







MoE-DiffIR: Task-customized Diffusion Priors for Universal Compressed Image Restoration 论文阅读笔记

-
中科大和字节发表在ECCV2024的一篇论文,通讯陈志波教授是很多顶刊顶会论文的通讯,看主页光是ECCV2024就中了4篇,CVPR2024也中了4篇。代码GitHub上占坑了,写着comming soon。
-
用prompt learning来实现all-in-one的diffusion-based的压缩图像修复。
-
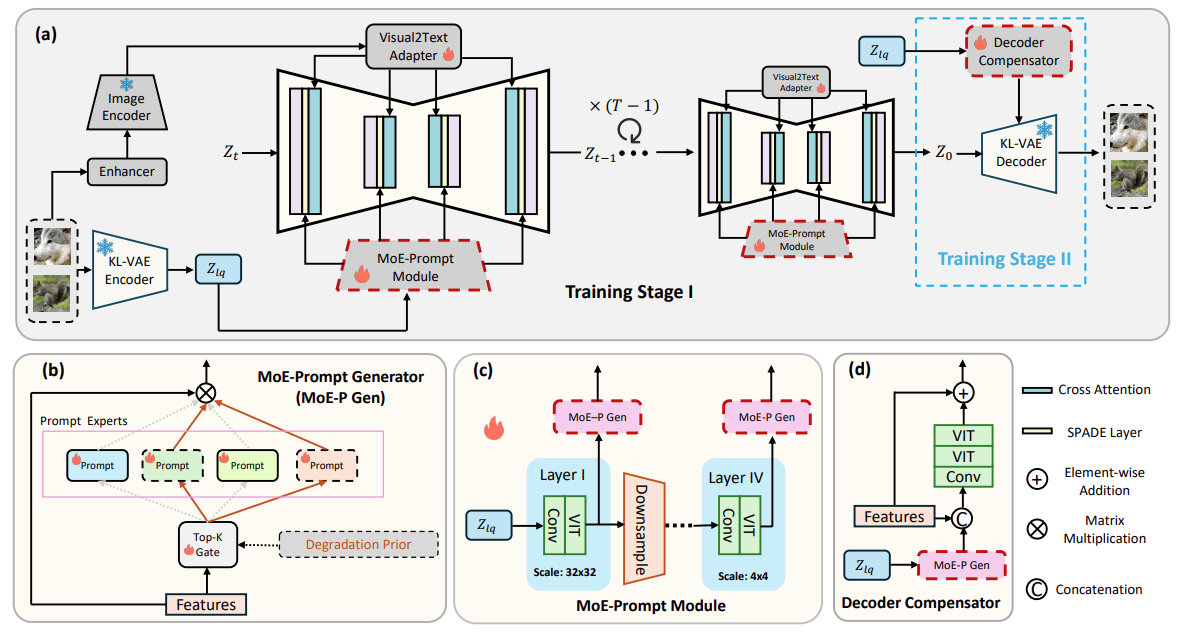
整体网络结构如下图所示:
-
从a图可以看到,其实是再普通的stable diffusion上,加了一个MoE-Prompt Module,一个Decoder compensator和一个visual2text adapter。也就是说,前面VAE-Encoder提取的feature在送进unet前,先过一下MoE-Prompt Module,加一下专家信息,后面的VAE-decoder也要过一下一个compensator,加一下专家信息。此外,还利用visual2text adapter加一下额外的信息。
-
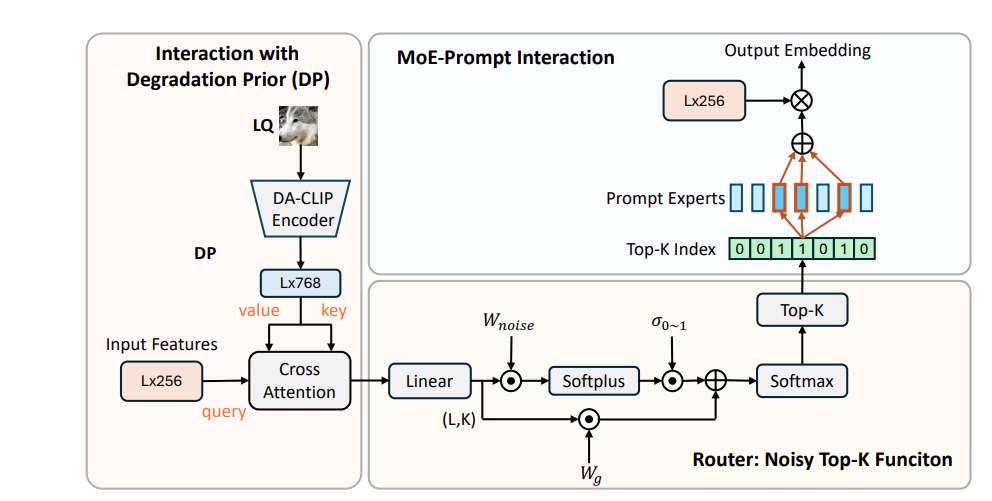
从bcd图可以看到(其实画得很含糊,不仔细,需要看附录,如下图),所谓MoE-Prompt,其实就是在原有的feature上,去和利用DA-CLIP对原图提取的degradation prior,进行交叉注意力,再用noisy top-k这个常用的MoE方法,得到top k个专家prompt,进行求和,再用结果的prompt去和feature计算矩阵乘法,得到经过MoE处理后的特征。
- 然后所谓的visual2text adapter,其实就是先用几层transformer(图中的enhancer)处理一下,然后用CLIP的image encoder提取特征(说是text 特征),然后过几层全连接,得到的结果送进stable diffusion里面去调制。
- 感觉visual2text adapter有点凑创新点,然后其它的也就是把MoE和prompt-learning结合到SD上,做restoration任务。而且限定compressed image也很奇怪。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









