









人工智能咨询培训老师叶梓 转载标明出处
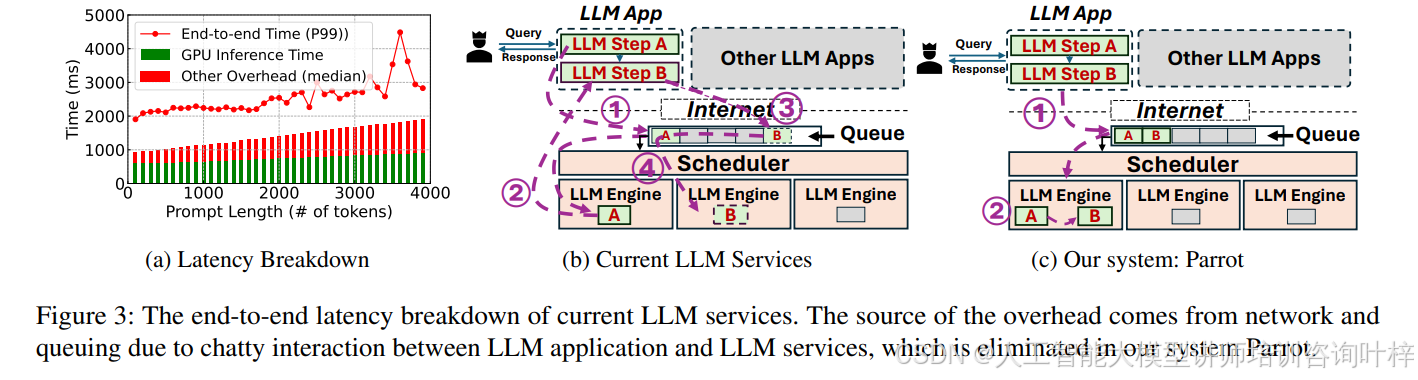
LLM应用通常需要通过多轮对话来完成任务,这些对话通过多个API调用来实现,表现出复杂的工作流模式。然而,公共LLM服务提供商面对不同租户和应用,每个都有不同的工作流和性能偏好。现有的LLM服务API设计仍然以请求为中心,无法了解应用级信息,例如哪些请求属于同一应用,不同请求之间的连接方式,或者是否存在任何相似性。这种信息的丢失导致公共LLM服务只能盲目优化单个请求的性能,导致LLM应用的端到端性能不佳(图3)。
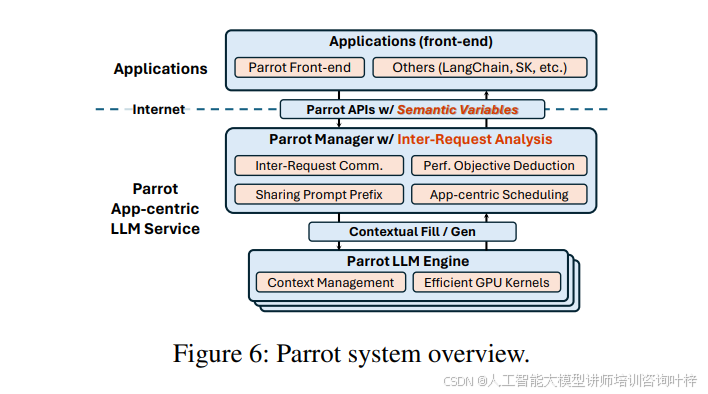
本文介绍了Parrot,这是一个由上海交通大学和微软研究院共同提出的LLM服务系统。Parrot专注于提升基于LLM应用的端到端体验,通过引入语义变量(Semantic Variable)这一统一抽象概念,将应用级知识暴露给公共LLM服务。语义变量用于注释请求提示中的输入/输出变量,并在连接多个LLM请求时创建数据管道,为编程LLM应用提供了一种自然的方式。通过公开语义变量,Parrot允许公共LLM服务执行传统的数据流分析,揭示多个LLM请求之间的关联,为端到端性能优化开辟了新的优化空间。图6展示了Parrot如何通过语义变量和应用中心的LLM服务来优化LLM应用。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
Parrot系统设计详解
设计概述
Parrot 旨在通过语义变量(Semantic Variable)的标注,提供一种自然的大模型应用编程方式。这种方式与现有的大模型编排框架(例如LangChain)兼容。基于这种抽象,Parrot Manager 被设计用来在集群级别调度大模型请求,通过派生应用级知识并优化应用的端到端性能。Parrot Manager 将大模型请求调度到LLM Engine,LLM Engine由一个或一组GPU服务器组成,能够独立服务大模型请求。

在Parrot中,一个大模型请求被视为一个语义函数,使用自然语言实现并由大模型执行。语义变量被定义为语义函数的输入或输出变量,在提示中被称为占位符。图7展示了一个简化的多代理应用示例,类似于MetaGPT。它包含两个语义函数:一个用于软件工程师编写代码,另一个用于QA工程师编写测试代码。它有三个语义变量:task、code和test,分别对应任务描述、软件工程师开发的代码和QA工程师开发的测试代码。
与传统的完成API不同,Parrot将完成请求分为提交操作和获取操作。调用语义函数会触发提交API,提交带有提示和输入语义变量的大模型请求。语义函数的执行是异步的,因此它返回输出语义变量的期货。通过获取API,应用可以按需从公共大模型服务中获取输出语义变量的值。这种异步设计允许Parrot支持的大模型服务接收所有不受本地函数阻塞的大模型请求,并实时分析它们的关系。

图8展示了用于请求间分析的原语,包括PrefixHash、GetProducer、GetConsumers和GetPerfObj等。这些原语用于从语义变量中提取大模型请求的哈希值,支持静态和动态生成的内容,以及在相同类型应用或不同应用间的请求中检测共同性。
Parrot主要通过两种应用级信息进行请求间分析:请求的DAG(有向无环图)和提示结构。Parrot在每个用户的注册会话中维护一个类似DAG的数据结构。每个节点要么是一个请求,要么是连接不同请求的语义变量。当一个请求到达时,Parrot通过链接语义变量在提示中的占位符将其插入DAG。Parrot可以执行传统的数据流分析,使用原语获取语义变量的生产者和消费者,恢复大模型请求的依赖关系。
语义变量的优化
为了避免不必要的客户端执行,需要在应用层面上识别请求的依赖关系,这在当今的公共大模型服务中是丢失的。Parrot通过图基执行器高效地服务依赖请求。执行器不断轮询,一旦准备就绪(即生产者请求全部完成),就将其发送到相应的引擎,这允许即时执行并最大化批处理机会。
为了优化应用的端到端性能,需要了解应用级性能标准。Parrot通过其原语派生的大模型请求的DAG来理解大模型应用的工作流程,从而帮助从端到端应用性能需求中派生请求级调度偏好。当一个应用将语义变量标注为偏好更高的吞吐量时,所有生成这个语义变量的请求(直接或间接)在调度时将被标记为吞吐量优先。
当一个大模型请求被调度到一个大模型引擎时,会在引擎上创建一个上下文来存储此请求的模型执行状态(主要是KV缓存)。Parrot通过暴露语义变量给大模型服务,能够理解提示结构,自动在语义变量的粒度上高效地检测共同性。使用Parrot的PrefixHash原语,Parrot只需要检查请求提示中每个语义变量后的位置的哈希值。Parrot维护一个键值存储,每个条目将(哈希化的)令牌前缀映射到请求列表,从而调度器可以快速在线检查机会。
为了解决现有公共大模型服务盲目优化不同个体请求的问题,Parrot的调度策略利用应用级知识来优化端到端性能。Parrot的调度器的主要目标是满足大模型应用的多样化性能目标,同时优化GPU集群利用率。Parrot的调度原则是:将具有相似性能要求的大模型请求分组以避免冲突,并最大化跨请求的共享机会。

算法1概述了Parrot的调度过程。系统根据其拓扑顺序安排大模型请求。Parrot倾向于将属于同一应用的请求一起调度,以避免交错调度的减速。对于通过Parrot的性能目标推导被识别为任务组一部分的请求,调度器尝试将整个任务组一起分配。此外,如果Parrot检测到其他排队请求或运行上下文具有共同前缀,它尝试将它们分配到同一个大模型引擎,利用Parrot的上下文分叉减少冗余计算和GPU内存事务。
Parrot目前只支持云端编排大模型请求,不涉及动态控制流和本地函数。这些扩展进一步启用了新的优化,例如,可以根据过去的配置文件推测性地预启动动态应用中的高概率分支。这也证明了Parrot的设计在面对新类型应用时的潜力。
实现
Parrot用于大模型应用,用Python实现,大约有14,000行代码。其前端提供语义变量和语义函数的抽象,这些抽象被转换为Parrot的API(用FastAPI实现)以提交大模型请求。一个集中的Parrot管理器处理大模型请求的管理,包括语义变量、通信和调度。还构建了一个基于vLLM、xFormers和自己的高效内核的大模型引擎。该引擎支持大模型服务的高级功能,包括分页内存管理和持续批处理。
Parrot的前端和管理者分别用1,600行和3,200行Python实现。Parrot的大模型引擎用5,400行Python和1,600行CUDA实现。我们已经用PyTorch和Transformers实现了OPT和LLaMA。
实验
Parrot的评估通过一系列实验来验证其在提升大模型应用性能方面的有效性。实验分为单GPU和多GPU设置,涉及四种具有代表性的大模型应用场景:长文档数据分析、多用户大模型应用、多代理应用和聊天服务工作负载。
实验平台包括一台配备24核AMD-EPYC-7V13 CPU和一块NVIDIA A100 (80GB) GPU的服务器,以及一台配备64核EPYC AMD CPU和四块NVIDIA A6000 (48GB) GPU的服务器。这些服务器运行CUDA 12.1和cuDNN 8.9.2,为大模型应用提供支持。
工作负载:实验涉及的大模型应用包括使用Arxiv数据集进行长文档数据分析、基于Bing Copilot和GPTs的多用户大模型应用、基于MetaGPT的多代理应用,以及基于ShareGPT数据集的聊天服务工作负载。这些应用覆盖了大模型在不同场景下的使用需求。
基线:Parrot的性能与使用LangChain和FastChat的大模型应用进行比较。FastChat是一个开源的大模型服务系统,支持HuggingFace的Transformers库和vLLM,具备FlashAttention、PagedAttention和连续批处理技术。
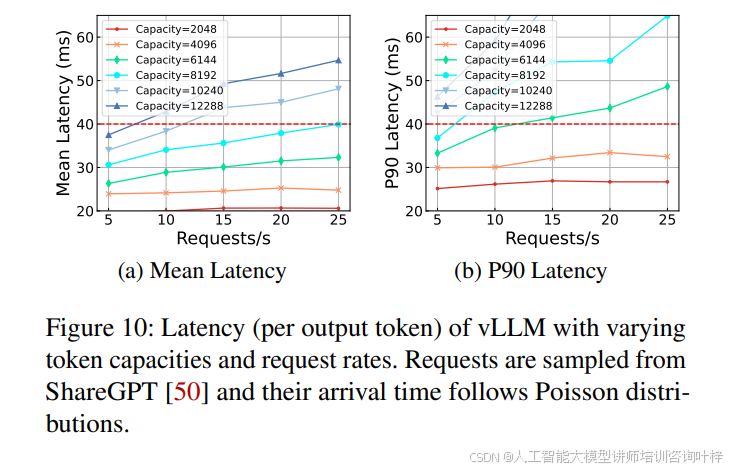
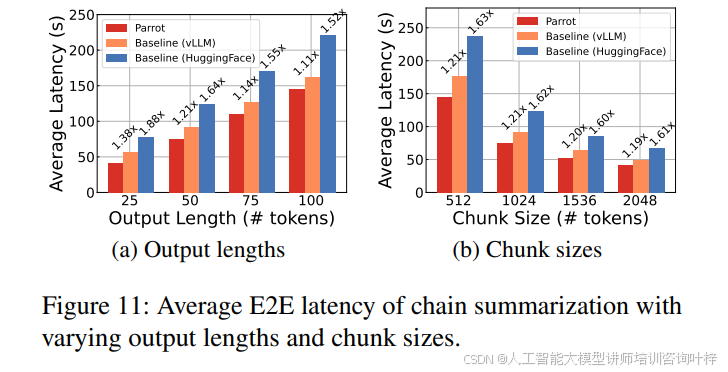
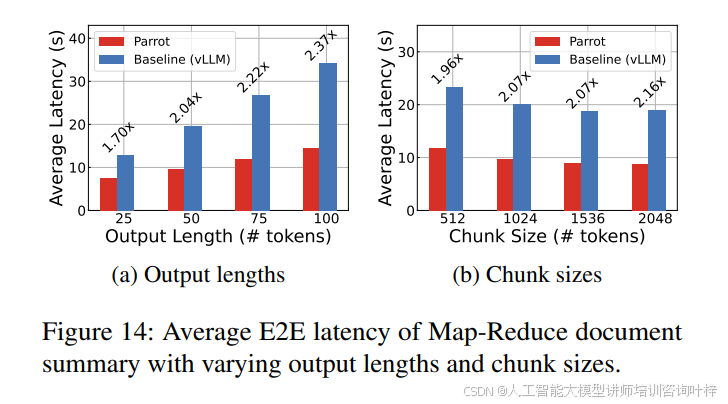
图10展示了vLLM在不同令牌容量和请求速率下的延迟。Parrot通过减少客户端交互显著降低了端到端延迟,尤其是在处理短输出时。例如,在链式摘要应用中,Parrot通过减少网络延迟和客户端交互,实现了高达1.38倍和1.88倍的延迟减少,如图11所示。在Map-Reduce摘要应用中,Parrot通过识别任务组并优化整个任务组的延迟,实现了2.37倍的加速,如图14所示。
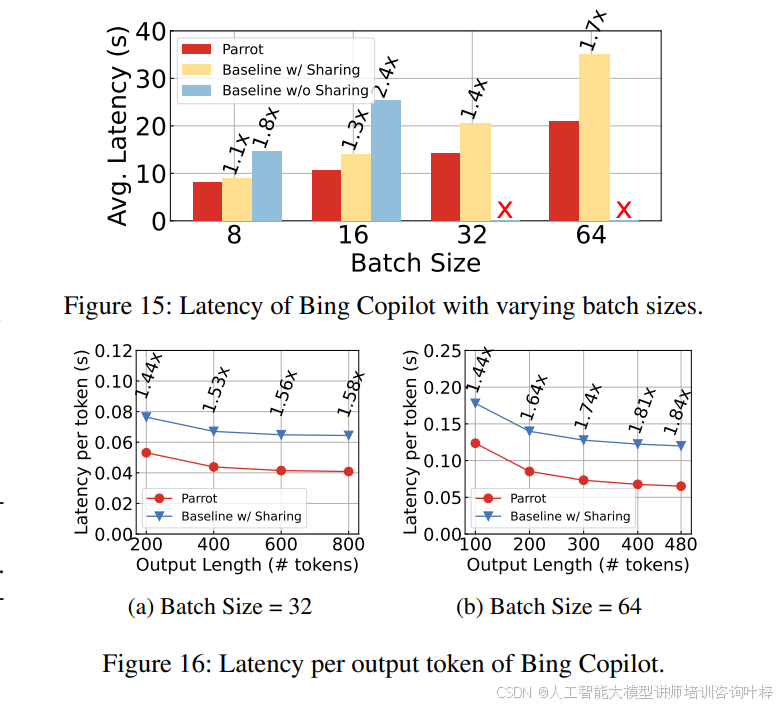
在处理多用户大模型应用时,Parrot通过共享长提示前缀,实现了1.8倍至2.4倍的加速,如图15所示。Parrot的GPU内核优化进一步减少了内存加载,提高了性能,如图16所示。
在多代理应用中,Parrot通过识别任务组并优化整个任务组的延迟,实现了高达11.7倍的加速,如图18所示。Parrot通过减少冗余和优化GPU内核,显著降低了延迟和内存使用,特别是在多文件编程场景中。
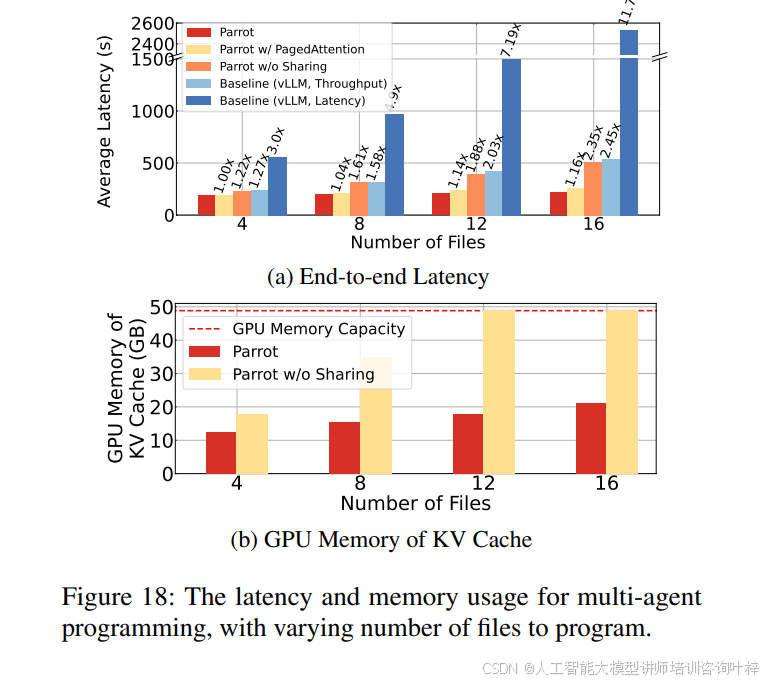
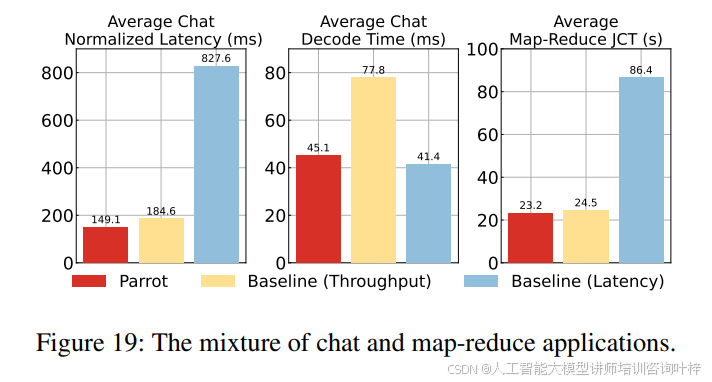
图19展示了Parrot在混合工作负载中的调度能力。Parrot为聊天应用提供了低延迟,同时为数据分析任务提供了高吞吐量,从而提高了大模型服务的整体性能。Parrot通过智能地在不同引擎上调度聊天和Map-Reduce工作负载,减轻了它们之间的竞争,实现了5.5倍和1.23倍的标准化延迟改进。
Parrot在优化大模型应用端到端性能方面表现出色,无论是在单GPU还是多GPU设置中。通过减少客户端交互、共享提示前缀、识别任务组和优化GPU内核,Parrot显著提高了大模型应用的性能和效率。这些评估结果证明了Parrot在处理多样化大模型应用需求时的有效性和优越性。



















 1471
1471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











