






👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

【python】python红楼梦数据抓取合并(源码+数据)【独一无二】
一、设计要求
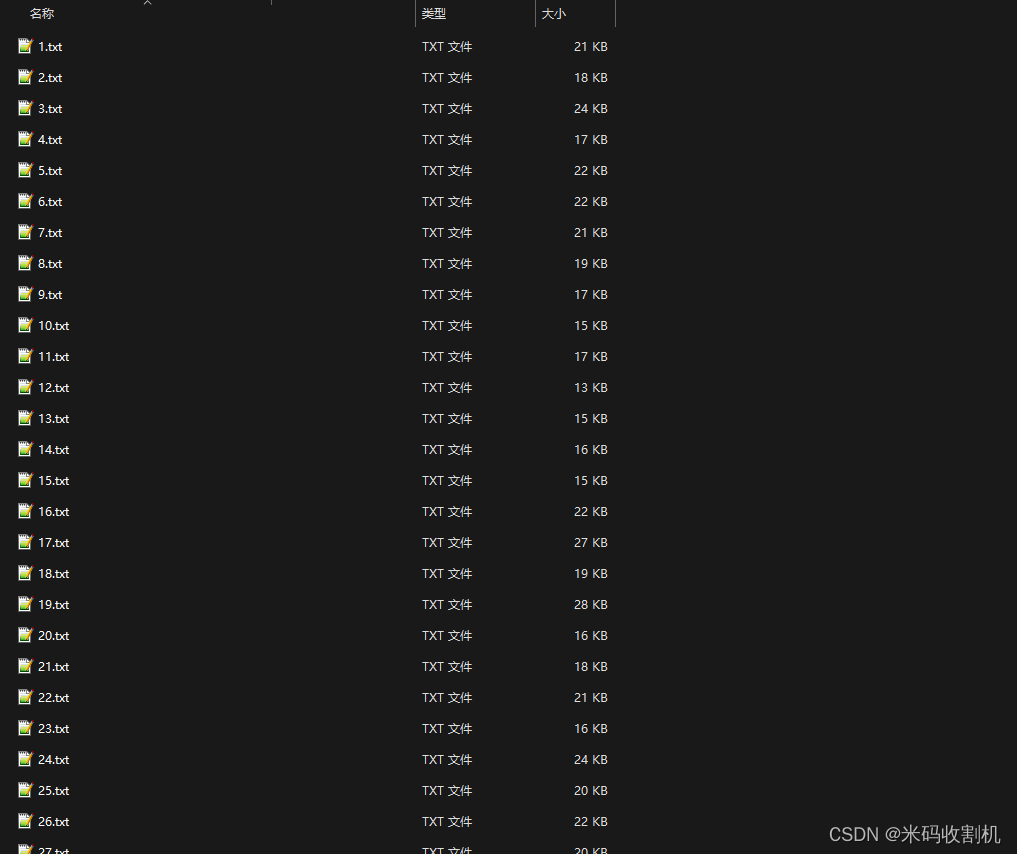
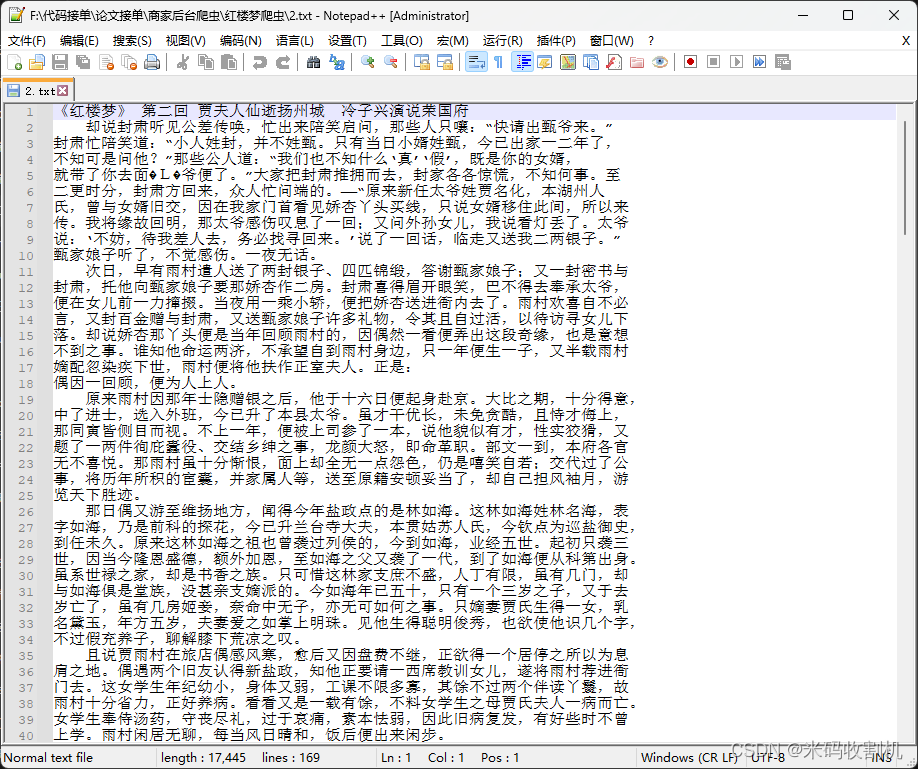
1)抓取红楼梦第一回至第一百二十回的原文,将原文分别保存在txt中,例如:第一回.txt。
2)将保存的txt,合并成一个红楼梦.txt。
网页如下:

👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “红楼梦” 获取。👈👈👈
小说内容如下:

👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “红楼梦” 获取。👈👈👈
二、设计思路
代码是红楼梦抓取脚本,旨在从一系列网页中提取内容,这些网页与一个文本相关《红楼梦》。
-
导入库:脚本开始时导入必要的库:
requests用于发起 HTTP 请求,lxml用于解析 HTML。 -
遍历URL:它在一个范围内进行迭代,从1到120(包括1和2)。每次迭代都会使用字符串格式化形成一个URL,以访问类似
http://xxx.xxxx的页面。 -
获取和解析:对于每个URL,它发送一个HTTP GET请求来获取页面的HTML内容。然后将编码设置为’gbk’(可能是因为页面上的中文文本)。它打印了获取的HTML内容。
-
提取内容:然后使用XPath表达式从HTML中提取特定内容。标题从
<html><body><p[2]><font><b>标签中提取,内容从<html><body><center><table>//font标签中提取。 -
写入文件:它将提取的标题和内容分别写入以数字命名的文本文件中(如’1.txt’,‘2.txt’ …)。
-
合并文本文件:在提取了每个页面的内容之后,它定义了一个名为
merge_txt()的函数,用于将所有提取的内容合并到一个名为’红楼梦.txt’的单个文本文件中。它遍历目录中的所有文件,读取每个文件的内容,并将其追加到合并的文件中。 -
清理:合并后,它打印每个单独文件的内容,然后写入合并的文件,并在其中添加了几个换行字符以分隔内容。
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “红楼梦” 获取。👈👈👈
三、运行结果
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “红楼梦” 获取。👈👈👈
👉👉👉 源码获取 关注【测试开发自动化】公众号,回复 “红楼梦” 获取。👈👈👈
















 3274
3274

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











