线程时,这时候我们红框数据的线程位置就如下图所示了:
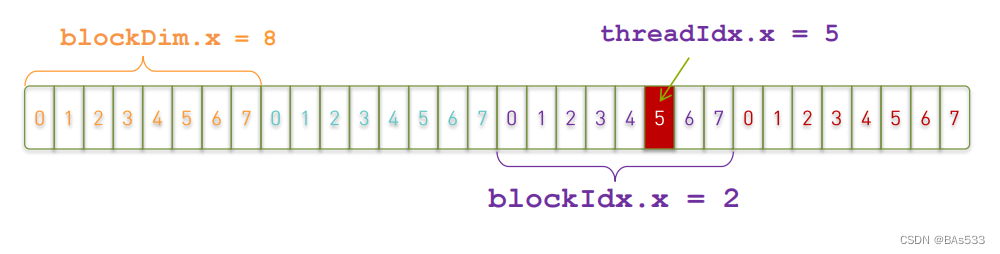
因为每一个线程块共有八个线程,所以 blockDim.x =8;
由于红框数据位于第二个线程中(线程从0开始计数),所以 blockIdx.x = 2;
又由于红框数据在第二个线程中位于五号位置(同样也是从0开始计数),所以 threadIdx.x = 5;
因此我们所求的红框数据应位于21号位置,计算图如下:

由此便可以确实当前线程所执行数据的位置。
六、如何设置Gridsize & Blocksize
相信很多初学者跟我一样,都会有这样的困惑,在调用内核函数的时候,需要在 <<< >>> 内设置网格的维度和块的维度,可是这个维度该怎么设置呢?
其实这个问题并没有一个统一的模版可以参考,只是其中有个点我们可以注意一下:
Blocksize的值应该是32的倍数
我们在上一篇中提到,CUDA线程层次根据硬件结构被分为三层,分别是 网格(grid)、块(block)、线程(thread) ,但是通常情况下一个线程块里包含的线程数会相当多,会引入线程束(Warp) 用来管理块内的线程,每个线程束会包含32个线程。
包含关系如下图所示:
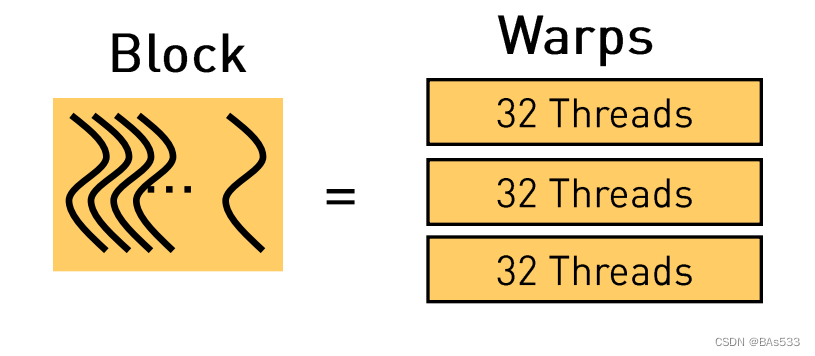
Warp的来源是因为,一个CUDA core可以执行一个 thread,一个SM的CUDA core会分成几个warp(即CUDA core在SM中分组),由warp scheduler负责调度。GPU 规定 Warp 中所有线程在同一周期执行相同的指令,而一个SM同时并发的warp是有限的,因为资源限制,SM要为每个线程块分配共享内存,也要为每个线程束中的线程分配独立的寄存器,所以SM的配置会影响其所支持的线程块和warp并发数量。因此如果warp发散,则会导致性能下降。
可以举两个例子对比一下。
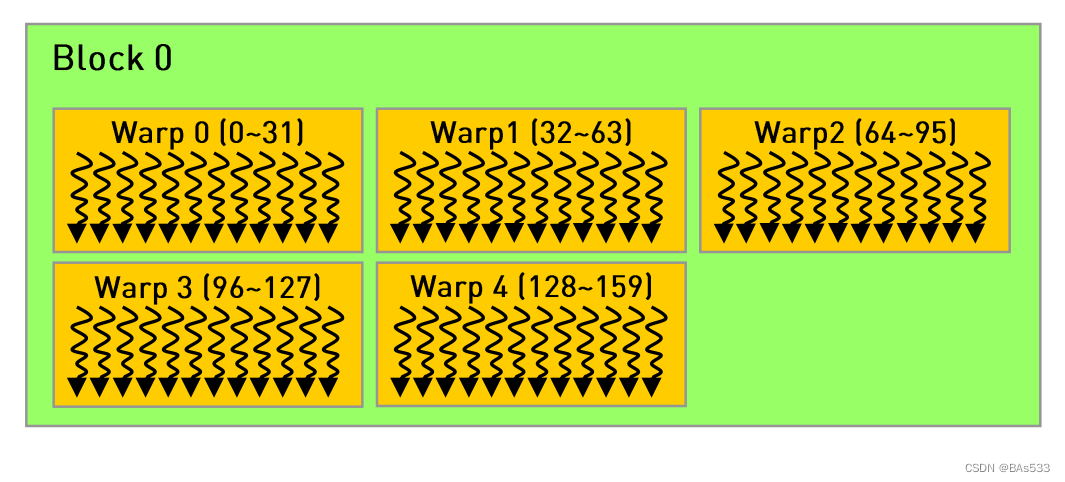
有两个线程块,维度分别是160和161,也就是 blockDim =160 和 blockDim =161 。
当 blockDim =160 时,GPU会自动给线程块分配 5 个Warp,如下图所示:
当 blockDim =161 时,GPU会自动给线程块分配 5 个Warp,但是此时将会多出一个线程,GPU将会再申请一个Warp给这多余的一个线程。如下图所示:
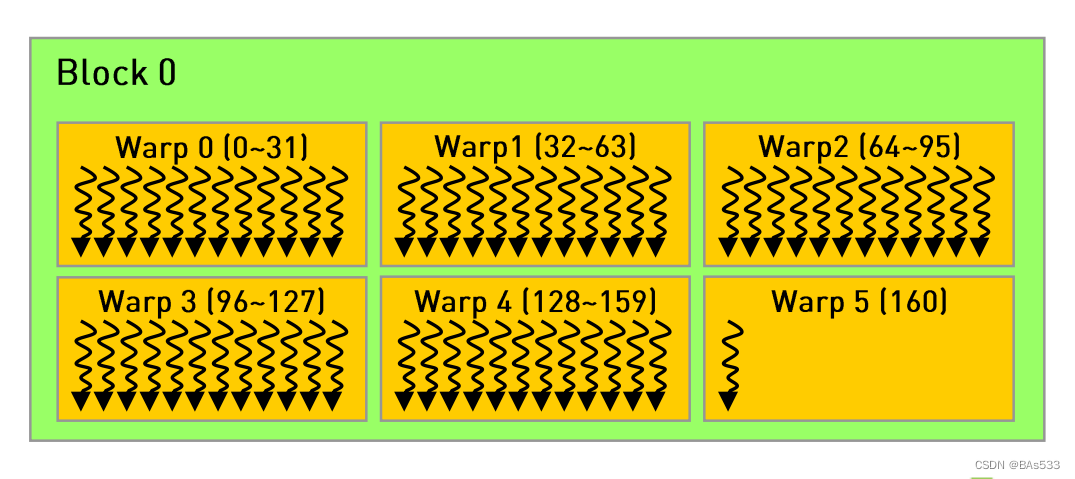
可以看到,当线程块的维度为32的倍数时,可以刚好划分完整的Wrap,实现资源利用最大化。
故Blocksize的值是32的倍数更好。
确定了Blocksize之后,假如我们有N个线程需要计算,那么 Gridsize = ( N + Blocksize -1) / Blocksize 即可,保证线程足够充裕。
Blocksize的值是32的倍数更好,但是不同的GPU中每个Block所包含的线程数可能会存在不同,如何查询GPU卡每个block支持的最大thread(线程)数可以参考下方大佬提供的方法。
本人是一名学生,也是正在学习Jetson的过程中,如有错误请批评指正!
部分图表信来源:https://mp.weixin.qq.com/s/em309Ho6AaV5f1ogWpajJw

















 775
775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









