







看到这篇文章的读者朋友应该对RNN和LSTM的基本结构有了一定的认识,下面就简单快速复习一下:
首先说明一下RNN是什么,递归神经网络(recursive neural network)或者循环神经网络(Recurrent Neural Network)的缩写都是RNN,循环神经网络首先被提出,而递归神经网络是循环神经网络的推广,不过现在我们一般不加区分,叫什么都可以,两者一般通用。
下图为RNN的结构示意图:
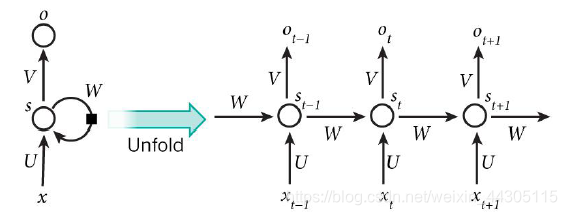
或者是:
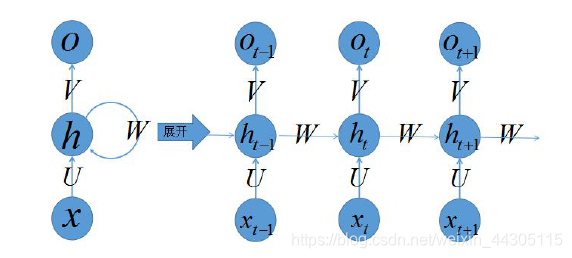
上述图中,,
输入,隐状态,输出等的关系如下:
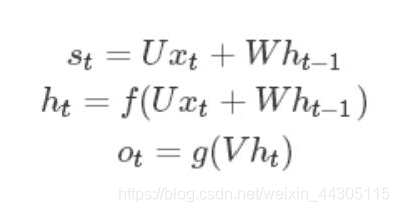
•网络某一时刻的输入xt,和之前介绍的BP神经网络的输入一样,xt是一个n维向量,不同的是RNN(递归神经网络)的输入将是一整个序列,也就是X = [x1,…,xt-1,xt,xt+1,…xT],T表示序列的长度,这也就是说RNN中一个样本就是一个序列。对于语言模型,每一个xt将代表一个词向量,一整个序列就代表一句话(也就是一个样本),T就是这句话包含的单词数量。又由于在神经网络中,我们的输入通常是多个样本作为一个批次的,所以在RNN中数据通常是三维的,也就是[batch_size,seq_len,input_dim]或者[seq_len,batch_size,input_dim],其中,batch_size表示批次大小,也就是一个批次含有多少个序列(句子);seq_len表示一个序列(句子)的长度;input_dim表示某时刻输入数据的维度,也就是这个输入数据的特征数目(features)。
•st是时间t处的“记忆”,相当于对输入值xt和上一时刻的状态值ht-1做了一个线性变换,保留了上一时刻的信息。维度为[batch_size,num_units],batch_size是批次大小,和inputs中的意义相同,num_units表示RNN cell中的神经元数量,从矩阵的线性变换的角度来说,就是将数据转换为多少维的向量,这个向量的维度就是num_units。
• ht代表时刻t的隐藏状态,形状也为[batch_size,num_units],
• ot代表时刻t的输出,我们这里说的输出,是状态值ht先经线性变换(也就是全链接操作)后再经softmax转换得到的最终输出,有些文章也会将ht视作输出,但是其实下一步还需要进行softmax转换才能得到最终结果。
• 输入层到隐藏层之间的权重由U表示,它将我们的原始输入进行抽象作为隐藏层的输入
• 隐藏层到隐藏层的权重W,它是网络的记忆控制者,负责调度记忆。
• 隐藏层到输出层的权重V,从隐藏层学习到的表示将通过它再一次抽象,并作为最终输出。
上式中f可以是tanh,relu,sigmoid等激活函数,g通常是softmax也可以是其他。
值得注意的是,我们说递归神经网络拥有记忆能力,而这种能力就是通过W将以往的输入状态
进行总结,而作为下次输入的辅助。可以这样理解隐藏状态:h=f(现有的输入+过去记忆总结)
辨析:输入序列的序列长度(T)与时间步长(timesteps)的关系是怎么样的呢?
由上文我们可知,同一批次的序列长度是一样的,但是不同批次的序列长度可能不同,具体要看使用的是静态RNN(所有批次序列长度必须保持一致)还是动态RNN(不同批次的序列长度可以不一样),但是在具体计算时,时间步长是和序列步长相匹配的,具体可以参考
https://blog.csdn.net/qq_27825451/article/details/88991529
该文章结合代码讲解了在tensorflow,keras中两者不一致是如何处理的,纠正了网上一些不太严谨的说法,给出了清晰明确的答案。
如果感觉仍是不太明确的同学,建议参考下面这些博客:
https://blog.csdn.net/qq_27825451/article/details/88988755
https://blog.csdn.net/qq_27825451/article/details/88991529
https://blog.csdn.net/qq_27825451/article/details/89015513
通过以上博客及本文,相信你一定对RNN的输入输出维度方面的认知有了比较全面和清楚的认知。

















 382
382

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









