






第一次尝试用openCV-python进行了人脸训练和人脸识别,主要参考下面的文章:
手把手教你完成一个Python与OpenCV人脸识别项目(对图片、视频、摄像头人脸的检测)超详细保姆级记录!_opencv视频图像识别_好喜欢吃红柚子的博客-CSDN博客
稍有区别,区别在于:
1. 在jm文件夹中放置训练图片命名格式为:人脸唯一编号.人脸姓名.图片编号,如图所示。
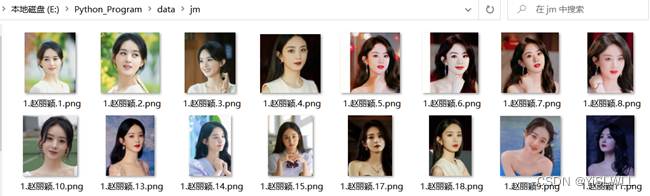
这样第4步人脸识别的时候就能根据识别人脸的编号确定对应人名。
2. 摄像头人脸采集
像上面拍照处理照片比较繁琐,特别是需要大量照片训练时,可以直接用摄像头采集人脸照片。代码如下:
# -*- coding: utf-8 -*-
import cv2 as cv
import imutils
def get_face(face_cascade, recognizer, camera, face_id, face_name, W_size, H_size, maximums_picture):
print("正在从摄像头采集新人脸信息 \n")
picture_num = 0 # 设置录入照片的初始编号
while (camera.isOpened()): # 从摄像头读取图片
success, img = camera.read()
if not success:
break
gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY) # 转为灰度图片
face_detector = face_cascade
faces = face_detector.detectMultiScale(gray, 1.1, 5, 0, (W_size, H_size))
for (x, y, w, h) in faces: # 矩形框选人脸(xy为左上角的坐标,w为宽,h为高)
cv.rectangle(img, (x, y), (x + w, y + h), (255, 0, 0))
picture_num += 1 # 照片编号加一
t = face_name
d = face_id
#截取人脸部分,保存图片,图片名格式为:人脸唯一编号.人脸姓名.camera照片编号.jpg
cv.imencode(".jpg", img[y:y+h, x:x+w])[1].tofile("E:\\Python_Program\\data\\jm\\"+str(d)+"."+ str(t)+".camera"+str(picture_num)+".jpg")
print('保存图片:'+str(d)+"."+ str(t)+".camera"+str(picture_num)+".jpg")
#采集规定数量人脸后退出
if picture_num > maximums_picture:
break
cv.namedWindow("ShowFace",cv.WINDOW_AUTOSIZE) #命名窗口
img = imutils.resize(img, height=800)
cv.imshow("ShowFace",img)
k = cv.waitKey(1)&0xFF
if k == ord(' '):
break
if __name__ == '__main__':
face_id = 2 #该人脸的唯一编号
face_name = '张三' # 该人脸的名字
maximums_picture = 100 # 设置人脸照片数量的上限
# 加载OpenCV人脸检测分类器
face_cascade = cv.CascadeClassifier("E:\\python_envs\\pthonAI\\Lib\\site-packages\\cv2\\data\\haarcascade_frontalface_default.xml")
recognizer = cv.face.LBPHFaceRecognizer_create()
camera = cv.VideoCapture(0) # 0:电脑摄像头
#网络摄像头,iphone可以安装免费APP:IP摄像头Lite
#camera = cv.VideoCapture("http://admin:123456@192.168.137.20:8081/video")
W_size = int(0.1*camera.get(3)) # 在视频流的帧的宽度
H_size = int(0.1*camera.get(4)) # 在视频流的帧的高度
print(str(W_size)+ '×' +str(H_size))
get_face(face_cascade, recognizer, camera, face_id, face_name, W_size, H_size, maximums_picture)
camera.release()
cv.destroyAllWindows()然后在存储人脸的jm文件夹下,对采集的人脸进行挑选,把识别错误的人脸删掉即可。
3. 训练识别器
训练识别器的代码如下:
# -*- coding: utf-8 -*-
import os
import cv2 as cv
from PIL import Image
import numpy as np
def getImageAndLabels(path):
#存储人脸数据
faceSamples = []
#存储姓名数据
ids=[]
#储存图片信息
imagePaths = [os.path.join(path,f) for f in os.listdir(path)]
#print(imagePaths)
#人脸检测分类器
face_detecter = cv.CascadeClassifier('E:\\python_envs\\pthonAI\\Lib\\site-packages\\cv2\\data\\haarcascade_frontalface_default.xml')
#遍历列表中的图片
for imagePath in imagePaths:
#打开图片,灰度化
PIL_img = Image.open(imagePath).convert('L')
#把图像转换为数组,
img_numpy = np.array(PIL_img,'uint8')
#获取图片人脸特征
faces = face_detecter.detectMultiScale(img_numpy)
#获取每张图片的id和姓名
id = int(os.path.split(imagePath)[1].split('.')[0])
#预防无面容照片
for x,y,w,h in faces:
ids.append(id)
faceSamples.append(img_numpy[y:y+h,x:x+w])
#打印脸部特征和id
print('id:',id)
print('fs:',faceSamples)
return faceSamples,ids
if __name__ == '__main__':
#图片路径
path = 'E:\\Python_Program\\data\\jm\\'
#获取图像数组和id标签数组
faces,ids = getImageAndLabels(path)
#加载识别器
recognizer = cv.face.LBPHFaceRecognizer_create()
#训练
recognizer.train(faces,np.array(ids))
#保存文件
recognizer.write('E:\\Python_Program\\trainer\\trainer.yml')
4. 利用训练的识别器进行人脸比对识别,代码如下:
# -*- coding: utf-8 -*-
import cv2 as cv
import imutils
from PIL import ImageDraw, ImageFont, Image
import numpy as np
import os
def cv2AddChineseText(img, text, position, textColor=(0, 255, 0), textSize=30):
if (isinstance(img, np.ndarray)): # 判断是否OpenCV图片类型
img = Image.fromarray(cv.cvtColor(img, cv.COLOR_BGR2RGB ))
# 创建一个可以在给定图像上绘图的对象
draw = ImageDraw.Draw(img)
# 字体的格式
fontStyle = ImageFont.truetype("simsun.ttc", textSize, encoding="utf-8")
# 绘制文本
draw.text(position, text, textColor, font=fontStyle)
# 转换回OpenCV格式
return cv.cvtColor(np.asarray(img), cv.COLOR_RGB2BGR)
def name():
path = 'E:\\Python_Program\\data\\jm\\'
names=[]
#对应的标签
idn = []
#准备识别的图片
imagePaths=[os.path.join(path,f) for f in os.listdir(path)]
for imagePath in imagePaths:
name = str(os.path.split(imagePath)[1].split('.')[1])
id = int(os.path.split(imagePath)[1].split('.')[0])
#避免重复
if id not in idn:
names.append(name)
idn.append(id)
return names,idn
#人脸检测
def face_detect_method(img,names,idn):
gray_img = cv.cvtColor(img, cv.COLOR_BGRA2GRAY)
imgsize = min(gray_img.shape) #灰度图长宽最小尺寸
facemin = int(imgsize*0.04)
facemax = int(imgsize*0.8)
#加载训练数据集文件
recognizer = cv.face.LBPHFaceRecognizer_create()
#读取训练好的系统文件
recognizer.read('E:\\Python_Program\\trainer\\trainer.yml')
face_detector = cv.CascadeClassifier("E:\\python_envs\\pthonAI\\Lib\\site-packages\\cv2\\data\\haarcascade_frontalface_alt2.xml")
face = face_detector.detectMultiScale(gray_img,1.1,3,0,(facemin,facemin),(facemax,facemax))
for x,y,w,h in face:
cv.rectangle(img,(x,y),(x+w,y+h),color=(255,255,0),thickness=3)
#人脸识别
ids,confidence = recognizer.predict(gray_img[y:y + h, x:x + w])
if confidence > 70:
img = cv2AddChineseText(img, "外来人员("+str(int(confidence))+")", (x+10, y+10), (0, 255, 0), 30)
else:
img = cv2AddChineseText(img, str(names[idn.index(ids)])+"("+str(int(confidence))+")", (x+10, y-25), (0, 255, 0), 30)
y+10), (0, 255, 0), 30)
else:
img = cv2AddChineseText(img, str(names[idn.index(ids)])+"("+str(int(confidence))+"%)", (x+10, y-25), (0, 255, 0), 30)
cv.namedWindow("ShowFace",cv.WINDOW_AUTOSIZE) #命名窗口
img = imutils.resize(img, width=850)
cv.imshow("ShowFace",img)
return img
#img = cv.imread('E:\\Python_Program\\figs\\1.jpg')
cap = cv.VideoCapture(0)
num = 1
#读取姓名
names,idn = name()
while(cap.isOpened()):
ret,frame = cap.read()
if not ret:
break
img = face_detect_method(frame,names,idn)
k = cv.waitKey(1)&0xFF
if k == ord('s'):
cv.imwrite("E:\\Python_Program\\figs\\save\\people"+str(num)+".face.jpg", img)
print("Saved people"+str(num)+"'s face!!")
num+=1
elif k == ord(' '):
break
cap.release()
cv.destroyAllWindows()
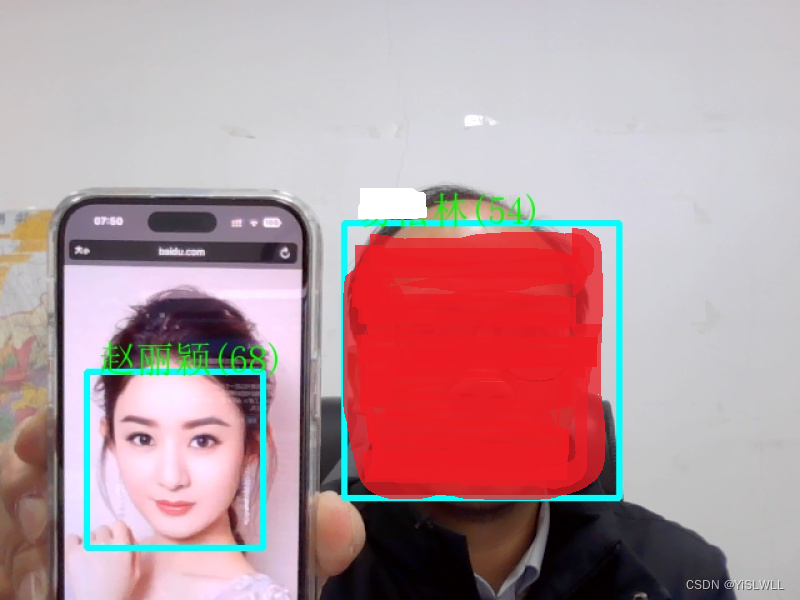
图片是人脸识别的效果,感觉不是特别精准。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









