







1.把pdf图片批量转为jpg;需要注意的是,需要先安装poppler这个软件,具体安装教程放在下面代码中了
2.代码
#poppler安装教程参考:https://blog.csdn.net/wy01415/article/details/110257130
#windows上poppler下载链接:https://github.com/oschwartz10612/poppler-windows
from pdf2image import convert_from_path
from PIL import Image
import os
def convert_pdf_to_jpg(pdf_folder, output_folder, poppler_path):
for pdf_file in os.listdir(pdf_folder):
if pdf_file.endswith('.pdf'):
pdf_path = os.path.join(pdf_folder, pdf_file)
images = convert_from_path(pdf_path, poppler_path=poppler_path)
for i, image in enumerate(images):
#如果pdf有多页用下面这个代码
# output_filename = f"{os.path.splitext(pdf_file)[0]}_page_{i + 1}.jpg"
# 如果pdf就1页用下面这个代码
output_filename = f"{os.path.splitext(pdf_file)[0]}.jpg"
output_path = os.path.join(output_folder, output_filename)
image.save(output_path, 'JPEG')
pdf_folder = 'E:/pythonworking/file/pdf_merge/workspace'
output_folder = 'E:/pythonworking/file/pdf_merge/workspace'
poppler_path = 'D:/software/Poppler/Release-24.02.0-0/poppler-24.02.0/Library/bin'
convert_pdf_to_jpg(pdf_folder, output_folder, poppler_path)
3.输出结果: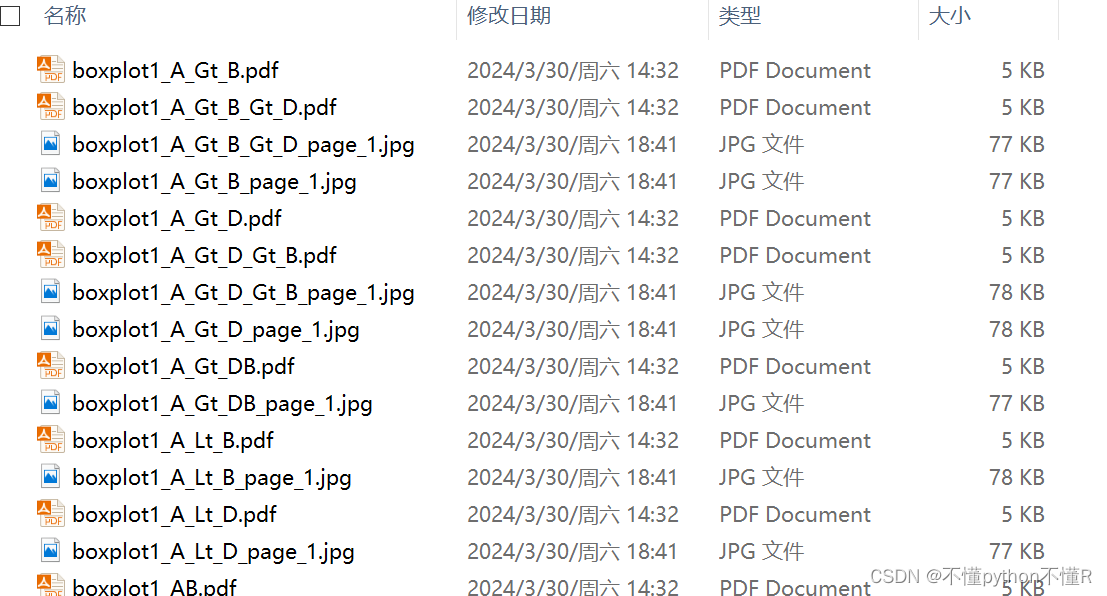
















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









