







Anton Schwaighofer, Volker Tresp, and Kai Yu. 2004. Learning Gaussian process kernels via hierarchical bayes. In Proceedings of the 17th International Conference on Neural Information Processing Systems (NIPS'04). MIT Press, Cambridge, MA, USA, 1209–1216.
研0学习笔记,本人对该论文的思路较为清晰,但是公式部分未理解透彻,发布此篇笔记仅为学习交流与笔记存档,有不对的地方请多指教~~
1总体思路
本文介绍了一种使用分层贝叶斯框架从多任务学习问题中学习高斯过程协方差函数的新方法。
2论文的主要假设是什么?

3主要过程
Learning GP Kernel Matrices via EM
第一步,使用简单有效的 EM 算法从数据中学习一组固定输入点上的共享均值向量和协方差矩阵。 此步骤是非参数的,因为它不需要协方差函数的参数形式。从数据中学习一个通用的协作核矩阵。 这绕过了内核设计的问题,因为这里不需要内核函数的参数形式。
Learning the Covariance Function via Generalized Nystrom
在第二步中,使用广义 Nystrom 方法拟合核函数以逼近学习的协方差矩阵,从而得到一个复杂的核函数,便于将学习到的协方差矩阵推广到新点。
4 EM learning
前提
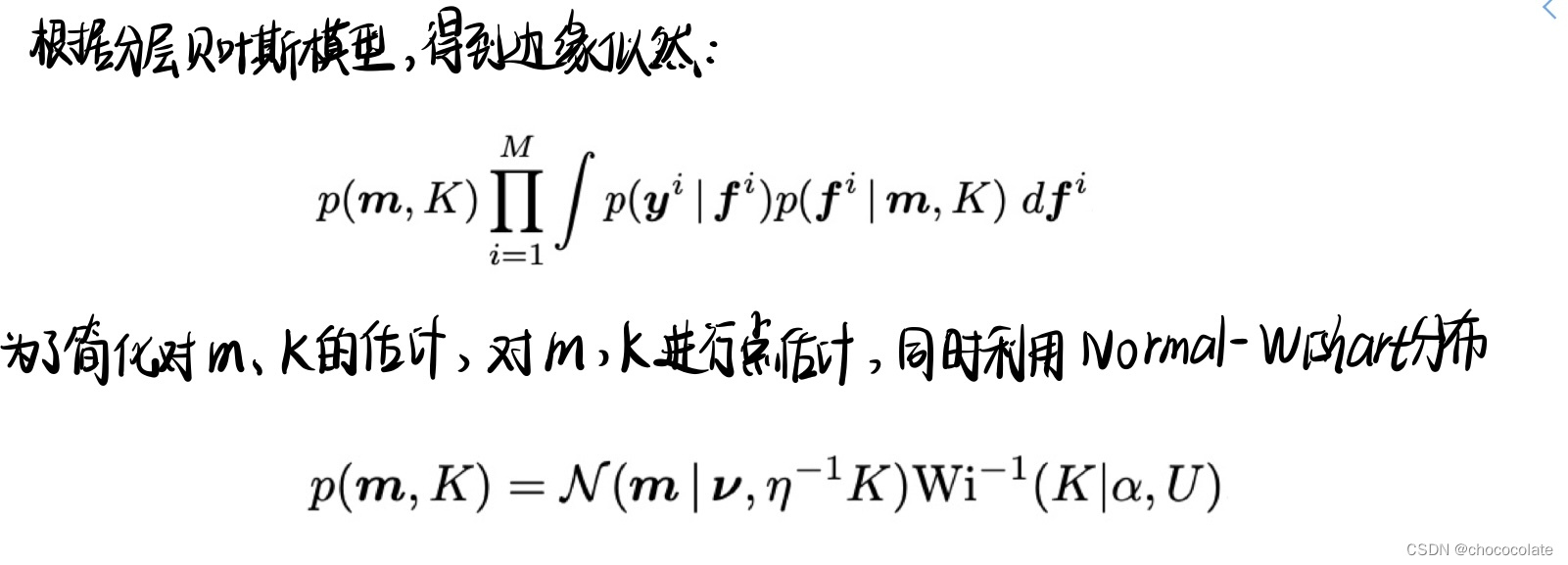
过程
EM 是一种迭代算法,用于在存在潜在变量时找到最大似然。该算法在执行期望 (E) 步骤和最大化 (M) 步骤之间迭代。在本文中:

EM效果
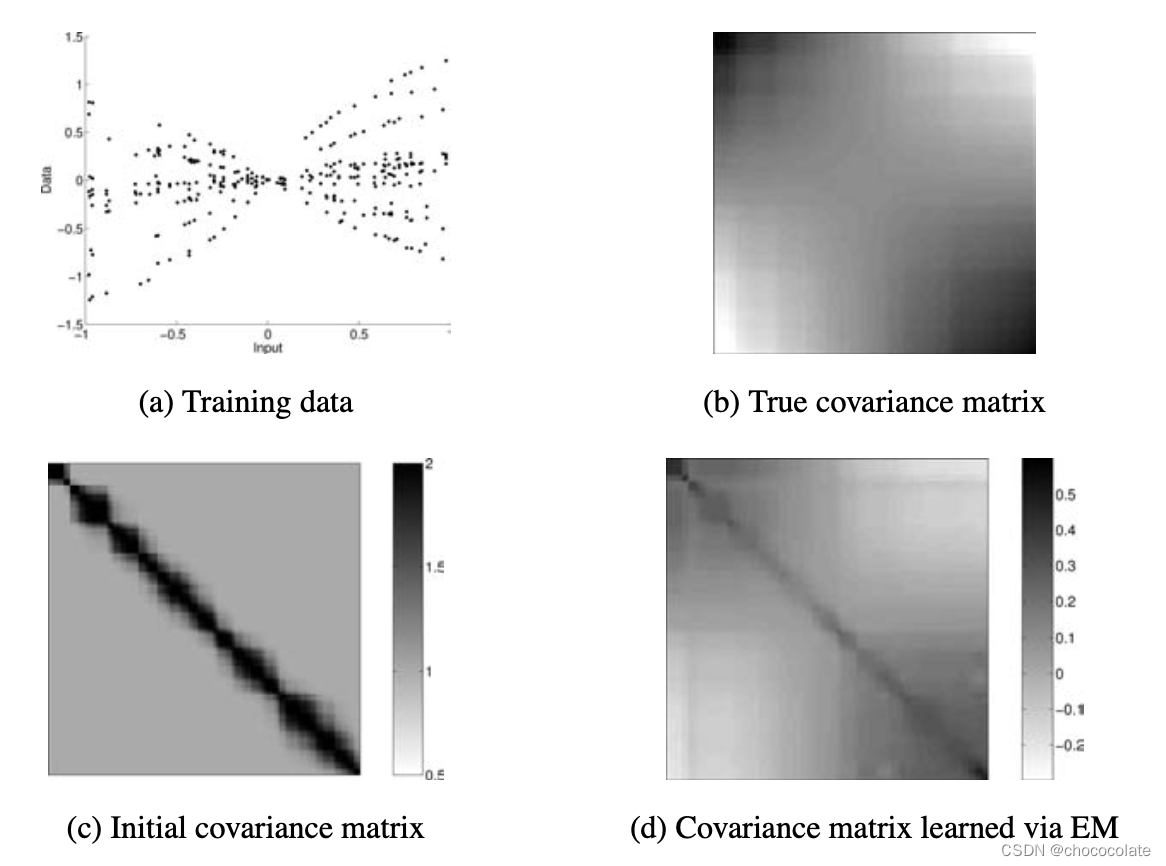
5 Nystrom方法
在一般的高斯过程中,预测过程为:
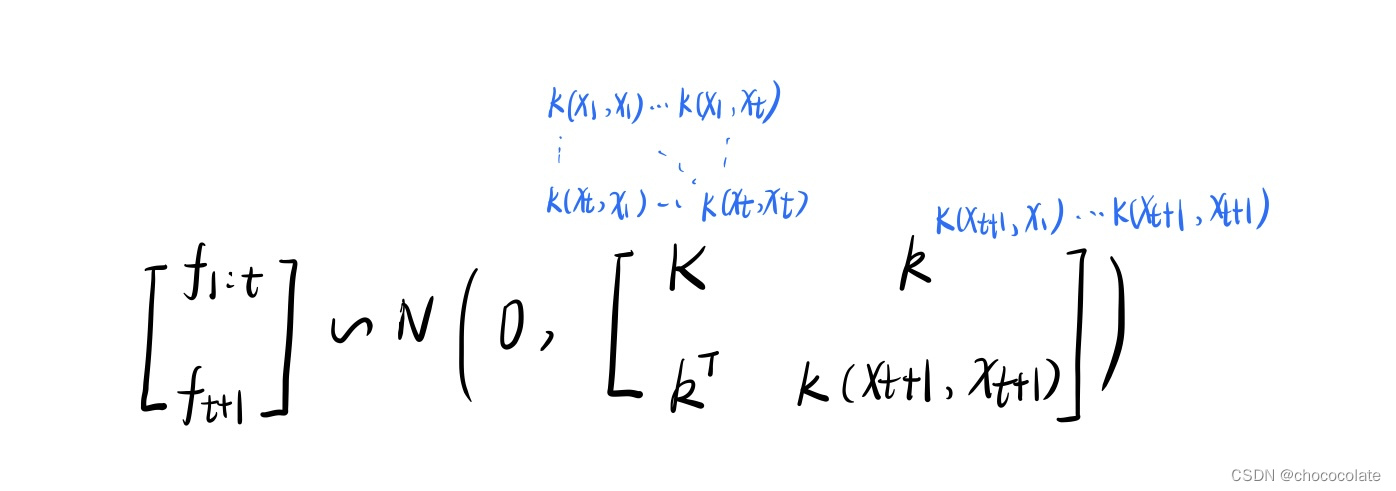
经过EM我们已经学习到了协方差矩阵,而预测时需要用到协方差函数,因此,我们需要学习一个协方差函数。
为什么需要Nystrom 方法以及它是怎样作用的?
在所有的EM算法中,内容特征并没有被利用,为了概括已经学习的核矩阵,我们使用了一个由以内容特征作为输入的辅助核函数r(,)构成的核平滑器kernel smoother。具体地,我们需要保证我们得到的kernel是正定的,我们的策略是插入K的特征向量,进而生成一个正定核。这里用到的r(,)是一个通用的平滑核。
这个方法与Nystrom方法有关,Nystrom是一种用于内核低秩逼近的通用方法,即可通过采样的方式,构建一个低秩矩阵去近似表示原核矩阵,降低核矩阵在计算中的运算代价。同时,也可以得到核空间中样本的向量表示。
论文中定义以下函数:
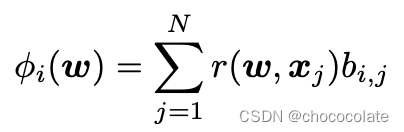
![]()
则,基于近似缩放的协方差函数可以表示为:
![]()
其中,
![]()
为超参数,I为单位矩阵。
















 830
830











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











