







XGBoost简介
XGBoost是GBDT(梯度下降树,Gradient Boosting Decision Tree)的一种,也是加法模型和前向优化算法。在监督学习中,可以分为:模型、参数、目标函数、学习方法。
- 模型:给定输入x后预测输出y的方法,比如说回归,分类,排序等。
- 参数:模型中的参数,比如线性回归中的权重和偏置。
- 目标函数:即损失函数,包含正则化项。
- 学习方法:给定目标函数后求解模型和参数的方法,比如:梯度下降法,数学推导等等。一般都是使用梯度下降的方法。
从这四个方面来构建XGBoost模型即可。
模型形式
首先假设判断一个人是否喜欢电脑游戏,即一个二分类问题。输入为年龄、性别、职业等特征,可以得到一个如下的回归树模型。

然后在每一个叶子节点上都会有一个分数,利用这个分数我们可以回归或映射成概率进行分类等等,如下图所示。

但是,对于一棵CART树(Classification And Regression Tree)来说,,拟合能力实在是太有限了。因此我们可以进行集成学习,最简单的,我们使用两个树进行预测,把两个树的和当作结果。如下图所示。

用多棵树进行预测的方法就是随机森林或者提升树等等模型。
目标函数
然后,我们来看一看对于XGBoost如何来用数学的公式进行表示。以上面的两个树为例,每个树的叶子节点下都有一个数值,我们可以把这个数值作为权值w,然后假设小男孩在tree1具体的数据为x,则预测值为tree1的预测值为,每一个树都有这样一个预测值,将其加权求和就是最后的预测值。公式如下。
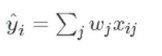
为了方便理解,以上的预测值求得方法只是一个简化后的易于懂得的公式,具体的数学公式比这个复杂许多。XGBoost的核心就是一个树一个树的加,比如说先用一个树求得预测结果,然后再加一个树再求预测结果,依此加树。然后就有了一个重要的需要解决的问题,那就是我如何保证我加了一个新的树,预测效果会变得更好。
首先,我们得用数学公式把一个树的模型表示出来,具体数学公式如下。图片上方的公式就表示了一个树的模型。

然后我们将n次模型预测的结果用数学公式写出来,如下所示。第一个为0,代表没有树模型。然后加上一个树模型之后预测出来一个值,再加一个树又预测出一个值,依次类推。这样就不难理解最后一个第t轮模型预测公式了。

然后刚刚提出的急需解决的问题就是,我在第t轮预测加上了一个新的树也就是一个新的函数,那我应该加上什么样的新函数来保证预测的效果比没加之前的要好。目标函数由两部分相加而成,一是正则化惩罚项,二是自身的均方误差或者其他类型的函数(用于量化原本y值和预测y值之间的差异)。
损失函数的正则化惩罚项如下图所示。对于一个树来说,叶子节点数越多,过拟合的风险就越大,所以需要限制一下叶子节点数的个数。在下面这个公式之中有具体体现,T代表叶子节点个数,代表惩罚力度,叶子节点数越多,惩罚项就越大。然后加法后面是一个L2惩罚项,因为对于线性回归、神经网络的权重参数都有一个L2的惩罚项,这里也不例外。

由此目标函数为差异量化函数即损失函数(量化原本y值和预测y值之间的差异,最简单的如均方误差)加上正则化惩罚项,公式如下图所示第一行。代入第t轮的模型预测函数并且算出前面所有的正则化惩罚项之后如第二行所示(正则化惩罚项算出之后为常数(constant),只有第t轮的还是未知的)。
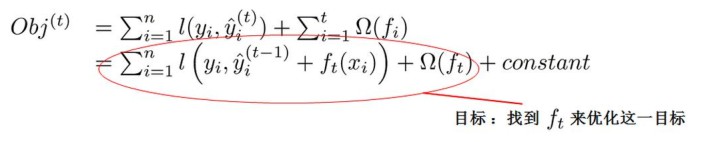
那怎样加一个使模型预测更准确的树呢?如下面这个公式所示,已经代入了损失函数,残差即预测值与真实值之间的差异(损失)。举一个例子,假设一个真实值为1000,第一个树预测值为+950,残差为50,第二个树知道了前一个树预测之后还差50,那XGBoost再加一个树预测弥补了一些为+30,再加一个预测又弥补了一些为+15,相加的995。即在构造每一个树的时候都会把前面的每一棵树当成一个整体,然后通过这个残差来优化一下,看看我的这个树怎么来构造使得这个残差值最小。这就是XGBoost的基本原理。

模型求解
目标函数已经推导出来了,对于这个目标函数可以做一个近似的转换,利用泰勒展开来近似我们原来的目标,具体过程如下图。值得指出的是,对于第t轮的目标函数,前t-1轮的预测结果和真实值都是常数,因此可以与后面的constant合并,然后由于常数项对于求解没有任何作用,因此可以去掉。

把对样本的遍历转换为对叶子节点的遍历,对叶子节点的遍历和对样本的遍历从结果上看都是一样的,但是从过程上看,对叶子节点的遍历更简单。 然后就得到了一个新的目标函数,如下图所示。

然后对损失函数进行进一步的化简,如下图所示。

对于损失函数求偏导,得出然后再往回带,就得出了最终的目标函数,模型求解完成。

XGBoost求解实例
通过例子来展示XGBoost的完整求解过程。Obj代表了当我们指定一个树的结构的时候,我们在目标上面最多减少多少。我们可以把它叫做结构分数(structure score)。你可以认为这个就是类似吉尼系数易于更加一般的对于树结构进行打分的函数。下面使一个具体的打分函数的例子。


以上就是XGBoost一个实例的求解过程。

















 546
546











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











