







非RNN说明,RNN基本说明教程可以跳转以下收集的关于rnn的链接链接
Q and A or notice
-
首先:rnn的是一种网络结构而seq2seq是一种架构,(在学习seq2seq时候我混淆了,导致认为例如pytorch的rnn函数输入和输出也可以不同序列长度,这一点错误(即问题2))

-
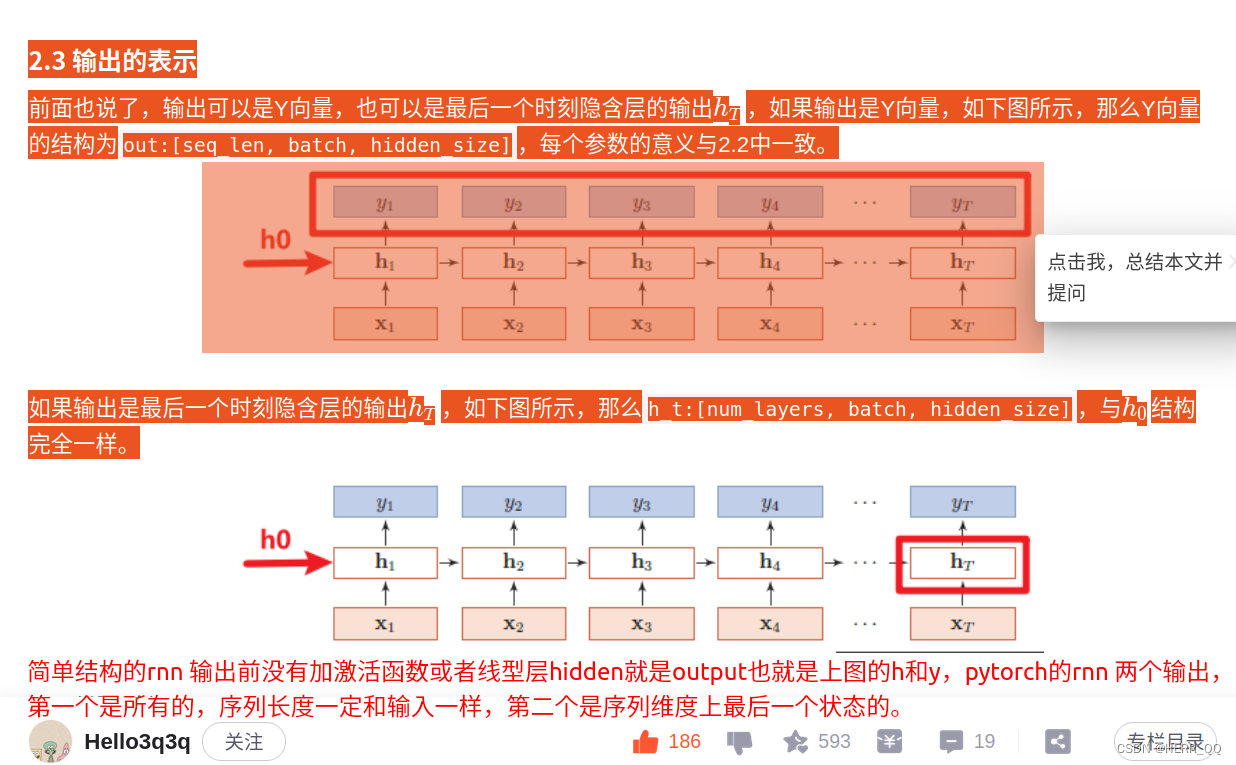
单层纯的RNN单元的输入和输出的sequence的length 一定是相同的 正确吗? 正确
例子 out (16,5,32) hidden(1,16,32), out[:, -1, :] 和 hidden.squeeze(0) 维度都是(16,32) -
怎么样让输入和输出序列的序列维度的长度不一样长呢,用pytorch举一个具体的例子说明,是因为输出只取了输出向量的最后一个值吗?
在某些情况下,RNN的输入序列和输出序列的长度可以不同,这通常发生在序列到序列(Seq2Seq)模型中,其中输入序列和输出序列的长度可以是不同的。一个典型的例子是机器翻译,其中输入是一种语言的句子,输出是另一种语言的句子,而这两个句子的长度通常不同。
下面是一个用PyTorch示例说明这个情况的简单示例:
import torch
import torch.nn as nn
# 假设输入序列长度为3,每个时间步有3个特征
input_sequence = torch.randn(1, 3, 3)
# 创建一个简单的RNN模型
rnn = nn.RNN(input_size=3, hidden_size=2, num_layers=1, batch_first=True)
# 将输入序列传递给RNN
output_sequence, hidden_state = rnn(input_sequence)
# 输出序列的形状
print("Output Sequence Shape:", output_sequence.shape)
在这个示例中,我们创建了一个RNN模型,输入序列的长度是3(3个时间步),每个时间步有3个特征。输出序列的形状将是(1,3,2),因为RNN的输出是隐藏状态序列,每个时间步都生成一个隐藏状态向量。这个输出序列的长度与输入序列的长度相同。
如果您希望输出序列的长度与输入序列的长度不同,通常需要将RNN的输出进行进一步的处理。例如,可以只选择输出序列中的最后一个时间步的隐藏状态,然后将其传递给一个全连接层以生成最终的输出。以下是一个示例:
# 仅选择输出序列中的最后一个时间步
last_hidden_state = output_sequence[:, -1, :]
# 通过全连接层生成最终输出
fc = nn.Linear(2, 1) # 2是隐藏状态的维度,1是输出的维度
final_output = fc(last_hidden_state)
print("Final Output Shape:", final_output.shape)
- 对于以上的第一个例子我有两个问题:1 output_sequence, hidden_state = rnn(input_sequence) 中的hiddenstate是什么 形状是什么 2 他和output之间不同点是什么,因为你这个rnn没有加入激活函数也没有线型层,他和输出是不是同一个东西?(ps: 看了这个大佬的回答和例子我彻底悟了彻底悟了)
很好的问题!让我为您解释一下。
- hidden_state 的形状和定义: hidden_state 是RNN在最后一个时间步的隐藏状态。对于一个基本的RNN,hidden_state 的形状是 (num_layers, batch_size, hidden_size)。在上面的例子中,num_layers 为1,batch_size 为1,hidden_size 为2,所以 hidden_state 的形状是 (1, 1, 2)。 hidden_state
可以被视为RNN的内部记忆。它捕获了之前时间步的信息,并被用于下一个时间步的计算。- outputsequence 和 hiddenstate 的区别: output_sequence 是一个包含每个时间步的隐藏状态的序列。对于每个输入时间步,RNN都会计算一个新的隐藏状态,并将其添加到 output_sequence 中。
而 hidden_state 只是最后一个时间步的隐藏状态。在基本的RNN中(不考虑LSTM和GRU的情况),hidden_state 和 output_sequence 的最后一个时间步实际上是相同的。 使用以下代码,您可以验证这一点:
print(torch.equal(output_sequence[:, -1, :], hidden_state.squeeze(0)))
输出应该是 True,这意味着 output_sequence 的最后一个隐藏状态和 hidden_state 是相同的。
确实,简单的RNN层并不包括激活函数和线性层(在PyTorch的nn.RNN中,内部默认使用tanh作为激活函数)。所以,输出序列的每个隐藏状态和 hidden_state(对于最后一个时间步)基本上是通过应用线性变换和激活函数(例如tanh)得到的。如果您想获得更复杂的输出,您可以在RNN的输出上附加额外的层,例如线性层或其他网络结构。
- 你以上例子的rnn模型没有传递hidden state的接口是内部自己传递了吗
我之前提供的示例中确实没有显式传递 hidden_state,但这是因为 PyTorch 的 RNN 模块默认会在内部处理隐藏状态。RNN
模块在每个时间步都会更新隐藏状态,并在内部维护这个状态。您可以访问隐藏状态,但通常不需要手动传递它,除非您有特定的需求。
在我的先前示例中,hidden_state 是 output_sequence 的最后一个时间步的隐藏状态。 PyTorch 的 RNN
模块将隐藏状态存储在内部,并且当您传递新的时间步数据时,它会自动更新这个隐藏状态。 如果您需要显式地传递 hidden_state,可以使用
initial_hidden 参数来提供一个初始的隐藏状态,或者使用 .forward 方法的 hidden
参数,来手动传递隐藏状态。但在大多数情况下,不需要手动传递隐藏状态,因为 RNN 模块会自动管理它。 以下是手动传递隐藏状态的示例:
import torch import torch.nn as nn
# 假设输入序列长度为3,每个时间步有3个特征
input_sequence = torch.randn(1, 3, 3)
# 创建一个简单的RNN模型
rnn = nn.RNN(input_size=3, hidden_size=2, num_layers=1, batch_first=True)
# 初始隐藏状态
initial_hidden = torch.zeros(1, 1, 2) # 形状是(1, 1, 2)
# 将输入序列传递给RNN,并显式传递隐藏状态
output_sequence, hidden_state = rnn(input_sequence, initial_hidden)
print("Output Sequence Shape:", output_sequence.shape) print("Hidden State Shape:", hidden_state.shape)
- 一个关于维度的附加问题:有一个tensor [[[1,2],[1,2]],[[1,2],[1,2]]] 他的dim 0 ,1,2 分别是什么方向?
这个tensor有三个维度,我们可以按照以下方式理解它们:
1.dim=0: 最外层的方括号。在这个例子中,它有2个元素。我们可以将其视为“批次”维度或“列表”维度,每个元素是一个列表。
2.dim=1: 第二层的方括号。在此例子中,每个“列表”都包含2个元素。我们可以将其视为“序列”维度或“行”维度,每个元素是一个向量。
3.dim=2: 最内层的方括号。在此例子中,每个“向量”都包含2个元素。我们可以将其视为“特征”维度或“列”维度。在许多深度学习上下文中,如处理序列数据时:
4.dim=0 通常表示批次(batch)的大小
5.dim=1 通常表示序列长度(sequence length)
6.dim=2 通常表示特征数或输入维度(input size or feature size)对于给出的tensor: [
[
[1,2],
[1,2]
],
[
[1,2],
[1,2]
] ]7.dim=0 有2个元素
8.dim=1 有2个元素
9.dim=2 有2个元素所以,tensor的形状(shape)是 [2, 2, 2]
- rnn 的维度记录:
x = torch.randn(batch_size, seq_len, input_size) # 输入数据
h0 = torch.zeros(num_layers,batch_size, hidden_size) # 修改后的输入数据
out 是RNN层的输出,它的形状通常是 [batch_size, sequence_length, hidden_size]
8.out.view(-1, hidden_size) 的作用是什么
def forward(self, x, hidden_prev):
out, hidden_prev = self.rnn(x, hidden_prev)
# [b, seq, h]
out = out.view(-1, hidden_size)
out = self.linear(out)#[seq,h] => [seq,3]
out = out.unsqueeze(dim=0) # => [1,seq,3]
return out, hidden_prev
在这里,out.view(-1, hidden_size) 的目的是将 out 从一个三维张量转换为一个二维张量,其中 -1 表示PyTorch会自动计算该维度的大小,以确保其他维度的元素数量保持不变。
具体来说,out.view(-1, hidden_size) 将 out 的形状从 [batch_size, sequence_length, hidden_size] 转换为 [batch_size * sequence_length, hidden_size]。这意味着它会将时间步(sequence_length)和批量样本一起展平,每个时间步的隐藏状态都成为这个二维张量的一行。
这种形状变换通常用于将RNN的输出传递给全连接层(如线性层),以便进行分类或回归等任务。全连接层期望输入为二维张量,因此需要对RNN的输出进行展平以适应这一要求。
8. 注意! linear 层其实只对feature 的size起作用 比如 linear(32,7) 输入为(2,2,32)则输出为(2,2,7)
全连接层或线性层的基本操作是线性变换加上一个偏置项,假设输入是x,参数矩阵是W,偏置是b,那么输出形状是y = Wx + b。只要W的形状是(out_features, in_features),b的形状是(out_features,),那么输出y的形状就是(batch_size, out_features)。在全过程中,batch_size并没有发生改变,也就是说,线性层并不改变样本量。
其次,对于时间序列数据,全连接层通常是直接应用于每个时间步的数据,即对每个时间步的数据都进行相同的线性变换操作,因此不改变时间步维度。
故,全连接层处理的是每一个样本在特征维度上的数据,将一个样本的特征进行线性变换而不涉及到其他维度。它是独立的也就是说该层并不知道前一个样本或者后一个样本的存在。对于三维数据(batch_size, seq_len, in_features),全连接层会依次对每个样本的每个时间步的数据进行线性变换,因此不会改变dim0和dim1。
- 关于rnn 中 对于输出的最后一层隐藏层的状态 为什么要detach
在RNN中,隐藏状态 hidden_prev 会在每个时间步被更新,并且在序列的每个元素之间传递。但是,在反向传播过程中,我们通常不希望梯度通过整个序列传递回去,因为这可能导致梯度消失或梯度爆炸问题。
hidden_prev = hidden_prev.detach() 这行代码的作用是将 hidden_prev 与之前的计算图断开联系。换句话说,它会阻止梯度从当前时间步传回到之前的时间步。具体来说,.detach() 方法创建了一个新的Tensor,从当前计算图中分离出来,但有着同样的内容。因为新Tensor与计算图分离,所以在进行反向传播时,梯度不会回传到分离点之前。
通过这样做,可以保持模型的稳定性,并且使训练过程更加高效,因为我们不需要存储和计算整个序列的梯度。这在处理长序列时尤其重要,因为长序列可能会导致梯度消失或爆炸问题,也会增加计算和存储开销。
10.问题是反向传播学习的时候,时间步的权重不也需要学习吗,detach了之后怎么被更新和学习呢?
隐藏状态的权重学习问题:在RNN中,隐藏状态确实需要在训练过程中更新。但是,这种更新是基于每个批次(或序列)的反向传播,而不是基于整个训练过程的累积梯度。每次传递一个新的输入序列到网络时,您都会使用当前的网络权重来计算隐藏状态和输出。然后,基于这个批次的损失,通过反向传播来更新网络的权重。
使用detach()的目的:在RNN中使用detach()是为了防止梯度在整个序列或多个序列之间传播。这有助于避免梯度消失或梯度爆炸问题,并减少计算负担。detach()并不会影响当前批次内的梯度反向传播,所以权重依然可以根据当前批次的误差进行更新。
笔者:也就是时间步这个传递权重这个过程和概念是对于一个input的时间维度内的,不应该在整个数据的不同batch见传播,要清理
关于Pytorch的 rnn 隐藏层状态的在不同Batch 和Epoch间传播的问题
在 PyTorch 中,对于 RNN 模型,隐藏状态在每个 batch 之间的传播是由 PyTorch 自动处理的。默认情况下,PyTorch 会在每个 batch 的前向传播过程中自动处理隐藏状态,确保梯度的传播和截断。这意味着在大多数情况下,你可能不需要手动使用 detach() 来处理隐藏状态。
在你的代码中,因为你在每个循环迭代中都重新初始化了 hidden_prev,并且没有保留计算图的依赖,所以你不显式使用 detach() 也是合适的。PyTorch 会在每次前向传播时自动处理隐藏状态,不需要手动介入。
总体而言,如果你的模型结构和训练过程没有特殊的需求,PyTorch 的默认机制通常足够处理隐藏状态的传播和梯度问题。只有在特殊情况下,例如需要手动管理隐藏状态以处理长期依赖关系或梯度问题时,才需要考虑手动使用 detach()。
示例 手动隔离
# 初始化隐藏状态
initial_hidden_state = torch.zeros(1, batch_size, hidden_size).to(device)
# 训练循环
for epoch in range(num_epochs):
for batch, (input_data, target) in enumerate(train_loader):
input_data, target = input_data.to(device), target.to(device)
# Forward pass
output, hidden_state = rnn_model(input_data, initial_hidden_state)
# 计算损失并进行反向传播
loss = loss_function(output, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 分离隐藏状态
initial_hidden_state = hidden_state.detach()
test中
使用 with torch.no_grad(): 这将禁用梯度计算,可以阻止梯度在时间步上的累积。















 1525
1525











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









