







人工智能咨询培训老师叶梓 转载标明出处
在人工智能领域,大型语言模型虽然在云端环境中展现出卓越的性能,但它们在隐私保护、成本控制以及对网络连接的依赖性方面存在不足。这些问题限制了AI技术在移动设备和边缘计算场景中的应用潜力。为了克服这些限制,研究者们一直在探索如何在设备端部署更高效、更安全的语言模型。本文将介绍一种突破性的解决方案——Octopus v2模型,是由斯坦福大学的研究者Wei Chen和Zhiyuan Li开发的一种新型设备端语言模型。该模型拥有20亿参数,并在准确性和延迟方面超越了GPT-4,同时将上下文长度减少了95%。与使用RAG(Retrieval-Augmented Generation)基于函数调用机制的Llama-7B相比,Octopus v2在延迟上提升了35倍。这种模型的低延迟特性使其适合在各种边缘设备上部署,满足实际应用的性能需求。其主要优势如下:
高准确性:Octopus v2在功能调用的准确性上超越了当前领先的GPT-4模型,为用户提供了更为可靠的AI代理服务。
低延迟:通过优化模型结构和推理过程,Octopus v2显著降低了响应时间,使得设备端AI应用能够快速响应用户需求。
减少上下文长度:通过创新的标记化方法,Octopus v2大幅度减少了模型在处理任务时所需的上下文信息量,从而降低了计算资源的消耗。
成本效益:相较于云端大型模型高昂的运行成本,Octopus v2的部署和维护成本更低,使得广泛的商业应用成为可能。
隐私保护:设备端模型减少了数据在云端的传输,从而降低了隐私泄露的风险,更好地保护了用户的个人信息。
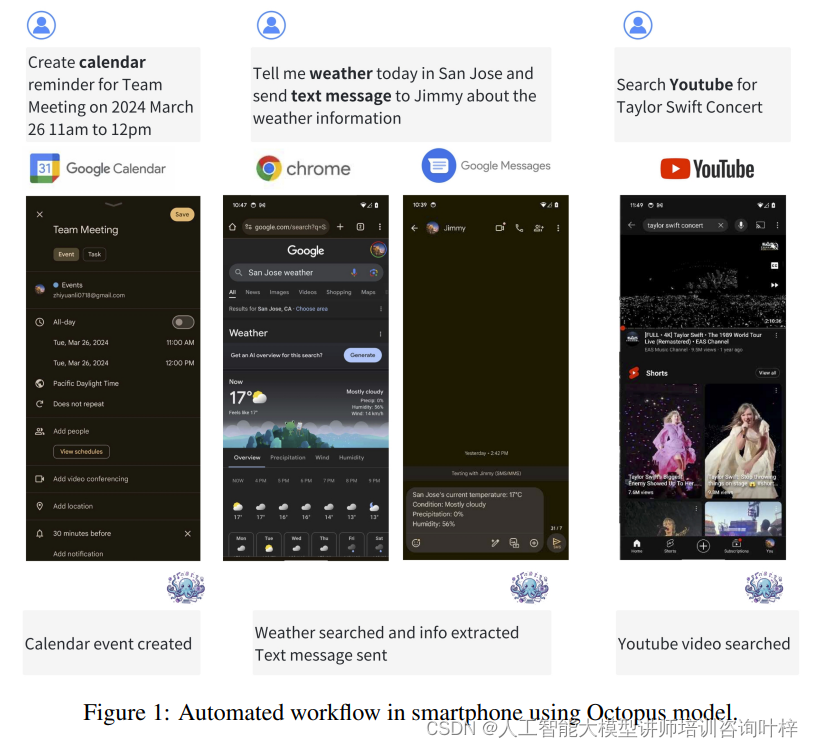
Octopus v2模型作为一个设备端语言模型,能够理解和处理自然语言指令,将其转换为可执行的函数调用。在图1中,模型执行以下步骤:
- 接收用户指令: 用户通过语音或文本输入向智能手机发出指令。
- 解析指令: Octopus模型解析用户的指令,理解其意图和需要执行的任务。
- 选择相应函数: 模型根据指令内容,从其知识库中选择最合适的函数或应用程序接口(API)。
- 生成参数: 模型生成执行该函数所需的参数,例如日期、时间、位置等。
- 执行函数调用: 使用生成的参数,模型调用相应的函数,执行任务。
- 反馈结果: 任务执行完毕后,模型将结果反馈给用户,可能是通过屏幕显示、语音通知或其他形式。
图1所展示的自动化工作流程的优势在于其低延迟、高准确性和用户隐私保护。Octopus v2模型减少了对云端资源的依赖,降低了数据传输过程中的隐私风险。模型的快速响应能力使得它适用于需要即时反馈的场景,如语音助手、智能提醒、自动化日程管理等。
方法
Octopus v2模型的设计理念是将语言模型应用于函数调用任务,这需要模型能够从用户查询中准确选择相应的函数并生成正确的函数参数。为了实现这一点,研究者们采用了一个两阶段过程:首先是功能选择阶段,其次是参数生成阶段。在功能选择阶段,模型需要理解函数描述及其参数,利用用户查询信息来创建可执行函数的参数。这一过程可以视为一个分类问题,其中N个可用函数被视为选择池,通过softmax分类来解决。通过将这一选择问题转化为单令牌分类问题,模型能够更准确地预测函数名称,同时减少了所需的令牌数量。

Octopus v2模型的一个关键创新是引入了功能令牌的概念。类似于自然语言的标记化,研究者们提出将特定函数表示为功能令牌。这些功能令牌通过类似于自然语言模型处理罕见词汇的技术进行训练,例如word2vec框架,其中上下文词汇丰富了令牌的语义表示。功能令牌的训练方法允许模型通过上下文来学习特定术语,即使这些术语在预训练语言模型中并不常见。通过这种方法,功能令牌能够被有效地集成到模型中,使得模型能够将函数调用方法转化为标准完成任务。
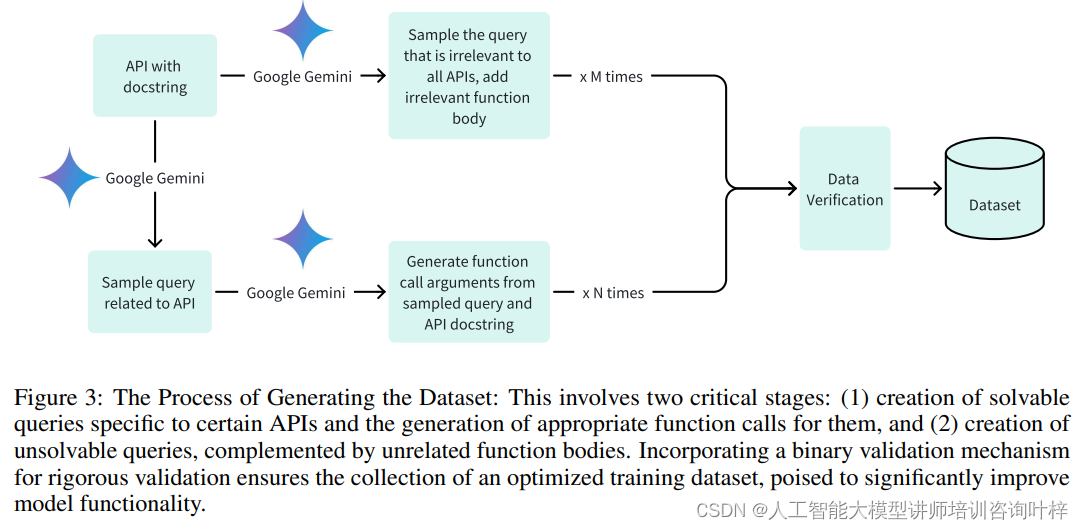
为了训练、验证和测试模型,研究者们采用了一套系统化的方法来收集高质量的数据集。以Android API为例,研究者们根据可用性、使用频率和技术实现的复杂性来选择API,并将其组织成三个不同的类别。数据集的生成包括三个关键阶段:生成相关查询及其关联的函数调用参数;开发不相关查询并配备适当的函数体;通过Google Gemini实现二元验证支持,确保数据集的完整性和准确性。
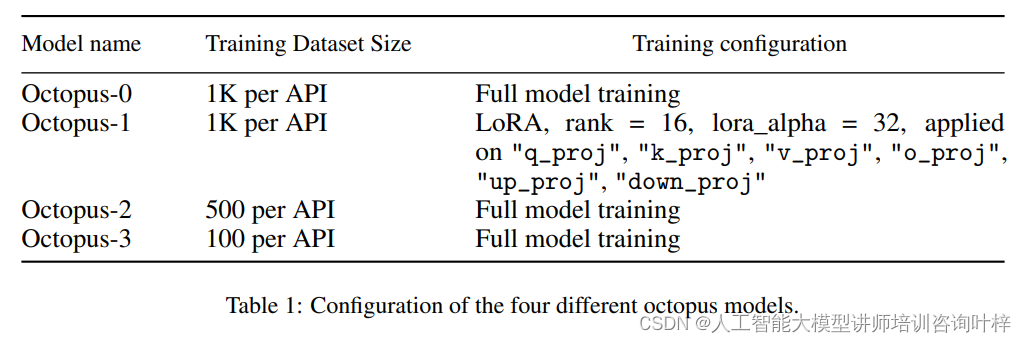
在模型开发和训练阶段,研究者们使用了Google Gemma-2B模型作为预训练模型,并采用了两种不同的训练方法:全模型训练和LoRA模型训练。全模型训练使用了AdamW优化器,设置了5e-5的学习率、10步的预热期和线性学习率调度器。LoRA训练同样使用了AdamW优化器和相同的学习率配置,但将LoRA应用于特定的模型模块,并设置了16的秩和32的alpha参数。这两种训练方法都设置了3个训练周期。
实验
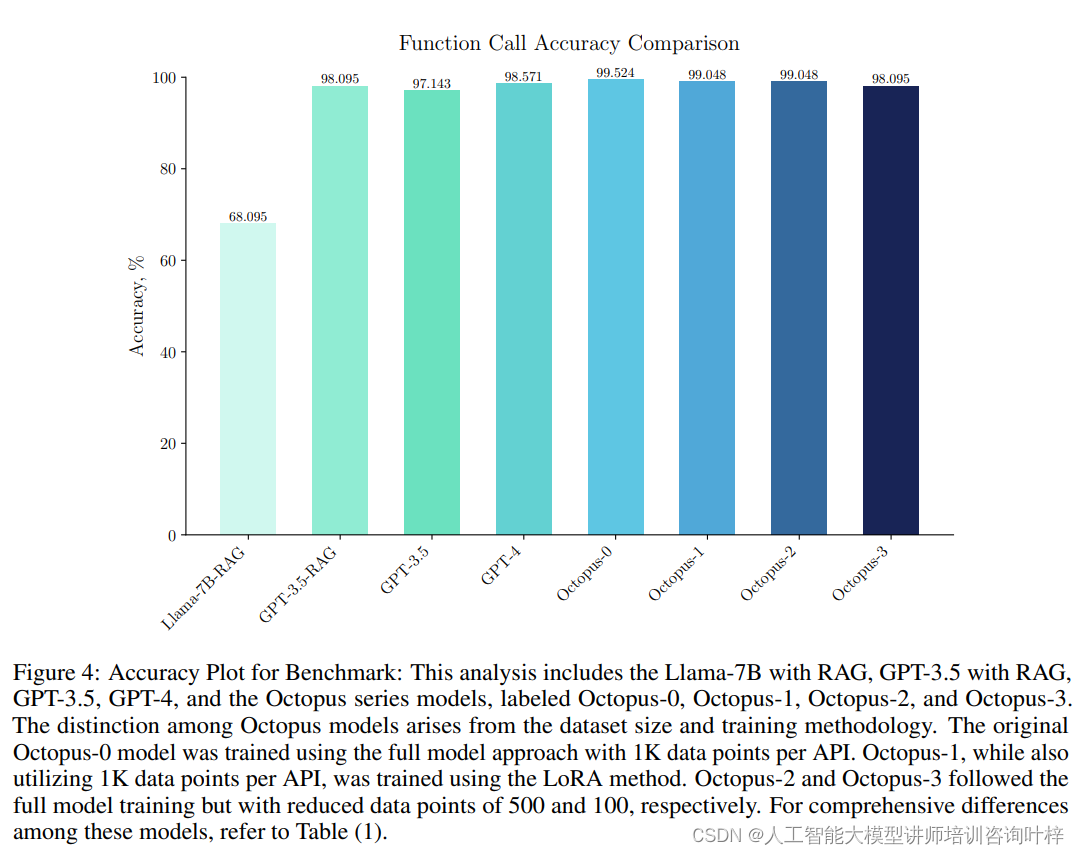
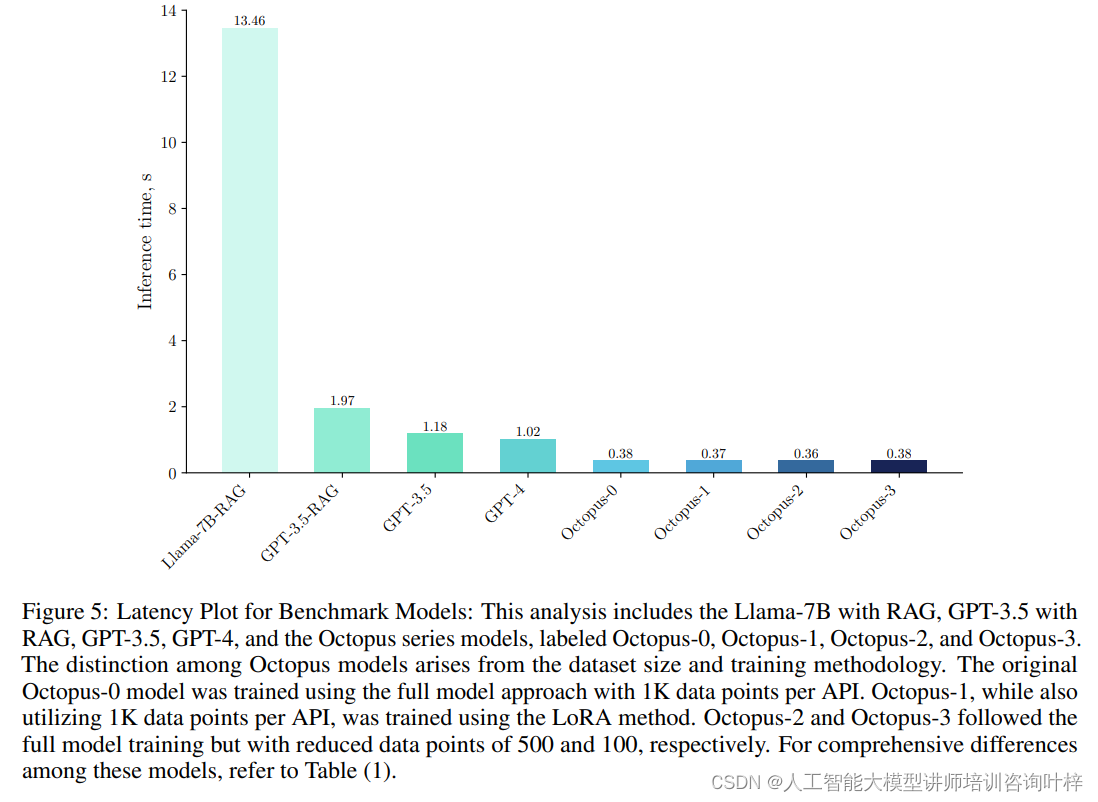
研究者们选择Android系统功能调用作为案例研究,以展示Octopus v2模型在生成准确功能调用方面的卓越性能。实验聚焦于模型的两个关键指标:准确性和延迟。通过选择20个Android API作为数据集基础,研究者们采用了两种不同的方法来生成函数调用命令。第一种方法是使用RAG方法,根据用户查询识别最相似的函数描述,然后利用这些描述生成预期的函数调用命令。实验结果表明,Octopus v2模型在这些API上表现出了99.524%的准确率,并显著降低了每次函数调用的延迟。
除了Android功能调用,Octopus v2模型的评估还扩展到了车辆功能调用,显示了算法对不同用例的适应性。研究者们专注于车辆的基本控制方法,如音量调节、空调控制和座椅定位。通过对车辆功能进行基准测试,观察到了与Android功能评估一致的性能模式。此外,使用Yelp和DoorDash API进行的测试也证实了模型在不同功能集上的性能一致性。
在训练Octopus v2模型时,数据集的大小对性能有显著影响。研究者们分析了使用1,000个数据点与只使用100个数据点的API训练模型的性能差异。结果表明,即使只使用100个数据点,模型仍然能够达到98.095%的准确率。这表明在训练新功能集时,可以在保持高性能的同时减少数据生成的成本。
LoRA(Low-Rank Adaptation)在Octopus v2模型框架中扮演了重要角色,尤其是在将模型集成到多个应用程序中时。与使用完整模型训练不同,研究者们选择了针对不同应用程序特定功能设置的LoRA训练。实验结果显示,尽管转向LoRA训练会导致轻微的准确率下降,但维持的高准确率水平对于生产部署来说已经足够健壮。
为了实现平行功能调用和嵌套功能调用,研究者们指出需要为每个API准备4K数据点,以便达到与单一功能调用相同的准确度水平。这表明在更复杂的函数调用场景中,模型需要更多的数据来学习如何正确地执行并行或嵌套的任务。
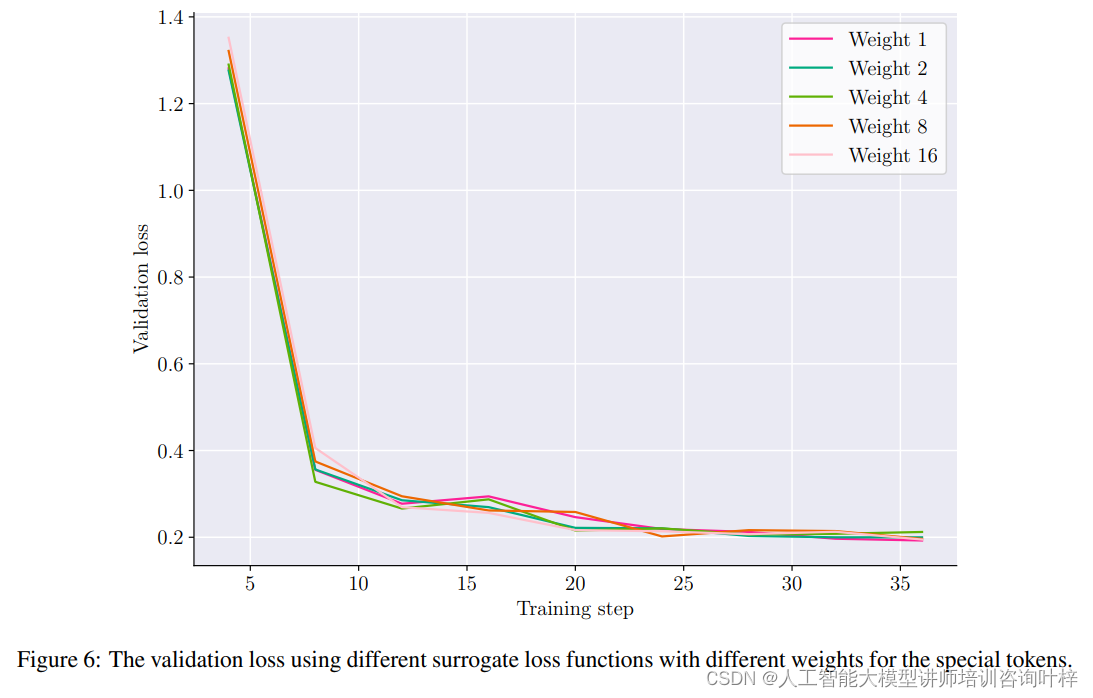
在模型训练中引入特殊令牌时,研究者们面临了数据集不平衡的挑战。为了解决这个问题,他们采用了加权交叉熵损失函数作为替代损失,以改善模型的收敛性。在配置中,非特殊令牌被赋予了1的权重,而特殊令牌则获得了更高的权重。实验表明,在训练过程的早期使用加权损失有助于收敛。然而,实验也发现,使用等权重的令牌损失在微调模型的性能或实际训练时间上没有显著差异。因此对于小数量的功能令牌,推荐使用等权重的损失函数。
通过这些详细的实验设置和评估,Octopus v2模型证明了其在不同场景下的有效性和可靠性。这些实验不仅展示了模型的强大性能,也为未来的研究和应用提供了宝贵的见解和数据支持。
Octopus v2模型的开发为智能设备的语言处理能力带来了突破性的进步。它不仅在准确性和延迟上超越了现有的大型语言模型,而且通过减少上下文长度,降低了模型运行的资源需求。这为智能设备在各种生产环境中的实际应用铺平了道路,同时也为未来的AI技术发展指明了方向。
论文链接:https://arxiv.org/abs/2404.01744



















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











