






在人工智能的领域,将文本描述转换为图像的技术正变得越来越先进。最近,一个由清华大学和Meta Reality Labs的研究人员组成的团队,提出了一种名为MultiBooth的新方法,它能够根据用户的文本提示,生成包含多个定制概念的图像。这项技术的出现,标志着我们在个性化图像生成方面迈出了重要的一步。
传统的文本到图像生成技术虽然已经能够根据给定的文本生成相应的图像,但它们在处理用户特定的个性化需求时,往往力不从心。例如,用户可能希望在图像中加入自己心爱的宠物或者个人物品,这些个性化的概念在大规模文本到图像模型的训练中往往不会被捕捉到。
MultiBooth的创新之处
MultiBooth的核心方法是一种新颖的图像生成技术,它能够根据文本提示生成包含多个定制概念的图像。这项技术通过两个关键阶段来实现:单概念学习和多概念整合。下面详细介绍这两个阶段的关键组成部分和方法。

1. 单概念学习阶段
多模态图像编码器:在这个阶段,MultiBooth使用一个多模态图像编码器来处理用户提供的少量图像。这个编码器不仅考虑图像的视觉信息,还结合了与图像相关的文本描述,以此来学习每个概念的精确表示。
高效的概念编码技术:为了提高学习效率,MultiBooth采用了一种高效的编码技术,称为LoRA(Low-Rank Adaptation)。LoRA通过在注意力机制的关键权重矩阵中引入低秩分解,以更少的参数实现对概念的编码。
自适应概念归一化(ACN):为了解决自定义嵌入与其他词汇嵌入之间的域差距问题,MultiBooth引入了ACN。ACN通过L2归一化和自适应缩放,使得自定义嵌入的L2范数与其他词汇嵌入保持一致,从而提高了多概念生成的能力。

2. 多概念整合阶段
区域定制模块:在多概念整合阶段,MultiBooth提出了一个区域定制模块,它通过在交叉注意力层中划分不同的区域,来指导不同概念的生成。每个区域的注意力值由相应的单概念模块和提示引导,从而在指定区域内生成特定的概念。
边界框定义:用户可以为每个概念定义边界框,这些边界框在生成过程中用来确定每个概念的空间位置,确保多概念在图像中的布局合理且互不干扰。
交叉注意力机制:在生成图像时,每个概念的图像特征通过与对应的文本嵌入和LoRA参数结合,利用交叉注意力机制生成。这样,每个概念都能在图像中的正确位置生成,同时保持与文本提示的一致性。
核心优势
- 高保真度:MultiBooth生成的图像在视觉质量和概念准确性上都表现出色。
- 文本对齐:图像生成结果与用户的文本提示高度一致,满足个性化需求。
- 计算效率:由于采用了高效的编码技术和区域定制模块,MultiBooth在推理时具有较低的计算成本。
- 可扩展性:MultiBooth的方法允许轻松扩展到更多的概念,而无需额外的训练。
MultiBooth的提出,为个性化和多概念图像生成领域提供了一种创新的解决方案,它通过结合先进的编码技术和区域定制策略,实现了根据文本提示生成复杂场景图像的目标。在论文中,研究人员通过一系列精心设计的实验来验证MultiBooth的性能。这些实验不仅包括了定性分析,即通过观察生成图像的视觉质量来判断,还包括了定量分析,即通过计算模型生成的图像与源图像或文本提示之间的相似度来评估。
实验设置
实验基于一个名为Stable Diffusion的模型,使用了一个强大的图像生成网络。研究人员在单个高性能GPU上运行实验,并选择了一组具有代表性的主题,如宠物、物体和场景等,来测试MultiBooth的性能。
定性分析
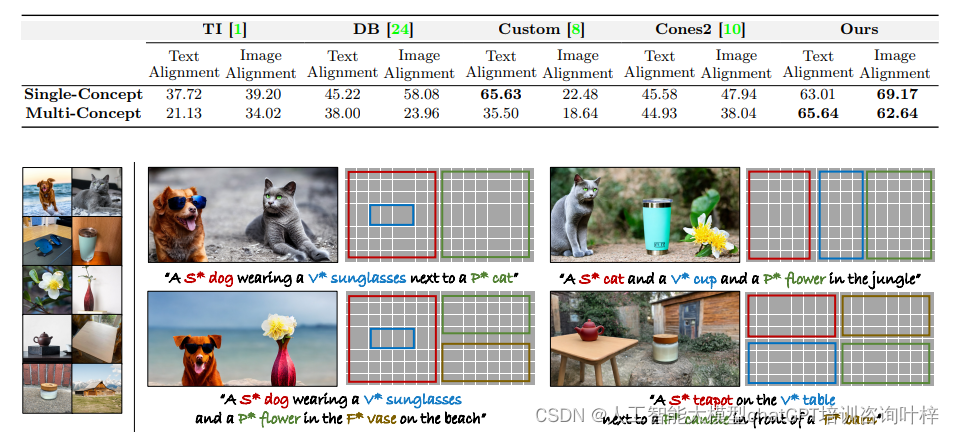
在定性分析中,研究人员通过视觉检查生成的图像来评估MultiBooth的效果。他们比较了MultiBooth与其他几种现有方法,如Textual Inversion、DreamBooth、Custom Diffusion和Cones2,生成的图像。结果显示,MultiBooth在生成包含多个概念的图像时,能够更好地保持每个概念的独立性和准确性,同时确保图像整体的协调性和真实感。

定量分析
定量分析涉及三个主要的评估指标:
- CLIP-I:计算生成图像与源图像在特征空间中的平均余弦相似度。
- Seg CLIP-I:对源图像进行分割,仅计算与生成图像中相应区域相关的部分的相似度。
- CLIP-T:计算文本提示的特征表示与生成图像的特征表示之间的平均余弦相似度。
实验结果表明,MultiBooth在所有评估指标上都优于其他方法。特别是,在CLIP-I和Seg CLIP-I指标上,MultiBooth的性能提升显著,这表明它在生成图像的视觉质量和与源图像的相似度方面都取得了很好的效果。
训练与推理时间
除了图像质量之外,MultiBooth在训练和推理时间上也显示出了优势。研究人员报告称,与其他方法相比,MultiBooth的训练和推理过程更快,这使得它在实际应用中更具吸引力。
消融研究
为了进一步理解MultiBooth各个组件的贡献,研究人员还进行了消融研究。他们分别移除了区域定制模块、QFormer编码器和自适应概念归一化(ACN),并观察到这些改变对模型性能的负面影响。这证明了这些组件对于MultiBooth实现高性能至关重要。
用户研究
最后,研究人员还进行了用户研究,让参与者对不同方法生成的图像进行评价。用户研究的结果进一步证实了MultiBooth在文本对齐和图像质量方面的优势,大多数用户更倾向于选择MultiBooth生成的图像。
以上证明了MultiBooth在多概念图像生成任务中的卓越性能。MultiBooth不仅能够生成高质量、与文本描述高度一致的图像,而且还具有训练和推理阶段的高效率。这些特性使得MultiBooth成为一个有前景的研究方向,为个性化图像生成开辟了新的可能性。与现有的 MCC 方法相比,MultiBooth 允许在训练和推理阶段以极小的成本进行即插即用的多概念生成,同时保持了高图像保真度。未来的研究将探索基于 MultiBooth 的无需训练的多概念定制任务。
论文链接:https://arxiv.org/abs/2404.14239
项目地址:https://multibooth.github.io/

















 697
697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











