






参考链接:CUDA C++ Programming Guide
Thread层次
threadIdx是一个三维的向量,从而使得线程能够通过1、2、3维线程下标进行索引,所有线程构成一个线程块,这提供了一种较为自然的方式来调用域中的元素进行计算,包括矢量、矩阵及体积的计算。
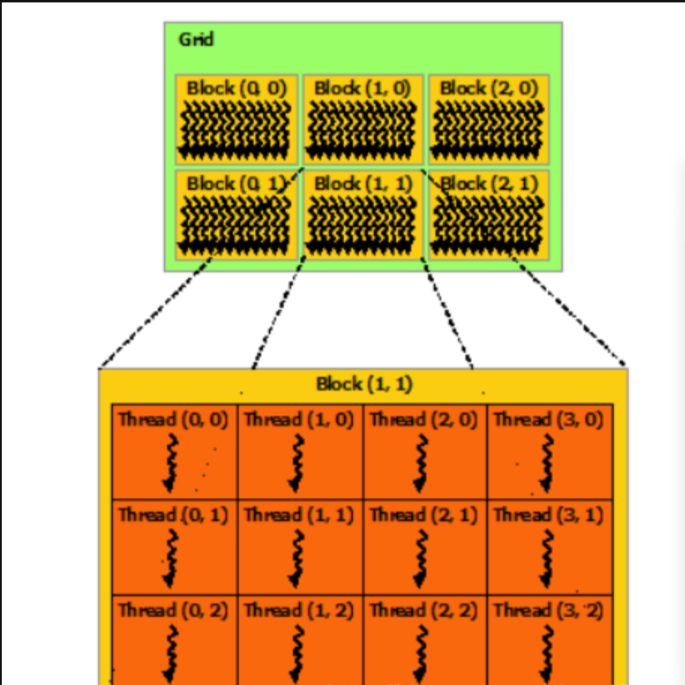
对于一维的线程块,线程的索引为线程的下标;
对于二维的线程块(Dx, Dy),线程(x, y)的索引为:x + y*Dx;
对于三维的线程块(Dx, Dy, Dz),线程(x, y, z)的索引为:x + y*Dx + z* Dx * Dy;
例如,N x N大小的矩阵A和B对应元素相加可以表示为:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = threadIdx.x;
int j = threadIdx.y;
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation with one block of N * N * 1 threads
int numBlocks = 1;
dim3 threadsPerBlock(N, N);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}
解释:这里网格(grid)的大小为1×1×1,只包含一个线程块(block),因此对块内的线程进行索引为直接索引。
每个线程块是有线程个数的限制的,因为线程块的所有线程都需要在同一个SM(Streaming Multiprocessor)核上,共用SM核的内存,目前一个线程块最大的容纳线程数为1024个。
线程块
线程块也是三维的,大小通常由待处理数据的大小决定。

线程块的索引是通过blockIdx变量,其维度可以通过blockDim获得,对上述例子进行拓展,其可以扩写为:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
int j = blockIdx.y * blockDim.y + threadIdx.y;
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}按以上方法设置:
gridDim.x = N / threadPerBlocks.x, gridDim.y = N / threadPerBlocks.y, gridDim.z = 1, 一共有gridDim.x * gridDim.y * gridDim.z个线程块;
blockDim.x = 16, blockDim.y = 16, blockDim.z = 1, 一个线程块包含16 × 16 x 1 = 256个线程;
blockIdx.x 索引在0到N / threadPerBlocks.x,blockIdx.y索引在0到N / threadPerBlocks.y,blockIdx.z索引为0;
threadIdx.x索引在0-16,threadIdx.y索引在0-16,threadIdx.z索引为0。
解释:i,j分别为行列的索引,blockIdx.x * blockDim.x + threadIdx.x表示x方向上的位置索引,blockIdx.y * blockDim.y + threadIdx.y表示y方向上的位置索引。blockDim的值是确定的,即单个线程块的线程数量,blockIdx是变化的,从0到网格的维度大小,threadIdx是变化的,表示从0到线程块对应方向的维度大小。
每个线程块应该独立的执行相关计算,这样可以使得线程块能够根据任意数量的处理核完成计算分配,如下图所示:
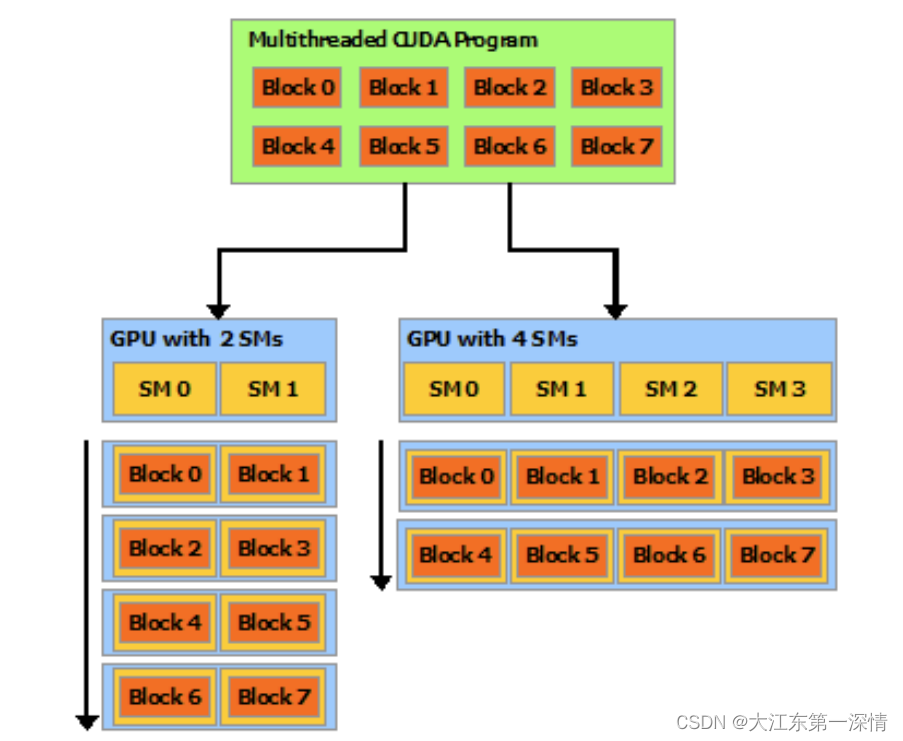
8个线程块可以根据SM核的大小进行分配。
在一个线程块里的线程能够通过shared memory分享数据并通过同步代码执行来协调内存的访问,__syncthreads()函数能够作为一个同步所有线程的命令,使线程块中的所有线程在完成当前运算后才开始下一次运算。
参考书:多核与GPU编程:工具、方法及实践

















 162
162

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









