






Attention Mechanisms已经成了模型设计的基础架构,在模型中不搞点Attention都不好意思说这是个好模型。
为了方便大家快速了解当前Attention Mechanisms的发展情况,本文总结了当前主流的17种注意力机制,介绍了它们的基本原理和计算方法,并给出了它们出处和相应代码,大家可以根据需要进一步阅读:
想快速了解Attention Mechanisms的基本原理的同学可以看之前的文章:
Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint arXiv:1508.04025, 2015.
https://arxiv.org/pdf/1508.04025v5.pdf
Dot-Product Attention 是最常见的一种注意力机制,最早应用于Encoder-Decoder模型中,其中计算公式为:
其中,表示Encoder的隐藏状态,表示Decodeer的隐藏状态。然后使用softmax来计算最终的attention权重。
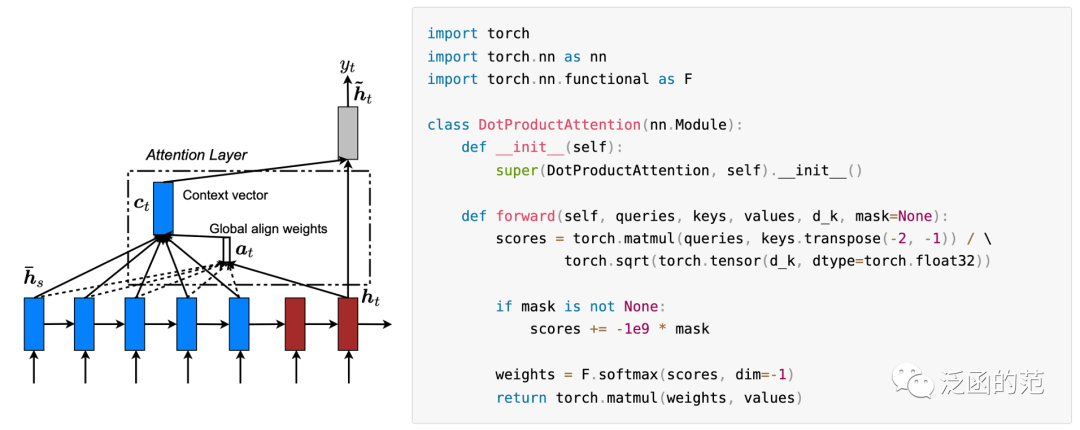
图片
Vaswani A, Shazeer N, Parmar N, et al. Attention is all you need[J]. Advances in neural information processing systems, 2017, 30.
https://arxiv.org/pdf/1706.03762v7.pdf
Scaled dot-product attention 常用于Transformer模型中,尤广泛应用于self-attention中。具体的注意力计算公式如下:
其中,Q表示query向量,K表示key量,V表示与每个key关联的value向量。将Q和K进行点积后,除以,然后应用softmax函数得到注意力权重。最后,将注意力权重与值向量V逐元素相乘,得到加权求和的结果,表示经过注意力机制后的输出。
将点积乘以的缩放因子的目的是控制注意力权重的大小。
假设q和k的分量是均值为0、方差为1的独立随机变量,它们的点积()的均值为0,方差为(Key向量的维度)。当较大时,点积的取值通常较大,可能导致在反向传播时梯度变得非常大。将其除以,使得点积的方差为1,这样助于平衡点积在注意力计算中的影响。

图片
Child R, Gray S, Radford A, et al. Generating long sequences with sparse transformers[J]. arXiv preprint arXiv:1904.10509, 2019.
https://arxiv.org/pdf/1904.10509v1.pdf
其中,、和表示将给定的转换为query、key和value的权重矩阵,是query和key向量维度。每个位置的输出是value的加权求和,权重由key和query的scaled dot-product决定。
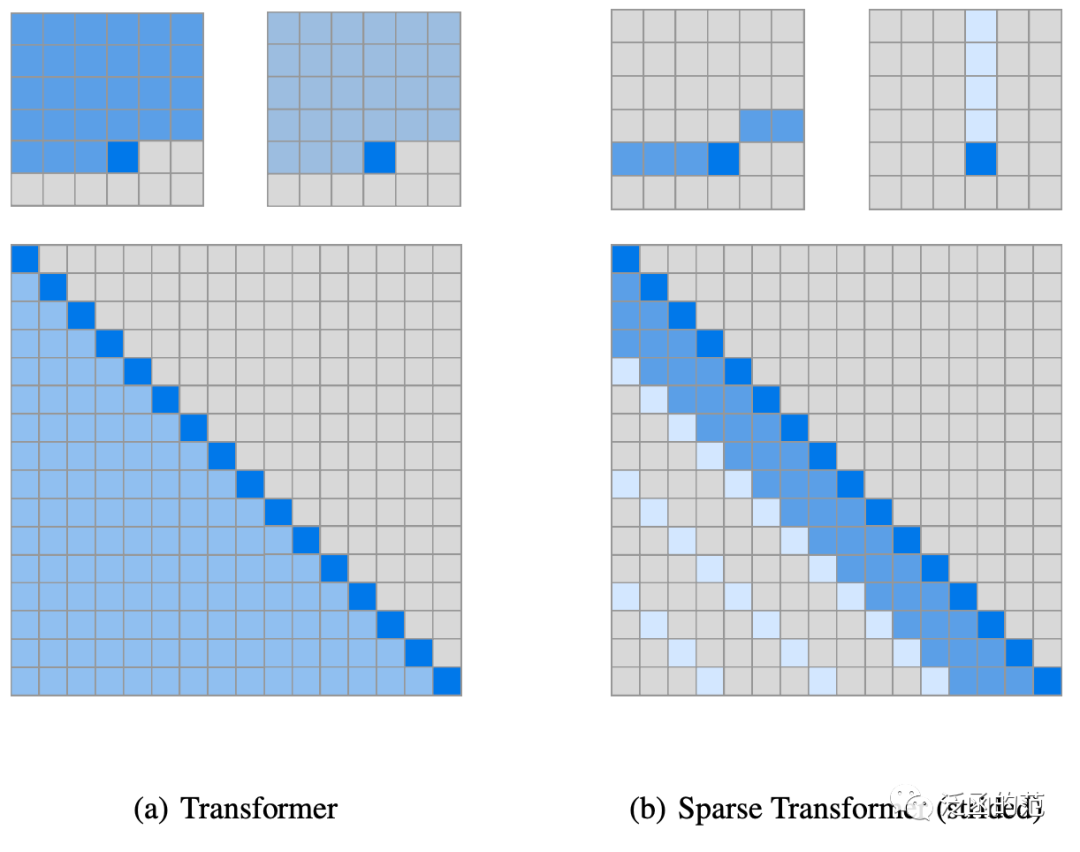
图片
Wang F, Jiang M, Qian C, et al. Residual attention network for image classification[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 3156-3164.
https://arxiv.org/pdf/1704.06904v1.pdf
受ResNet的成功启发,Wang等人将注意力机制与残差相结合,提出了非常深的卷积残差注意力网络(RAN)。
在RAN中,每个注意力模块可以分为掩码分支和主干分支。主干分支处理特征,可以采用任何最先进的结构来实现(如pre-activation residual unit、Inception等)。掩码分支使用自底向上和自顶向下的结构,学习一个与主干分支的输出大小相同的掩码,用于对输出特征进行软加权。经过两个卷积层后,使用sigmoid层将输出归一化到区间。RAN可以表示为:
其中,是自底向上的结构,在残差单元之后多次使用Max-pooling来增加receptive field,而是自顶向下的部分,使用线性插值保持输出与输入的feature map大小相同。此外,两个部分之间还有skip-connection(公式中省略了)。表示主干分支,可以是任何结构。
在每个注意力模块内部,自底向上和自顶向下的前馈结构建模了空间和跨通道的依赖关系。RAN可以以end-to-end训练方式应用于任何深度网络结构。然而,这种自底向上和自顶向下的结构未能利用全局空间信息。而且,直接预测3D注意力计算成本高。
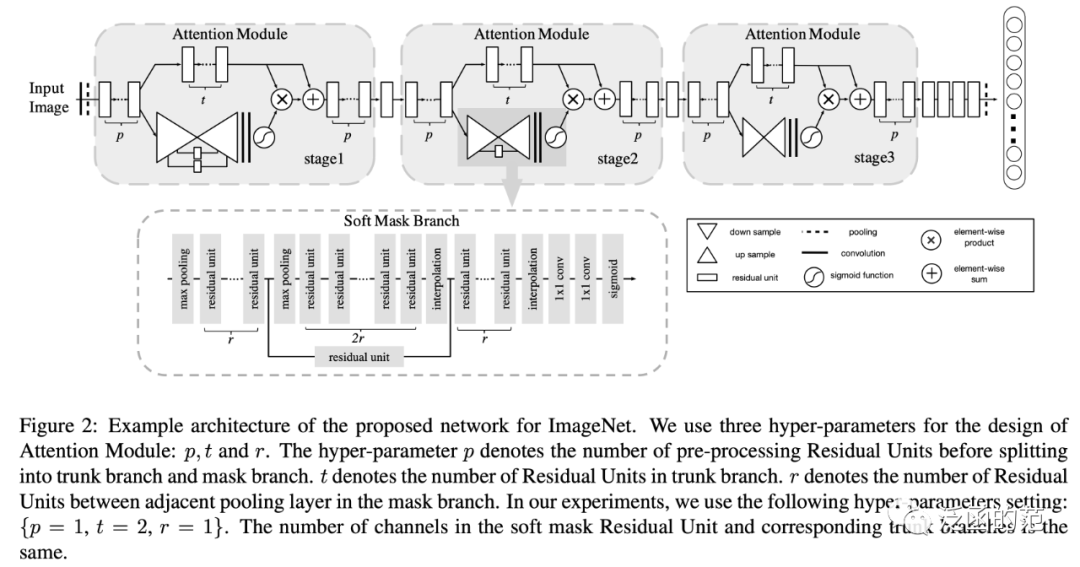
图片
详细代码见:https://github.com/tengshaofeng/ResidualAttentionNetwork-pytorch.git
Bahdanau D, Cho K, Bengio Y. Neural machine translation by jointly learning to align and translate[J]. arXiv preprint arXiv:1409.0473, 2014.
https://arxiv.org/pdf/1409.0473.pdf
Additive Attention,也称为Bahdanau Attention,使用一个单隐藏层的前馈神经网络来计算注意力数:

图片
Hu J, Shen L, Sun G. Squeeze-and-excitation networks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7132-7141.
https://arxiv.org/pdf/1709.01507v4.pdf
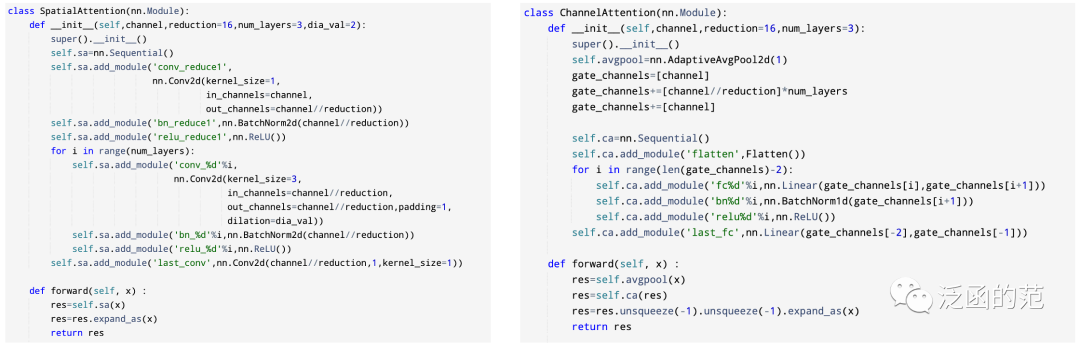
Channel Attention最早是由SENet提出的。SENet的核心是一个Squeeze-and-Excitation(SE)模块,用于收集全局信息、捕捉通道间的关系并提高表示能力。SE模块分为Squeeze模块和Excitation模块两部分。Squeeze模块通过Global Average Pooling来收集全局空间信息。Excitation模块通过使用全连接层和非线性层(ReLU和sigmoid)来捕捉通道间的关系,并输出一个注意力向量。然后,输入特征的每个通道通过与注意力向量的相应元素相乘来进行缩放。以为输入、为输出的SE模块(具有参数)可以表示为:
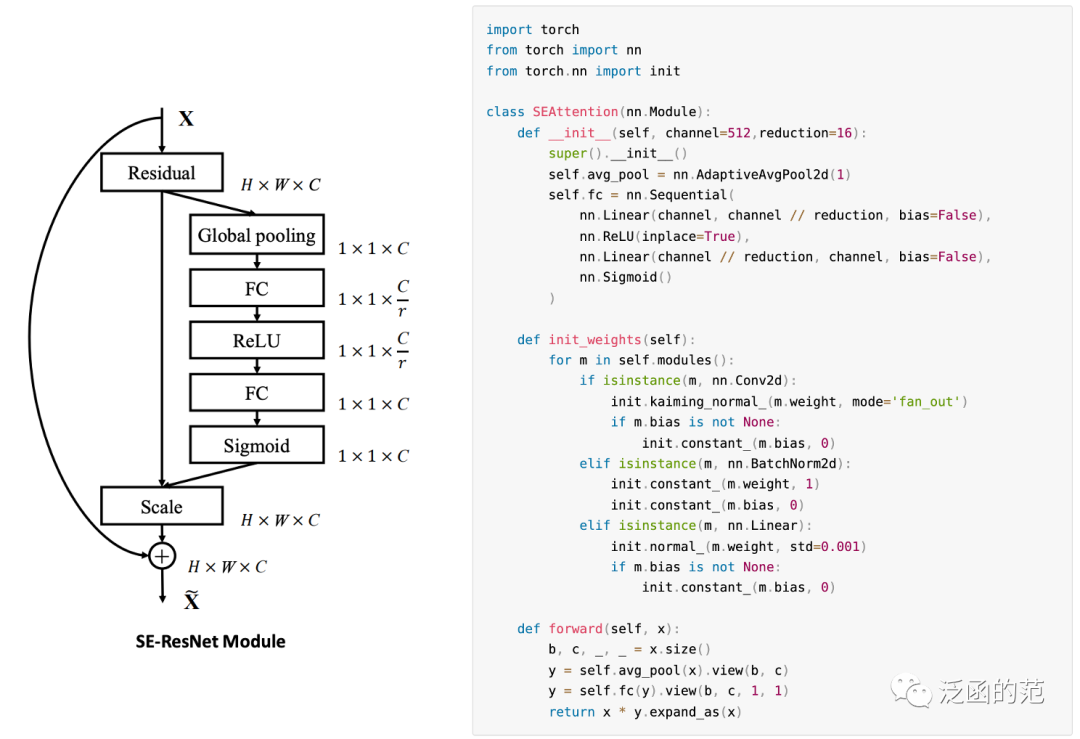
图片
Beltagy I, Peters M E, Cohan A. Longformer: The long-document transformer[J]. arXiv preprint arXiv:2004.05150, 2020.
https://arxiv.org/pdf/2004.05150.pdf
Sliding Window Attention最早是作为Longformer结构的一部分提出的。它的动机是基于原始Transformer中的非稀疏注意力具有的时间和空间复杂度,其中是输入序列的长度,因此不适合处理长输入。考虑到局部上下文的重要性,Sliding Window Attention围绕每个token使用固定大小的窗口Attention。使用多个堆叠的窗口化注意力层可以得到一个更大的receptive field,最顶层可以访问所有输入位置并具备整合整个输入信息的能力。
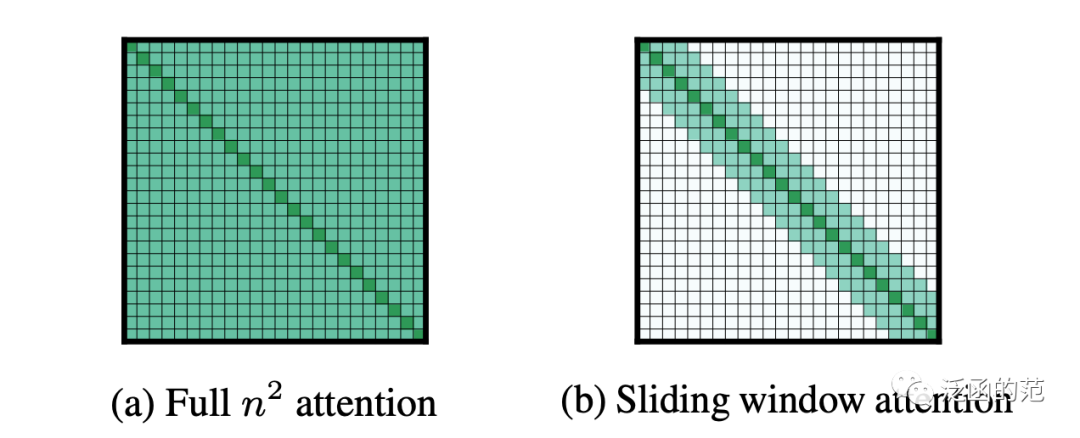
图片
更具体地说,给定固定的窗口大小,每个Token在每个侧面参与个Token的注意力计算。该模式的计算复杂度为,与输入序列长度线性相关,通常情况下。类似于CNN中堆叠小核的层会生成从输入的大部分构建的高级特征(receptive field),具有多个堆叠Transformer的模型将具有较大的receptive field。
详细代码见:https://github.com/allenai/longformer.git
Touvron H, Cord M, Sablayrolles A, et al. Going deeper with image transformers[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2021: 32-42.
https://arxiv.org/pdf/2103.17239v2.pdf
Class Attention(CA)是CaiT中用于视觉Transformer的注意力机制,旨在从一组处理过的图块中提取信息。它与自注意力层完全相同,只是依赖于以下注意力关系:
考虑一个具有个注意力头和个patches的网络,并用表示嵌入维度大小,多头Class Attention使用多个投影矩阵进行参数化,即,并具有相应的偏置。CA残差块的计算过程如下。首先,将图块嵌入(以矩阵形式)扩充为。然后,进行投影计算:
Class-attention权重的计算如下:

图片
Luong M T, Pham H, Manning C D. Effective approaches to attention-based neural machine translation[J]. arXiv preprint arXiv:1508.04025, 2015.
https://arxiv.org/pdf/1508.04025)
Location-based Attention 仅从目标隐藏状态计算得出,计算方式如下:
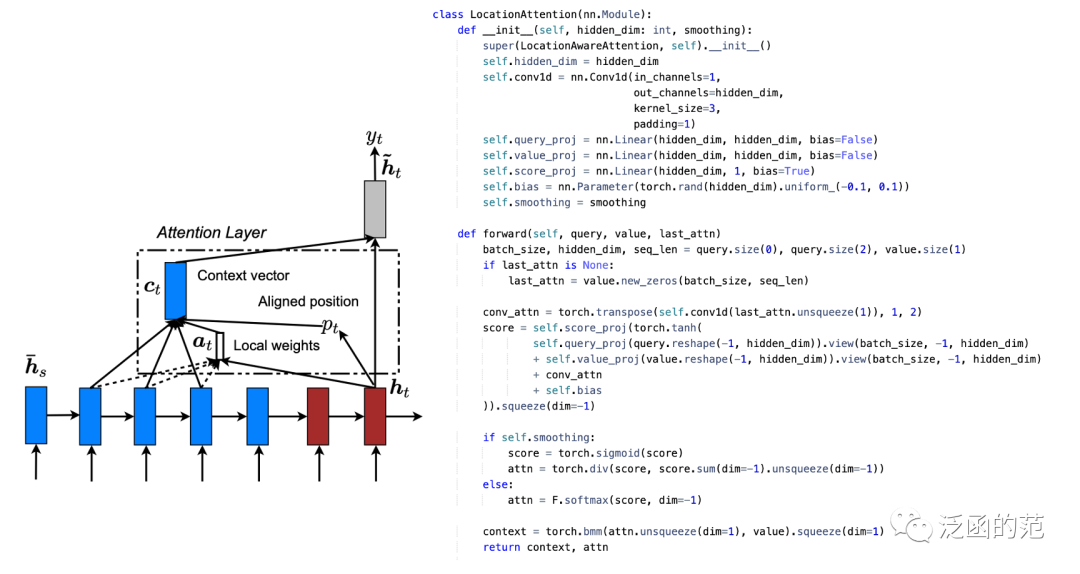
图片
Oktay O, Schlemper J, Folgoc L L, et al. Attention u-net: Learning where to look for the pancreas[J]. arXiv preprint arXiv:1804.03999, 2018.
https://arxiv.org/pdf/1804.03999.pdf
Attention Gate 目的是将注意力集中在目标区域,同时抑制与目标无关区域的特征激活。给定输入和门控信号,门控信号在粗粒度上收集并包含上下文信息,Attention Gate使用Additive Attention来获取门控系数。输入和门控信号首先通过线性映射,映射到维度的空间,然后在通道维度上进行压缩,生成空间注意力权重图。整个过程可以表示为:
Attention Gate引导模型的注意力集中在重要区域,同时抑制与目标无关区域的特征激活。由于其轻量化设计,它显著增强了模型的表示能力,而不会明显增加计算成本和模型参数量。它具有通用性和模块化性,使得它可以简单地应用于各种CNN模型中。
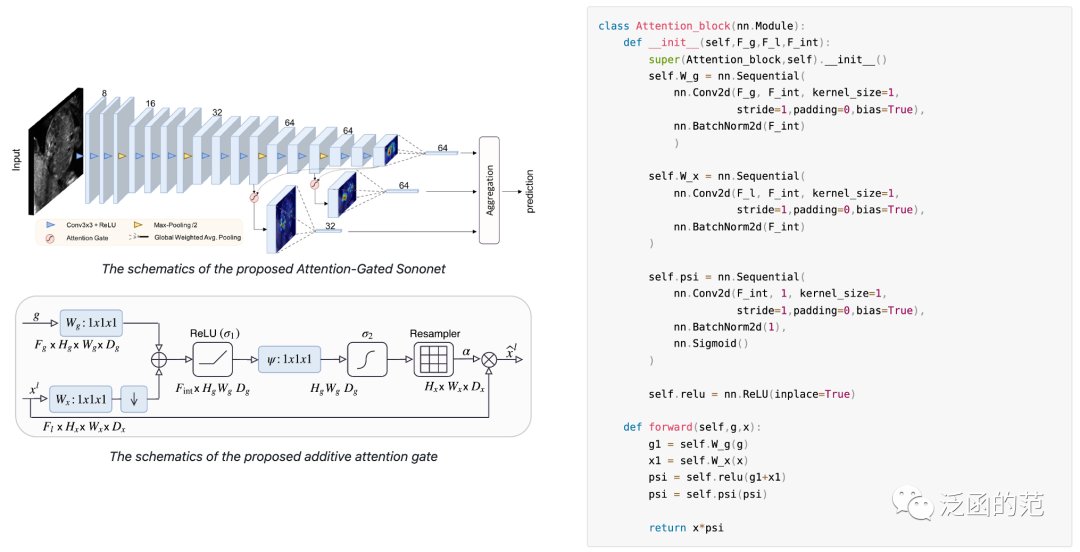
图片
Park J, Woo S, Lee J Y, et al. Bam: Bottleneck attention module[J]. arXiv preprint arXiv:1807.06514, 2018.
https://arxiv.org/pdf/1807.06514.pdf
Bottleneck Attention Module(BAM)是由Park等人提出,旨在有效提高网络的表示能力。BAM使用Dilated Convolution来扩大空间注意力子模块的receptive field,并且未了节省计算成本采用瓶颈结构。
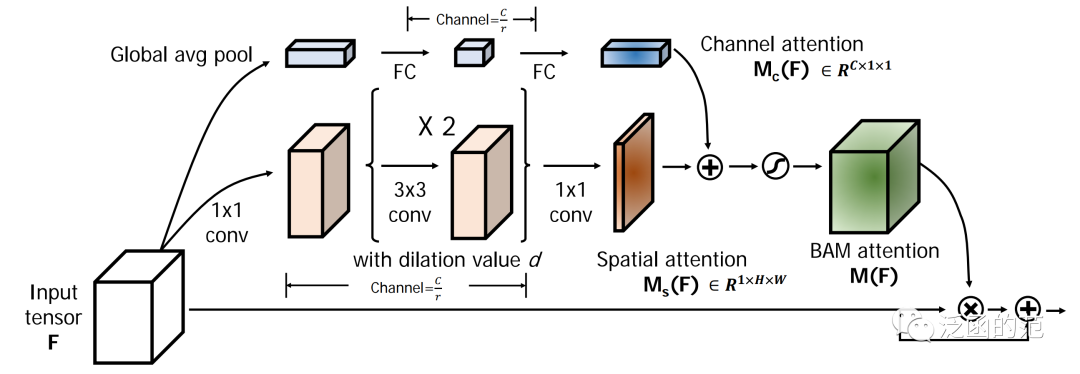
图片
对于给定的输入,BAM在两个并行分支中分别计算通道注意力和空间注意力;然后将两个注意力相加,同时将两个分支输出调整大小为。通道注意力分支类似于前文提到的SE block,对特征应用 Global Average pooling 以聚合全局信息,然后通过MLP对通道进行降维。为了有效利用上下文信息,空间注意力分支结合了瓶颈结构和Dilated Convolution。总体而言,BAM的表示方式如下:
图片
BAM可以在空间和通道维度上强调或抑制特征,同时提高表示能力。同时对通道和空间注意力分支进行的维度降低使其能够与任何卷积神经网络集成,几乎不增加额外的计算成本。然而,尽管扩张卷积有效地扩大了感受野,但它仍然无法捕捉到远距离的上下文信息,并且无法编码跨域关系。
详细代码见:https://github.com/xmu-xiaoma666/External-Attention-pytorch/blob/master/model/attention/BAM.py
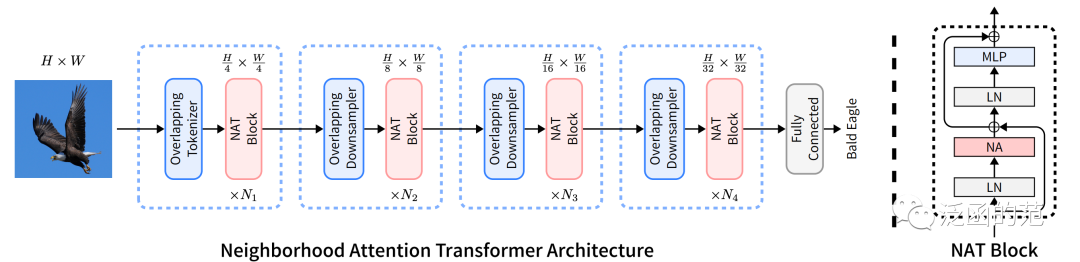
Hassani A, Walton S, Li J, et al. Neighborhood attention transformer[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 6185-6194.
https://arxiv.org/pdf/2204.07143v5.pdf
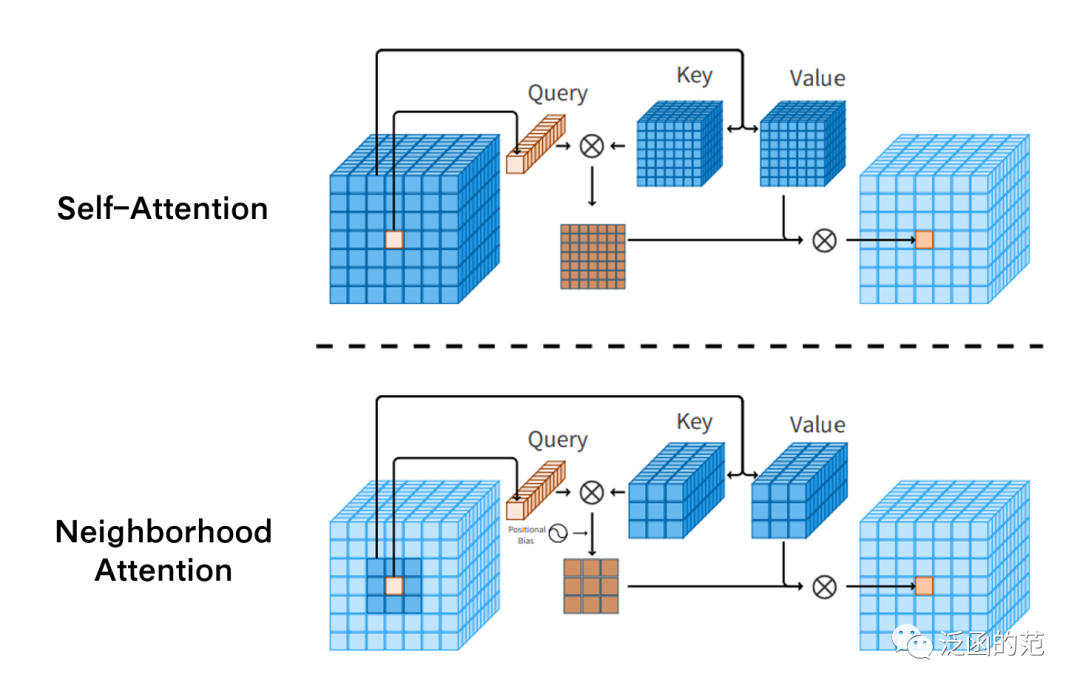
Neighborhood Attention 是一种Restricted Self-Attention,其中每个Token的receptive field被限制在其最近的相邻像素上。它主要用于取代层次化视觉Transformer中使用的其他局部注意力机制。

图片
Neighborhood Attention 在概念上类似于独立的自注意力(Stand Alone Self-Attention, SASA),两者都可以通过在<key, value>对上进行栅格扫描滑动窗口操作来实现。
图片
图片
在尝试使用Neighborhood Attention 和 SASA 进行实验时,主要是计算问题。对于每个query仅提取key-value操作不仅计算缓慢,还占用大量内存,这使得它很难应用于解决大规模问题。
详细代码见:https://github.com/SHI-Labs/Neighborhood-Attention-Transformer.git
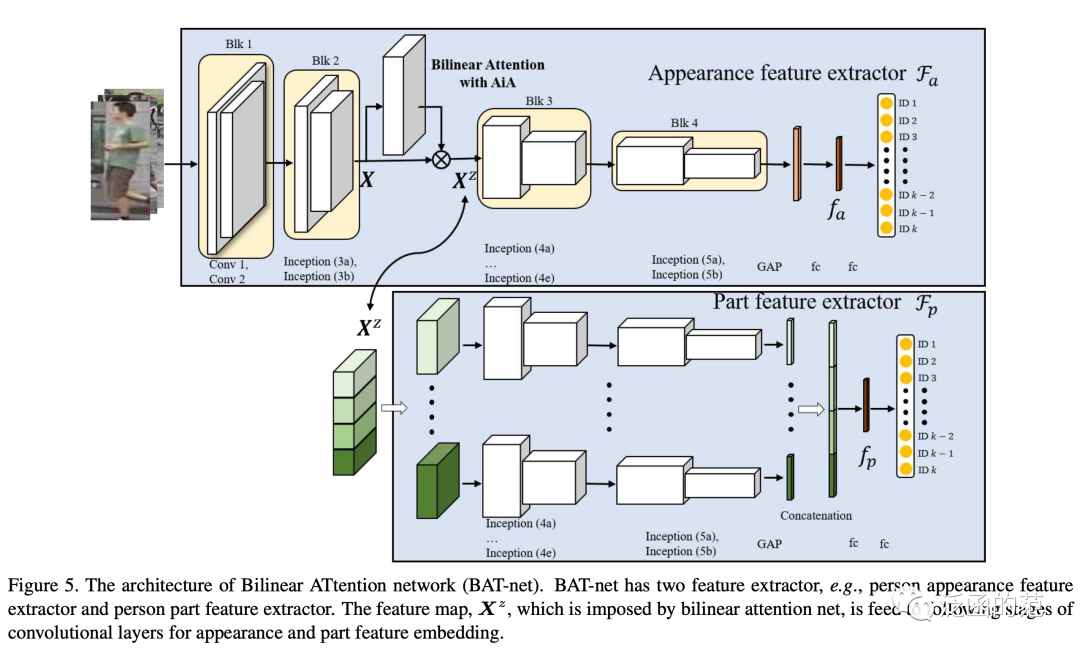
Fang P, Zhou J, Roy S K, et al. Bilinear attention networks for person retrieval[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 8030-8039.
https://openaccess.thecvf.com/content_ICCV_2019/papers/Fang_Bilinear_Attention_Networks_for_Person_Retrieval_ICCV_2019_paper.pdf
Bilinear Attention(Bi-Attention)采用 Attention-in-Attention(AiA)机制来捕捉二阶统计信息:外部通道注意力向量是用内部通道注意力的输出计算得出的。

图片
图片
Roy A, Saffar M, Vaswani A, et al. Efficient content-based sparse attention with routing transformers[J]. Transactions of the Association for Computational Linguistics, 2021, 9: 53-68.
https://arxiv.org/pdf/2003.05997v5.pdf
Routed Attention 最出是在Routing Transformer架构中分提出的一种注意力模式。每个注意力模块考虑了空间的聚类:当前timestep只关注属于同一簇的上下文。也就是说,当前timestep的query通过其聚类被路由到有限数量的上下文中。
如下图所示,行表示输出,列表示输入。不同的颜色表示输出Token的聚类成员关系。
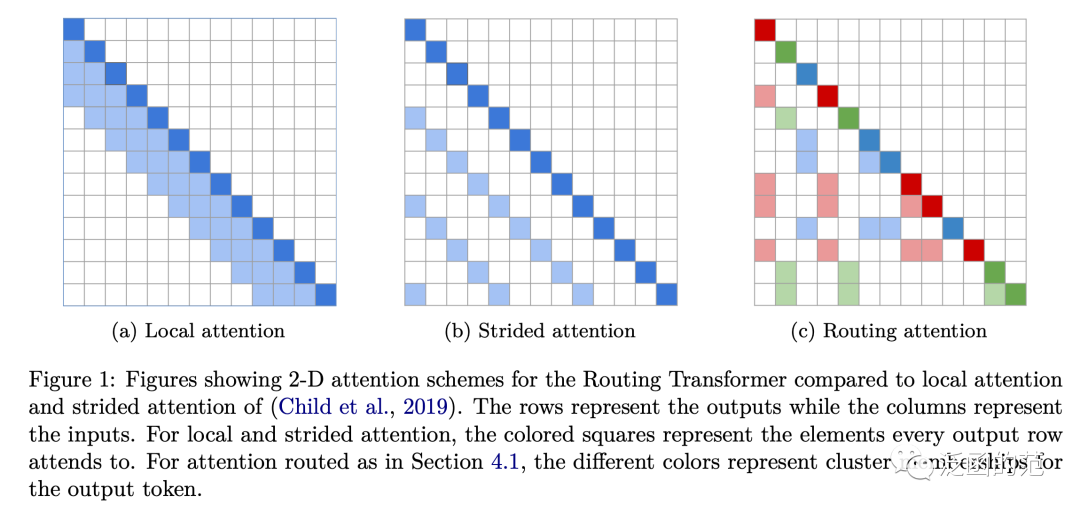
图片
详细代码见:https://github.com/lucidrains/routing-transformer.git
Ali A, Touvron H, Caron M, et al. Xcit: Cross-covariance image transformers[J]. Advances in neural information processing systems, 2021, 34: 20014-20027.
https://arxiv.org/pdf/2106.09681v2.pdf
与传统的Transformer在Token纬度上进行操作不同,Cross-Covariance Attention(XCA)在特征维度上进行操作。
使用传统注意力中的query()、key()和value()的符号定义,XCA 定义如下:
其中,每个输出Token的embedding对应于中的Token embedding 的个特征的凸组合。注意力权重是基于交叉协方差矩阵计算得出的。此外,作者通过对 query和 key 矩阵进行归一化来限制其幅度,使得归一化矩阵和的每一列为长度是的单位向量,并使得维的交叉协方差矩阵中的每个元素都在范围内。
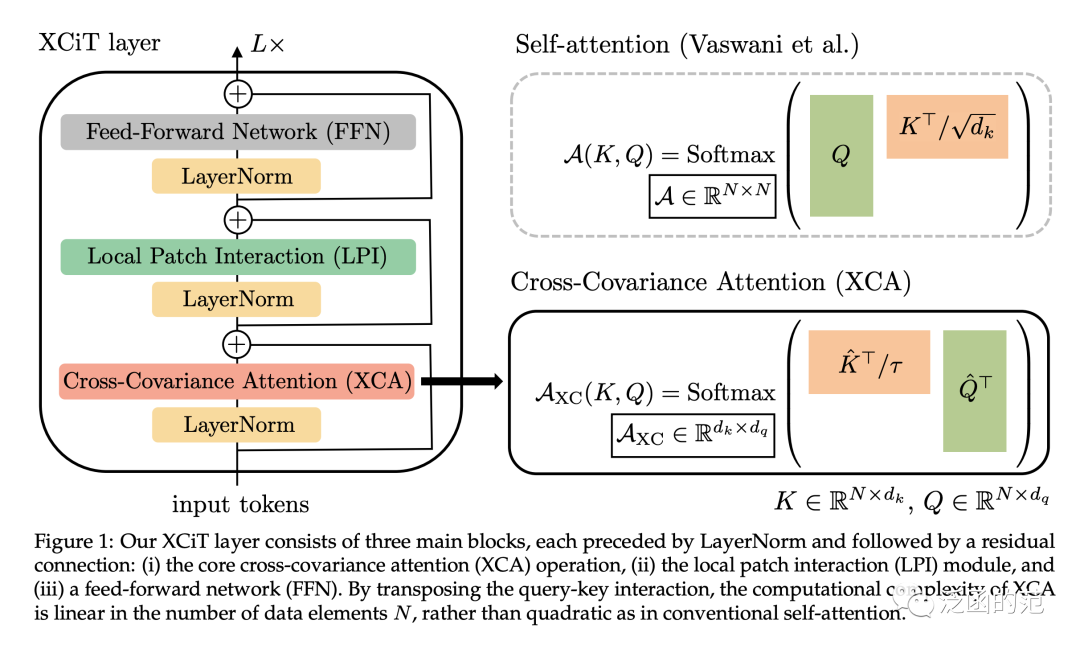
图片
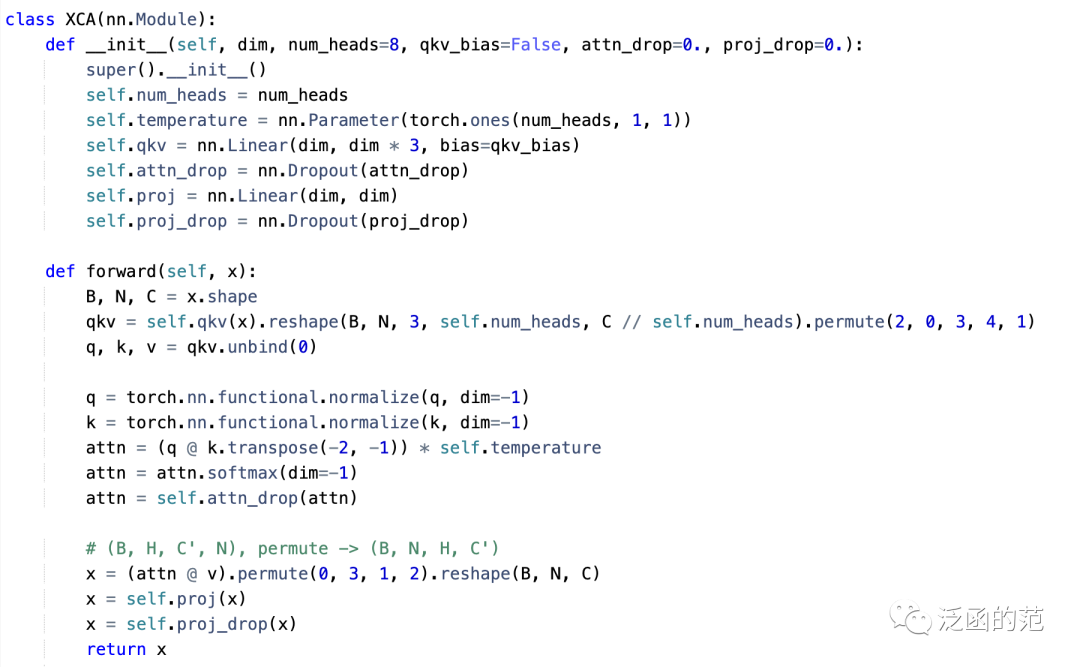
图片
详细代码见:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/xcit.py
Zhang Z, Lan C, Zeng W, et al. Relation-aware global attention for person re-identification[C]//Proceedings of the ieee/cvf conference on computer vision and pattern recognition. 2020: 3186-3195.
https://arxiv.org/pdf/1904.02998v2.pdf
Relation-aware Global Attention(RGA)强调成对关系提供的全局结构信息的重要性,并将其用计算注意力图。
RGA有两种形式,空间RGA(RGA-S)和通道RGA(RGA-C)。
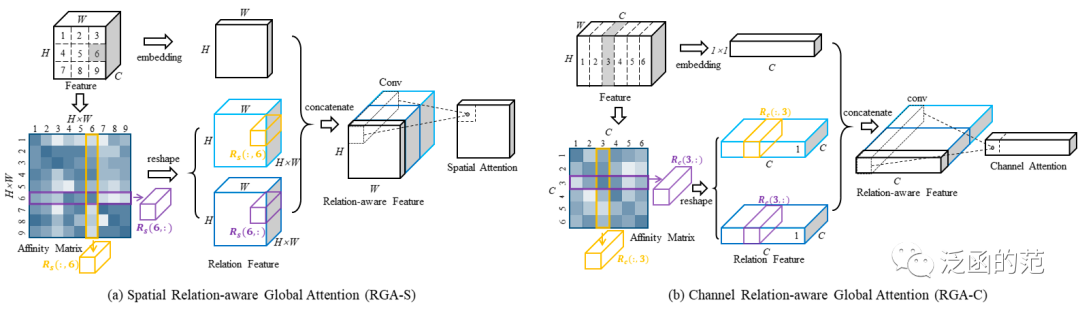
图片
位置处的关系向量是由所有位置的成对关系堆叠而成:
空间关系感知特征可以表示为:
其中,表示通道域的Global Average Pooling操作。
最后,位置处的空间注意力可以表示为:
RGA-C与RGA-S具有相同的形式,只是将输入视为一组维的特征。
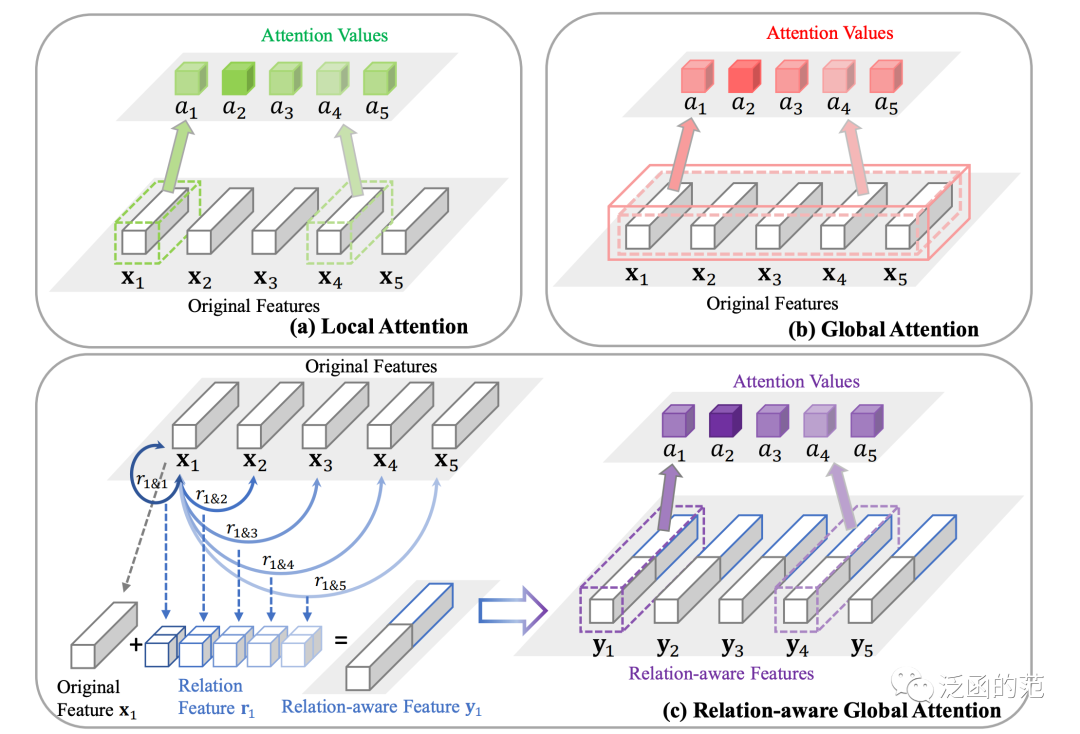
图片
RGA利用全局关系为每个特征节点计算注意力分数,从而提供有价值的结构信息,并显著增强了表示能力。RGA-S和RGA-C足够灵活,可以在任何CNN网络中使用;作者建议将它们连续使用来更好地捕捉空间和跨通道的关系。
详细代码见:https://github.com/microsoft/Relation-Aware-Global-Attention-Networks.git
Chu X, Tian Z, Wang Y, et al. Twins: Revisiting the design of spatial attention in vision transformers[J]. Advances in Neural Information Processing Systems, 2021, 34: 9355-9366.
https://arxiv.org/pdf/2104.13840v4.pdf
Locally-grouped Self-Attention(LSA)是Twins-SVT架构中提出的一种局部注意力机制。LSA 首先将2D feature map均匀划分为多个子窗口,并使self-attention的通信仅在每个子窗口内进行。这个设计也与multi-head self-attention的设计相呼应,其中通信仅在同一head的通道之间发生。
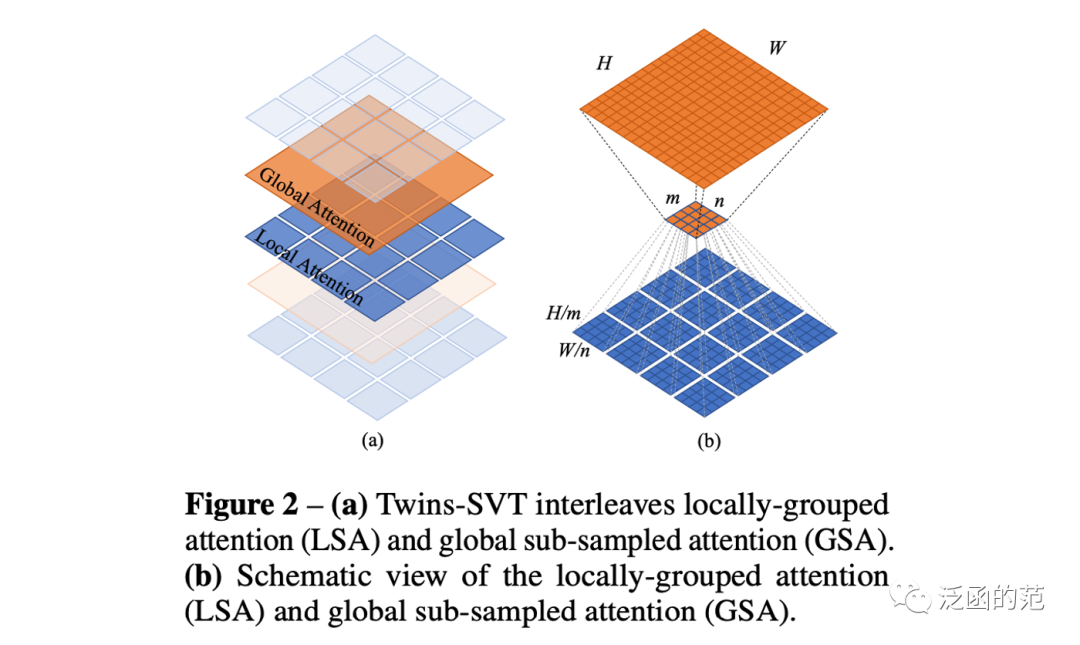
图片
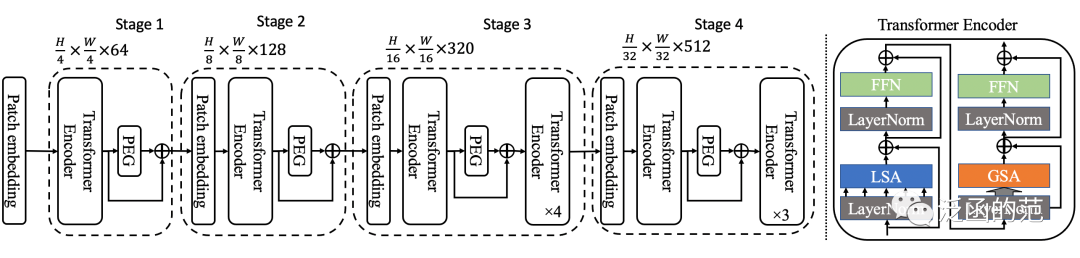
图片
尽管局部分组自注意力机制在计算上更友好,但图像被划分为非重叠的子窗口。因此,我们需要一种机制在不同的子窗口之间进行通信,就像Swin中一样。否则,信息将被局限在本地处理,使感受野变小,并且在我们的实验中显著降低性能。这类似于在CNN中不能将所有标准卷积都替换为深度可分离卷积的事实。
详细代码见:https://github.com/Meituan-AutoML/Twins.git
本文总结了当前主流的17种注意力机制,介绍了它们的基本原理和计算方法,并给出了它们出处和相应代码,大家可以根据需要进一步阅读。















 411
411











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









