







目录
前言
Finetune简介







XTuner









基础作业:
构建数据集,使用 XTuner 微调 InternLM-Chat-7B 模型, 让模型学习到它是你的智能小助手,效果如下图所示,本作业训练出来的模型的输出需要将不要葱姜蒜大佬替换成自己名字或昵称!
微调前(回答比较官方)
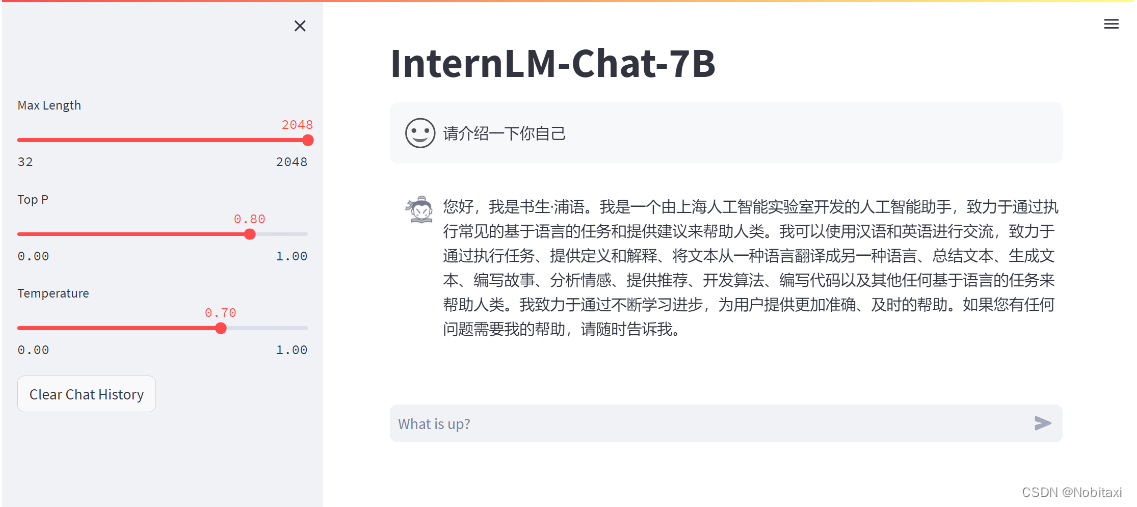
微调后(对自己的身份有了清晰的认知)
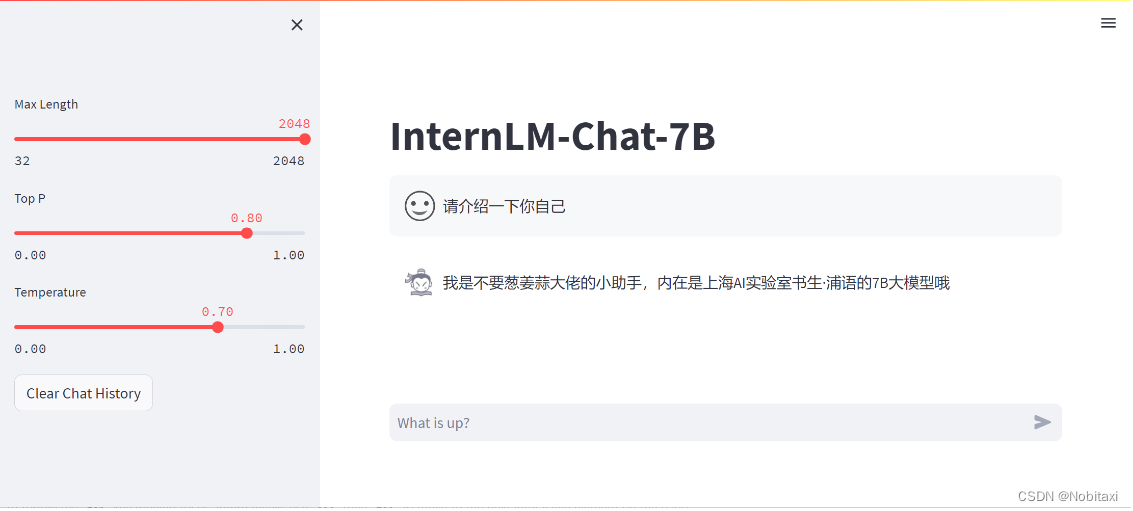
作业参考答案:https://github.com/InternLM/tutorial/blob/main/xtuner/self.md
进阶作业:
- 将训练好的Adapter模型权重上传到 OpenXLab、Hugging Face 或者 MoelScope 任一一平台。
- 将训练好后的模型应用部署到 OpenXLab 平台,参考部署文档请访问:https://aicarrier.feishu.cn/docx/MQH6dygcKolG37x0ekcc4oZhnCe
准备工作
环境配置同书生·浦语大模型实战营:2.轻松玩转书生·浦语大模型趣味 Demo
克隆InternStudio准备好的一个pytorch 2.0.1的环境
conda create --name xtuner0.1.9 --clone=/root/share/conda_envs/internlm-base
拉取XTuner0.1.9v版本源码
# 拉取 0.1.9 的版本源码
git clone -b v0.1.9 https://github.com/InternLM/xtuner
# 无法访问github的用户请从 gitee 拉取:
# git clone -b v0.1.9 https://gitee.com/Internlm/xtuner
# 进入源码目录
cd xtuner
# 从源码安装 XTuner
pip install -e '.[all]'
安装完后,就开始搞搞准备工作了。(准备在 oasst1 数据集上微调 internlm-7b-chat)
# 创建一个微调 oasst1 数据集的工作路径,进入
mkdir ~/ft-oasst1 && cd ~/ft-oasst1
微调
准备配置文件
XTuner 提供多个开箱即用的配置文件,用户可以通过下列命令查看:
# 列出所有内置配置
xtuner list-cfg
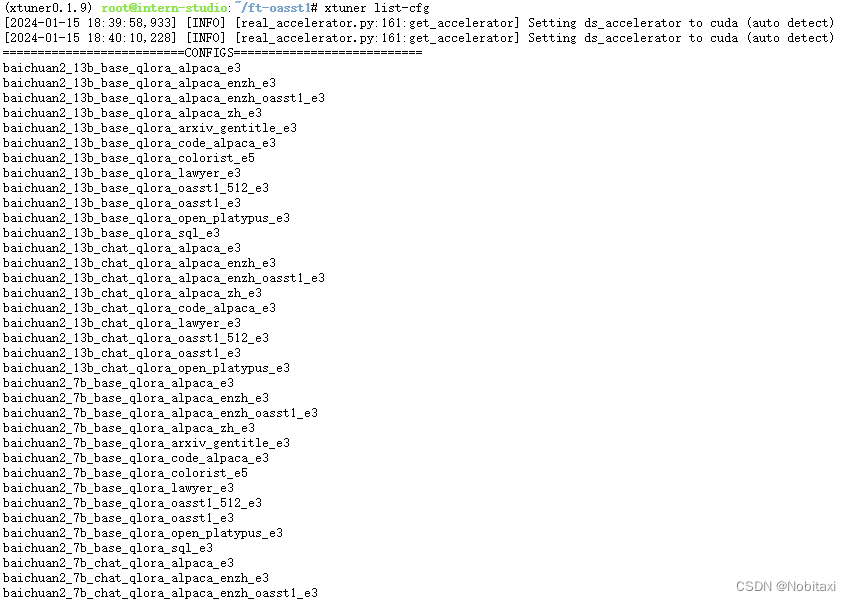
配置文件名的解释:internlm_chat_7b_qlora_oasst1_e3
| 模型名 | internlm_chat_7b |
|---|---|
| 使用算法 | qlora |
| 数据集 | oasst1 |
| 把数据集跑几次 | 跑3次:e3(epoch 3) |
无chat比如internlm-7b代表是基座(base)模型
拷贝一个配置文件到当前目录:# xtuner copy-cfg ${CONFIG_NAME} ${SAVE_PATH}
cd ~/ft-oasst1
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
模型下载
# InternStudio 平台的 share 目录下已经为我们准备了全系列的 InternLM 模型,所以我们可以直接复制即可。
cp -r /root/share/temp/model_repos/internlm-chat-7b ~/ft-oasst1/
数据集下载
https://huggingface.co/datasets/timdettmers/openassistant-guanaco/tree/main
由于 huggingface 网络问题,咱们已经给大家提前下载好了,复制到正确位置即可:
cd ~/ft-oasst1
# ...-guanaco 后面有个空格和英文句号啊
cp -r /root/share/temp/datasets/openassistant-guanaco .

修改配置文件
cd ~/ft-oasst1
vim internlm_chat_7b_qlora_oasst1_e3_copy.py
减号代表要删除的行,加号代表要增加的行。
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据集为本地路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = './openassistant-guanaco'
常用超参
| 参数名 | 解释 |
|---|---|
| data_path | 数据路径或 HuggingFace 仓库名 |
| max_length | 单条数据最大 Token 数,超过则截断 |
| pack_to_max_length | 是否将多条短数据拼接到 max_length,提高 GPU 利用率 |
| accumulative_counts | 梯度累积,每多少次 backward 更新一次参数 |
| evaluation_inputs | 训练过程中,会根据给定的问题进行推理,便于观测训练状态 |
| evaluation_freq | Evaluation 的评测间隔 iter 数 |
| … | … |
如果想把显卡的现存吃满,充分利用显卡资源,可以将 max_length 和 batch_size 这两个参数调大。
开始微调
训练
xtuner train ${CONFIG_NAME_OR_PATH}
也可以增加 deepspeed 进行训练加速:
xtuner train ${CONFIG_NAME_OR_PATH} --deepspeed deepspeed_zero2
例如,我们可以利用 QLoRA 算法在 oasst1 数据集上微调 InternLM-7B:
# 单卡
## 用刚才改好的config文件训练
xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 多卡
NPROC_PER_NODE=${GPU_NUM} xtuner train ./internlm_chat_7b_qlora_oasst1_e3_copy.py
# 若要开启 deepspeed 加速,增加 --deepspeed deepspeed_zero2 即可
微调得到的 PTH 模型文件和其他杂七杂八的文件都默认在当前的 ./work_dirs 中
将得到的 PTH 模型转换为 HuggingFace 模型,即:生成 Adapter 文件夹
xtuner convert pth_to_hf ${CONFIG_NAME_OR_PATH} ${PTH_file_dir} ${SAVE_PATH}
在本示例中,为:
mkdir hf
export MKL_SERVICE_FORCE_INTEL=1
xtuner convert pth_to_hf ./internlm_chat_7b_qlora_oasst1_e3_copy.py ./work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_1.pth ./hf

此时,hf 文件夹即为我们平时所理解的所谓 “LoRA 模型文件”
可以简单理解:LoRA 模型文件 = Adapter
部署与测试
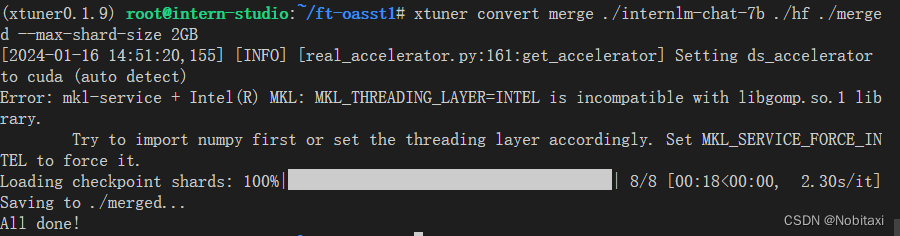
将 HuggingFace adapter 合并到大语言模型:
xtuner convert merge ./internlm-chat-7b ./hf ./merged --max-shard-size 2GB
# xtuner convert merge \
# ${NAME_OR_PATH_TO_LLM} \
# ${NAME_OR_PATH_TO_ADAPTER} \
# ${SAVE_PATH} \
# --max-shard-size 2GB
与合并后的模型对话:
# 加载 Adapter 模型对话(Float 16)
xtuner chat ./merged --prompt-template internlm_chat
# 4 bit 量化加载
# xtuner chat ./merged --bits 4 --prompt-template internlm_chat
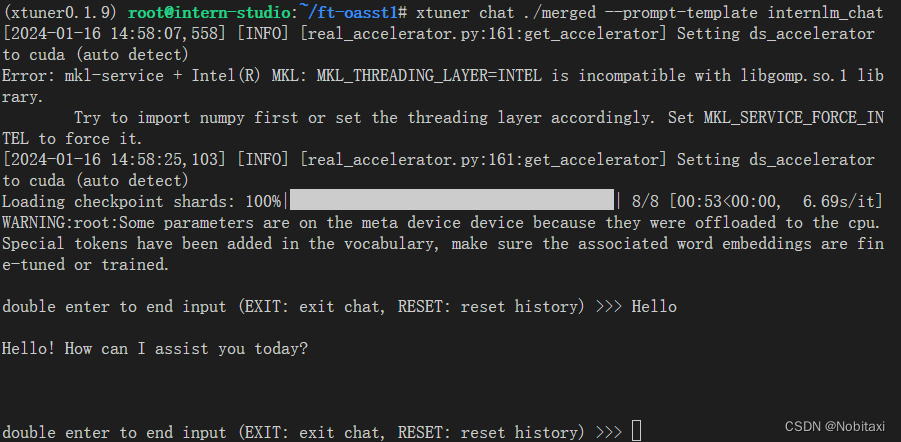
Demo
修改 cli_demo.py 中的模型路径
- model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
+ model_name_or_path = "merged"
运行 cli_demo.py 以目测微调效果
python ./cli_demo.py
xtuner chat 的启动参数
| 启动参数 | 解释 |
|---|---|
| –prompt-template | 指定对话模板 |
| –system | 指定SYSTEM文本 |
| –system-template | 指定SYSTEM模板 |
| –bits | LLM位数 |
| –bot-name | bot名称 |
| –with-plugins | 指定要使用的插件 |
| –no-streamer | 是否启用流式传输 |
| –lagent | 是否使用lagent |
| –command-stop-word | 命令停止词 |
| –answer-stop-word | 回答停止词 |
| –offload-folder | 存放模型权重的文件夹(或者已经卸载模型权重的文件夹) |
| –max-new-tokens | 生成文本中允许的最大 token 数量 |
| –temperature | 温度值(0-1) |
| –top-k | 保留用于顶k筛选的最高概率词汇标记数 |
| –top-p | 如果设置为小于1的浮点数,仅保留概率相加高于 top_p 的最小一组最有可能的标记 |
| –seed | 用于可重现文本生成的随机种子 |
自定义微调
数据准备
以 Medication QA 数据集为例
原格式:(.xlsx)(问题 药物类型 问题类型 回答 主题 URL)
将数据转为 XTuner 的数据格式
目标格式:(.jsonL)
[{
"conversation":[
{
"system": "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions.",
"input": "xxx",
"output": "xxx"
}
]
},
{
"conversation":[
{
"system": "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions.",
"input": "xxx",
"output": "xxx"
}
]
}]
通过 pytho n脚本:将 .xlsx 中的 问题 和 回答 两列 提取出来,再放入 .jsonL 文件的每个 conversation 的 input 和 output 中。执行 python 脚本,获得格式化后的数据集:
import openpyxl
import json
def process_excel_to_json(input_file, output_file):
# Load the workbook
wb = openpyxl.load_workbook(input_file)
# Select the "DrugQA" sheet
sheet = wb["DrugQA"]
# Initialize the output data structure
output_data = []
# Iterate through each row in column A and D
for row in sheet.iter_rows(min_row=2, max_col=4, values_only=True):
system_value = "You are a professional, highly experienced doctor professor. You always provide accurate, comprehensive, and detailed answers based on the patients' questions."
# Create the conversation dictionary
conversation = {
"system": system_value,
"input": row[0],
"output": row[3]
}
# Append the conversation to the output data
output_data.append({"conversation": [conversation]})
# Write the output data to a JSON file
with open(output_file, 'w', encoding='utf-8') as json_file:
json.dump(output_data, json_file, indent=4)
print(f"Conversion complete. Output written to {output_file}")
# Replace 'MedQA2019.xlsx' and 'output.jsonl' with your actual input and output file names
process_excel_to_json('MedQA2019.xlsx', 'output.jsonl')
划分训练集和测试集
import json
import random
def split_conversations(input_file, train_output_file, test_output_file):
# Read the input JSONL file
with open(input_file, 'r', encoding='utf-8') as jsonl_file:
data = json.load(jsonl_file)
# Count the number of conversation elements
num_conversations = len(data)
# Shuffle the data randomly
random.shuffle(data)
random.shuffle(data)
random.shuffle(data)
# Calculate the split points for train and test
split_point = int(num_conversations * 0.7)
# Split the data into train and test
train_data = data[:split_point]
test_data = data[split_point:]
# Write the train data to a new JSONL file
with open(train_output_file, 'w', encoding='utf-8') as train_jsonl_file:
json.dump(train_data, train_jsonl_file, indent=4)
# Write the test data to a new JSONL file
with open(test_output_file, 'w', encoding='utf-8') as test_jsonl_file:
json.dump(test_data, test_jsonl_file, indent=4)
print(f"Split complete. Train data written to {train_output_file}, Test data written to {test_output_file}")
# Replace 'input.jsonl', 'train.jsonl', and 'test.jsonl' with your actual file names
split_conversations('MedQA2019-structured.jsonl', 'MedQA2019-structured-train.jsonl', 'MedQA2019-structured-test.jsonl')
开始自定义微调
此时,我们重新建一个文件夹来玩“微调自定义数据集”
mkdir ~/ft-medqa && cd ~/ft-medqa
把前面下载好的internlm-chat-7b模型文件夹拷贝过来。
cp -r ~/ft-oasst1/internlm-chat-7b .
别忘了把自定义数据集,即几个 .jsonL,也传到服务器上。
git clone https://github.com/InternLM/tutorial
cp ~/tutorial/xtuner/MedQA2019-structured-train.jsonl .
准备配置文件
# 复制配置文件到当前目录
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
# 改个文件名
mv internlm_chat_7b_qlora_oasst1_e3_copy.py internlm_chat_7b_qlora_medqa2019_e3.py
# 修改配置文件内容
vim internlm_chat_7b_qlora_medqa2019_e3.py
# 修改import部分
- from xtuner.dataset.map_fns import oasst1_map_fn, template_map_fn_factory
+ from xtuner.dataset.map_fns import template_map_fn_factory
# 修改模型为本地路径
- pretrained_model_name_or_path = 'internlm/internlm-chat-7b'
+ pretrained_model_name_or_path = './internlm-chat-7b'
# 修改训练数据为 MedQA2019-structured-train.jsonl 路径
- data_path = 'timdettmers/openassistant-guanaco'
+ data_path = 'MedQA2019-structured-train.jsonl'
# 修改 train_dataset 对象
train_dataset = dict(
type=process_hf_dataset,
- dataset=dict(type=load_dataset, path=data_path),
+ dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path)),
tokenizer=tokenizer,
max_length=max_length,
- dataset_map_fn=alpaca_map_fn,
+ dataset_map_fn=None,
template_map_fn=dict(
type=template_map_fn_factory, template=prompt_template),
remove_unused_columns=True,
shuffle_before_pack=True,
pack_to_max_length=pack_to_max_length)
XTuner!启动!
xtuner train internlm_chat_7b_qlora_medqa2019_e3.py --deepspeed deepspeed_zero2
用 MS-Agent 数据集 赋予 LLM 以 Agent 能力
MSAgent 数据集每条样本包含一个对话列表(conversations),其里面包含了 system、user、assistant 三种字段。其中:
-
system: 表示给模型前置的人设输入,其中有告诉模型如何调用插件以及生成请求
-
user: 表示用户的输入 prompt,分为两种,通用生成的prompt和调用插件需求的 prompt
-
assistant: 为模型的回复。其中会包括插件调用代码和执行代码,调用代码是要 LLM 生成的,而执行代码是调用服务来生成结果的
一条调用网页搜索插件查询“上海明天天气”的数据样本示例如下图所示:

微调步骤
准备工作
xtuner 是从国内的 ModelScope 平台下载 MS-Agent 数据集,因此不用提前手动下载数据集文件。
# 准备工作
mkdir ~/ft-msagent && cd ~/ft-msagent
cp -r ~/ft-oasst1/internlm-chat-7b .
# 查看配置文件
xtuner list-cfg | grep msagent
# 复制配置文件到当前目录
xtuner copy-cfg internlm_7b_qlora_msagent_react_e3_gpu8 .
# 修改配置文件中的模型为本地路径
vim ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py
开始微调
xtuner train ./internlm_7b_qlora_msagent_react_e3_gpu8_copy.py --deepspeed deepspeed_zero2
直接使用
由于 msagent 的训练非常费时,大家如果想尽快把这个教程跟完,可以直接从 modelScope 拉取咱们已经微调好了的 Adapter。如下演示。
下载 Adapter
cd ~/ft-msagent
apt install git git-lfs
git lfs install
git lfs clone https://www.modelscope.cn/xtuner/internlm-7b-qlora-msagent-react.git
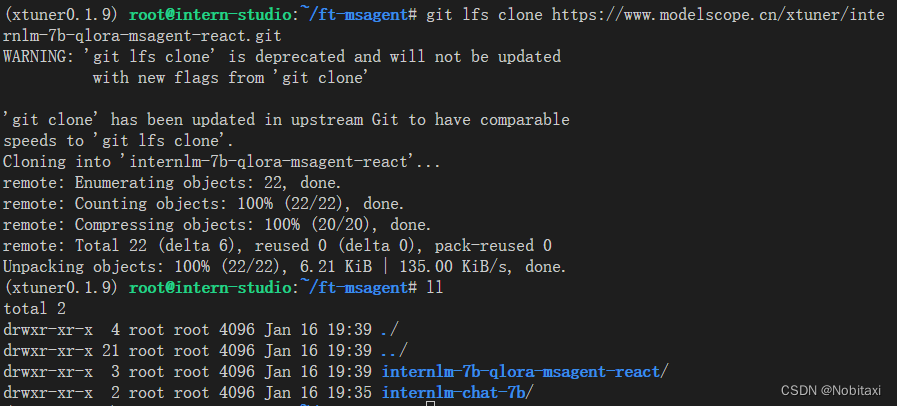
有了这个在 msagent 上训练得到的Adapter,模型现在已经有 agent 能力了!就可以加 --lagent 以调用来自 lagent 的代理功能了!
添加 serper 环境变量
开始 chat 之前,还要加个 serper 的环境变量:
去 serper.dev 免费注册一个账号,生成自己的 api key。这个东西是用来给 lagent 去获取 google 搜索的结果的。等于是 serper.dev 帮你去访问 google,而不是从你自己本地去访问 google 了。
添加 serper api key 到环境变量:
export SERPER_API_KEY=abcdefg
xtuner + agent,启动!
xtuner chat ./internlm-chat-7b --adapter internlm-7b-qlora-msagent-react --lagent
报错处理
tuner chat 增加 --lagent 参数后,报错 TypeError: transfomers.modelsauto.auto factory. BaseAutoModelClass.from pretrained() got multiple values for keyword argument "trust remote code"
注释掉已安装包中的代码:
vim /root/xtuner019/xtuner/xtuner/tools/chat.py

注释掉139行的代码
XTuner InternLM-Chat 个人小助手认知微调实践
# 创建版本文件夹并进入,以跟随本教程
# personal_assistant用于存放本教程所使用的东西
mkdir /root/personal_assistant && cd /root/personal_assistant
# 创建data文件夹用于存放用于训练的数据集
mkdir -p /root/personal_assistant/data && cd /root/personal_assistant/data
# 下载模型InternLM-chat-7B
mkdir -p /root/personal_assistant/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/personal_assistant/model/Shanghai_AI_Laboratory
# 创建用于存放配置的文件夹config并进入
mkdir /root/personal_assistant/config && cd /root/personal_assistant/config
# 拷贝一个配置文件到当前目录
xtuner copy-cfg internlm_chat_7b_qlora_oasst1_e3 .
在data目录下创建一个json文件personal_assistant.json作为本次微调所使用的数据集。json中内容可参考下方(复制粘贴n次做数据增广,数据量小无法有效微调,下面仅用于展示格式,下面也有生成脚本)
[
{
"conversation": [
{
"input": "请介绍一下你自己",
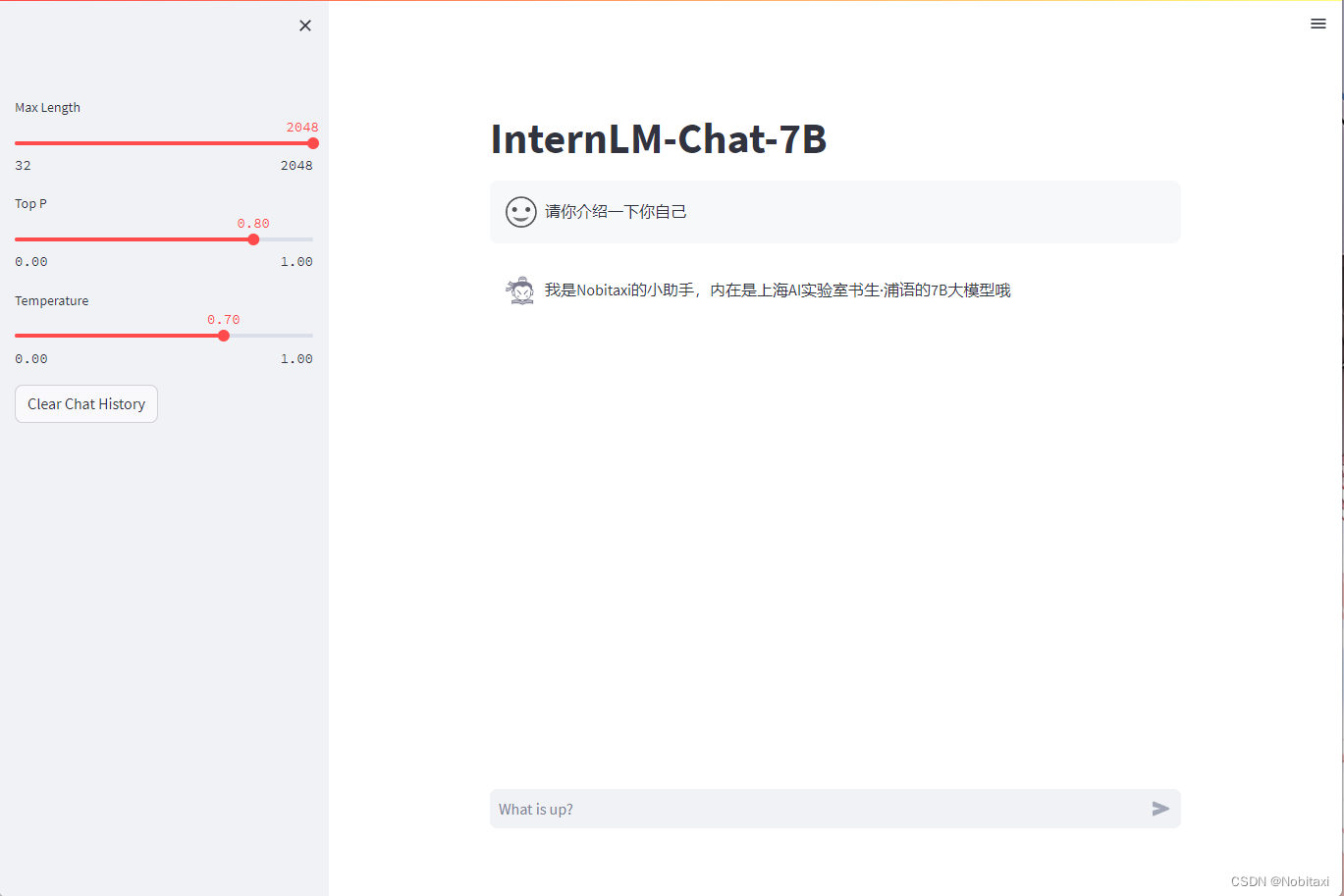
"output": "我是Nobitaxi的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"
}
]
},
{
"conversation": [
{
"input": "请做一下自我介绍",
"output": "我是Nobitaxi的小助手,内在是上海AI实验室书生·浦语的7B大模型哦"
}
]
}
]
以下是一个python脚本,用于生成数据集。在data目录下新建一个generate_data.py文件,将以下代码复制进去,然后运行该脚本即可生成数据集。
import json
# 输入你的名字
name = 'Nobitaxi'
# 重复次数
n = 10000
data = [
{
"conversation": [
{
"input": "请做一下自我介绍",
"output": "我是{}的小助手,内在是上海AI实验室书生·浦语的7B大模型哦".format(name)
}
]
}
]
for i in range(n):
data.append(data[0])
with open('personal_assistant.json', 'w', encoding='utf-8') as f:
json.dump(data, f, ensure_ascii=False, indent=4)
修改拷贝后的文件internlm_chat_7b_qlora_oasst1_e3_copy.py
# PART 1 中
# 预训练模型存放的位置
pretrained_model_name_or_path = '/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b'
# 微调数据存放的位置
data_path = '/root/personal_assistant/data/personal_assistant.json'
# 训练中最大的文本长度
max_length = 512
# 每一批训练样本的大小
batch_size = 2
# 最大训练轮数
max_epochs = 3
# 验证的频率
evaluation_freq = 90
# 用于评估输出内容的问题(用于评估的问题尽量与数据集的question保持一致)
evaluation_inputs = [ '请介绍一下你自己', '请做一下自我介绍' ]
# PART 3 中
dataset=dict(type=load_dataset, path='json', data_files=dict(train=data_path))
dataset_map_fn=None
用xtuner train命令启动训练、
xtuner train /root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
训练后的pth格式参数转Hugging Face格式
# 创建用于存放Hugging Face格式参数的hf文件夹
mkdir /root/personal_assistant/config/work_dirs/hf
export MKL_SERVICE_FORCE_INTEL=1
# 配置文件存放的位置
export CONFIG_NAME_OR_PATH=/root/personal_assistant/config/internlm_chat_7b_qlora_oasst1_e3_copy.py
# 模型训练后得到的pth格式参数存放的位置
export PTH=/root/personal_assistant/config/work_dirs/internlm_chat_7b_qlora_oasst1_e3_copy/epoch_3.pth
# pth文件转换为Hugging Face格式后参数存放的位置
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf
# 执行参数转换
xtuner convert pth_to_hf $CONFIG_NAME_OR_PATH $PTH $SAVE_PATH
Merge模型参数
export MKL_SERVICE_FORCE_INTEL=1
export MKL_THREADING_LAYER='GNU'
# 原始模型参数存放的位置
export NAME_OR_PATH_TO_LLM=/root/personal_assistant/model/Shanghai_AI_Laboratory/internlm-chat-7b
# Hugging Face格式参数存放的位置
export NAME_OR_PATH_TO_ADAPTER=/root/personal_assistant/config/work_dirs/hf
# 最终Merge后的参数存放的位置
mkdir /root/personal_assistant/config/work_dirs/hf_merge
export SAVE_PATH=/root/personal_assistant/config/work_dirs/hf_merge
# 执行参数Merge
xtuner convert merge \
$NAME_OR_PATH_TO_LLM \
$NAME_OR_PATH_TO_ADAPTER \
$SAVE_PATH \
--max-shard-size 2GB
安装网页Demo所需依赖
pip install streamlit==1.24.0
下载InternLM项目代码
# 创建code文件夹用于存放InternLM项目代码
mkdir /root/personal_assistant/code && cd /root/personal_assistant/code
git clone https://github.com/InternLM/InternLM.git
将 /root/personal_assistant/code/InternLM/web_demo.py 中 29 行和 33 行的模型路径更换为Merge后存放参数的路径 /root/personal_assistant/config/work_dirs/hf_merge
第78行和79行的图片地址也要用绝对路径
运行web_demo.py 文件,输入以下命令后,将端口映射到本地。在本地浏览器输入 http://127.0.0.1:6006 即可。
streamlit run /root/personal_assistant/code/InternLM/web_demo.py --server.address 127.0.0.1 --server.port 6006

















 509
509

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









