







 该研究提出一种结合ViT与CNN的新型网络结构,解决了基于深度学习的图像隐写分析中局部与全局特征融合的问题。通过引入注意力机制和卷积Transformer,有效地提升了对各种尺寸图像的隐写检测能力。
该研究提出一种结合ViT与CNN的新型网络结构,解决了基于深度学习的图像隐写分析中局部与全局特征融合的问题。通过引入注意力机制和卷积Transformer,有效地提升了对各种尺寸图像的隐写检测能力。
复旦大学 Ge Luo, Ping Wei, Shuwen Zhu
ICASSP 2022「B类会议」,包括语音、信号等多个方向
摘要
问题: 提出基于深度学习的网络结构一般会堆叠很多的卷积层用来增加图像隐写的局部接受野,但是具有多个卷积层的检测器无法从全局角度有效提取隐写图像特征。
解决: 提出一种将viT用于隐写分析上的网络体系,利用viT的注意力机制进行特征提取和分类,捕获噪声特征之间的局部和全局依赖性。
实验结果: 在固定大小和任意大小的数据集表现良好(BOSSbase 1.01和ALASKA #2)
引言
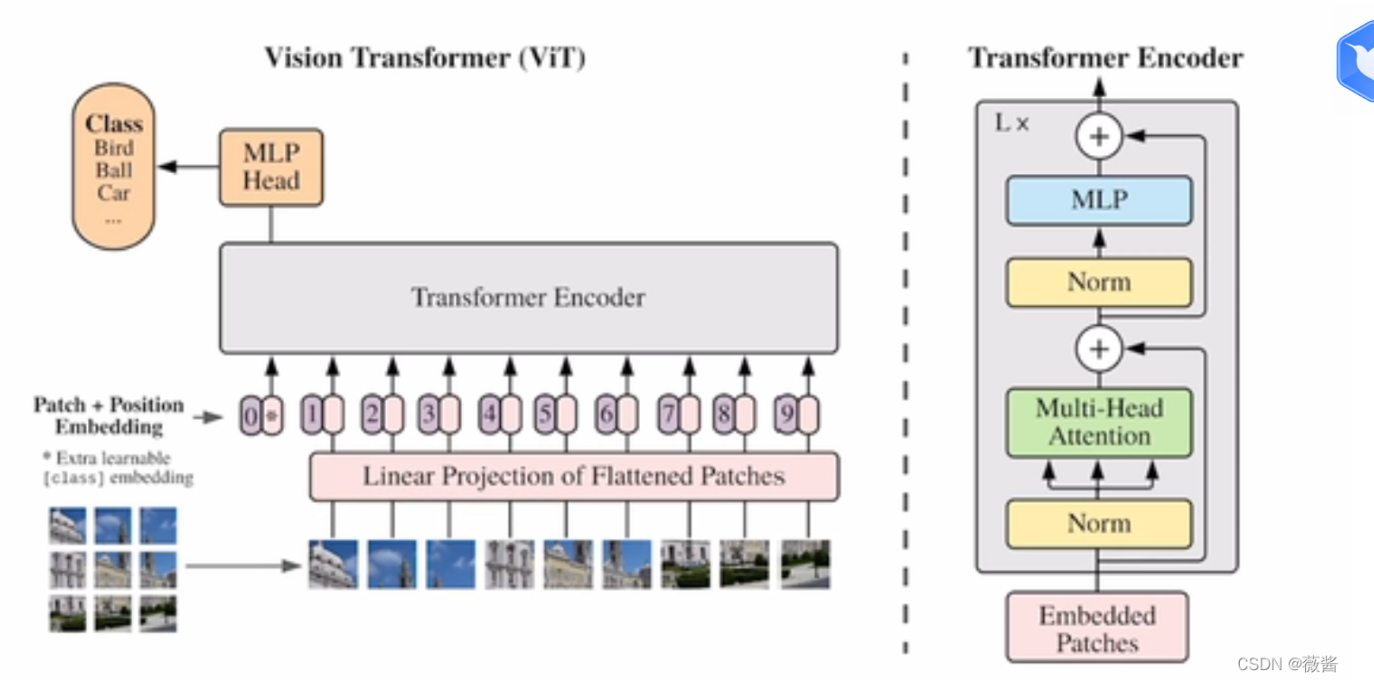
介绍隐写分析的定义-》 隐写分析分类(1.传统人工定义特征 2. 深度学习) -》 提出现有的基于CNN隐写分析方法局限性,未能利用隐写信号特征之间的全局关系,检测大图像,聚集能力低下 -》 引出本文新模型新方法 (如下图所示) -》
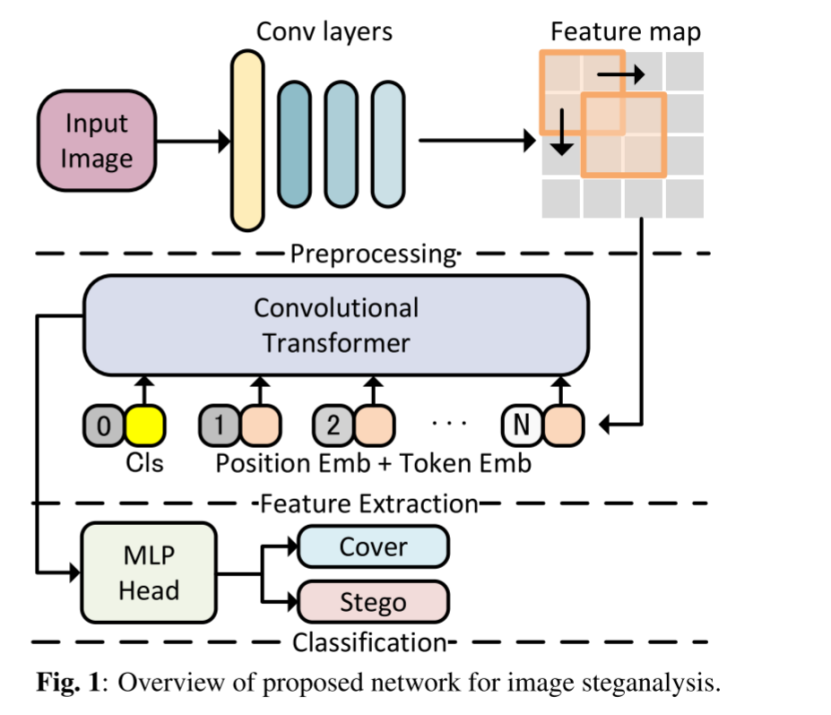
-》 提出本文主要贡献
-
用于图像隐写分析的卷积viT,从局部和全局提取噪声残差
-
应用带信道注意模块的卷积层在预处理阶段利用全局信息。
-
引入卷积transformer,全局自注意力使隐写分析网络能够在特征提取阶段学习噪声残差之间的关系。
-
与异构数据集上的现有方法相比,我们的网络在固定大小的数据集上提供了令人满意的性能,它提高了检测精度。
方法
网络结构
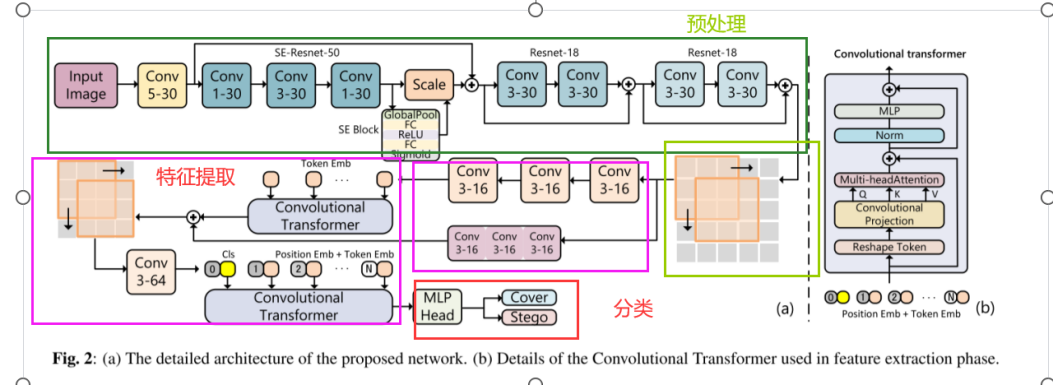
-
预处理阶段:用SRM滤波器内核(Conv5-30)初始化第一卷积层权重,使用一个Resnet50 额外添加了通道注意力模块SE Block,两个Resnet18
-
特征提取阶段:应用两个改进版本的卷积transformer,从全局角度有序提取噪声残差特征向量。将预处理的输出特征图 经过3个Conv3-16内核,又展平作为token embedding 输入到卷积transfomer,其中再加上3个额外的粉红色卷积层残差连接,融合预处理层输出的逐层局部特征和 卷积transformer输出的全局噪声特征 ,重新形成特征图后,下一个阶段又继续卷积+position embedding+transformer(类似viT)
-
分类阶段:利用MLP head 和cls token 进行二分类
【不太懂论文里说, 处理任意大小的输入图像时,可以附加到SID,提取最后的的特征图统计矩】
信道注意力模块
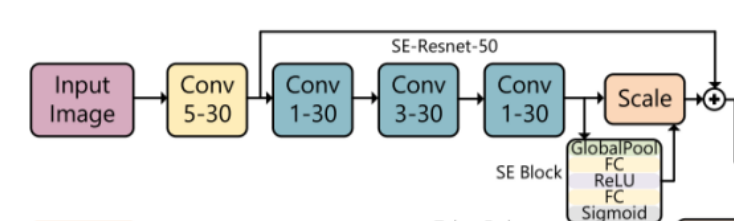
利用30个通道之间的关系,通过信道注意力机制提高噪声残差质量,强调噪声特性。
融合卷积层学习到的局部空间相关性和来自不同信道的全局信息 SE block : Squeeze and Excitation “Squeeze”操作将输入特征图 U ∈ R(H × W × C) 压缩为1 × 1 × C map(1 × 1 × 30)
通过堆叠层(Globalpool 层、 FC 层、 relU 层、 FC 层、 S形函数)一个接一个地表示
“Excitation” 操作将后续输出映射到30通道权重。 “Scale” 块中使用这些通道权重缩放来自三个卷积层的输出
卷积transformer
特点: 捕获全局依赖关系时,保留部分卷积,对局部关系建模。
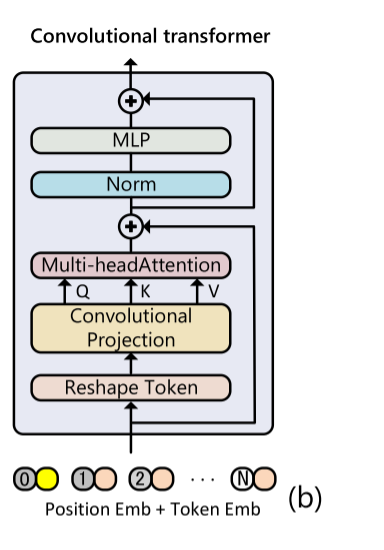
卷积transformer 不是线性投影,而是在自注意力前使用卷积投影
将输入token重塑为2Dtoken -> 再进行卷积投影成1D,作用于Q/K/V
位置编码
提供位置信息,有效捕获全局图像特征。
本网络是在特征提取阶段的第一个卷积transformer未加位置编码,而是在第二个卷积transformer加了位置编码
因为: 若在第一transfomer中, 网络会错误的认为是隐写信号,将影响检测
卷积投影
卷积投影使得transformer强调局部空间信息
实验
实验设置
-
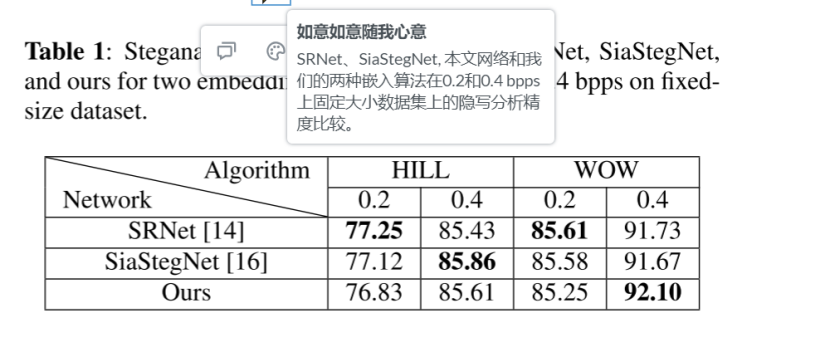
两种内容自适应隐写术方法,HILL [22],WOW [23],已分别用于生成隐写图像。我们提出的网络与SRnet [14] 和SiaStegNet [16] 进行了比较。
-
所有实验结果均使用Nvidia GTX 1080Ti GPU卡获得。
数据集
固定大小: BOSSbase 1.01 256*256 的12000/2000/6000图像作为训练/验证/测试
任意大小: ALASKA_512 【80000 张512*512】 24000/4000 训练/验证 ALASKA_VAR 【包含16组不同大小图像】 每组的750张图像测试(总计12000)
超参
初始lr=0.0001 300epoch降为0.00001 batchsize=32
固定大小数据集结果
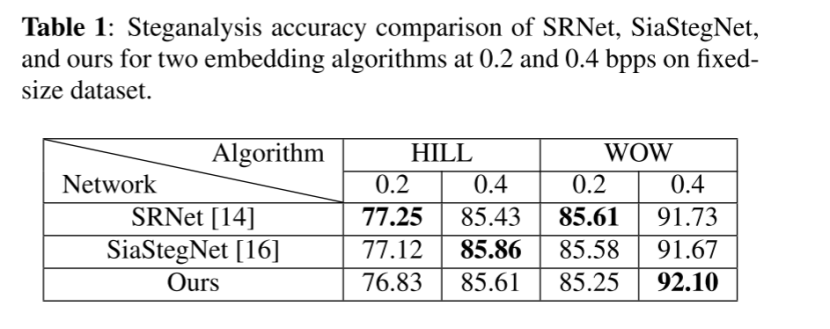
我们的网络在检测固定大小图像性能与SRNet和SiaStegNet非常匹配
检测在WOW 0.4bpp隐写算法中,92.1%的准确性,高于其他两种网络3个百分点
然而其他两种网络在HILL上更出色些
总结: 对于固定尺寸,卷积transformer提供的局部+全局信息融合能力未完全实现
任意大小数据集结果
----用基于Siamese主干的卷积viT替换子网,WOW在0.4bpp生成512*512stego图像
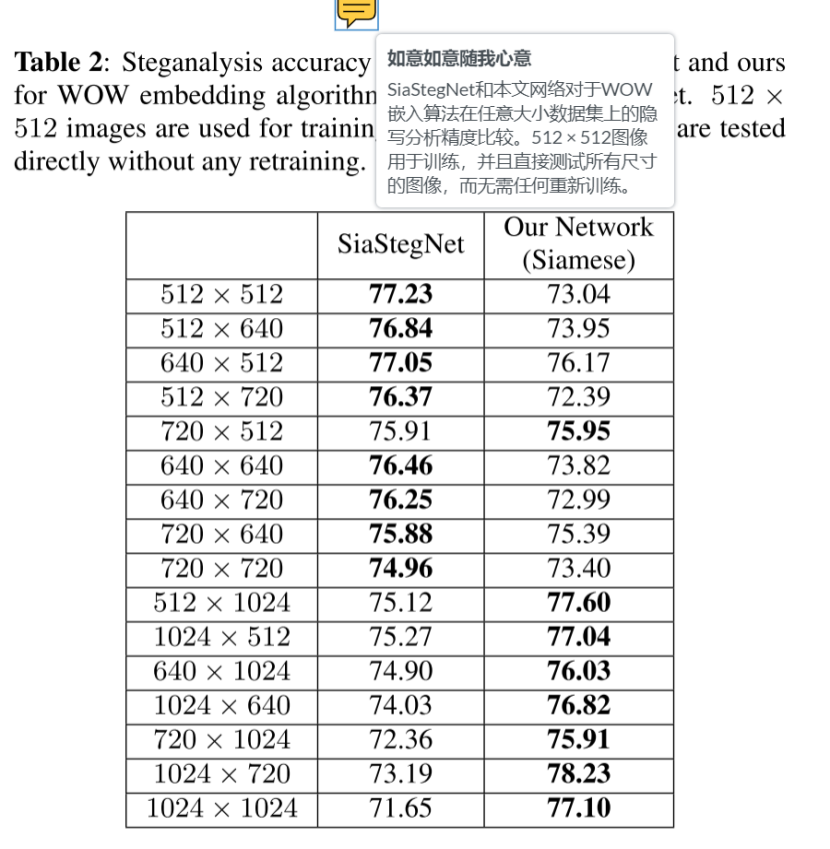
---检测较小尺寸【512 * 512至720 * 720】,SiaStegNet优于我们网络性能
---但在大图像测试,我们网络效果极好
消融实验
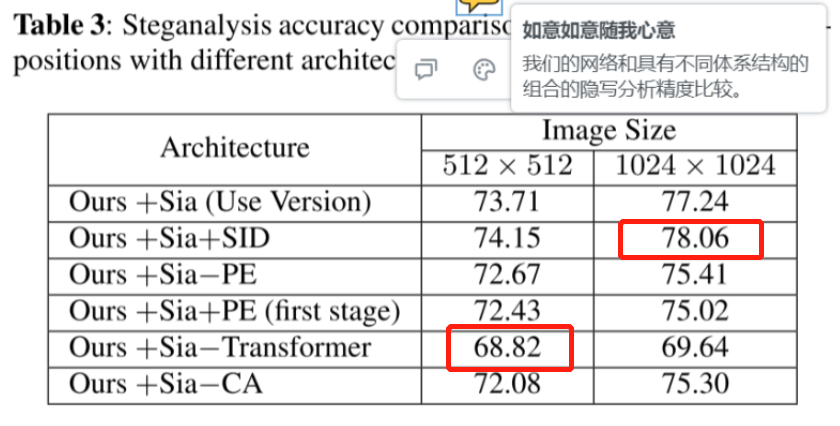
可以明显看到:网络删除Transformer时,精度急剧下降
检测大图像,SID 和Sia可提高检测性能
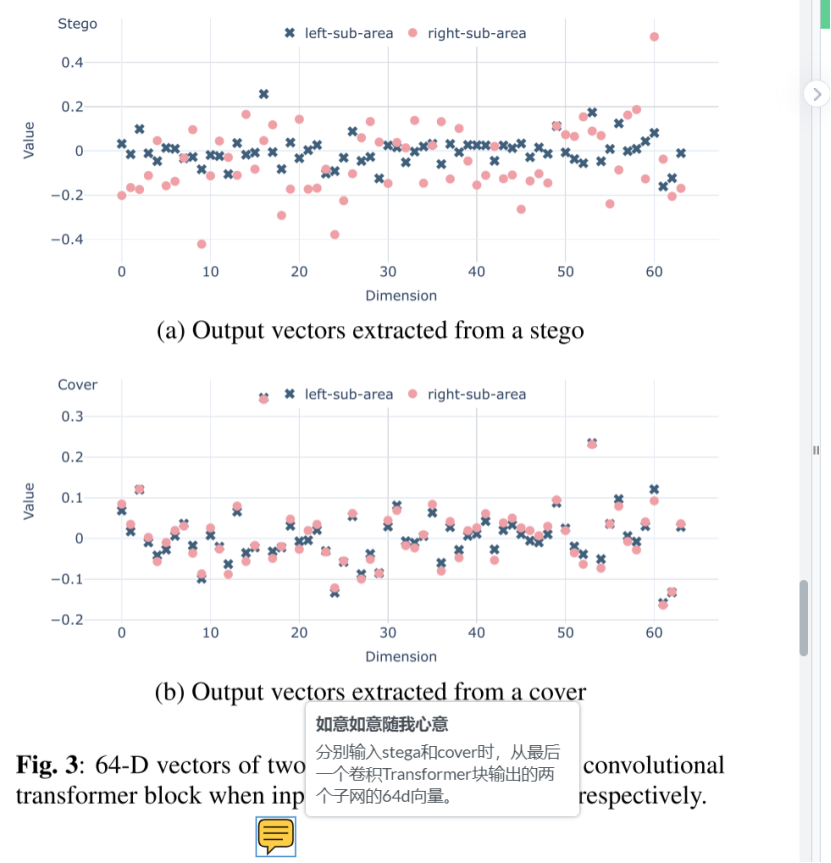
卷积transformer 可以有效地区分stego和cover
从图上可以看到,cover 在64维度不同区域的值几乎相等 但是stego却截然不同
结论
基于CNN+vision transformer提供的自注意处理异构数据集
网络优势:
(1) 将channel attention融合到预处理阶段,可以利用信息产生全局的图像残差。 (2) 在特征提取阶段,我们使用convoluntional transformer从局部和全局角度提取噪声残差的特征。 (3) 我们以合理的步骤将positional embeddings添加到token嵌入中,以增强全局注意力,从而进一步提高检测精度。
未来的工作将集中在基于vision transformer的用于图像隐写分析的新型体系结构上。

















 1534
1534

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









