







Python入门
一、工具的使用
1.1 Jupyter notebook 开发工具
运行方式
$ jupyter notebook
1.2 Pycharm自动导包
二、常用依赖
2.1 conda环境的建立
conda create -n 环境名 python=版本号
2.2 pandas
2.2.1 DataFrame和Series的区别
| DataFrame | Series | |
|---|---|---|
| 文档地址 | DataFrame | Series |
| 维度 | 二维 | 一维 |
| Rerferences | Series vs. DataFrame in Pandas – Shiksha Online |
2.2.2 DataFrame与numpy互转
# DataFrame --> numpy
data1 = pd.DataFrame(data={'col1': [1, 2], 'col2': [3, 4]})
print(data1)
print(data1.columns)
print(np.array(data1)) # Droping the column automaticaly
# numpy --> DataFrame
data2 = np.array([[1,2,3],
[4,5,6]])
print(pd.DataFrame(data=data2))
data1=
col1 col2
0 1 3
1 2 4
data1.columns=
Index([‘col1’, ‘col2’], dtype=‘object’)
np.array(data1)=
[[1 3]
[2 4]]
pd.DataFrame(data=data2)
0 1 2
0 1 2 3
1 4 5 6
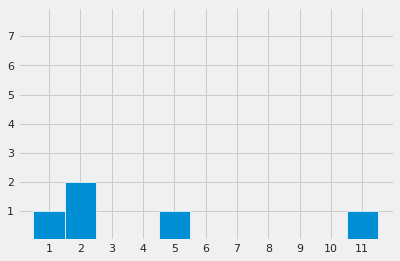
2.2.3 pandas数据绘制
Series自带plot功能
import pandas as pd
data = pd.DataFrame(data={'col1': [1, 2, 11, 5, 2], 'col2': [3, 4, 3, 4, 2]})
x = pd.value_counts(data['col1'], sort=True).sort_index()
y = x.index
x = x.to_numpy()
y = y.to_numpy()
# plot the data
fig, ax = plt.subplots()
ax.bar(y, x, width=1, edgecolor="white", linewidth=0.7)
ax.set(xlim=(0, 12), xticks=np.arange(1, 12), ylim=(0, 8), yticks=np.arange(1, 8))
plt.show()
2.3 matplotlib
//@TODO,此处会引用另一篇文章,该文章待完成,都问大模型吧,这一节不更了,自从有了你,生命都变得更美丽~~
2.4 python操作excel的库与对比
根据此文,选择xlwings做为操作excel的首选库
《可能是全网最完整的 Python 操作 Excel库总结!》
2.5 API快捷查询
要查看某个类有哪些方法和属性
dir(类名)
三、管理环境依赖
3.1 批量导出与安装环境依赖
如何配置环境,甚至是配置一个一模一样的环境,对于运行他人代码或者复现论文而言,都是非常重要的一环。
(1) 打开终端
(2) 切换至该Python项目的根目录或子目录,并激活该项目的虚拟环境
(3) 运行pip list --format=freeze > requirements.txt,那么依赖环境就导出好了。
(4) 反过来,激活该项目的虚拟环境并运行pip install -r requirements.txt则是安装,从我实际使用的体验上来说,对于python而言,使用虚拟环境更方便,可以隔离各个项目之间的环境依赖,让环境更清爽,但有一个问题是,为什么python没有其对应的类似maven的工具?毕竟如果两个项目分别用了不同的虚拟环境,但用到了同一个版本的依赖包,相当于要安装两遍,占用双倍的存储空间,而Java中,有maven可以导入依赖,项目只需要引用即可。
| 参考文章或视频链接 |
|---|
| Maven for Python: Possible or Not? |
| Maven equivalent for python [closed] - stackoverflow |
| 《精确管理Python项目依赖:自动生成requirements.txt的智能方法》- CSDN |
3.2 管理环境依赖
| 参考文章或视频链接 |
|---|
| 相比 Pipenv,Poetry 是一个更好的选择 |
3.3 发布本地Python项目作为依赖
我开发好了一个python项目,如何发布呢?
我想把我开发好的python项目,发布到本地的python环境中如何做?
所以python的依赖包都是以源码形式发布的吗?
| 参考文章或视频链接 |
|---|
| [1] 《打包发布自己的第一个 Python 项目(包)》 |
| [2] What is setup.py in Python? |
References
| 参考文章或视频链接 |
|---|
| 《python数据分析学习笔记之matplotlib、numpy、pandas》 |















 1072
1072











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









