






👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术

【python】python取Tw评论(纯属原创手把手教学)
1. 任务描述
要爬取Tw的某个贴子下的评论,用于分析大熊猫丫丫回国,对网友的情感进行分析的课题研究。
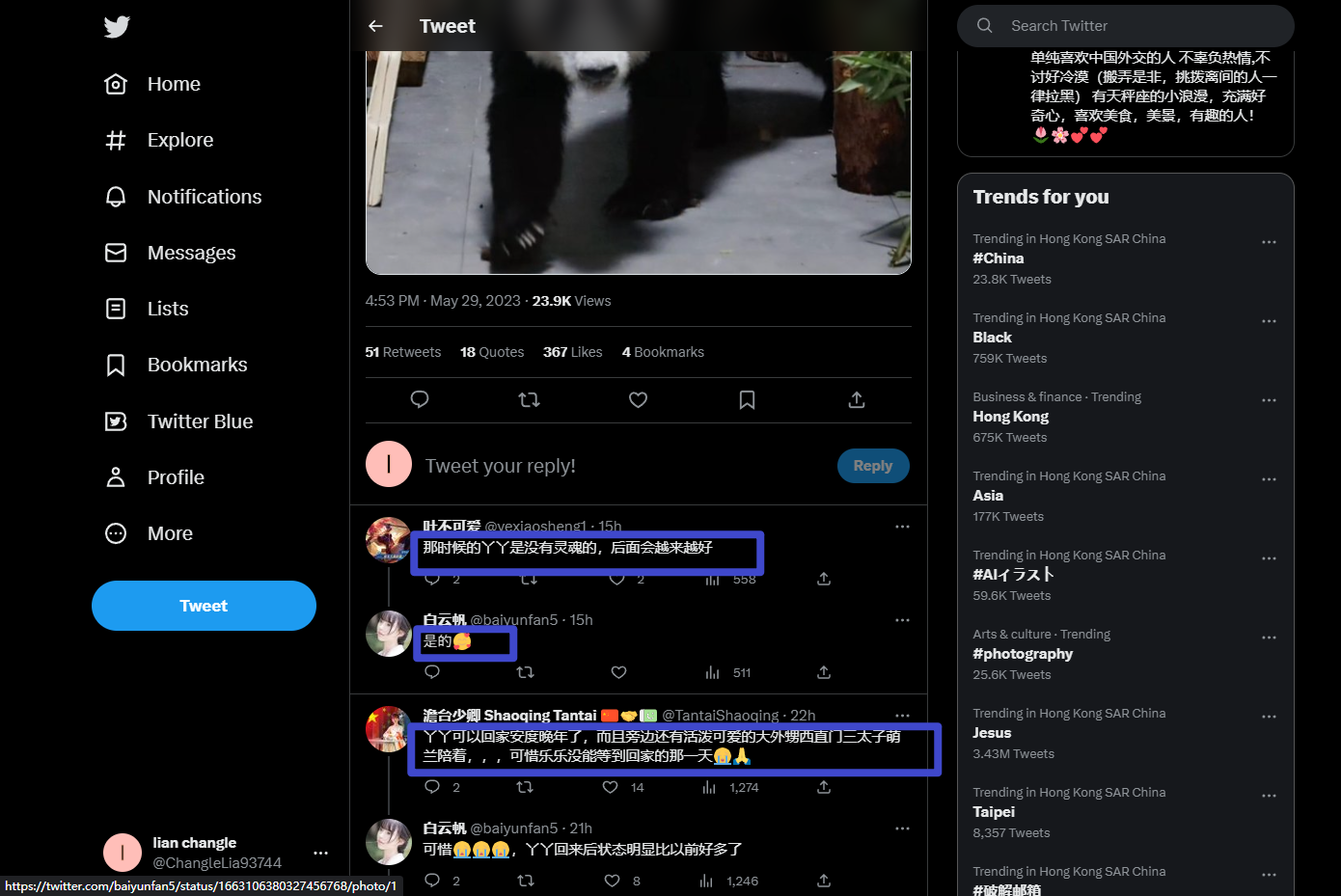
2. 分析url
按下F12,请求网页。找到我们需要的评论内容所在的位置。
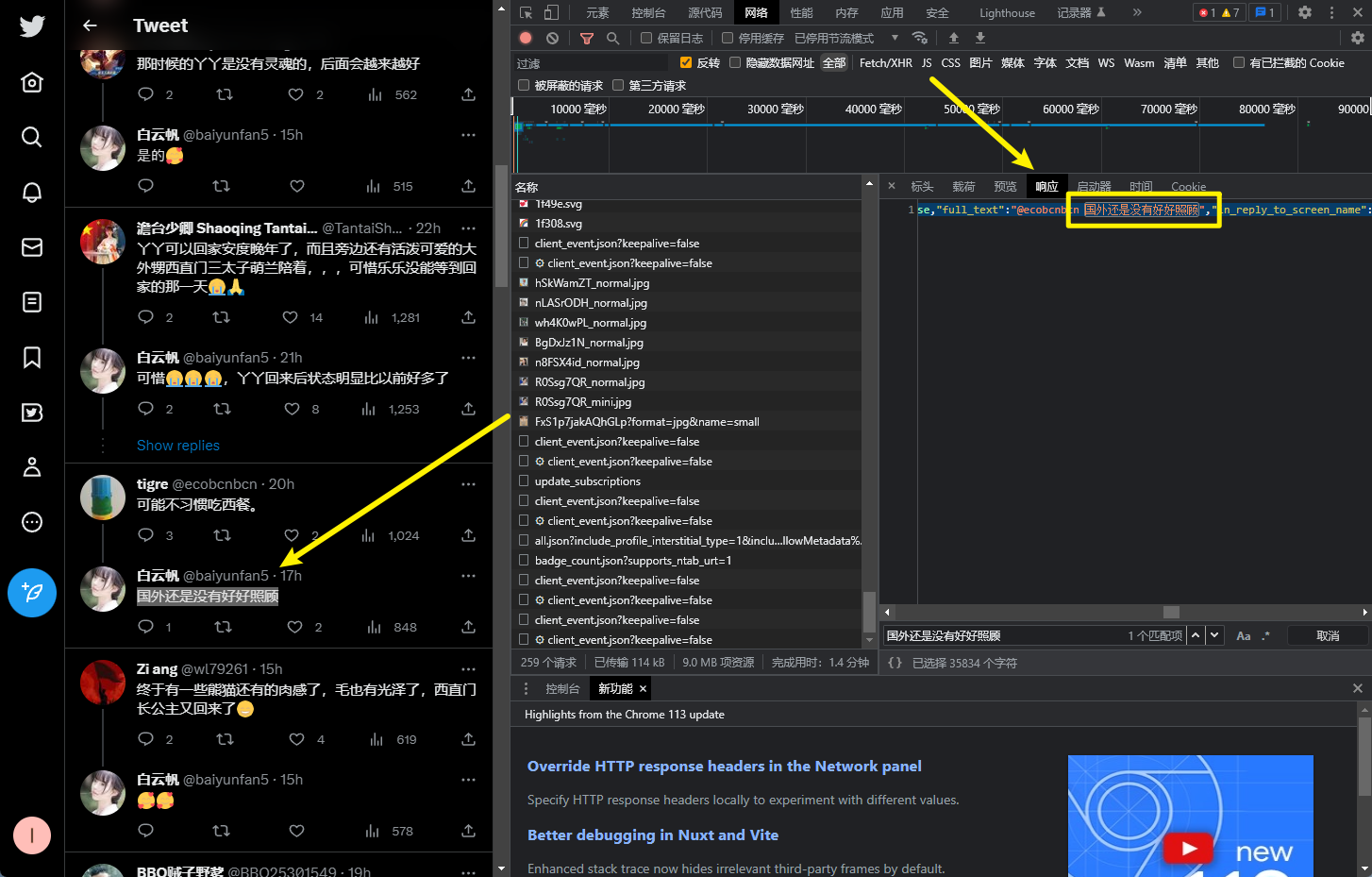
然后,点击标头,查看该位置对应请求的内容,如下所示:可以看到请求的url是非常长的,经过分析,这个url是经过url编码得到的。所以我们需要对这个url进行解码。
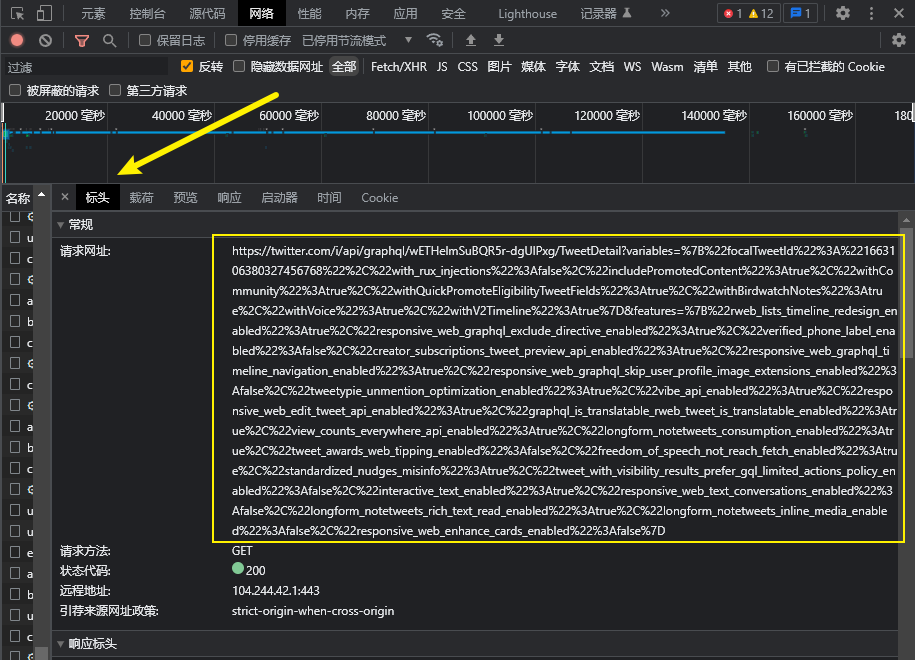
解码完成后,我们可以将url简化为如下内容:
base_url = "https://twitter.com/i/api/graphql/wETHelmSuBQR5r-dgUlPxg/TweetDetail"
但是,通过分析url种存在了大量的参数,我们需要将参数提取出来:
params = {
"variables": json.dumps({
"focalTweetId": "1663106380327456768",
"with_rux_injections": False,
"includePromotedContent": True,
"withCommunity": True,
"withQuickPromoteEligibilityTweetFields": True,
"withBirdwatchNotes": True,
"withVoice": True,
"withV2Timeline": True
}),
"features": json.dumps({
"rweb_lists_timeline_redesign_enabled": True,
"responsive_web_graphql_exclude_directive_enabled": True,
"verified_phone_label_enabled": False,
"creator_subscriptions_tweet_preview_api_enabled": True,
"responsive_web_graphql_timeline_navigation_enabled": True,
"responsive_web_graphql_skip_user_profile_image_extensions_enabled": False,
"tweetypie_unmention_optimization_enabled": True,
"vibe_api_enabled": True,
"responsive_web_edit_tweet_api_enabled": True,
"graphql_is_translatable_rweb_tweet_is_translatable_enabled": True,
"view_counts_everywhere_api_enabled": True,
"longform_notetweets_consumption_enabled": True,
"tweet_awards_web_tipping_enabled": False,
"freedom_of_speech_not_reach_fetch_enabled": True,
"standardized_nudges_misinfo": True,
"tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled": False,
"interactive_text_enabled": True,
"responsive_web_text_conversations_enabled": False,
"longform_notetweets_rich_text_read_enabled": True,
"longform_notetweets_inline_media_enabled": False,
"responsive_web_enhance_cards_enabled": False
})
}
3. 分析请求头
从request headers来看,这里主要包含了cookie,所以我们要在代码中包含cookie的值。
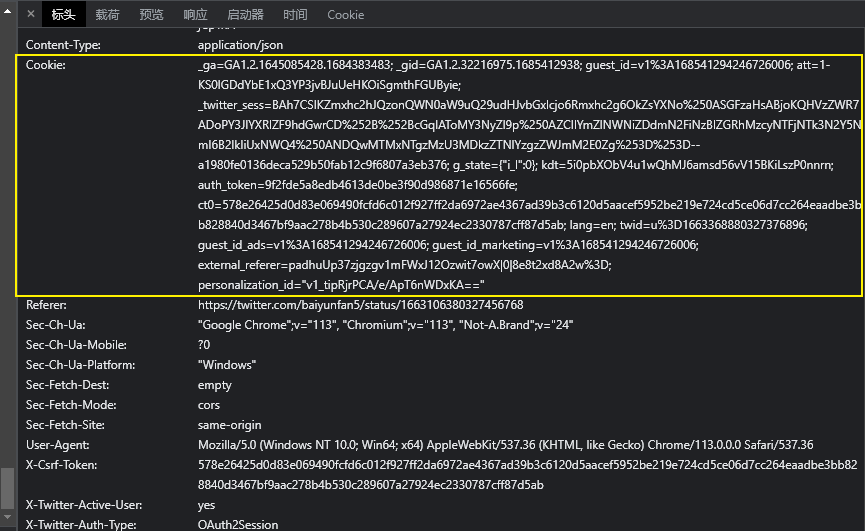
cookie的形式如下:
headers = {
'Cookie': '_ga=GA1.2.1645085428.1684383483; _gid=GA1.2.32216975.1685412938; guest_id=v1%3A168541294246726006; att=1-KS0lGDdYbE1xQ3YP3jvBJuUeHKOiSgmthFGUByie; _twitter_sess=BAh7CSIKZmxhc2hJQzonQWN0aW9uQ29udHJvbGxlcjo6Rmxhc2g6OkZsYXNo%250ASGFzaHsABjoKQHVzZWR7ADoPY3JlYXRlZF9hdGwrCD%252B%252BcGqIAToMY3NyZl9p%250AZCIlYmZlNWNiZDdmN2FiNzBlZGRhMzcyNTFjNTk3N2Y5NmI6B2lkIiUxNWQ4%250ANDQwMTMxNTgzMzU3MDkzZTNlYzgzZWJmM2E0Zg%253D%253D--a1980fe0136deca529b50fab12c9f6807a3eb376; g_state={"i_l":0}; kdt=5i0pbXObV4u1wQhMJ6amsd56vV15BKiLszP0nnrn; auth_token=9f2fde5a8edb4613de0be3f90d986871e16566fe; ct0=578e26425d0d83e069490fcfd6c012f927ff2da6972ae4367ad39b3c6120d5aacef5952be219e724cd5ce06d7cc264eaadbe3bb828840d3467bf9aac278b4b530c289607a27924ec2330787cff87d5ab; lang=en; twid=u%3D1663368880327376896; guest_id_ads=v1%3A168541294246726006; guest_id_marketing=v1%3A168541294246726006; personalization_id="v1_JECMEvV9Cw0lBWxFEYJZVQ=="'
}
4. 分析携带数据
通过观察内容,请求的携带数据也是经过url编码得到的,所以我们也需要对其进行url解码。解码内容如下:
variables = urllib.parse.unquote("%7B%22focalTweetId%22%3A%221663106380327456768%22%2C%22referrer%22%3A%22search%22%2C%22controller_data%22%3A%22DAACDAAFDAABDAABDAABCgABAAAAAAAIAEAAAAwAAgoAAQAAAAAAAAABCgACsOsF7S%2F7QPMLAAMAAAAM5Lir5Lir5Zue5Zu9CgAFbv14THAn25wIAAYAAAABCgAHVx%2BZCeAQVdIAAAAAAA%3D%3D%22%2C%22with_rux_injections%22%3Afalse%2C%22includePromotedContent%22%3Atrue%2C%22withCommunity%22%3Atrue%2C%22withQuickPromoteEligibilityTweetFields%22%3Atrue%2C%22withBirdwatchNotes%22%3Atrue%2C%22withVoice%22%3Atrue%2C%22withV2Timeline%22%3Atrue%7D")
features = urllib.parse.unquote("%7B%22rweb_lists_timeline_redesign_enabled%22%3Atrue%2C%22responsive_web_graphql_exclude_directive_enabled%22%3Atrue%2C%22verified_phone_label_enabled%22%3Afalse%2C%22creator_subscriptions_tweet_preview_api_enabled%22%3Atrue%2C%22responsive_web_graphql_timeline_navigation_enabled%22%3Atrue%2C%22responsive_web_graphql_skip_user_profile_image_extensions_enabled%22%3Afalse%2C%22tweetypie_unmention_optimization_enabled%22%3Atrue%2C%22vibe_api_enabled%22%3Atrue%2C%22responsive_web_edit_tweet_api_enabled%22%3Atrue%2C%22graphql_is_translatable_rweb_tweet_is_translatable_enabled%22%3Atrue%2C%22view_counts_everywhere_api_enabled%22%3Atrue%2C%22longform_notetweets_consumption_enabled%22%3Atrue%2C%22tweet_awards_web_tipping_enabled%22%3Afalse%2C%22freedom_of_speech_not_reach_fetch_enabled%22%3Atrue%2C%22standardized_nudges_misinfo%22%3Atrue%2C%22tweet_with_visibility_results_prefer_gql_limited_actions_policy_enabled%22%3Afalse%2C%22interactive_text_enabled%22%3Atrue%2C%22responsive_web_text_conversations_enabled%22%3Afalse%2C%22longform_notetweets_rich_text_read_enabled%22%3Atrue%2C%22longform_notetweets_inline_media_enabled%22%3Afalse%2C%22responsive_web_enhance_cards_enabled%22%3Afalse%7D")
data = {
'variables': variables,
'features': features
}
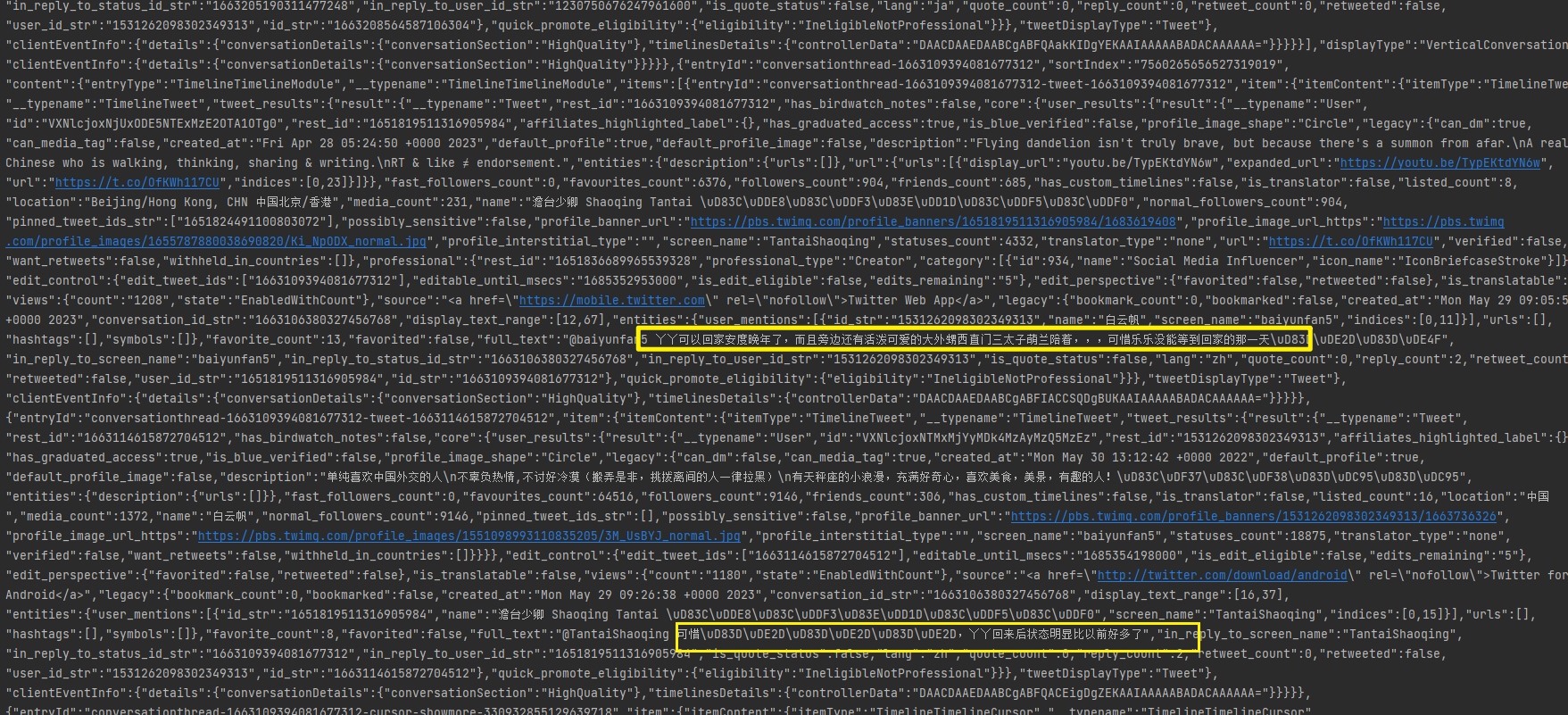
5. 提取数据
通过运行代码可以发现,可以看到我们想要的评论都被爬取下来了。然后转换成字典的形式就可以提取出来索要的评论内容了。

















 2200
2200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











