







day5 AI面试刷题
1. 写出全概率公式&贝叶斯公式
全概率公式:
P
(
A
)
=
∑
i
=
1
n
P
(
A
∣
B
i
)
P
(
B
i
)
P(A)=\sum^n_{i=1}P(A|B_i)P(B_i)
P(A)=∑i=1nP(A∣Bi)P(Bi)
贝叶斯公式:
P
(
A
1
∣
B
)
=
P
(
B
∣
A
1
)
P
(
A
1
)
P
(
B
)
=
P
(
B
∣
A
1
)
P
(
A
1
)
∑
i
=
1
n
P
(
B
∣
A
i
)
P
(
A
i
)
\begin{aligned} P(A_1|B)=\frac{P(B|A_1)P(A_1)}{P(B)}=\frac{P(B|A_1)P(A_1)}{\sum^n_{i=1}P(B|A_i)P(A_i)} \end{aligned}
P(A1∣B)=P(B)P(B∣A1)P(A1)=∑i=1nP(B∣Ai)P(Ai)P(B∣A1)P(A1)
2. 朴素贝叶斯为什么“朴素naive”?
因为朴素贝叶斯假设每个特征之间没有关联,即各个变量相互独立。
参考答案:
朴素贝叶斯(Navie Bayesian)中的朴素可以理解为是“简单、理想化”的意思,因为“朴素”是假设了样本特征之间是相互独立、没有相关关系。这个假设在现实世界中是很不真实的,属性之间并不是都是相互独立的,有些属性也会存在相关性,所以说朴素贝尔斯是一种很“朴素”的算法。
3. 朴素贝叶斯有没有超参数可以调?
参考答案:
朴素贝叶斯模型的训练过程,本质上是通过数学统计方法从训练数据中统计先验概率
P
(
C
)
P(C)
P(C)和后验概率
P
(
x
i
∣
C
)
P(x_i|C)
P(xi∣C),而这个过程是不需要超参数调节的,所以朴素贝叶斯模型没有可调节的超参数。虽然在实际应用中,朴素贝叶斯会与拉普拉斯平滑修正(Laplacian Smoothing Correction)一起使用,而拉普拉斯平滑修正方法中有平滑系数这一超参数,但是这并不属于朴素贝叶斯模型本身的范畴。
4. 朴素贝叶斯的工作流程是怎样的?
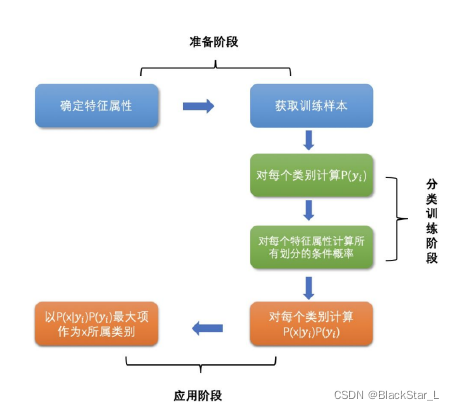
朴素贝叶斯的工作流程可以分为三个阶段进行,分别是准备阶段、分类器训练阶段和应用阶段。
**准备阶段:**这个阶段的任务是为朴素贝叶斯分类做必要的准备,主要工作是根据具体情况确定特征属性,并对每个特征属性进行适当划分,去除高度相关性的属性(如果两个属性具有高度相关性的话,那么该属性将会在模型总发挥了2次作用,会使得朴素贝叶斯所预测的结果向该属性所希望的方向偏离,导致分类出现偏差),然后由人工对一部分待分类项进行分类,形成训练样本集合。这一阶段的输入是所有待分类数据,输出是特征属性和训练样本。(这一阶段是整个朴素贝叶斯分类中唯一需要人工完成的阶段,其质量对整个过程将有重要影响)
分类器训练阶段: 这个阶段的任务就是生成分类器,主要工作是计算每个类别在训练样本中的出现频率及每个特征属性划分对每个类别的条件概率估计,并将结果记录。其输入是特征属性和训练样本,输出是分类器。从公式上理解,朴素贝叶斯分类器模型的训练目的就是要计算一个后验概率
P
(
C
∣
x
)
P(C|x)
P(C∣x)使得在给定特征的情况下,模型可以估计出每个类别出现的概率情况:
P
(
C
∣
x
)
=
P
(
C
)
P
(
x
∣
C
)
P
(
x
)
=
P
(
C
)
P
(
x
)
∏
i
=
1
d
P
(
x
i
∣
C
)
\begin{aligned} P(C|x)=\frac{P(C)P(x|C)}{P(x)}=\frac{P(C)}{P(x)}\prod^d_{i=1}P(x_i|C) \end{aligned}
P(C∣x)=P(x)P(C)P(x∣C)=P(x)P(C)i=1∏dP(xi∣C)
因为 P ( x ) P(x) P(x)是一个先验概率,它对所有类别来说是相同的,而我们在预测的时候会比较每个类别相对的概率情况、选取最大的哪个作为输出值。所以我们可以不计算 P ( x ) P(x) P(x)。贝叶斯学习的过程就是要根据训练数据统计计算先验概率 P ( C ) P(C) P(C) 和后验概率 P ( x i ∣ c ) P(x_i|c) P(xi∣c)。
应用阶段: 这个阶段的任务是使用分类器对待分类项进行分类,其输入是分类器和待分类项,输出是待分类项与类别的映射关系。并选出概率值最高所对应的类别,用公式表示为:
h
(
x
)
=
arg max
c
∈
y
P
(
C
)
∏
i
=
1
d
P
(
x
i
∣
C
)
h(x)=\argmax_{c\in y}P(C)\prod^d_{i=1}P(x_i|C)
h(x)=c∈yargmaxP(C)i=1∏dP(xi∣C)
5. 朴素贝叶斯对异常值敏不敏感?
参考答案: 基础的朴素贝叶斯模型的训练过程,本质上是通过数学统计方法从训练数据中统计先验概率 P ( C ) P(C) P(C) 和后验概率 P ( x i ∣ C ) P(x_i|C) P(xi∣C),少数的异常值,不会对统计结果造成比较大的影响。所以朴素贝叶斯模型对异常值不敏感。















 1657
1657











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









