






目录
(本文侧重DivideMix方法的剖析,旨在理解其方法原理,并不按照原文逐字翻译。)
文章《DivideMix: Learning with Noisy Labels as Semi-supervised Learning》发表在ICLR2020上,作者Junnan Li、Richard Socher和Steven C. H. Hoi。
文章地址:https://arxiv.org/abs/2002.07394
代码地址:https://github.com/LiJunnan1992/DivideMix
要解决的问题
深度学习模型的训练需要大量的标注数据,而精确标注数据的成本非常高。为了降低获取训练数据的成本,可以采用一些替代办法,如通过商用搜索引擎获取、下载社交媒体上带标签的图片、利用机器自动生成标签等。但是采用这些方法收集的训练数据,它的标签可能是错误的,即可能存在noisy label。用这样的数据来训练模型很容易产生过拟合。
解决这个问题的办法有两个主要方向:一是带噪声标签学习LNL,二是半监督学习SSL。目前这两种方法的结合应用尚未被探索。作者提出的DivideMix方法,即融合了这两种方法。DivideMix将看起来很像打错标签的样本的标签丢弃,利用打错标签的样本当作无标签数据来正则化模型。
主要贡献
(1)Divide动态地将训练数据分为标签集(label set)和无标签集(unlabel set),然后用这两个数据集以半监督的方式训练模型。
(2)DivideMix:一个利用半监督学习的带噪声标签学习的创新框架。
- co-divide:同时训练两个网络。每一个网络,动态地在每个样本的损失分布上拟合高斯混合模型(GMM),将训练样本分成有标签集和无标签集。被分出来的数据子集被用来训练另一个网络。co-divide机制使得两个网络彼此不不同,所以他们可以过滤不同类型的误差,防止自训练中的确认偏差。
- 半监督学习(SSL):
- co-refinement:对有标签样本,利用网络的预测结果纠正他们的标签。(有标签样本是以另一个网络的参数为输入的GMM划分出来的,因此用co)
- co-guessing:对无标签样本,结合两个网络的结果,猜测他们的标签
(3)实验:DivideMix在CIFAR-10、CIFAR-100、Clothing M、Web Vision 1.0四个数据集上取得了SOTA的效果
DivideMix方法剖析

DivideMix模型同时训练两个网络,分别记为网络A和网络B。两个网络的结构一致,由于随机的初始化、随机的小批量序列等因素,在训练过程中能够保持一定的差异。他们之间实现某种意义上的互补,每个网络过滤掉另一个网络的错误。DivideMix模型如图 1 所示。当完成一个Epoch的训练后,进入下一个Epoch。这时首先使用Co-divide方法将整个训练数据集划分为干净数据集和噪声数据集,并丢弃噪声样本的标签。然后,按照小批量训练的方法,使用Co-refinement方法为批量中的每一个干净样本重打标签,使用Co-gussing方法为批量中的每一个噪声样本赋予新的标签。最后对批量中的干净样本和噪声样本执行MixMatch,MixMatch操作生成的新的样本作为两个子网络的输入,采用SGD方法监督完成网络训练参数的更新。
原文给出了算法,如下图所示。建议结合算法阅读下文。

Co-divide方法
Co-divide的作用是将训练数据集划分为干净数据集好噪声数据集。现考虑网络A,将训练集D中的每一个样本i 输入到网络A,网络A将输出其对应的预测结果,即预测向量。样本的预测向量和标签向量的交叉熵(Cross-Entropy)作为单样本的损失li 。采用最大化期望的方法将全部样本的损失的分布拟合一个二分量的高斯混合模型(Gaussian Mixture Model,GMM)。对每一个样本i ,后验概率p(g|li) 作为其属于干净样本的概率(g 表示高斯分量),表示为ωi 。用τ 表示干净样本和噪声样本的分类阈值。当ωi≥τ ,则样本i 视为干净样本;当ωi<τ ,则样本i 视为噪声样本。对网络A,利用上述方法即可将样本集划分为干净数据集χeB 和噪声数据集UeB (为什么上标是B,因为由网络A划分的数据集,后面送给网络B处理,也因此才叫co-divide)。同理,对网络B,利用上述方法即可将样本划分为干净数据集χeA 和噪声数据集UeA 。
Co-refinement方法
Co-refinement的作用是对干净样本重新打标签。现考虑网络A,将干净样本及其旋转增强后的m个样本输入当前状态的网络A,得出的m个预测向量取平均,作为该样本的预测向量。通过线性组合标签向量和预测向量,并运用sharpen函数处理,其结果作为该样本新的标签向量,仅在本Epoch有效。对网络B同理。(见算法)
Co-guessing方法
Co-guessing的作用是对噪声样本(其原来的标签已经被丢弃)赋予新的标签。现考虑网络A,将噪声样本及其旋转增强后的m个样本同时输入当前状态的网络A和网络B。网络A和网络B分别输出对应的预测向量,共计2m个预测向量。将这2m个预测向量取平均,并运用sharpen函数处理,其结果作为该样本的标签向量,仅在本Epoch有效。对网络B同理。(见算法)
MixMatch方法
MixMatch的作用是混合经过Co-refinement和Co-guessing后的样本,生成实际用于完成本次训练的输入数据。它对每一个输入样本x1 ,从当前批量里面(包含干净样本子集和噪声样本子集)中随机抽取另一个样本x2 ,组成样本对(x1 ,x2 ),它们对应的标签为(p1 ,p2 )。混合的(x' ,p' )用如下公式计算。
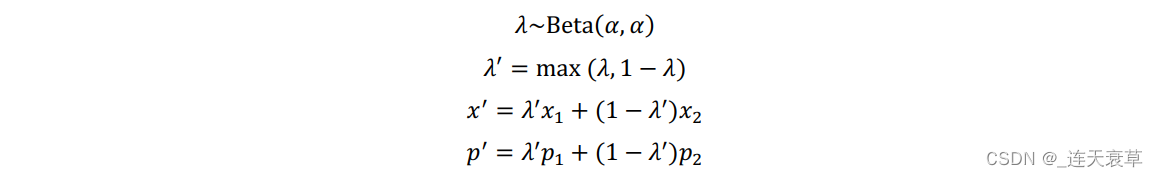
若x1 取自干净样本,则其经过计算后的新样本(包含计算后的标签)组成的集合表示为X' ;若x1 取自噪声样本,则其经过计算后的新样本(包含计算后的标签)组成的集合表示为U' 。X' 和U' 用作本次训练的实际输入数据。
损失函数
对![]() 中的数据使用交叉熵作为损失,对
中的数据使用交叉熵作为损失,对![]() 中的数据,使用均方误差作为损失。为了防止将所有样本都分配到某一个类别,加入了正则化项。
中的数据,使用均方误差作为损失。为了防止将所有样本都分配到某一个类别,加入了正则化项。
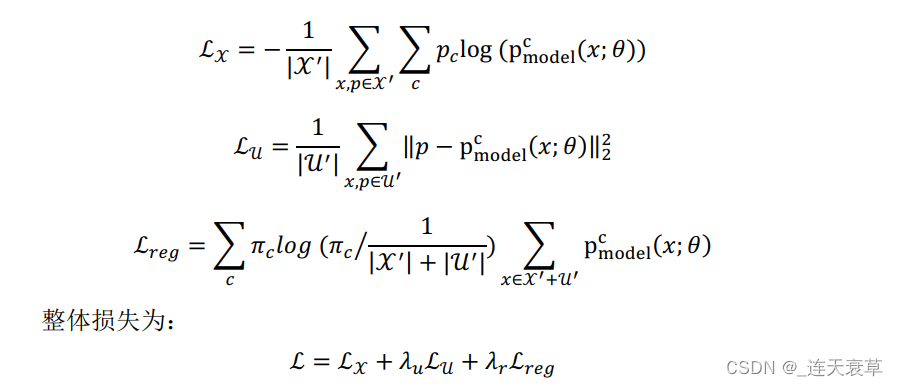















 420
420











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









