







Scrapy框架知识手册 - 从零到一
一、初识Scrapy
1、Scrapy简介
Scrapy是一个使用Python开发的(基于Twisted框架)开源网络爬虫框架,目前由Scrapinghub Ltd维护。
Scrapy简单易用、灵活易拓展,任何人都可以根据需求方便的修改。它的开发社区活跃,并且是跨平台的,在Linux、 MaxOS以及Windows平台都可以使用。
Scrapy用途广泛,可以用于数据挖掘、监测和自动化。
2、网络爬虫原理
网络爬虫是指:在互联网上自动爬取网站内容信息的程序,也被称作网络蜘蛛或网络机器人。
大型的爬虫程序被广泛应用于搜索引擎、数据挖掘等领域,个人用户或企业也可以利用爬虫收集对自身有价值的数据。
3、网络爬虫的基本流程
任何爬虫程序都遵循这三个基本流程:请求数据、解析数据和保存数据。
请求数据
请求的数据除了普通HTML页面之外,还有JSON数据、字符串数据、图片、视频、音频等等。
解析数据
当整个数据被请求后得到,对数据内容进行分析,并筛选出需要的内容。
保存数据
将数据以某种格式保存起来,如:写入文件中(csv、json)等,或保存到数据库(MySQL、MongoDB)等等。
二、Scrapy安装与创建
1、安装
直接pip安装
pip install scrapy
查看版本
# cmd或shell下
C:\Users\Administrator>python
>>>import scrapy
>>>scrapy.__version__
# 或者 scrapy.version_info
# 显示安装的版本号
(2.1.0)
2、查看命令
直接运行scrapy,查看提示指令
C:\Users\Administrator>scrapy
Scrapy 2.1.0 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
# 运行快速基准测试。(检测电脑性能)
bench Run quick benchmark test
# 通过Scrapy下载器获取一个URL。(将源代码下载下来,并显示出来)
fetch Fetch a URL using the Scrapy downloader
# 使用预定义模板生成一个爬虫程序。(创建一个新的spider文件)
genspider Generate new spider using pre-defined templates
# 运行一个独立的爬虫程序(不创建一个项目)。(直接scrapy runspider <爬虫文件名>,与crawl启动爬虫不同)
runspider Run a self-contained spider (without creating a project)
# 获得配置信息
settings Get settings values
# 交互式抓取控制台。(进入scrapy的交互模式)
shell Interactive scraping console
# 创建爬虫项目
startproject Create new project
# 打印Scrapy框架版本
version Print Scrapy version
# 将URL在浏览器中打开,就像在Scrapy中看见的那样
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
# 使用scrapy <指令> -h 可以看见更多关于指令的信息
Use "scrapy <command> -h" to see more info about a command
3、主要命令
- 创建项目:
scrapy startproject <项目名> - 创建爬虫:
scrapy genspider <爬虫名> <域名> - 运行爬虫:
scrapy crawl <爬虫名>
三、Scrapy简单实现
英文名言警句网站 http://quotes.toscrape.com
1、项目创建
>scrapy startproject quotes
New Scrapy project 'quotes', using template directory 'd:\pycharm\webcrawler\venv\lib\site-packages\scrapy\templates\project', created in:
D:\XXXXXX\quotes
You can start your first spider with:
cd quotes
scrapy genspider example example.com
2、创建爬虫
切换到项目中,即按照提示,切换到quotes文件夹中去
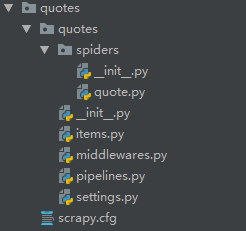
>scrapy genspider quote toscrape.com
Created spider 'quote' using template 'basic' in module:
quotes.spiders.quote
结果展示:
3、更改robot协议
将setting中的,是否遵循robot选项,True改变为False

4、分析页面
使用Chrome浏览器的开发者工具,分析页面
每一个内容都存在于标签<div class=“quote”>…</div>中
内容:

查看翻页:

完整的URL:

5、编写spider
查看quotes.py文件
更改start_urls为’http://quotes.toscrape.com/’

Spider 是用户编写用于从单个网站(或者一些网站)爬取数据的类。
为了创建一个Spider,必须继承spider.Spider类,并且定义以下三个属性:
- name。在genspider时创建的,用于区别Spider。该名字必须是唯一的,不可以为不同Spider设定相同的名字。
- allowed_domains。是爬虫能抓取的域名,爬虫只能在这个域名下抓去网页。可以不设置。
- start_urls。可迭代类型,列表也可以是列表推导式。包含了Spider在启动时进行爬取的url列表。因此,第一个页面必须设置进来,而后续的URL则从初始的URL获取到的数据中提取。
- parse()。回调函数。是Spider的一个方法,被调用时,该方法中的response,是每个start_urls完成下载后生成的Response对象将会作为唯一的参数传递给该函数。也可以通过其他函数来接收。
页面解析主要完成下面两个任务:- 直接提取页面中的数据(re、XPath、CSS选择器),生成item。
- 生成需要进一步处理的URL的Request对象,即提取页面中的链接,并产生对链接页面的下载请求。
页面解析函数通常为一个生成器函数,每一项从页面中提取的数据以及每一个对链接页面的下载请求都由yield语句交给Scrapy引擎。
6、解析页面
分析页面获取:名言,作者,标签,这三个属性。
quote.py
# -*- coding: utf-8 -*-
import scrapy
import urllib.parse
from ..items import QuotesItem
class QuoteSpider(scrapy.Spider):
# 爬虫项目的名字,启动爬虫时需指定
name = 'quote'
# 运行爬虫爬取指定域名下的数据,范围是一个列表
allowed_domains = ['toscrape.com']
# 起始网址,爬虫从哪个网站开始爬取
start_urls = ['http://quotes.toscrape.com/']
# 起始网址请求的数据,默认返回给parse函数进行处理
def parse(self, response):
# response = requests.response + parsel.Seletcor
# 会有response的所有方法,会有Selector的所有方法
quotes = response.css('.quote')
for quote in quotes:
item = QuotesItem()
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags a.tag::text').extract()
yield item
# 如果解析数据的方法,返回的是字典或者item,scrapy框架会自动进行处理
# scrapy里使用yield,协程
# 获取下一页
next_page = response.css('li.next>a::attr(href)').get()
base_url = 'http://quotes.toscrape.com'
if next_page:
next_url = urllib.parse.urljoin(base_url, next_page)
# 构建一个request请求,让下载中间件进行下载,最终会返回一个响应体
# 传入一个回调函数,让其进行处理
yield scrapy.Request(next_url, callback=self.parse)
items.py
# -*- coding: utf-8 -*-
import scrapy
class QuotesItem(scrapy.Item):
# define the fields for your item here like:
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
piplelines.py 数据保存
class QuotesPipeline(object):
def process_item(self, item, spider):
with open('data_save.csv', 'a', encoding='utf-8')as f:
f.write(item['text']+','+item['author']+','+','.join(item['tags']))
f.write('\n')
return item
取消settings文件中的注释

注意:
- response.css()可以直接提取响应内容
- start_urls可以直接写多个网址,以列表格式分隔开。
- extract_first()是提取内容,提取的是第一个内容,不是列表,而是字符串。extract()是提取多个内容,以列表形式保存的多个字符串内容。不使用这两个方法,则得到的是对象。
7、运行爬虫
在quote项目名目录下运行爬虫
直接即可:
scrapy crawl quote
不取消注释settings.py中关于ITEM_PIPELINES字典数据时,也可以通过指令,保存为csv文件(该保存仅供测试,或者简单保存):
scrapy crawl quote -o quotes.csv
-o支持多种格式保存,添加上后缀即可。
爬虫的运行过程:
Scrapy为Spider的start_urls属性中的每一个URL创建了scrapy.Request对象,并将parse方法作为回调函数(callback)赋值给了Request。
Request对象经过调度,执行生成scrapy.http.Response对象并送回给Spider的parse()方法处理。
四、Scrapy框架结构
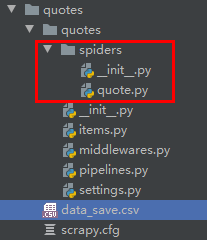
1、Scrapy结构
项目结构:(一步步展开)

quotes/: 总项目quotes/quotes/: 该项目的python模块。内部添加及更改代码。quotes/scrapy.cfg: 项目的配置文件

quotes/quotes/spiders/: 放置spider代码的目录.quotes/quotes/items.py: 项目中的item文件.quotes/quotes/middlewares.py: 爬虫中间件、下载中间件(处理请求体与响应体)quotes/quotes/pipelines.py: 项目中的pipelines文件.quotes/quotes/settings.py: 项目的设置文件.

quotes/quotes/spiders/quote.py: quote爬虫程序
2、Scrapy原理(数据流动)

| 序号 | 组件 | 作用 |
|---|---|---|
| 1 | Scrapy Engine(引擎) | 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。 |
| 2 | Spider(爬虫) | 负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。 |
| 3 | Spider Middlewares(Spider中间件) | 可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests) |
| 4 | Scheduler(调度器) | 负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。 |
| 5 | Downloader Middlewares(下载中间件) | 可以当作是一个可以自定义扩展下载功能的组件。 |
| 6 | Downloader(下载器) | 负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。 |
| 7 | Item Pipeline(管道) | 负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。 |
3、Scrapy各个组件的介绍

- Engine。引擎,处理整个系统的数据流处理、触发事务,是整个框架的核心。
- Items。项目数据,它定义了爬取结果的数据结构,爬取的数据会被赋值成该Item对象。
- Scheduler。调度器,接受引擎发过来的请求并将其加入队列中,在引擎再次请求的时候将请求提供给引擎。
- Downloader。下载器,下载网页内容,并将网页内容返回给蜘蛛。
- Spiders。 蜘蛛,其内定义了爬取的逻辑和网页的解析规则,它主要负责解析响应并生成器结果和新的请求。
- Item Pipeline。项目管道,负责处理由蜘蛛从网页中抽取的项目,它的主要任务是清洗、验证和存储数据。
- Downloader Middlewares。下载器中间件,位于引擎和下载器之间的钩子框架,主要处理引擎与下载器之间的请求及响应。
- Spider Middlewares。 蜘蛛中间件,位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的响应和输出的结果及新的请求。
五、Scrapy的基本使用
1、spiders文件之spider.Spider(SPIDERS-爬虫文件)
Spider 类定义了如何爬取某个(或某些)网站。包括了爬取的动作(例如:是否跟进链接)以及如何从网页的内容中提取结构化数据(爬取item)。 换句话说,Spider就是定义爬取的动作及分析某个网页(或者是有些网页)的地方。

对spider来说,爬取的循环类似下文:
-
以初始的URL初始化Request,并设置回调函数。 当该request下载完毕并返回时,将生成response,并作为参数传给该回调函数。
spider中初始的request是通过调用 start_requests()来获取的。 start_requests() 读取 start_urls 中的URL, 并以 parse 为回调函数生成 Request。
-
在回调函数内分析返回的(网页)内容,返回 Item 对象或者 Request 或者一个包括二者的可迭代容器。见下1、2。 返回的Request对象之后会经过Scrapy处理,下载相应的内容,并调用设置的callback函数(函数可相同)。

-
在回调函数内,可以使用 选择器(Selectors) (可以使用BeautifulSoup, lxml 或者想用的任何解析器) 来分析网页内容,并根据分析的数据生成item。
-
最后,由spider返回的item将被存到数据库(由某些 Item Pipeline处理)或使用 Feed exports存入到文件中。
虽然该循环对任何类型的spider都(多少)适用,但Scrapy仍然为了不同的需求提供了多种默认spider。 之后将讨论这些spider。
1.1、Spider
scrapy.spider.Spider 是最简单的spider。每个其他的spider必须继承自该类(包括Scrapy自带的其他spider以及自己编写的spider)。 其仅仅请求给定的 start_urls / start_requests ,并根据返回的结果(resulting responses)调用 spider 的 parse 方法。
1.1.1、name
定义 spider 名字的字符串(string)。spider 的名字定义了 Scrapy 如何定位(并初始化) spider ,所以其必须是唯一的。 不过您可以生成多个相同的 spider 实例(instance),这没有任何限制。 name 是 spider 最重要的属性,而且是必须的。
如果该 spider 爬取单个网站(single domain),一个常见的做法是以该网站(domain)(加或不加后缀 )来命名 spider 。 例如,如果 spider 爬取 mywebsite.com ,该spider通常会被命名为 mywebsite 。
1.1.2、allowed_domains
可选。包含了spider允许爬取的域名(domain)列表(list)。 当 OffsiteMiddleware 启用时, 域名不在列表中的URL不会被跟进。
1.1.3、start_urls
URL 列表。当没有制定特定的 URL 时,spider 将从该列表中开始进行爬取。 因此,第一个被获取到的页面的 URL 将是该列表之一。 后续的 URL 将会从获取到的数据中提取。
1.1.4、start_requests()
该方法必须返回一个可迭代对象(iterable)。该对象包含了spider用于爬取的第一个 Request。
当 spider 启动爬取并且未制定 URL 时,该方法被调用。 当指定了URL时,make_requests_from_url() 将被调用来创建 Request 对象。 该方法仅仅会被 Scrapy 调用一次,因此您可以将其实现为生成器。
该方法的默认实现是使用 start_urls 的url生成 Request。
如果您想要修改最初爬取某个网站的Request对象,您可以重写(override)该方法。 例如,如果您需要在启动时以 POST 登录某个网站,你可以这么写:
def start_requests(self):
return [scrapy.FormRequest("http://www.example.com/login",
formdata={'user': 'john', 'pass': 'secret'},
callback=self.logged_in)]
def logged_in(self, response):
## here you would extract links to follow and return Requests for
## each of them, with another callback
pass
1.1.5、parse
当response没有指定回调函数时,该方法是Scrapy处理下载的response的默认方法。
parse 负责处理response并返回处理的数据以及(/或)跟进的URL。 Spider 对其他的Request的回调函数也有相同的要求。
该方法及其他的Request回调函数必须返回一个包含 Request 及(或) Item 的可迭代的对象。
参数: response– 用于分析的response
1.1.6、closed(reason)
当spider关闭时,该函数被调用。
1.2、启动方式
1.2.1、start_urls
start_urls 是一个列表,同上。
1.2.2、start_requests
使用start_requests() 重写start_urls,要使用Request()方法自己发送请求:
def start_requests(self):
"""重写 start_urls 规则"""
yield scrapy.Request(url='http://quotes.toscrape.com/page/1/', callback=self.parse)
1.2.3、scrapy.Request
scrapy.Request 是一个请求对象,创建时必须制定回调函数。
1.2.4、数据保存
注意:这种保存方式,仅供测试。
可以使用 -o 将数据保存为常见的格式(根据后缀名保存)
支持的格式有下面几种:
- json
- jsonlines
- jl
- csv
- xml
- marshal
- pickle
使用方式:
scrapy crawl quotes -o datas.json
1.2.5、URL拼接
使用urllib包中的parse库中的urljoin方法
import urllib.parse
urllib.parse.urljoin('http://quotes.toscrape.com/', '/page/2/')
Out[6]: 'http://quotes.toscrape.com/page/2/'
urllib.parse.urljoin('http://quotes.toscrape.com/page/2/', '/page/3/')
Out[7]: 'http://quotes.toscrape.com/page/3/'
2、Scrapy框架案例
1、豆瓣250
网站链接:豆瓣电影 Top 250
1.1、创建项目
>scrapy startproject douban
You can start your first spider with:
cd douban
scrapy genspider example example.com
>cd douban
>scrapy genspider db_spider douban.com
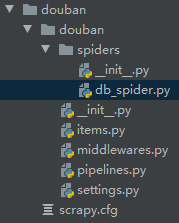
修改起始URL:
改为网站链接

settings.py文件中,修改robot协议:

1.2、分析网页
(1) 数据:
ol标签下的所有li标签

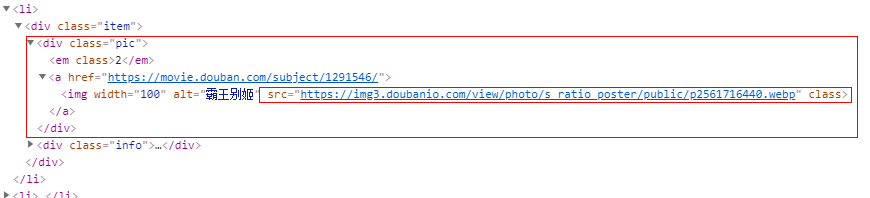
获取:pic–图片 title–标题 director–导演 star–评分 quote–格言
图片:
标题:

导演:

评分:

格言:

(2) 翻页:

1.3、构建Scrapy
(1) items.py
import scrapy
class DoubanItem(scrapy.Item):
# define the fields for your item here like:
pic = scrapy.Field()
title = scrapy.Field()
director = scrapy.Field()
star = scrapy.Field()
quote = scrapy.Field()
(2) db_spider.py
# -*- coding: utf-8 -*-
import scrapy
import urllib.parse
from ..items import DoubanItem
class DbSpiderSpider(scrapy.Spider):
name = 'db_spider'
allowed_domains = ['douban.com']
start_urls = ['https://movie.douban.com/top250']
def parse(self, response):
lis = response.css('ol.grid_view li')
for li in lis:
item = DoubanItem()
item['pic'] = li.css('div.pic img::attr(src)').extract_first()
item['title'] = li.css('div.info span.title::text').extract()
item['director'] = li.css('div.info div.bd>p::text').extract()
item['star'] = li.css('div.star span.rating_num::text').extract_first()
item['quote'] = li.css('p.quote span.inq::text').extract_first()
yield item
next_page = response.css('span.next a::attr(href)').extract_first()
next_url = urllib.parse.urljoin(response.url, next_page)
if next_page:
yield scrapy.Request(next_url, callback=self.parse)
(3) pipelines.py
class DoubanPipeline(object):
def process_item(self, item, spider):
direcctor_c = (','.join(item['director'])).strip().replace('\n', '').replace(' ', '').replace(',,' ,'')
with open('douban250.csv', 'a', encoding='utf8') as f:
f.write(item['pic']+','+','.join(item['title'])+','+direcctor_c + ',' +
item['star']+','+item['quote'])
f.write('\n')
return item
(4) settings.py
修改请求头:

取消注释ITEM_PIPELINES:
1.4、运行Scrapy
scrapy crawl db_spider
结果:

2、猫眼100
网站链接:猫眼Top 100 榜
1.1、创建项目
>scrapy startproject maoyan
You can start your first spider with:
cd maoyan
scrapy genspider example example.com
>cd maoyan
>scrapy genspider my_spider maoyan.com
修改起始URL:
改为网站链接

settings.py文件中,修改robot协议:

1.2、分析网页
(1) 数据:
dl标签下的所有dd标签

获取:title - 标题、img - 图像、star - 明星、time - 放映时间、score - 评分
title - 标题 和 img - 图像

star - 明星

time - 放映时间

score - 评分

翻页:

1.3、构建Scrapy
(1) items.py
import scrapy
class MaoyanItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
img = scrapy.Field()
star = scrapy.Field()
time = scrapy.Field()
score = scrapy.Field()
(2) my_spider.py
# -*- coding: utf-8 -*-
import scrapy
import urllib.parse
import re
from ..items import MaoyanItem
class MySpiderSpider(scrapy.Spider):
name = 'my_spider'
allowed_domains = ['maoyan.com']
start_urls = ['https://maoyan.com/board/4?offset=0']
def parse(self, response):
dds = response.css('dl.board-wrapper dd')
# print(response.text)
for dd in dds:
item = MaoyanItem()
item['title'] = dd.css('img.board-img::attr(alt)').get()
# 注意这里为data-src而不是网页中的src
item['img'] = dd.css('img.board-img::attr(data-src)').get()
item['star'] = dd.css('p.star::text').get()
item['time'] = dd.css('p.releasetime::text').get()
item['score'] = dd.css('p.score i::text').getall()
yield item
# print(response.url)
# https://maoyan.com/board/4?offset=0
base_url = response.url.split('?')[0]
next_page = response.css('ul.list-pager li:nth-last-child(1) a::attr(href)').get()
next_url = urllib.parse.urljoin(base_url, next_page)
if next_page:
yield scrapy.Request(next_url, callback=self.parse)
注意:
网站上的HTML和IDE中的HTML有属性名的不同,以IDE中的属性名为标准
比如:图片链接属性名,在网站中为src而IDE中为data-src。

(3) pipelines.py
class MaoyanPipeline(object):
def process_item(self, item, spider):
star = item['star'].strip().replace('\n', '').replace(' ', '')
with open('maoyan100.csv', 'a', encoding='utf-8')as f:
f.write(item['title']+','+item['img']+','+star+','+item['time']+',' + ''.join(item['score']))
# f.write(item['img'])
f.write('\n')
return item
(2) settings.py
取消注释ITEM_PIPELINES

设置请求头:


1.4、运行Scrapy
scrapy crawl db_spider
结果:

五、Scrapy的进阶使用
1、scrapy.Request - 返回请求
Request对象用来描述一个HTTP请求,下面是其构造器方法的参数列表:
Request(url, callback=None, method='GET', headers=None, body=None,
cookies=None, meta=None, encoding='utf-8', priority=0,
dont_filter=False, errback=None, flags=None, cb_kwargs=None)
- url(字符串)–此请求的URL
- callback(callable)–将以请求的响应(一旦下载)作为第一个参数调用的函数。有关更多信息,请参见下面的将其他数据传递给回调函数。如果“请求”未指定回调,parse() 则将使用“Spider” 方法。请注意,如果在处理过程中引发异常,则会调用errback。
- method(字符串)–此请求的HTTP方法。默认为
'GET'。 - meta(dict)– Request.meta属性的初始值。如果给出,则在此参数中传递的字典将被浅表复制。
- headers(dict)–请求头。dict值可以是字符串(对于单值标头)或列表(对于多值标头)。如果
None作为值传递,则将根本不发送HTTP标头。
以前面的格言网站为例子:
import scrapy
from urllib import parse
class QuotesSpider(scrapy.Spider):
name = 'quotes3'
allowed_domains = ['toscrape.com']
start_urls = ['http://quotes.toscrape.com/page/1/']
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
auth = quote.css('.author::text').extract_first()
tages = quote.css('.tags a::text').extract()
yield dict(text=text, auth=auth, tages=tages)
next_url = response.css('.next a::attr(href)').extract_first()
next_url = parse.urljoin(response.request.url, next_url)
print(next_url)
yield scrapy.Request(url=next_url, callback=self.parse)
1.1 meta的使用
meta 参数主要用于在两个函数之间传递参数
meta 一次性的,每次创建 request 对象,都会重新创建
meta是一个字典,它的主要作用是用来传递数据的,meta = {‘key1’:value1},如果想在下一个函数中取出 value1, 只需得到上一个函数的 meta[‘key1’] 即可, 因为meta是随着Request产生时传递的,下一个函数得到的Response对象中就会有meta,即 response.meta。
如后面项目会涉及的例子:
第一个parse函数将自己的item传递给parse1函数进行后续的处理操作
class Win4000Spider(scrapy.Spider):
name = 'win4000'
allowed_domains = ['win4000.com'] # 大规模采集
start_urls = ['http://www.win4000.com/mobile_detail_169064.html']
def parse(self, response):
item = Win4000Item()
item['title'] = response.css('h1::text').get()
item['img_urls'] = response.css('.pic-large::attr(src)').getall()
print('item', item)
# 这个 item 先不返回 只有一个下载地址
# yield item
next_page = response.css('.pic-next-img a::attr(href)').get()
if next_page:
yield scrapy.Request(next_page, callback=self.parse1, meta={'item': item})
def parse1(self, response):
# 第二页的数据
item = response.meta.get('item')
1.2 scrapy 发送 post 请求
通过start_requests函数中的scrapy.http.JSONRequest()构建post请求
import scrapy
class LgSpiderSpider(scrapy.Spider):
name = 'lg_spider'
allowed_domains = ['lagou.com']
# 请求默认是get,列表对象
# start_urls = ['http://lagou.com/']
# post请求,函数对象
def start_requests(self):
yield scrapy.http.JSONRequest('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
data={
'first': 'true',
'pn': '1',
'kd': 'python',
},
callback=self.parse)
def parse(self, response):
print(response.text)
print(response.request.headers)
pass
说明: 该例子为中间件章节的Scrapy框架拉勾网案例
2、items.py(项目数据)
Item是保存爬取数据的容器,它的使用方法和字典类似。不过,相比字典,Item提供了额外的保护机制,可以避免拼写错误或者定义字段错误。
创建Item需要继承scrapy.Item类,并且定义类型为scrapy.Field的字段。在创建项目开始的时候Item文件是这样的。
import scrapy
class ExampleItem(scrapy.Item):
# define the fields for your item here like:
# 参照下面这个参数定义你的字段
# name = scrapy.Field()
pass
1.1 解析字段的问题
在前面的小例子中,可以写成如下形式
import scrapy
...
def parse(self, response):
quotes = response.css('.quote')
for quote in quotes:
text = quote.css('.text::text').extract_first()
auth = quote.css('.author::text').extract_first()
tages = quote.css('.tags a::text').extract()
yield dict(text=text, auth=auth, tages=tages)
使用Python字典可以很方便的存储格言的信息(text、auth、tags),但字典可能有以下缺点:
- 无法一目了然地了解数据中包含哪些字段,影响代码可读性。我们直接打开items.py文件即可知道,该爬虫爬取什么字段内容。
- 缺乏对字段名字的检测,容易因程序员的笔误而出错。有了items.py文件中预定义的字段名称,后面使用时,如果用错名字会报错提醒。
- 不便于携带元数据(传递给其他组件的信息)。item类封装整个字段,便于函数或组件之间进行传递。
为解决上述问题,在Scrapy中可以使用自定义的Item类封装爬取到的数据。
1.2 Item和Field
Scrapy提供了两个类,用户可以使用它们自定义数据类,封装爬取到的数据。
用来描述自定义数据类包含哪些字段(如name、price等)。
自定义一个数据类,只需继承Item,并创建一系列Field对象的类属性即可。
items.py
# 特殊的字典结构 可以在scrapy中传递数据
class QuotesItem(scrapy.Item):
# Field 字段
# 就是类似于产生一个类似字典格式的数据 拥有字典的一些属性
# 字段默认为空
# 我们可以通过实例化 像着键赋值 但是如果没有写这个键 就不能赋值 但是字典可以
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
以定义书籍信息 quote 为例,它包含个字段,分别为书的名字text、author和tags,代码如下:
quotes.py - spider
from ..items import QuotesItem
import scrapy
......
def parse(self, response):
item = QuotesItem()
quotes = response.css('.quote')
for quote in quotes:
item['text'] = quote.css('.text::text').extract_first()
item['author'] = quote.css('.author::text').extract_first()
item['tags'] = quote.css('.tags a::text').extract()
yield item
Item支持字典dict接口,所以 QuotesItem 在使用上和Python字典类似。
对字段进行赋值时,QuotesItem 内部会对字段名进行检测,如果赋值一个没有定义的字段,就会抛出异常(防止因用户粗心而导致错误)
1.3 多个Item及其处理
items.py
class QuotesItem(scrapy.Item):
text = scrapy.Field()
author = scrapy.Field()
tags = scrapy.Field()
class Quotes1Item(scrapy.Item):
text1 = scrapy.Field()
autho1r = scrapy.Field()
tags1 = scrapy.Field()
class Quotes2Item(scrapy.Item):
text2 = scrapy.Field()
author2 = scrapy.Field()
tags2 = scrapy.Field()
pipelines.py
from ..items import QuotesItem
from ..items import Quotes1Item
from ..items import Quotes2Item
class CSVPipeline(object):
... ...
def process_item(self, item, spider):
# 使用isinstance然后通过if判断方式进行items类别筛选
# 写入json文件
if isinstance(item, QuotesItem):
pass
elif isinstance(item, Quotes1Item):
pass
elif isinstance(item, Quotes2Item):
pass
return item
class JSONPipeline(object):
... ...
3、pipelines.py(ITEMPIPELINES-管道文件)
当 spider 获取到数据(item)之后,就会将数据发送到 Item Pipeline,Item Pipeline 通过顺序执行的几个组件处理它。
在Scrapy中,Item Pipeline是处理数据的组件,一个Item Pipeline就是一个包含特定接口的类,通常只负责一种功能的数据处理,在一个项目中可以同时启用多个Item Pipeline,它们按指定次序级联起来,形成一条数据处理流水线。(数字越小,级别越高)
Item Pipeline 的典型用途是:
- 清理HTML数据
- 验证的数据(检查项目是否包含某些字段)
- 过滤掉重复的数据
- 将数据存储在数据库中
注意:不要去改动item。截取item,保存数据,返回item。
2.1 使用方法
Scrapy 提供了 pipeline 模块来执行保存数据的操作。在创建的 Scrapy 项目中自动创建了一个 pipeline.py 文件,同时创建了一个默认的 Pipeline 类:
class ExamplePipeline(object):
def process_item(self, item, spider):
return item
(1)普通简单使用:
import json
class JSONPipeline(object):
def process_item(self, item, spider):
with open('quotes.json', 'a', encoding='utf-8') as f:
f.write(json.dumps(dict(item), ensure_ascii=False))
f.write('\n')
return item
只是上面定义方法还不行,还要激活该组件,也就是激活管道文件才能保存数据。激活是在配置文件setteings.py文件中激活,在配置文件中找到如下变量值取消注释:
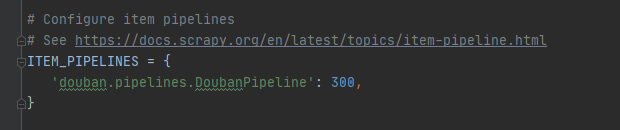
ITEM_PIPELINES = {
'quote.pipelines.JSONPipeline': 300,
}
在上图中的字典结构的配置中,键是管道文件所在的路径,值是该管道文件的激活顺序,数字越小代表越早激活 。因为有时候会有多个管道文件。
(2)标准使用:
import XXX
class XXXPipeline(object):
def __init__(self):
## 可选实现,做参数初始化等
## doing something
pass
def process_item(self, item, spider):
## item (Item 对象) – 被爬取的item
## spider (Spider 对象) – 爬取该item的spider
## 这个方法必须实现,每个item pipeline 组件都需要调用该方法,
## 这个方法必须返回一个 Item 对象,被丢弃的item将不会被之后的pipeline组件所处理。
return item
def open_spider(self, spider):
## spider (Spider 对象) – 被开启的spider
## 可选实现,当spider被开启时,这个方法被调用。
pass
def close_spider(self, spider):
## spider (Spider 对象) – 被关闭的spider
## 可选实现,当spider被关闭时,这个方法被调用
pass
数据处理部分在process_item函数中进行, 如数据筛选,清洗等等。
注意:一定要修改配置文件
2.2 文件保存
csv文件
import csv
class CSVPipeline(object):
def __init__(self):
self.f = open('win4000.csv', 'a', encoding='utf8')
self.csv_write = csv.DictWriter(self.f, ['title', 'img'])
self.csv_write.writeheader()
def process_item(self, item, spider):
self.csv_write.writerow(dict(item))
return item
def close_spider(self, spider):
self.f.close()
json文件
import json
class JSONPipeline(object):
def __init__(self):
self.f = open('win4000.json', 'a', encoding='utf8')
def process_item(self, item, spider):
self.f.write(json.dumps(dict(item), ensure_ascii=False))
self.f.write('\n')
return item
def close_spider(self, spider):
self.f.close()
2.3 数据库保存
保存到数据库和保存到文件中格式类似的,只不过初始化的时候,将本来是打开文件的操作,转为连接数据库的操作。写入的时候将本来是写入到文件的操作转为写入到数据库中的操作。以Redis数据库为例:
Redis数据库
# 这个是保存到redis
class RedisPipeline(object):
def __init__(self):
## 初始化链接reids
self.redis_cli = redis.StrictRedis(
host='127.0.0.1',
port=6379,
db=1,
)
def process_item(self, item, spider):
## 保存到redis
self.redis_cli.lpush('quotes', json.dumps(dict(item)))
return item
def close_spider(self, spider):
self.redis_cli.close()
MySQL数据库
# 这个是保存到mysql
class MySQLPipeline(object):
"""
create database quotes charset=utf8;
use quotes;
create table quotes (txt text, author char(20), tags char(200));
"""
def __init__(self):
self.connect = pymysql.connect(
host='192.168.159.128',
port=3306,
db='quotes', # 数据库名
user='windows',
passwd='123456',
charset='utf8',
use_unicode=True
)
# 创建操作数据的游标
self.cursor = self.connect.cursor()
def process_item(self, item, spider):
# 保存到mysql
# 执行sql语句
self.cursor.execute(
'insert into quotes (txt, author, tags) value(%s, %s, %s)', (item['text'], item['author'], item['tags'])
)
# 提交数据执行数据
self.connect.commit()
return item
# 关闭链接
def close_spider(self, spider):
self.cursor.close()
self.connect.close()
MongoDB数据库
有时,我们想把爬取到的数据存入某种数据库中,可以实现Item Pipeline完成此类任务。下面实现一个能将数据存入MongoDB数据库的Item Pipeline,代码如下:
在类属性中定义两个常量:
DB_URI 数据库的URI地址。
DB_NAME 数据库的名字。
from scrapy.item import Item
import pymongo
class MongoDBPipeline(object):
DB_URI = 'mongodb://localhost:27017/'
DB_NAME = 'scrapy_data'
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.DB_URI)
self.db = self.client[self.DB_NAME]
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
collection = self.db[spider.name]
post = dict(item) if isinstance(item, Item) else item
collection.insert_one(post)
return item
2.4 数据去重
将重复的数据不保存
from scrapy.exceptions import DropItem
class DuplicatesPipeline(object):
def __init__(self):
self.ids_seen = set()
def process_item(self, item, spider):
if item['id'] in self.ids_seen:
raise DropItem("Duplicate item found: %s" % item)
else:
self.ids_seen.add(item['id'])
return item
2.3 文件下载
下载文件也是实际应用中很常见的一种需求,例如使用爬虫爬取网站中的图片、视频、WORD文档、PDF文件、压缩包等。本章来学习在Scrapy中如何下载文件和图片。
scrapy专门封装了一个下载图片的 ImagesPipeline, 使用 ImagesPipeline for图像文件的优点是,可以配置一些额外的功能,例如生成缩略图和根据图像大小过滤图像。
FilesPipeline和ImagesPipeline
Scrapy框架内部提供了两个Item Pipeline,专门用于下载文件和图片:
● FilesPipeline
● ImagesPipeline
我们可以将这两个Item Pipeline看作特殊的下载器,用户使用时只需要通过item的一个特殊字段将要下载文件或图片的url传递给它们,它们会自动将文件或图片下载到本地,并将下载结果信息存入item的另一个特殊字段,以便用户在导出文件中查阅。下面详细介绍如何使用它们。
(1) 图片下载 - ImagesPipeline
目标网址:https://www.vmgirls.com/12985.html
有时候可能会采集图片资源,Scrapy帮我们实现了图片管道文件,很方便保存图片:
class VmgirlsSpider(scrapy.Spider):
name = 'vmgirls'
allowed_domains = ['vmgirls.com']
start_urls = ['https://www.vmgirls.com/12985.html']
def parse(self, response: scrapy.Selector):
item = PictureItem()
item['title'] = response.css('h1::text').extract_first()
item['img_s'] = response.css('.post-content img::attr(data-src)').extract()
print(item['img_s'])
yield item
重点:
get_media_requests()是用来发送请求的,需要传入图片的网址。file_path()是用来指定保存的文件的名字。item_completed() 当请求完成后进行的操作- 除了编写图片管道文件,还要在配置环境中激活,以及指定图片的存储位置。
class DownloadPicturePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
for image_url in item['img_s']:
yield scrapy.Request(image_url, meta={'filename': item['title']})
def file_path(self, request, response=None, info=None):
## 重命名,若不重写这函数,图片名为哈希
## 提取url前面名称作为图片名。
# request 文件下载之前的请求体
filename = request.meta.get('filename')
image_guid = request.url.split('/')[-1]
return os.path.join(filename, image_guid)
def item_completed(self, results, item, info):
## 保存图片下载的路径
image_paths = [x['path'] for ok, x in results if ok]
if not image_paths:
raise DropItem("Item contains no images")
item['image_paths'] = image_paths
return item
results格式,形式类似如下:
[( , { }), ( , { })]
[
(True, {
'url': 'http://static.win4000.com/home/images/placeholder.jpg',
'path': '高颜值长发美女手机壁纸\\placeholder.jpg',
'checksum': '049a591414e15671082f795487f13a5d'}),
(True, {
'url': 'http://static.win4000.com/home/images/placeholder.jpg',
'path': '高颜值长发美女手机壁纸\\placeholder.jpg',
'checksum': '049a591414e15671082f795487f13a5d'})
]
在配置文件settings.py中,增加ITEM_PIPELINES的键值对
ITEM_PIPELINES = {'scrapy.pipelines.files.ImagesPipeline': 1}
在配置文件settings.py中,使用IMAGES_STORE指定文件下载目录,如:
IMAGES_STORE = './images'

(2) 文件下载 - FilesPipeline
使用FilesPipeline下载页面中所有PDF文件,可按以下步骤进行:
在配置文件settings.py中启用FilesPipeline,通常将其置于其他Item Pipeline之前:
ITEM_PIPELINES = {'scrapy.pipelines.files.FilesPipeline': 1}
在配置文件settings.py中,使用FILES_STORE指定文件下载目录,如:
FILES_STORE = './files'
在Spider解析一个包含文件下载链接的页面时,将所有需要下载文件的url地址收集到一个列表,赋给item的file_urls字段(item[‘file_urls’])。FilesPipeline在处理每一项item时,会读取item[‘file_urls’],对其中每一个url进行下载,Spider示例代码如下:
class DownloadBookSpider(scrapy.Spider):
...
def parse(response):
item = {}
# 下载列表
item['file_urls'] = []
for url in response.xpath('//a/@href').extract():
download_url = response.urljoin(url)
# 将url 填入下载列表
item['file_urls'].append(download_url)
yield item
当FilesPipeline下载完item[‘file_urls’]中的所有文件后,会将各文件的下载结果信息收集到另一个列表,赋给item的files字段(item[‘files’])。下载结果信息包括以下内容:
● Path文件下载到本地的路径(相对于FILES_STORE的相对路径)。
● Checksum文件的校验和。
● url文件的url地址。
4、Scrapy框架案例
4.1 win4000美女图片爬取
>scrapy startproject win4000
>cd win4000
>scrapy genspider win_spider win4000.com
在settings.py文件里取消robot协议
(2) 分析网页:
数据:
标题 - title
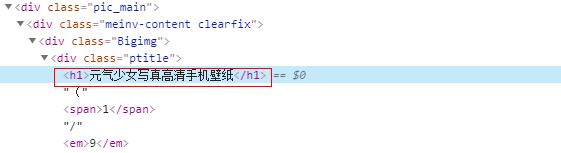
图片 - img

翻页:

(3) 编写Scrapy项目:
win_spider.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import Win4000Item
class WinSpiderSpider(scrapy.Spider):
name = 'win_spider'
allowed_domains = ['win4000.com']
start_urls = ['http://www.win4000.com/mobile_detail_169554.html']
def parse(self, response):
item = Win4000Item()
item['title'] = response.css('h1::text').get()
item['img'] = response.css('.pic-large::attr(src)').getall()
# yield item
# 翻页
next_url = response.css('.pic-next-img a::attr(href)').get()
if next_url:
yield scrapy.Request(next_url, callback=self.parse1, meta={"item": item})
def parse1(self, response):
# 翻页后,请求该页的标题和图片
title = response.css('h1::text').get()
img = response.css('.pic-large::attr(src)').getall()
# 获取meta参数中的数据,meta保存上一页的数据,其中title是我们需要的
item = response.meta.get("item")
t = item['title']
# 标题相等,在原img列表的基础上继续添加img
if title == t:
item['img'].extend(img)
# 标题不相等时,换到了新的主题
else:
# 返回该item
yield item
# 重新创建item
item = Win4000Item()
item['title'] = title
item['img'] = img
# item先不返回,将图片册收集完毕再返回
# yield item
# 翻页
next_url = response.css('.pic-next-img a::attr(href)').get()
if next_url:
yield scrapy.Request(next_url, callback=self.parse1, meta={"item": item})
items.py
import scrapy
class Win4000Item(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
img = scrapy.Field()
pipelines.py
import csv
import json
# save as CSV
class CSVPipeline(object):
def __init__(self):
self.f = open('win4000.csv', 'a', encoding='utf8')
self.csv_write = csv.DictWriter(self.f, ['title', 'img'])
self.csv_write.writeheader()
def process_item(self, item, spider):
self.csv_write.writerow(item)
return item
def close_spider(self, spider):
self.f.close()
# save as JSON
class JSONPipeline(object):
def __init__(self):
self.f = open('win4000.json', 'a', encoding='utf8')
def process_item(self, item, spider):
self.f.write(json.dumps(dict(item)))
self.f.write('\n')
return item
def close_spider(self, spider):
self.f.close()
更改settings.py文件中ITEM_PIPELINES配置
ITEM_PIPELINES = {
'win4000.pipelines.CSVPipeline': 200,
'win4000.pipelines.JSONPipeline': 300,
}
(4) 启动项目:
scrapy crawl win_spider
按键盘Ctrl + C 自行切断爬取进程,否则会爬全网。

这里只展示爬取三个主题

4.2 改进 - 多item爬取,图片分类别存储
items.py
import scrapy
# 标题+大图
class Win4000Item(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
img = scrapy.Field()
# 标题+小图+标签+说明信息+路径
class InfoWin4000Item(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
img = scrapy.Field()
tags = scrapy.Field()
info = scrapy.Field()
path = scrapy.Field()
win_spider.py
# -*- coding: utf-8 -*-
import scrapy
from ..items import Win4000Item, InfoWin4000Item
class WinSpiderSpider(scrapy.Spider):
name = 'win_spider'
allowed_domains = ['win4000.com']
start_urls = ['http://www.win4000.com/mobile_detail_169554.html']
def parse(self, response):
item = Win4000Item()
item['title'] = response.css('h1::text').get()
item['img'] = response.css('.pic-large::attr(src)').getall()
# yield item
# 翻页
next_url = response.css('.pic-next-img a::attr(href)').get()
if next_url:
yield scrapy.Request(next_url, callback=self.parse1, meta={"item": item})
def parse1(self, response):
# 翻页后,请求该页的标题和图片
title = response.css('h1::text').get()
img = response.css('.pic-large::attr(src)').getall()
# 获取meta参数中的数据,meta保存上一页的数据,其中title是我们需要的
item = response.meta.get("item")
t = item['title']
# 标题相等,在原img列表的基础上继续添加img
if title == t:
item['img'].extend(img)
# 标题不相等时,换到了新的主题
else:
# 返回该item
yield item
"""
此处为新增的内容,其余同上
"""
# 创建info_item
# 每组相册,只执行一次,则安排到该else的位置
info_item = InfoWin4000Item()
info_item['title'] = title
info_item['img'] = response.css('ul#scroll li img::attr(src)').getall()
info_item['tags'] = response.css('div.label a::text').getall()
info_item['info'] = response.css('.npaper_jj p::text').getall()
# 直接返回给pipelines,无需翻页
yield info_item
# 重新创建item
item = Win4000Item()
item['title'] = title
item['img'] = img
# item先不返回,将图片册收集完毕再返回
# yield item
# 翻页
next_url = response.css('.pic-next-img a::attr(href)').get()
if next_url:
yield scrapy.Request(next_url, callback=self.parse1, meta={"item": item})
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import csv
import json
import scrapy
from scrapy.pipelines.images import ImagesPipeline
from .items import Win4000Item, InfoWin4000Item
# CSV保存,根据item类别分别存储
class CSVPipeline(object):
def __init__(self):
# 保存item内容
self.f = open('win4000.csv', 'a', encoding='utf8')
self.csv_write = csv.DictWriter(self.f, ['title', 'img'])
self.csv_write.writeheader()
# 保存info_item内容
self.f_info = open('win4000_info.csv', 'a', encoding='utf8')
self.csv_write_info = csv.DictWriter(self.f_info, ['title', 'img', 'tags', 'info', 'path'])
self.csv_write_info.writeheader()
def process_item(self, item, spider):
if isinstance(item, Win4000Item):
self.csv_write.writerow(dict(item))
if isinstance(item, InfoWin4000Item):
self.csv_write_info.writerow(dict(item))
return item
def close_spider(self, spider):
self.f.close()
self.f_info.close()
# JSON保存,根据item类别分别存储
class JSONPipeline(object):
def __init__(self):
self.f = open('win4000.json', 'a', encoding='utf8')
self.f_info = open('win4000_info.json', 'a', encoding='utf8')
def process_item(self, item, spider):
if isinstance(item, Win4000Item):
self.f.write(json.dumps(dict(item)))
self.f.write('\n')
if isinstance(item, InfoWin4000Item):
self.f_info.write(json.dumps(dict(item)))
self.f_info.write('\n')
return item
def close_spider(self, spider):
self.f.close()
self.f_info.close()
# 图片保存,根据item类别分别存储
class Win4000Pipelines(ImagesPipeline):
def get_media_requests(self, item, info):
if isinstance(item, InfoWin4000Item):
for url in item['img']:
yield scrapy.Request(url, meta={'title': item['title']})
def file_path(self, request, response=None, info=None):
# request 文件下载之前的请求体
# 文件名
dirname = request.meta.get('title')
# 图片名
filename = request.url.split('/')[-1]
return dirname + '\\' + filename
def item_completed(self, results, item, info):
if isinstance(item, InfoWin4000Item):
# print('results', results)
path = []
## 保存图片下载的路径
for r in results:
if r[0]:
path.append(r[1]['path'])
# 对item进行修改
item['path'] = path
return item
settings.py
ITEM_PIPELINES = {
'win4000.pipelines.Win4000Pipelines': 100,
'win4000.pipelines.CSVPipeline': 200,
'win4000.pipelines.JSONPipeline': 300,
}
# 存储文件地址
IMAGES_STORE = './images'
启动爬虫后的结果:
4.3 我主良缘同城交友网信息爬取
我主良缘同城交友网网址:我主良缘
采集用户的图片以及用户信息
(1). 分析网站结构,网站信息动态加载,找到json接口:

(2) 创建项目:
>scrapy startproject liangyuan
>cd liangyuan
>scrapy genspider ly_spider 7799520.com
修改robot协议
(3) 编写scrapy项目
这里不使用items.py文件中的Item类,直接得到类似于字典的json数据进行处理
ly_spider.py
import scrapy
import json
class LySpiderSpider(scrapy.Spider):
name = 'ly_spider'
allowed_domains = ['7799520.com']
start_urls = ['http://www.7799520.com/api/recommend/pc/luck/list?token=&page=1']
def parse(self, response):
data_json = json.loads(response.text)
# pprint(data_json)
datas = data_json['data']['list']
for data in datas:
yield data
next_base = response.url.split('&')[0]
next_num = "&page="+str(eval(response.url[-1]+"+1"))
next_url = next_base+next_num
if next_url:
yield scrapy.Request(next_url, callback=self.parse)
pipelines.py
import json
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class JSONPipeline(object):
def __init__(self):
self.f = open('./datas/liangyuan.json', 'a', encoding='utf8')
def process_item(self, item, spider):
self.f.write(json.dumps(dict(item), ensure_ascii=False))
self.f.write('\n')
return item
def close_spider(self, spider):
self.f.close()
class DownloadPicturePipeline(ImagesPipeline):
def get_media_requests(self, item, info):
yield scrapy.Request(item['avatar'])
def file_path(self, request, response=None, info=None):
filename = 'ly_imgs'
image_name = request.url.split('/')[-1]+'.png'
return filename+'\\'+image_name
def item_completed(self, results, item, info):
return item
(4) 运行项目:
> scrapy crawl ly_spider
查看客户图片:

查看json文件,每个客户数据:

六、Scrapy的深入使用
1、middleware.py(MIDDLEWARE - 中间件)
1.1 Downloadr Middlewares
(1) 中间件的作用
没有中间件时的爬取策略:

有中间件时的爬取策略:

Downloader Middlewares中文名字为:下载器中间件,它位于 scrapy 引擎和下载器之间的一层组件。如下图所示:

作用:
- 一去:引擎将 请求 传递给下载器之前, 下载中间件 可以对 请求 进行一系列处理。比如设置请求的User-Agent,设置代理等
- 一回:在下载器完成将Response传递给引擎之前,下载中间件可以对响应进行一系列处理。比如进行gzip解压等。
我们主要使用下载中间件处理请求,一般会对请求设置随机的User-Agent,设置随机的代理。目的在于防止爬取网站的反爬虫策略。
(2) 中间件的文件
Scrapy 自动生成的这个文件名称为 middlewares.py,名字后面的 s 表示复数,说明这个文件里面可以放很多个中间件。可以看到有一个 SpiderMiddleware(爬虫中间件)中间件 和 DownloaderMiddleware (下载器中间件)中间件

在 middlewares.py 中添加下面一段代码(可以在 下载中间件这个类 里面写,也可以把 爬虫中间件 和 下载中间件 这两个类删了,自己写个 下载中间件的类。推荐自己单写一个类作为下载中间件):
默认下载器中间件代码如下:
class ExampleDownloaderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the downloader middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
# This method is used by Scrapy to create your spiders.
s = cls()
crawler.signals.connect(s.spider_opened, signal=signals.spider_opened)
return s
# 处理请求
def process_request(self, request, spider):
# Called for each request that goes through the downloader middleware.
# 调用通过下载器中间件的每个请求。
# Must either:
# - return None: continue processing this request
# - or return a Response object
# - or return a Request object
# - or raise IgnoreRequest: process_exception() methods of
# installed downloader middleware will be called
# 必须:
# - return None:继续处理这个请求
# - 或者返回一个 Response 对象
# - 或者返回一个 Request 对象
# - 或者抛出 IgnoreRequest :下载中间件的 process_exception() 将被激活
return None
# 处理响应
def process_response(self, request, response, spider):
# Called with the response returned from the downloader.
# 调用 downloader 返回的 response
# Must either;
# - return a Response object
# - return a Request object
# - or raise IgnoreRequest
# 必须:
# - 返回一个 Response 对象
# - 返回一个 Request 对象
# - 或者抛出一个 IgnoreRequest
return response
# 处理异常
def process_exception(self, request, exception, spider):
# Called when a download handler or a process_request()
# (from other downloader middleware) raises an exception.
# 激发一个下载处理器或者一个 process_request() (来自其他下载器中间件) 抛出一个异常
# Must either:
# - return None: continue processing this exception
# - return a Response object: stops process_exception() chain
# - return a Request object: stops process_exception() chain
# 必须:
# - return None:继续处理这个请求
# - 或者返回一个 Response 对象: 停止 process_exception() 调用链
# - 或者返回一个 Requests 对象: 停止 process_exception() 调用链
pass
def spider_opened(self, spider):
spider.logger.info('Spider opened: %s' % spider.name)
(3) 中间件类方法的解析
# 1. process_request函数
process_request(self, request, spider)
该方法是下载器中间件类中的一个方法,该方法是每个请求从引擎发送给下载器下载之前都会经过该方法。所以该方法经常用来处理请求头的替换,IP的更改,Cookie等的替换。
参数:
- request (Request 对象) – 处理的request
- spider (Spider 对象) – 该request对应的spider
返回值:
- 返回 None。Scrapy将继续处理该request,执行其他的中间件的相应方法,直到合适的下载器处理函数(download handler)被调用,该request被执行(其response被下载)。
- 如果其返回Response对象。Scrapy将不会调用 任何 其他的
process_request()或process_exception()方法,或相应地下载函数; 其将返回该response。已安装的中间件的process_response()方法则会在每个response返回时被调用。 - 如果其返回Request对象,Scrapy则停止调用
process_request方法并重新调度返回的request。当新返回的request被执行后, 相应地中间件链将会根据下载的response被调用。 - 如果其raise一个
IgnoreRequest异常,则安装的下载中间件的process_exception()方法会被调用。如果没有任何一个方法处理该异常, 则request的errback(Request.errback)方法会被调用。如果没有代码处理抛出的异常, 则该异常被忽略且不记录(不同于其他异常那样)。
# 2. process_request函数
process_response(self, request, response, spider)
该方法是下载器中间件类中的一个方法,该方法是每个响应从下载器发送给spider之前都会经过该方法。
参数:
- request (Request 对象) – response所对应的request
- response (Response 对象) – 被处理的response
- spider (Spider 对象) – response所对应的spider
返回值:
- 如果其返回一个Response (可以与传入的response相同,也可以是全新的对象), 该response会被其他中间件的
process_response()方法处理。 - 如果其返回一个Request对象,则返回的request会被重新调度下载。处理类似于
process_request()返回request所做的那样。 - 如果其抛出一个
IgnoreRequest异常,则调用request的errback(Request.errback)。如果没有代码处理抛出的异常,则该异常被忽略且不记录(不同于其他异常那样)。
1.2 随机替换请求头
有些网站需要用户在访问的时候确认用户采用的是用浏览器来进行访问的,也就是常见的User-Agent信息。在Scrapy中也可以设置相应的请求头信息。
如创建UserAgentDownloaderMiddleware中间件如下:
class UserAgentDownloaderMiddleware(object):
def __init__(self):
self.fake = Faker('en_US')
def process_request(self, request, spider):
useragent = self.fake.user_agent()
request.headers.update({"User-Agent": useragent})
return None
同pipelines一样,还需要在setting.py文件中激活配置好的中间件才能生效:
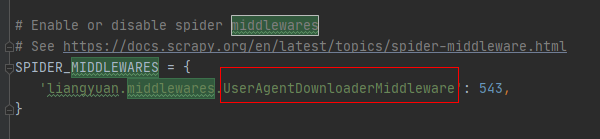
DOWNLOADER_MIDDLEWARES 设置会与 Scrapy 默认定义的 DOWNLOADER_MIDDLEWARES_BASE设置合并(但不是覆盖), 而后根据顺序(order)进行排序,最后得到启用中间件的有序列表: 第一个中间件是最靠近引擎的,最后一个中间件是最靠近下载器的。
关于如何分配中间件的顺序请查看 DOWNLOADER_MIDDLEWARES_BASE 设置,而后根据想要放置中间件的位置选择一个值。 由于每个中间件执行不同的动作,中间件可能会依赖于之前(或者之后)执行的中间件,因此顺序是很重要的。
原则来说开发自己的中间件需要替换Scrapy默认中间件,如果想禁止内置的(在 DOWNLOADER_MIDDLEWARES_BASE 中设置并默认启用的)中间件, 必须在项目的 DOWNLOADER_MIDDLEWARES设置中定义该中间件,并将其值赋为None。例如关闭User-Agent中间件:
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware': None
默认的下载器中间件(DOWNLOADER_MIDDLEWARES_BASE)执行的顺序值如下:

这些默认的下载器中间件的默认值可以在 scrapy.settings.default_settings.py 找到,在该文件下也可以找到爬虫中间件的默认顺序。
faker 是一个虚假数据生成的第三方库,可以随机生成各种虚假数据用于测试:
安装:
pip install Faker
使用:
In[1]:import faker
In[2]:fake = faker.Faker()
In[3]:fake.name()
Out[3]: 'John Richardson'
In[4]:fake.email()
Out[4]: 'carlos82@gomez-johnston.com'
In[5]:fake.user_agent()
Out[5]: 'Opera/9.41.(Windows NT 6.2; hsb-DE) Presto/2.9.166 Version/10.00'
1.3 随机替换IP
当使用Scrapy爬虫大规模请求某个网站时,经常会遇到封禁IP的情况。在这种情况下,设置IP代理就非常重要了。在Scrapy中设置代理IP也很简单,其原理就是在发送请求之前,指定一个可用的IP代理服务器即可。同样,IP的设置也是在下载器中间件里面设置,自定义自己的IP代理中间件。
class HttpProxyDownloaderMiddleware(object):
def __init__(self):
self.fake = Faker()
def process_request(self, request, spider):
port = fake.port_number()
ip = fake.ipv4()
proxy = ip+':'+port
request.meta['proxy'] = 'http://' + proxy
return None
注意: 使用fake创建的IP代理基本不可用,这样创建实际上没有意义。所以,后面项目会介绍代理池,具体可在github上搜索"代理池"关键字找到可用代理池项目。
如:代理池
1.4 随机设置Cookie值
有时候我们想要爬取的数据可以需要登录才能看到,这时候我们就需要登录网页。登陆后的网页一般都会在本地保存该网页的登录信息Cookies在本地。只要获取该Cookie,那么在以后跳转到其他网页的时候,只需要携带该Cookie即可。
class CookieDownloaderMiddleware(object):
def process_request(self, request, spider):
cookie = "cookie"
request.headers.update({'Cookie': cookie})
return None
注意:这里Faker没有方法模拟Cookie值。具体Cookie值应从请求网站上获取。
1.5 超时重试
可以直接查看scrapy的源码,在setting文件夹下的 default_settings.py 文件里面可以找到超时重试的配置选项。
RETRY_ENABLED = True # 是否开启超时重试
RETRY_TIMES = 2 # initial response + 2 retries = 3 requests 重试次数
RETRY_HTTP_CODES = [500, 502, 503, 504, 522, 524, 408, 429] # 重试的状态码
DOWNLOAD_TIMEOUT = 1
2、Scrapy框架案例
2.1 拉勾网 - 多spider和middlewares反爬
(1)创建项目
>scrapy startproject lagou
>cd lagou
>scrapy genspider lg_spider lagou.com
>scrapy genspider lg_spider2 lagou.com
取消settings.py中的robot协议
(2)分析网页
network中的XHR,找到动态加载的JSON接口

(3)构建Scrapy项目
爬虫文件使用start_requests函数中的scrapy.http.JSONRequest构建post请求
lg_spider.py
import scrapy
class LgSpiderSpider(scrapy.Spider):
name = 'lg_spider'
allowed_domains = ['lagou.com']
# 请求默认是get,列表对象
# start_urls = ['http://lagou.com/']
# post请求,函数对象
def start_requests(self):
yield scrapy.http.JSONRequest('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
data={
'first': 'true',
'pn': '1',
'kd': 'python',
},
callback=self.parse)
def parse(self, response):
print(response.text)
print(response.request.headers)
pass
lg_spider2.py
import scrapy
class LgSpider2Spider(scrapy.Spider):
name = 'lg_spider2'
allowed_domains = ['lagou.com']
# 请求默认是get,列表对象
# start_urls = ['http://lagou.com/']
# post请求,函数对象
def start_requests(self):
yield scrapy.http.JSONRequest('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
data={
'first': 'true',
'pn': '1',
'kd': 'python',
},
callback=self.parse)
def parse(self, response):
print(response.text)
print(response.request.headers)
pass
middlewares.py
lg_spider设置cookie
lg_spider2不设定cookie
通过函数中的spider参数的name属性进行分别设定
# -*- coding: utf-8 -*-
# Define here the models for your spider middleware
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/spider-middleware.html
import faker
import requests
from scrapy import signals
def get_cookie():
url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
headers1 = {
#'authority': 'www.lagou.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
# 'origin': 'https://www.lagou.com',
}
response = requests.get(url=url, headers=headers1)
cookie = response.cookies
return cookie.get_dict()
class HeadersDownloaderMiddleware(object):
def __init__(self):
self.fake = faker.Faker()
def process_request(self, request, spider):
# request.headers是一个字典
request.headers.update({
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': self.fake.user_agent()
})
return None
class CookieDownloaderMiddleware(object):
def __init__(self):
self.fake = faker.Faker()
def process_request(self, request, spider):
# 如果spider的名字是拉钩2
# 不修改cookie
if spider.name == 'lg_spider2':
return None
# request.cookies是一个字典
request.cookies.update(get_cookie())
return None
settings.py
DOWNLOADER_MIDDLEWARES = {
'lagou.middlewares.HeadersDownloaderMiddleware': 543,
'lagou.middlewares.CookieDownloaderMiddleware': 542,
}
(4)运行项目
>scrapy crawl lg_spider
>scrapy crawl lg_spider2
分别开两个终端,分别同时运行:
lg_spider - 设定cookie反爬,未被识别

lg_spider2 - 没有设定cookie反爬,被识别,从而被服务器"投毒"。

2.2 拉勾网项目改进 - 添加代理池、重新尝试
使用自己搭建的阿里云服务器,具体可见:阿里云服务器基本配置
使用自己搭建的IP代理池接口:http://39.97.118.3:5010/get/
(1)改写爬虫文件
# -*- coding: utf-8 -*-
import json
import scrapy
class LgSpiderSpider(scrapy.Spider):
name = 'lg_spider'
allowed_domains = ['lagou.com']
# 请求默认是get,列表对象
# start_urls = ['http://lagou.com/']
# post请求,函数对象
def start_requests(self):
yield scrapy.http.JSONRequest('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
data={
'first': 'true',
'pn': '1',
'kd': 'python',
},
callback=self.parse, meta={'page': 1})
def parse(self, response):
page = response.meta.get('page')
html = response.text
data = json.loads(html)
print("**************", '1', '*****************')
# 如果被反爬了,则重新尝试
if data.get('status'):
print('请求频繁,重试!')
yield scrapy.http.JSONRequest('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
data={
'first': 'true',
'pn': page,
'kd': 'python',
},
callback=self.parse, meta={'page': page})
# 获取到数据,则进行翻页
elif data.get('success'):
print('请求成功!')
# 构建翻页
yield data
if page <= 10:
page += 1
print("**************", page, '*****************')
yield scrapy.http.JSONRequest('https://www.lagou.com/jobs/positionAjax.json?needAddtionalResult=false',
data={
'first': 'false',
'pn': page,
'kd': 'python',
},
callback=self.parse, meta={'page': page})
(2)编写中间件
import faker
import requests
from scrapy import signals
# 获取Cookie
def get_cookie():
url = 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput='
headers1 = {
#'authority': 'www.lagou.com',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36',
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
# 'origin': 'https://www.lagou.com',
}
response = requests.get(url=url, headers=headers1)
cookie = response.cookies
return cookie.get_dict()
# 获取代理池
def get_proxy():
response = requests.get('http://39.97.118.3:5010/get/')
data = response.json()
return data['proxy']
# 请求头中间件
class HeadersDownloaderMiddleware(object):
def __init__(self):
self.fake = faker.Faker()
def process_request(self, request, spider):
# request.headers是一个字典
request.headers.update({
'referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'user-agent': self.fake.user_agent()
})
return None
# Cookie中间件
class CookieDownloaderMiddleware(object):
def __init__(self):
self.fake = faker.Faker()
def process_request(self, request, spider):
# 如果spider的名字是拉钩2
# 不修改cookie
if spider.name == 'lg_spider2':
return None
# request.cookies是一个字典
request.cookies.update(get_cookie())
return None
# 代理中间件
class ProxyDownloaderMiddleware(object):
def __init__(self):
self.fake = faker.Faker()
def process_request(self, request, spider):
request.meta['proxy'] = get_proxy()
return None
DOWNLOADER_MIDDLEWARES = {
'lagou.middlewares.HeadersDownloaderMiddleware': 543,
'lagou.middlewares.CookieDownloaderMiddleware': 542,
'lagou.middlewares.ProxyDownloaderMiddleware': 544,
}
(3)参考默认配置,对setting.py增加重试和超时时间

# 设定重试
RETRY_ENABLED = True
RETRY_TIMES = 5

# 超时时延,设置为5s
# 5s请求不到数据即跳过
DOWNLOAD_TIMEOUT = 5
(4)运行结果
scrapy crawl lg_spider -o datas.csv
爬取成功时:

爬取失败时:

注意这并不是被反爬了,而是服务器的代理池不稳定,代理IP的问题。可以增加尝试次数和时间,甚至可以多运行几次,有几率获得成功率最高的一次运行。
七、CrawlSpider
重写了默认的spiders.Spider,继承自他,而变成spiders.CrawlSpider
用于爬取数量较多,并且链接很有规则的网站
以"站长之家"为案例:站长地址
1、spiders.CrawlSpider
创建时指定模板
>scrapy startproject zhanzhang
>cd zhanzhang
>scrapy genspider zz_spider chinaz.com -t crawl
Created spider 'zz_spider' using template 'crawl' in module:
zhanzhang.spiders.zz_spider
# -t 指定模板
查看项目内容
基本没有变化,同样修改start_urls。
但是查看spider文件,可以发现有个rules变量

CrawlSpider 继承于 Spider 类,除了继承过来的属性(如:name、allow_domains)等等,还提供了新的属性和方法:如rules属性和Rule方法,该Rule是一个类。
2、rules属性和Rule对象
(1) Rule对象的形式和常用参数
class scrapy.spiders.Rule(
link_extractor,
callback = None,
cb_kwargs = None,
follow = None,
process_links = None,
process_request = None
)
link_extractor:是一个Link Extractor对象,用于定义需要提取的链接。callback: 从link_extractor 中每获取到链接时,参数所指定的值作为回调函数,该回调函数接受一个response作为其第一个参数。follow:是一个布尔(boolean)值,指定了根据该规则从response提取的链接是否需要跟进。 如果callback为None,follow 默认设置为True ,否则默认为False。process_links:指定该spider中哪个的函数将会被调用,从link_extractor中获取到链接列表时将会调用该函数。该方法主要用来过滤。process_request:指定该spider中哪个的函数将会被调用, 该规则提取到每个request时都会调用该函数。 (用来过滤request)
(2) 与spider的区别 - 增强start_url,替代scrapy.Requests
CrawlSpider 使用 rules 来决定爬虫的爬取规则,并将匹配后的url请求提交给引擎。所以也无需yield了。
start_urls作为最开始的引子,通过rules属性,引出start_urls网页中的所有筛选后的链接。
(3) 可以有多个Rule对象
一个rules可以包含一个或多个Rule对象,每个Rule对象,定义了爬取网站的特定操作,比如提取当前相应内容里的特定链接,是否对提取的链接跟进爬取,对提交的请求设置回调函数等。
Rule可以相同,但是里面的提取规则不同。
如果多个rule匹配了相同的链接,则根据规则在本集合中被定义的顺序,第一个会被使用。
注意: 当编写爬虫规则时,避免使用parse作为回调函数callback。由于CrawlSpider使用parse方法来实现其逻辑,如果覆盖了 parse方法,crawl spider将会运行失败。
start_requests() 是Spider类中的一个方法,我们要想使用这个方法就应该在继承 scrapy.Spider 后重写该方法。
3、使用 linkextractor 提取链接
class scrapy.linkextractors.LinkExtractor
LinkExtractors 的目的很简单: 提取链接。
每个LinkExtractor有唯一的公共方法是 extract_links(),它接收一个 Response 对象,并返回一个 scrapy.link.Link 对象。
Link Extractors要实例化一次,并且 extract_links 方法会根据不同的 response 调用多次提取链接。
class scrapy.linkextractors.LinkExtractor(
allow = (), # 允许的网站
deny = (), # 不允许的网站
allow_domains = (), # 允许的域名
deny_domains = (), # 不允许的域名
deny_extensions = None,
restrict_xpaths = (), # xpath提取
tags = ('a','area'), # 指定标签
attrs = ('href'), # 标签指定属性
canonicalize = True,
unique = True, # 默认去重
process_value = None
restrict_css = () # css选择器提取
)
主要参数:
allow:满足括号中“正则表达式”的URL会被提取,如果为空,则全部匹配。deny:满足括号中“正则表达式”的URL一定不提取(优先级高于allow)。allow_domains:会被提取的链接的domains。deny_domains:一定不会被提取链接的domains。restrict_xpaths:使用xpath表达式,和allow共同作用过滤链接。restrict_css:使用css表达式,和allow共同作用过滤链接。
改写zhanzhang项目中的rules属性

rules = (
Rule(LinkExtractor(
# 正则表达式
allow=r'http://top.chinaz.com/hangye/index_(.*?).html',
restrict_css=('.Taright', ),
),
callback='parse_item',
follow=True),
)
4、站长之家全网爬案例
继前面的分析,完成后续项目
将每一个链接里的第一个页面数据信息爬取下来
zz_spider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from ..items import ZhanzhangItem
class ZzSpiderSpider(CrawlSpider):
name = 'zz_spider'
allowed_domains = ['chinaz.com']
start_urls = ['https://top.chinaz.com/hangyemap.html']
# rules是一个元组
# LinkExtractor 规则的具体实现(正则表达式)
rules = (
Rule(LinkExtractor(
allow=r'http://top.chinaz.com/hangye/index_(.*?).html',
restrict_css=('.Taright', ),
),
callback='parse_item',
follow=True),
)
def parse_item(self, response):
# print(response.text)
lis = response.css('ul.listCentent li')
for li in lis:
item = ZhanzhangItem()
item['title'] = li.css('.rightTxtHead a::attr(title)').get()
item['img'] = li.css('.leftImg img::attr(src)').get()
item['rank'] = li.css('.CentTxt p.RtCData:nth-child(1) a::text').get()
item['RtData'] = li.css('.CentTxt p.RtCData:nth-last-child(1) a::text').get()
item['info'] = li.css('p.RtCInfo::text').get()
yield item
pipelines.py
class ZhanzhangPipeline(object):
def __init__(self):
self.f = open('zhanzhang.csv', 'a', encoding='utf8')
def process_item(self, item, spider):
d = dict(item)
self.f.write(','.join(d.values()))
self.f.write('\n')
return item
settings.py
ITEM_PIPELINES = {
'zhanzhang.pipelines.ZhanzhangPipeline': 300,
}
运行结果:
scrapy crawl zz_spider

速度很快,几秒钟即可爬几千条数据。
但是,每个链接除了第一页,还有后续页面。对于翻页,与前面项目类似,可参考前面项目,这里不再过多赘述,主要体现SpiderCrawl的使用。
八、过滤器
数据过滤和请求过滤
以"英语点津"中的双语新闻为例:网址
>scrapy startproject chinadaily
>cd chinadaily
>scrapy genspider eng_spider chinadaily.com

1、数据过滤 - 简单去重
有时候采集的数据需要进行去重。
eng_spider.py
使结果重复,再进行处理
# -*- coding: utf-8 -*-
import scrapy
from ..items import ChinadailyItem
class EngSpiderSpider(scrapy.Spider):
name = 'eng_spider'
allowed_domains = ['chinadaily.com']
# start_urls = ['https://language.chinadaily.com.cn/news_bilingual/']
# 使用start_requests代替start_urls
def start_requests(self):
# 默认开启了指纹过滤器,过滤请求
yield scrapy.Request('https://language.chinadaily.com.cn/news_bilingual/', callback=self.parse)
def parse(self, response):
divs = response.css('.content_left div.gy_box')
for div in divs:
item = ChinadailyItem()
item['title'] = div.css('p.gy_box_txt2 a::text').get()
item['info'] = div.css('p.gy_box_txt3 a::text').get()
item['img'] = div.css('.gy_box img::attr(src)').get()
yield item
# 制造重复数据,这里对结果进行去重
yield item
settings.py
ROBOTSTXT_OBEY = False
ITEM_PIPELINES = {
'chinadaily.pipelines.ChinadailyPipeline': 300,
}
pipelines.py
filter_item = []
class ChinadailyPipeline(object):
def __init__(self):
self.f = open('english1.csv', 'w', encoding='utf8', newline='')
def process_item(self, item, spider):
d = dict(item)
# 如果filter_item筛选表中没有该item,则保存
if d not in filter_item:
filter_item.append(d)
self.f.write(','.join(d.values()))
self.f.write('\n')
return item
def close_spider(self, spider):
self.f.close()
结果:
scrapy crawl eng_spider
去重前:
去重后:

缺点: 一旦数据变多,item越多,就会非常慢。
2、数据过滤 - 摘要算法
作为过滤器的目的: 节省内存空间
但在其他地方,有数据加密安全的作用。
Message-Digest Algorithm 5,消息摘要算法版本5。由Ron Rivest(RSA公司)在1992年提出,目前被广泛应用于数据完整性校验、数据(消息)摘要、数据加密等。MD2、MD4、MD5 都产生16字节(128位)的校验值,一般用32位十六进制数表示。
摘要哈希生成的正确姿势是什么样呢?分三步:
1.收集相关业务参数,在这里是金额和目标账户。当然,实际应用中的参数肯定比这多得多,这里只是做了简化。
2.按照规则,把参数名和参数值拼接成一个字符串,同时把给定的密钥也拼接起来。之所以需要密钥,是因为攻击者也可能获知拼接规则。
3.利用MD5算法,从原文生成哈希值。MD5生成的哈希值是128位的二进制数,也就是32位的十六进制数。

考虑把多种摘要算法结合使用比如
明文: abcd
MD5摘要:
e2fc714c4727ee9395f324cd2e7f331f
Python 的 hashlib 提供了常见的摘要算法,如MD5,SHA1等等。
摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
假设我们有多个字典
d1 = {"name": "张三", "age": 18, "hobby": "吃"}
d2 = {"name": "李四", "age": 18, "hobby": "喝"}
d3 = {"name": "王五", "age": 18, "hobby": "玩"}
items = [d1, d2, d3]
print(items)
突然后多出一条数据
d4 = {"name":"赵六","age":18,"hobby":"乐"}
需要判断第四条数据是否在这之前已经出现过了
用之前学习过的方式就是用一下方法判断
d4 = {"name": "赵六", "age": 18, "hobby": "乐"}
if d4 not in items:
print('d4不存在于items')
这种简单判断,当数据内容非常多时,判断就会占用很多的内存空间。
这时候就可以简化方法,只记录他们的hash值,这样就可以多内存的负担减少很多
h1 = hashlib.md5(json.dumps(d1).encode()).hexdigest()
h2 = hashlib.md5(json.dumps(d2).encode()).hexdigest()
h3 = hashlib.md5(json.dumps(d3).encode()).hexdigest()
items2 = [h1, h2, h3]
print(items2)
h4 = hashlib.md5(json.dumps(d4).encode()).hexdigest()
if h4 not in items2:
print('d4不存在与items2')
摘要算法就是通过摘要函数对任意长度的数据 data 计算出固定长度的摘要,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算哈希很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
import hashlib
import json
# 1. 详细方法
md5 = hashlib.md5()
d = {'name':'asd'}
d_str = json.dumps(d)
md5.update(d_str.encode())
h = md5.hexdigest()
# 2. 便捷方法
h = hashlib.md5(json.dumps(d).encode()).hexdigest()
同样,改写:
pipelines.py
import hashlib
import json
# 爬虫程序重新启动一次,过滤就会再来一次
# 爬虫结束之前把去重结果保存一次,下次启动时,把去重结果加载一遍
# 不需要将保存过的结果再保存一次
filter_item = []
class ChinadailyPipeline(object):
def __init__(self):
self.f = open('english_finger1.csv', 'w', encoding='utf8', newline='')
def process_item(self, item, spider):
d = dict(item)
h = hashlib.md5(json.dumps(d).encode()).hexdigest()
if h not in filter_item:
filter_item.append(h)
self.f.write(','.join(d.values()))
self.f.write('\n')
return item
def close_spider(self, spider):
self.f.close()
结果同上
3、请求过滤 - 指纹过滤器
对整个request进行过滤,包括:url、method、params等等。
后面对过滤器进行改写,仅对url进行过滤。
去重处理可以避免将重复性的数据保存到数据库中以造成大量的冗余性数据。不要在获得爬虫的结果后进行内容过滤,这样做只不过是避免后端数据库出现重复数据。
去重处理对于一次性爬取是有效的,但对于增量式爬网则恰恰相反。对于持续性长的增量式爬网,应该进行"前置过滤",这样可以有效地减少爬虫出动的次数。在发出请求之前检查询爬虫是否曾爬取过该URL,如果已爬取过,则让爬虫直接跳过该请求以避免重复出动爬虫。
Scrapy 提供了一个很好的请求指纹过滤器(Request Fingerprint duplicates filter)
scrapy.dupefilters.ReppupeFilter,当它被启用后,会自动记录所有成功返回响应的请求的URL,并将其以文件(requests.seen)方式保存在项目目录中。请求指纹过滤器的原理是为每个URL生成一个指纹并记录下来,一旦当前请求的URL在指纹库中有记录,就自动跳过该请求。
默认情况下这个过滤器是被自动启用的。


源码解释:
class RFPDupeFilter(BaseDupeFilter):
"""Request Fingerprint duplicates filter"""
# 默认是一个指纹过滤器,会对整个request进行过滤,
# request = 对url请求网址/ method请求方法/ params 请求参数 / ...进行过滤
def __init__(self, path=None, debug=False):
self.file = None
# 内存型集合,不持久,下次运行则会消失
self.fingerprints = set()
self.logdupes = True
self.debug = debug
self.logger = logging.getLogger(__name__)
if path:
self.file = open(os.path.join(path, 'requests.seen'), 'a+')
self.file.seek(0)
self.fingerprints.update(x.rstrip() for x in self.file)
@classmethod
def from_settings(cls, settings):
debug = settings.getbool('DUPEFILTER_DEBUG')
return cls(job_dir(settings), debug)
def request_seen(self, request):
# 拿到request
fp = self.request_fingerprint(request)
if fp in self.fingerprints:
# 如果返回True,已经存在该数据
return True
# 否则不存在,则记录到指纹里面
self.fingerprints.add(fp)
# 最终将内容写入到文件中
if self.file:
self.file.write(fp + os.linesep)
def request_fingerprint(self, request):
return request_fingerprint(request)
当然也可以根据自身的需求编写自定义的过滤器,
继承 scrapy.dupefilters.BaseDupeFilter 开发自定义的过滤器。
class BaseDupeFilter:
@classmethod
def from_settings(cls, settings):
return cls()
def request_seen(self, request):
return False
def open(self): # can return deferred
pass
def close(self, reason): # can return a deferred
pass
def log(self, request, spider): # log that a request has been filtered
pass
由于scrapy.dupefilters.RFPDupeFilter采用文件方式保存指纹库,对于增量爬取且只用于短期运行的项目还能应对。一旦遇到爬取量巨大的场景时,这个过滤器就显得不太适用了,因为指纹库文件会变得越来越大,过滤器在启动时会一次性将指纹库中所有的URL读入,导致消耗大量内存。
可以用Scrapy提供的request_fingerprint函数为请求生成指纹,然后将指纹写入Redis
中,实现代码如下:
class URLFilter(BaseDupeFilter):
"""根据URL过滤"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
print('url_set', url_set)
def request_seen(self, request):
url = self.request_fingerprint(request)
if url in url_set:
return False
else:
url_set.add(request.url)
def request_fingerprint(self, request):
# return hashlib.md5(request.url).hexdigest()
return request.url
当数据量不大时(大约在200MB内),可以直接在内存中进行去重处理(例如,可以使用 set() 进行去重),而更省事又能对去重状态进行持久化的办法就是采用 scrapy.dupefilters.RFPDupeFilter 。
当数据量在5GB以内时,建议采用上文中的 RedisDupeFilter 进行去重,当然这要求服务器的内存必须大于5GB,否则Redis可能会将机器的内存耗光。
当数据量达到10~100GB级别时,由于内存有限,就必须用"位"来去重,才能够满足需求。而布隆过滤器就是将去重对象映射到几个内存"位",通过几个位的0/1值来判断一个对象是否已经存在,以应对海量级的请求数据的重复性校验。
同样进行改写:
对指纹过滤器进行重写,仅仅对url进行过滤。
eng_spider.py
使url重复,再进行处理
# -*- coding: utf-8 -*-
import scrapy
from ..items import ChinadailyItem
class EngSpiderSpider(scrapy.Spider):
name = 'eng_spider'
allowed_domains = ['chinadaily.com']
# start_urls = ['https://language.chinadaily.com.cn/news_bilingual/']
def start_requests(self):
# 默认会开启指纹过滤器,过滤请求。但后面进行改写指纹过滤器。
# 创造重复url
yield scrapy.Request('https://language.chinadaily.com.cn/news_bilingual/', callback=self.parse)
yield scrapy.Request('https://language.chinadaily.com.cn/news_bilingual/', callback=self.parse)
yield scrapy.Request('https://language.chinadaily.com.cn/news_bilingual/', callback=self.parse)
def parse(self, response):
divs = response.css('.content_left div.gy_box')
for div in divs:
item = ChinadailyItem()
item['title'] = div.css('p.gy_box_txt2 a::text').get()
item['info'] = div.css('p.gy_box_txt3 a::text').get()
item['img'] = div.css('.gy_box img::attr(src)').get()
yield item
# 创造重复数据
# yield item
middlewares.py
class URLFilter(BaseDupeFilter):
"""根据URL过滤"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
# 过滤url的集合
self.url_set = set()
print('url_set', self.url_set)
def request_seen(self, request):
# 对每一个请求进行过滤
url = self.request_fingerprint(request)
if url in self.url_set:
# False屏蔽过滤器
# True启用过滤器,代表这个url已经被请求过了
return True
else:
self.url_set.add(request.url)
def request_fingerprint(self, request):
# 1. 返回hashlib,去重更节省内存
# return hashlib.md5(request.url).hexdigest()
# 2. 直接返回url
return request.url
settings.py
# 过滤器的位置,替换默认setting.py中的位置
DUPEFILTER_CLASS = 'chinadaily.middlewares.URLFilter'
注意: URLFilter是写到middlewares.py中,其实它的位置可以任意,但是要在settings.py中的DUPEFILTER_CLASS 参数中指定位置,并且无需在settings.py中取消XXX_MIDDLEWARES的注释,因为跟中间件无关。
运行结果:
scrapy crawl eng_spider
urls去重前:

urls去重后:

九、Scrapy分布式
Scrapy_redis : Redis-based components for Scrapy.
Github地址:https://github.com/rmax/scrapy-redis
Scrapy_redis 在scrapy 的基础上实现了更多,更强大的功能,具体体现在:reqeust去重,爬虫持久化,和轻松实现分布式
那么,scrapy_redis是如何帮助我们抓取数据的呢?
1、单机爬虫
正常的 Scrapy 单机爬虫:

Scrapy并不会共享调度队列,也就是说Scrapy是不支持分布式的。为了支持分布式,我们需要让Scrapy支持共享调度队列,也就是改造成共享调度和去重的功能。
默认情况下Scrapy是不支持分布式的,需要使用基于Redis 的 Scrapy-Redis 组件才能实现分布式。
2、分布式爬虫
Redis数据库充当分发工具
分布式:分而治之
将一个爬虫代码,分别部署在多台电脑上,共同完成整个爬虫任务。

使用Redis服务器来集中处理所有的请求,主要负责请求的去重和调度。通过这种方式,所有电脑端的爬虫共享了一个爬取队列,并且每个电脑端每次得到的请求都是其他爬虫未曾访问的。从而提高了爬虫效率。
得到一个请求之后,检查一下这个Request是否在Redis去重,如果在就证明其它的spider采集过,如果不在就添加进调度队列,等待别人获取。
Scrapy 是一个通用的爬虫框架,但是不支持分布式,Scrapy-redis是为了更方便地实现Scrapy分布式爬取,而提供了一些以redis为基础的组件。
安装如下:pip install scrapy-redis
Scrapy-redis 提供了下面四种组件(components):(四种组件意味着这四个模块都要做相应的修改)
- Scheduler(调度器) - 原本在本机进行调度,现在在服务器进行调度,即redis数据库进行调度
- Duplication Filter(去重) - 原本去重后的数据保存到本地,保存到元组和列表,现在要保存到服务器中去
- Item Pipeline(管道)- 保存数据
- Base Spider(爬虫类)
2.1 Scheduler(调度器)
Scrapy改造了Python本来的collection.deque(双向队列)形成了自己的Scrapy queue,但是Scrapy多个spider不能共享待爬取队列Scrapy queue, 即Scrapy本身不支持爬虫分布式,scrapy-redis 的解决是把这个Scrapy queue换成redis数据库(也是指redis队列),便能让多个spider去同一个数据库里读取,这样实现共享爬取队列。
Redis支持多种数据结构,这些数据结构可以很方便的实现这样的需求:
-
列表有lpush(),lpop(),rpush(),rpop(),这些方法可以实现先进先出,或者先进后出式的爬取队列。
-
集合元素是无序且不重复的,可以很方便的实现随机排序且不重复的爬取队列。
-
Scrapy的Request带有优先级控制,Redis中的集合也是带有分数表示的,可以用这个功能实现带有优先级调度的爬取队列。
Scrapy把待爬队列按照优先级建立了一个字典结构,比如:
{
优先级0 : 队列0
优先级1 : 队列1
优先级2 : 队列2
}
然后根据request中的优先级,来决定该入哪个队列,出列时则按优先级较小的优先出列。由于Scrapy原来的Scheduler只能处理Scrapy自身的队列,不能处理Redis中的队列,所以原来的Scheduler已经无法使用,应该使用Scrapy-Redis的Scheduler组件。
2.2 Duplication Filter(去重)
Scrapy自带去重模块,该模块使用的是Python中的集合类型。该集合会记录每个请求的指纹,指纹也就是Request的散列值。指纹的计算采用的是hashlib的sha1()方法。计算的字段包含了,请求的Method,URL,Body,Header这几个内容,这些字符串里面只要里面有一点不同,那么计算出来的指纹就是不一样的。也就是说,计算的结果是加密后的字符串,这就是请求指纹。通过加密后的字符串,使得每个请求都是唯一的,也就是指纹是惟一的。并且指纹是一个字符串,在判断字符串的时候,要比判断整个请求对象容易。所以采用了指纹作为判断去重的依据。
Scrapy-Redis要想实现分布式爬虫的去重功能,也是需要更新指纹集合的,但是不能每个爬虫维护自己的单独的指纹集合。利用Redis集合的数据结构类型,可以轻松实现分布式爬虫的指纹判重。也就是说:每台主机得到Request的指纹去和Redis中的集合进行对比,如果指纹存在,说明是重复的,也就不会再去发送请求,如果不曾存在于Redis中的指纹集合,就会发送请求,并且将该指纹加入Redis的集合中。这样就实现了分布式爬虫的指纹集合的共享。
2.3 Item Pipeline
引擎将(Spider返回的)爬取到的Item给Item Pipeline,scrapy-redis 的Item Pipeline将爬取到的 Item 存⼊redis的 items queue。修改过Item Pipeline可以很方便的根据 key 从 items queue 提取item,从⽽实现 items processes集群。
2.4 Base Spider
不再使用scrapy原有的Spider类,重写的RedisSpider继承了Spider和RedisMixin这两个类,RedisMixin是用来从redis读取url的类。当我们生成一个Spider继承RedisSpider时,调用setup_redis函数,这个函数会去连接redis数据库,然后会设置signals(信号):
当spider空闲时候的signal,会调用spider_idle函数,这个函数调用schedule_next_request函数,保证spider是一直活着的状态,并且抛出DontCloseSpider异常。
当抓到一个item时的signal,会调用item_scraped函数,这个函数会调用schedule_next_request函数,获取下一个request。
3、Scrapy_redis
scrapy-redis Github网址: https://github.com/rolando/scrapy-redis
直接clone
git clone https://github.com/rolando/scrapy-redis.git
3.1 MongoDB和Redis存储与操作
3.2 房天下案例
房天下网址:https://www.fang.com/SoufunFamily.html
爬取所有省份链接内的新房和二手房。

具体请看:
Scrapy分布式爬虫 - 房天下案例
参考文档
Scrapy官网
中文文档
Proxy_Pool Github
Scrapy状态管理工具- Gerapy文档
Gerapy Github
更新时间
第一次更新 2020/7/1















 4066
4066











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









