






Multiscale Vision Transformers
下载论文
Haoqi Fan, Bo Xiong, Karttikeya Mangalam
ICCV 2021
Abstract
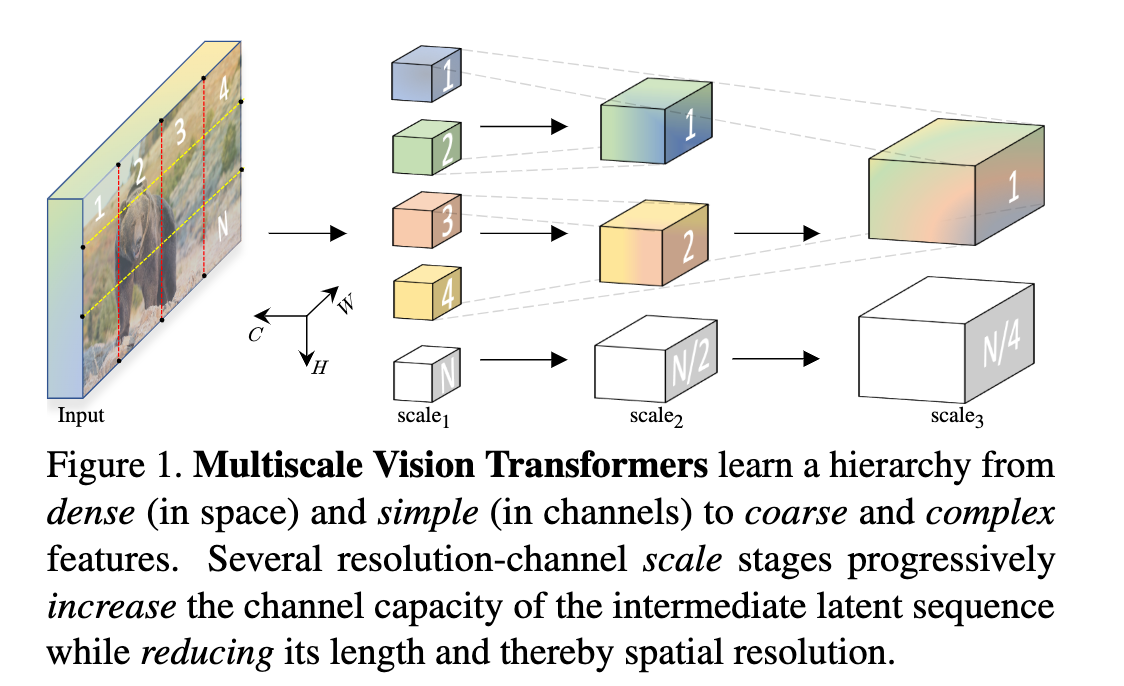
我们将多尺度特征层次的基本思想与transformer模型相结合,提出了用于视频和图像识别的多尺度vision transformer(MViT)。多尺度transformer有一系列的通道分辨率尺度级别。这些阶段从输入分辨率和较小的通道维度开始,在降低空间分辨率的同时,逐级增加通道容量。这创建了一个多尺度的特征金字塔,浅层在高空间分辨率下运行,以建模简单的低级视觉信息,而更深的层在粗糙空间下运行,但建模复杂的高级特征。我们评估了这种基础架构先验,用于为各种视频识别任务建模视觉信号的密集性质,在这些任务中,它优于依赖大规模外部预训练的并发视觉转换器,并且计算和参数成本高出 5-10 倍。我们进一步去除了时间维度,并将我们的模型应用于图像分类,它优于先前在vision transformer上的工作。
要解决的问题
- 动机:在低空间分辨率下工作可以降低计算需求;在较低分辨率下可以更好地理解“上下文”,然后可以指导更高分辨率下的处理
- 将多尺度特征层次的基本思想与vision transformer模型进行结合
找问题点的位置:
- Abstract
- Introduction每一段的最后一两句
- Conclusion
Method
模型Multiscale Vision Transformer(MViT)架构建立在阶段的核心概念之上,每个阶段由多个具有特定时空分辨率和通道维度的transformer 块组成。
1. Multi Head Pooling Attention(MHPA)
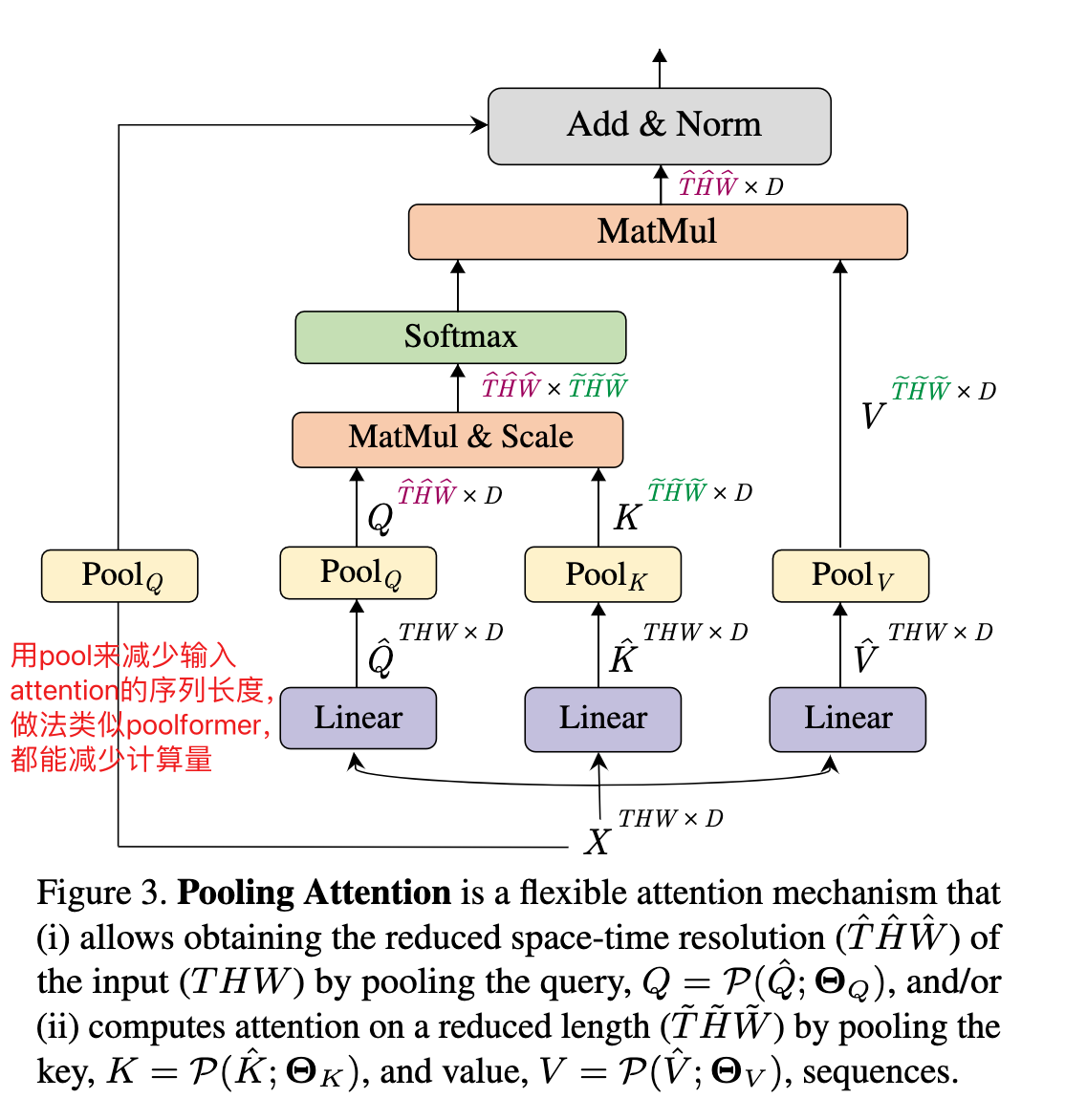
-
Pooling Operator,在输入之前,对中间张量Q,K,V进行池化,这是MHPA的基石,也是多尺度Transformer架构的基础
-
THW分别代表:T,帧维度;H,高度维度;W,宽度维度
-
pool 的kernel size是三维的
-
缩减的效果如下
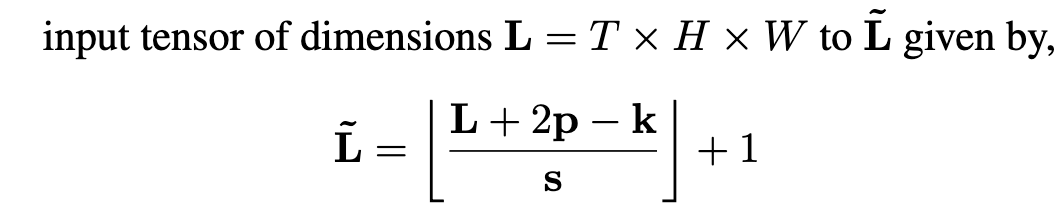
-
2. Multiscale Transformer Networks


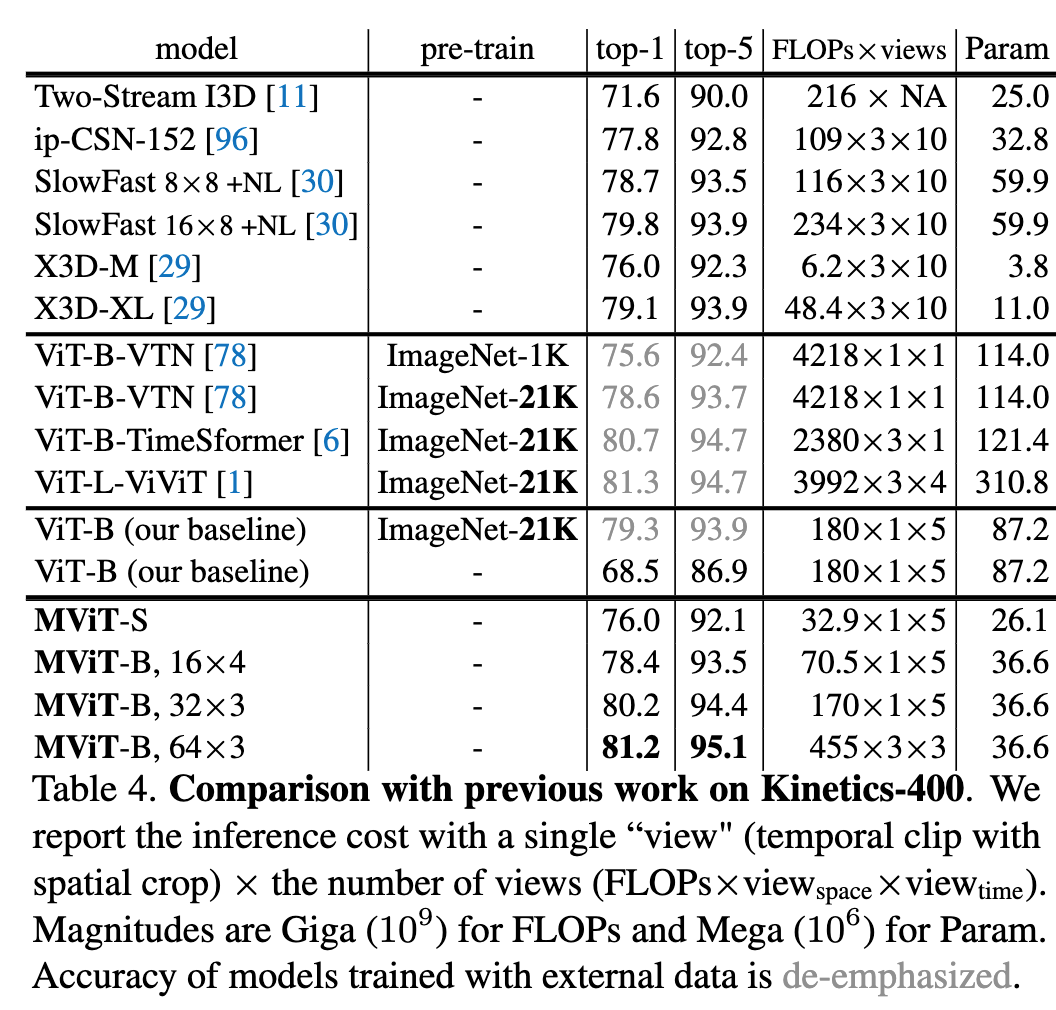
Experiment

总结
-
这篇文章提出了多尺度的vision transformer,将多尺度的概念与transformer结合了起来
-
参考了CNN中特征金字塔的方式,层次性地扩展了通道维度,同时减少时空分辨率
-
相比ViT,优势在于对时间特征的捕捉更加优秀,经shuffle实验可以看到,ViT注重的是画面信息,而MViT可以充分学习时间信息

-
这篇论文的方法简单有效,采用pooling的方式来控制transformer的计算量,PoolFormer(2022年)也是类似的做法,论文是MetaFormer is Actually What You Need for Vision,可以再去看看这个论文, 值得借鉴作为backbone使用,但是对于效果好的原理还是没能想明白,大概是pooling操作提取了有效信息,丢弃了冗余信息。















 3551
3551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









