









人工智能咨询培训老师叶梓 转载标明出处
大模型在生成内容时存在信任度问题,比如可能会产生毫无根据的信息或与检索到的上下文相矛盾。针对这一挑战,加州大学洛杉矶分校(UCLA)的研究人员提出了SYNCHECK,这是一个轻量级的监测工具,能够在生成过程中同步检测不忠实的句子。
方法
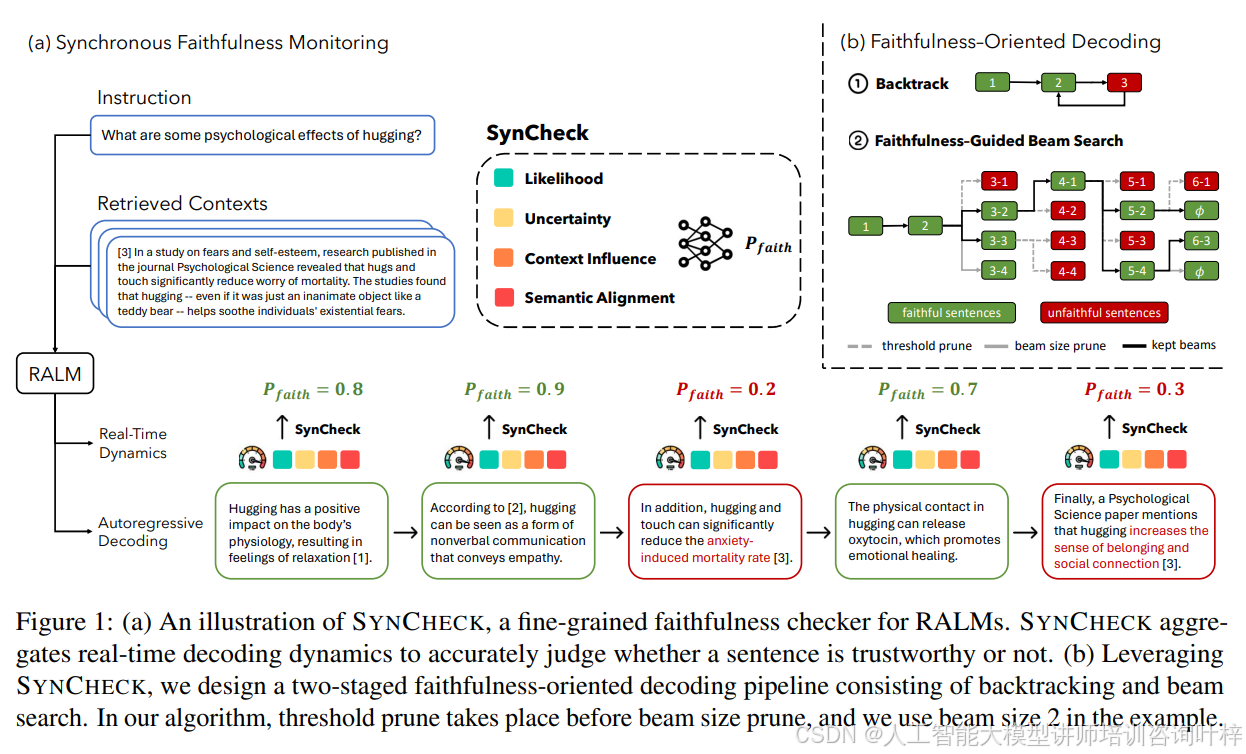
图1展示了SYNCHECK的工作原理和结构。分为两个主要部分:同步可信度监控和可信度导向解码。图1a展示了SYNCHECK如何聚合多个信号来评估每个句子的忠实度,而图1b则展示了如何利用这些信号来指导束搜索过程。
SYNCHECK方法的核心在于实时监控大模型的解码过程,并检测可能的不忠实行为。它通过分析以下几个关键信号来实现:
-
似然性: SYNCHECK计算句子的最小似然性和长度归一化似然性,以检测知识盲点。低似然输出通常表明模型在生成响应时缺乏足够的知识支持。
-
不确定性:通过监控句子中每个标记的熵以及中间层激活的局部内在维度,SYNCHECK可以捕捉模型在生成文本时的不确定性,这可能表明模型对其使用的知识点不自信。
-
上下文影响:SYNCHECK比较了两种分布——包含上下文的分布和不包含上下文的分布——通过计算两者之间的Kullback-Leibler散度,来评估模型对检索到的上下文的依赖程度。
-
语义对齐:即使模型显示出高置信度,其输出也可能与上下文信息不匹配。SYNCHECK使用轻量级蕴含检查器来评估生成的句子是否在语义上与检索到的上下文一致。
SYNCHECK将这些信号综合起来,通过一个轻量级的聚合器(可以是逻辑回归、XGBoost或MLP模型)来学习区分忠实和不忠实文本的特征。
有了SYNCHECK产生的实时监控信号,能否进一步设计有效的干预方法来提高RALM输出的忠实度?放弃或选择性预测是直接的应用:在检测到潜在质量问题后,系统可以拒绝生成任何输出。然而,粗粒度的二元放弃决策会浪费模型生成的相当一部分忠实信息。为了设计一种更有原则的方法来提高输出的忠实度,同时增加保留的信息量,引入了FOD,这是一个面向忠实度的大模型解码算法。
FOD方法利用SYNCHECK提供的实时监控信号来指导解码过程,以提高输出的忠实度。FOD方法包括两个阶段:
-
贪婪搜索和回溯:FOD首先运行贪婪搜索,直到遇到一个忠实度分数低于预设阈值的句子,这时会触发回溯操作。
-
忠实度引导的束搜索:从上一步的最后一个忠实句子开始,FOD在多个束中并行搜索,对每个束的延续进行采样,并直接剪枝掉那些忠实度分数低于另一个阈值的样本。然后,保留具有最高忠实度分数的K个束。

算法1 提供了FOD的详细步骤,包括如何使用SYNCHECK来评估和选择忠实度最高的束。这个过程涉及到对每个生成的句子进行忠实度评分,并根据这些评分来动态调整搜索方向。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
实验
任务和数据集收集:
- 实验涉及四种常见的长文本生成任务:问答(QA)、摘要(Summ)、数据到文本(Data2txt)和传记生成(Biography)。
- 使用了RAGTruth基准测试,它提供了来自不同数据源的问题和检索上下文,包括MS MARCO、CNN/Daily Mail和Yelp开放数据集。
- 对于传记生成任务,作者创建了两个新数据集F-100和F-100-anti,模拟容易产生不忠实生成的情况。F-100的上下文从维基百科检索而来,而F-100-anti则通过实体替换从另一个实体检索的证据来创建上下文。
- 数据集的划分遵循RAGTruth的train-test split,而新创建的数据集则只有一个测试分割。
上下文忠实度跟踪:
- 主要测试了两个大模型:Llama 2 7B Chat和Mistral 7B Instruct。
- 对于FS、F-100和F-100-anti,通过贪婪解码收集输出。对于QA、Summ和Data2txt,直接利用RAGTruth提供的输出。
- 使用NLTK库将输出分解为句子,并为每个句子分配忠实度标签。对于QA、Summ和Data2txt,使用人工标注的基础less spans和conflict spans作为不忠实的段落。对于FS、F-100和F-100-anti,使用预先训练的propositionizer将输出分解为去上下文化propositions,并使用AutoAIS模型判断每个proposition的忠实度。最后,使用词汇匹配算法将span/proposition级别的忠实度标签映射到句子级别。
基线对比:
- 将SYNCHECK与几种忠实度检查基线进行比较,包括SPANEXTRACT、CRITICTOK、FLARE、ALIGNSCORE和MINICHECK。这些方法分别从不同的角度评估输出与上下文之间的忠实度。
评估指标:
- 报告了两个响应级别的指标:忠实度和信息量。忠实度被设计为proposition级别的上下文一致性,使用Chen等人(2023)提出的模型将响应分解为propositions,并使用Min等人(2023)提出的retrieval+llama+npm方法直接用C作为上下文进行事实核查。忠实度报告为所有propositions中忠实propositions的比例。信息量则报告响应中的propositions数量。对于放弃或空响应,我们将其从忠实度评估中排除,但将信息量分数设为0。
实验结果:
- 在表1中展示了所有上下文忠实度跟踪方法的AUROC结果。SYNCHECKMLP在两种大模型上,平均在六个任务中实现了最强的性能。这表明SYNCHECKMLP在忠实度检测方面优于其他方法。
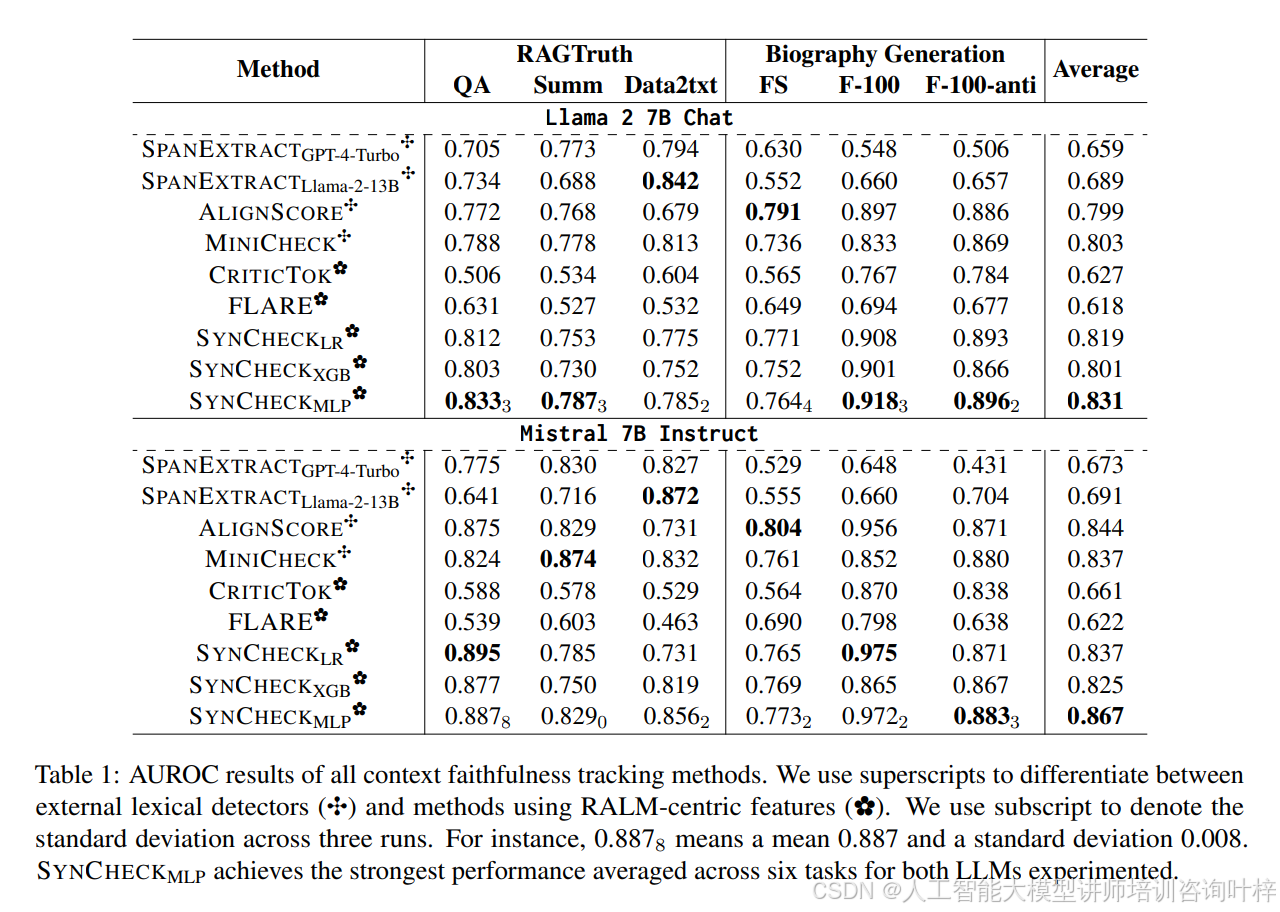
实验展示了SYNCHECK和FOD方法在提高大模型输出忠实度方面的有效性。通过与现有方法的对比,证明了所提出方法的优越性。




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











