









图像压缩
(一)基础知识
一部90分钟的彩色电影,每秒放映24帧。把它数字化,每帧512x512象素, 每象素的R、G、B三分量分别占8 bit,总比特数为:90602435125128bit=97200MB=95GB.
如一张CD光盘可存600兆字节数据,这部电影图像(不包括声音)就需要160张CD光盘用来存储。此时此刻,图像压缩就很有必要。
1.1 冗余与压缩
图像作为信源有很大的冗余度,通过编码的方法减少或去掉这些冗余信息后可以有效压缩图像,同时又不会损害图像的有效信息。数据是用来表示信息的。如果不同的方法为表示等量的信息使用了不同的数据量,那么使用较多数据量的方法中,有些数据必然是代表了无用的信息,或者是重复地表示了其它数据已表示的信息,这就是数据冗余的概念。如果n1和n2代表两个表示相同信息的数据集合中所携载信息单元的数量,则n1表示的数据集合的相对数据冗余。
相对数据冗余:
R
D
=
1
−
1
/
C
R
R_{D}=1-1/C_{R}
RD=1−1/CR
压缩率:
C
R
=
n
1
/
n
2
C_{R}=n1/n2
CR=n1/n2
例如 10(或 10:1)压缩比,这指出在压缩过的数据集中,对于每 1 个单元,原始图像有 10 个携带信息的单元(如比特)。
相对数据冗余和压缩率的一些特例:
 图像压缩就是减少表示数字图像时需要的数据量,是通过去除一个或三个基本数据冗余来得到的。主要有三类,分别是编码冗余、空间或/和时间冗余、不相干冗余。
图像压缩就是减少表示数字图像时需要的数据量,是通过去除一个或三个基本数据冗余来得到的。主要有三类,分别是编码冗余、空间或/和时间冗余、不相干冗余。
-
图像数据的冗余主要表现为:图像中相邻像素间的相关性引起的空间冗余;图像序列中不同帧之间存在相关性引起的时间冗余;图像内部相邻像素之间存在较强的相关性多造成的空间冗余;不同彩色平面或频谱带的相关性引起的频谱冗余;人类视觉系统忽略或与用途无关的信息造成的不相关信息。由于图像数据量的庞大,在存储、传输、处理时非常困难,因此图像数据的压缩就显得非常重要。
-
图像压缩可以是有损数据压缩也可以是无损数据压缩。对于如绘制的技术图、图表或者漫画优先使用无损压缩,这是因为有损压缩方法,尤其是在低的位速条件下将会带来压缩失真。如医疗图像或者用于存档的扫描图像等这些有价值的内容的压缩也尽量选择无损压缩方法。有损方法非常适合于自然的图像,例如一些应用中图像的微小损失是可以接受的(有时是无法感知的),这样就可以大幅度地减小位速。
-
通用的图像压缩系统如下图所示:主要是通过编码器和解码器组成。

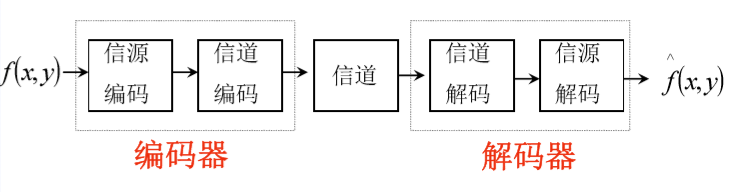

-
信源编码器:减少或消除输入图像中的编码冗余、像素间冗余及心理视觉冗余。
-
转换器:对输入的数据进行转换,以改变数据的描述形式,减少或消除像素间的冗余(可逆)。
-
量化器:根据给定的保真度准则降低转换器输出的精度,以进一步减少心理视觉冗余(不可逆)。
-
符号编码器:根据使用的码字为量化器输出和映射 输出创建码字,减少编码冗余。
-
不是每个图像压缩系统都必须包含这3种操作,如进行无误差压缩时,必须去掉量化器。
-
信道编码器和信道解码器:信道是有噪声的或易产生误差时,信道编码器和信道解码器对整个编解码过程非常重要。由于信源编码器的输出数据一般只有很少的冗余,所以它们对输出噪声很敏感。
-
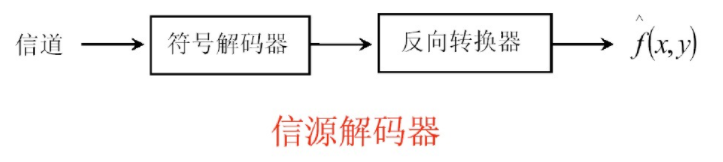
符号解码器:进行符号编码的逆操作。
-
反向转换器:进行转换器的逆操作。
-
因为量化操作是不可逆的,所以信源解码器中没有对量化的逆操作。
这里产生重建的输出图像
f
^
(
x
,
y
)
\widehat{f }(x,y)
f
(x,y) 。一般而言,
f
^
(
x
,
y
)
\widehat{f }(x,y)
f
(x,y)可能是,也可能不是
f
(
x
,
y
)
f(x,y)
f(x,y)的精确表示。如果是,系统就是无误差的、信息保持的或无损的;如果不是,在重建图像中会有一部分失真。对于后一种情况,被称为有损压缩,可以对x和y的任意取值在
f
(
x
,
y
)
f(x,y)
f(x,y)和
f
^
(
x
,
y
)
\widehat{f }(x,y)
f
(x,y)之间定义误差e(x,y):
e
(
x
,
y
)
=
f
^
(
x
,
y
)
−
f
(
x
,
y
)
e(x,y)= \widehat{f}(x,y)-f(x,y)
e(x,y)=f
(x,y)−f(x,y)
所以,两幅图像间的总误差为:
e
(
x
,
y
)
=
∑
x
=
0
M
−
1
∑
y
=
0
N
−
1
[
f
^
(
x
,
y
)
−
f
(
x
,
y
)
]
e(x,y)= \sum_{x=0}^{M-1}\sum_{y=0}^{N-1}\left [\widehat{f}(x,y)-f(x,y) \right ]
e(x,y)=∑x=0M−1∑y=0N−1[f
(x,y)−f(x,y)]
同时,f(x,y)和f^(x,y)之间的均方根(root-mean-square,rms)误差erms是 MxN数组的均方误差的平均值的平方根:
e
r
m
s
=
[
1
/
M
N
∑
x
=
0
M
−
1
∑
y
=
0
N
−
1
[
f
^
(
x
,
y
)
−
f
(
x
,
y
)
]
2
]
1
/
2
e_{rms}= \left [1/MN\sum_{x=0}^{M-1}\sum_{y=0}^{N-1}\left [\widehat{f}(x,y)-f(x,y) \right ]^{2} \right]^{1/2}
erms=[1/MN∑x=0M−1∑y=0N−1[f
(x,y)−f(x,y)]2]1/2
(二)编码冗余
2.1 相关定义
信息测量:==
对一个随机事件E,如果它的出现概率是 P(E),那么它包含的信息:
I
(
E
)
=
l
o
g
1
P
(
E
)
=
−
l
o
g
P
(
E
)
I(E)=log \frac{1}{P(E)}=-logP(E)
I(E)=logP(E)1=−logP(E)
I(E)称为E的自信息。如果P(E)=1(即事件总发 生),那么I(E)=0。
编码冗余就是当所用的码字大于最佳编码(也就是最小长度)时存在的冗余。还提到了熵的概念,查了资料得到:==熵(entropy)指的是体系的混乱的程度,它在控制论、概率论、数论、天体物理、生命科学等领域都有重要应用,在不同的学科中也有引申出的更为具体的 定义,是各领域十分重要的参量。==这里我们讨论的是图像处理中的熵,图像熵是一种特征的统计形式,它反映了图像中平均信息量的多少。
图像熵数学公式为:
H
=
−
∑
j
=
1
J
P
(
a
j
)
L
o
g
P
(
a
j
)
H=-\sum_{j=1}^{J}P(a_{j})LogP(a_{j})
H=−∑j=1JP(aj)LogP(aj)
编码应用中,熵表示信源中消息的平均信息量。在不考虑消息间的相关性时,是无失真代码平均长度比特数的下限。
熵的性质:
(1) 熵是一个非负数,即总有H(s)>=0。
(2) 当其中一个符号sj的出现概率p(sj)=1时,其余符号si(i≠j)的出现概率p(si)=0,H(s)=0。
(3) 当各个si出现的概率相同时,则最大平均信息量为logq。(此处对数以2为底)
(4)熵值总有H(s)< logq。(此处对数以2为底)
无失真编码定理
可以证明,在无干扰的条件下,存在一:种无失真的编码方法,使编码的平均长度L与信源的熵H(s)任意地接近, 即L=H(s)+ε。其中ε为任意小的正数,但以H(s)为其下限即L≥H(s),这就是香农(Shannon)无干扰编码定理。
η
=
H
(
s
)
L
‾
=
1
1
+
R
\eta =\frac{H(s)}{\overline{L}}=\frac{1}{1+R}
η=LH(s)=1+R1
编码效率:
C
=
n
n
d
C=\frac{n}{n_{d}}
C=ndn
压缩比:由香农(Shannon)无干扰编码定理,无失真编码最大可能的数据压缩比为:
∗
∗
C
M
=
n
H
(
s
)
+
ξ
≈
n
H
(
s
)
∗
∗
**C_{M}=\frac{n}{H(s)+\xi}\approx\frac{n}{H(s)}**
∗∗CM=H(s)+ξn≈H(s)n∗∗
熵与冗余度的关系
对于无失真图像的编码,原始图像数据的压缩存在一个下限,即平均码组长度不能小于原始图像的熵,而理论上的最佳编码的平均码长无限接近原始图像的熵。
信息冗余度一“信息剩余度”。是指一定数量的信号单元可能有的最大信息量与其包含的实际信息量之差。通常用R表示。在通信系统中,信源编码是降低信号中的信息冗余度的编码,目的是提高通信系统的有效性;信道编码是提高信息冗余度的编码,目的是提高通信系统的可靠性

2.2 霍夫曼编码
概念:霍夫曼树─即最优二叉树,带权路径长度最小的二叉树,经常应用于数据压缩。 在计算机信息处理中,“霍夫曼编码”是一种一致性编码法(又称“熵编码法”),用于数据的无损耗压缩。
哈夫曼编码(Huffman Coding),又称霍夫曼编码,是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫做Huffman编码(有时也称为霍夫曼编码)。通俗来说就是,信源符号出现频率越高,使用的码字就越少。 其过程可以用以下图来进行说明:
- 通过对符号的概率进行排序,建立信源递减序列,这种符号排序考 虑了合并最低概率的符号作为单独的符号,并在下一次信源约简时替换它们。在最左边,初始信源符号集和它们的概率按照概率值由高到低降序排序。为了形成第一次信源约简,底部的两个概率值0.125和 0.1875 被合并,形成概率值为 0.3125 的合并过的符号。这个合并过的符号和与之关联的概率被放置在第一次信源约简列,这 样,约简信源的概率还要从最大到最小排序。然后,这个过程一直重复,直到约简信源只有两个符号(在最右边)为止。

- 对每个约简的信源进行编码,编码从最小的信源开始,一直到原始信源。当然,对于两符号信源的最短二进制编码由 0 和 1组成。这些符号被分配给右边的两个符号(分配是任意的,颠倒 0 和 1 的顺序也是可以的)。概率为 0.5的约简信源符号通过合并两个约简信源左侧的符号生成,用来编码的 0现在被分配给这些符号,并且 0 和 1 被任意分给每个符号以便区分它们。然后, 这个操作对每个约简信源重复,直到到达原始信源。
 例:
例:

 python实现霍夫曼树以及编码:
python实现霍夫曼树以及编码:
先为节点定义名称,值,左右孩子,二进制编码数字
class Node(object):
def __init__(self,name=None,value=None):
self._name=name
self._value=value
self._left=None
self._right=None
self._codevalue='0'
实现霍夫曼树:
class HuffmanTree(object):
#根据Huffman树的思想:以叶子节点为基础,反向建立Huffman树
def __init__(self,char_weights):
self.codeway = {}#存储节点对应的编码数,1or0
self.a=[Node(part[0],part[1]) for part in char_weights] #根据输入的字符及其频数生成叶子节点
while len(self.a)!=1:#如果没有到达根节点
self.a.sort(key=lambda node:node._value,reverse=True)#根据节点的value进行从大到小的排序
c=Node(value=(self.a[-1]._value+self.a[-2]._value))#对于权值最小的两个节点加和作为新节点c的value
c._left=self.a.pop(-1)#把排序完的树叶节点挂靠在c上,作为左右节点
c._right=self.a.pop(-1)
self.a.append(c)#bac作为节点连在树上
self.root=self.a[0]
实现霍夫曼编码:
def binaryTreePaths(self, root):
if not root:#如果root不存在
return []
if not root._left and not root._right:#如果root就是一个叶节点
return [str(root._value)]
pathList = []#用来存储路径
if root._left:#沿左子树下行递归遍历直到到达了叶节点
root._left._codevalue = '0'
pathList+=self.binaryTreePaths(root._left)
self.codeway[root._left._value]=root._left._codevalue
if root._right:
root._right._codevalue='1'
pathList+=self.binaryTreePaths(root._right)
self.codeway[root._right._value] = root._right._codevalue
for index, path in enumerate(pathList):#枚举pathList,得到对应节点路径的存放路径
pathList[index]=str(root._value) + ' ' + path
return pathList
处理结果:
 试着来进行图像的霍夫曼编码压缩:
试着来进行图像的霍夫曼编码压缩:
(1)将彩色图转为灰色图,此时图像的每个像素点可以用单独的像素值表示:
def picture_convert(filename,newfilename):
picture = Image.open(filename)
picture = picture.convert('L')#转换为灰值图
picture. save(newfilename)#保存灰度图像
return picture
(2)统计每个像素出现的次数:
def pixel_number_caculate(list):
pixel_number = {}
for i in list:
if i not in pixel_number.keys():
pixel_number[i] = 1 # 若此像素点不在字符频率字典里则直接添加
else:
pixel_number[i] += 1 # 若存在在字符频串字典里则对应值加一
return pixel_number
构造节点,分別陚予其值和对应的权值:
def node_construct(pixel_number):
node_list = []
for i in range(len(pixel_number)):
node_list.append(node(weight=pixel_number[i][1], code=str(pixel_number[i][0])))
return node_list
(3)根据叶子结点列表,生成对应的霍夫曼编码树:
def tree_construct(listnode):
listnode = sorted(listnode, key=lambda node: node.weight)
while len(listnode) != 1:
low_node0, low_node1 = listnode[0], listnode[1]
new_change_node = node()
new_change_node.weight = low_node0.weight + low_node1.weight
new_change_node.left = low_node0
new_change_node.right = low_node1
low_node0.parent = new_change_node
low_node1.parent = new_change_node
listnode.remove(low_node0)
listnode.remove(low_node1)
listnode.append(new_change_node)
listnode = sorted(listnode, key=lambda node: node.weight)
return listnode
(4)构造编码表:
coding_table = {}
for e in node_list:
new_change_node = e
coding_table.setdefault(e.code, "")
while new_change_node != head:
if new_change_node.parent.left == new_change_node:
coding_table[e.code] = "1" + coding_table[e.code]
else:
coding_table[e.code] = "0" + coding_table[e.code]
new_change_node = new_change_node.parent
# 输出每个像累点灰度值和编码
for key in coding_table.keys():
print("信源像素点" + key + "编码后的码字力:" + coding_table[key])
# 输出编码表
print("编码表为:", coding_table)

压缩编码后:

(三)像素间冗余
从信息论的角度来看,描述信息源的数据是信息和数据冗余之和,即:数据=信息+数据冗余。空间冗余是图像数据中经常存在的一种数据冗余,是静态图像中存在的最主要的一种数据冗余。是静态图像中存在的最主要的一种数据冗余。任何一幅图中的像素都可以合理地从 它们的相邻像素值预测,这些单独像素携带的信息相对较少。单一像素的视觉贡献对一幅图像 来说大部分是多余的;它们应该能够在相邻像素值的基础上推测出来。这些相关性是像素间冗余的潜在基础。
定义:同一景物表面上采样点的颜色之间通常存在着空间关联性,相邻各点的取值往往近似或者相同,这就是空间冗余。例如图片中有一篇连续的区域,这个区域的像素都是相同的颜色,那么空间冗余就产生了。
对于一张静态图片,存在空间冗余(几何冗余),这是由于在一张图片中单个像素对图像的视觉贡献常常是冗余的,可借助其相邻像素的灰度值进行推断。
对于连续图片或视频,还会存在时间冗余(帧间冗余),大部分相邻图片间的对应点像素都是缓慢过度的。

解决方案:对于图像的空间冗余我们通常采用DCT(Discrete Cosine Transfrom,离散余弦变换)编码压缩技术。DCT可以对图像的空间冗余进行有效的压缩,他是MEPG(Moving Picture Experts Group,运动图像专家组)压缩编码的基础。DCT是正交变换编码的一种,他将空间域上图像变换到频率域上进行处理。
图像空间相关性表示相邻元素点取值变化速度。从频域的角度上看,意味着像素信号的能量主要集中在低频附近,高频信号的能量随频率的增加而迅速衰减。事实上,图像信号变换越慢,则其高频分量越少。典型的如彩场信号,彩场整屏像素都相同,只有一个直流分量。图像信号变化越快细节越丰富,则对应高频分量越多,但是能量主要还是集中在低频分量上。通过频域变换,可以将原图像信号用直流分量以及少数低频交流分量的系数来表示,从而有效的对空间冗余进行压缩,这就是DCT方法,它属于有损压缩。
(四)心理视觉冗余
心理视觉冗余与实在的视觉信息相关,它是因人而异的,不同的人对于同一张照片产生的心理视觉冗余是不同的。去除心理视觉冗余数据必然导致定量信息的损失,并且该视觉信息损失是不可逆转的操作。就好比一张图像(无法放大)比较小时,人眼是无法直接判断出其分辨率,为了压缩图像的数据量,可以去除一些人眼无法直接观察出的信息,但当其放大时,没有去除心理视觉冗余的图像将和去除心理视觉冗余的图像产生明显差别
与编码及像素间冗余不同,心理视觉冗余和真实的或可计量的视觉信息有联系,心理视觉冗余数据的消除引起的定量信息损失很小,成为量化,量化会导致数据的有损压缩。这是一种不可逆操作。就好比一张图像(无法放大)比较小时,人眼是无法直接判断出其分辨率,为了压缩图像的数据量,可以去除一些人眼无法直接观察出的信息,但当其放大时,没有去除心理视觉冗余的图像将和去除心理视觉冗余的图像产生明显差别。
引入量化:对无损预测压缩的误差进行量化,通过消除视觉心理冗余,达到对图像进一步压缩的目的。



上述方案的压缩编码中,预测器的输入是fn, 而解压中的预测器的输入是fn’,要使用相同的预测器,编码方案要进行修改。
修改后的有损预测编码:

(五)图像视频压缩标准
5.1 图像压缩标准
◆JPEG—— 静态图像压缩标准
Joint Photographic Experts Group(联合图像专家组)
◆JPEG2000——新一代静态 图像压缩标准
适用范围:
➢灰度图像,彩色图像
➢静止图像的压缩,视频序列帧内图像压缩
JPEG压缩标准(ISO 10918-1)
 5.2 JPEG标准的划分
5.2 JPEG标准的划分
4种编码模式
- lossless encoding mode
- DCT based sequential encoding
- DCT_ based progressive encoding
- DCT_ based hierarchical encoding
3种技术层次(按算法的复杂性)
■基本系统(Baseline System)
■扩展系统(Extended System,提供二进制算术编码)
■专用无损失系统(Independent System)
JPEG2000压缩标准(ISO 15444)
■核心技术是离散小波变换(DWT)
■高压缩率
■同时支持有损和无损压缩
■实现了渐进传输
■支持“感兴趣区域”压缩
5.3 视频压缩
视频的定义:
(1)由多副尺寸相同的静止图像组成的序列
(2)与静止图像相比,视频多了一个时间轴,成为三维信号

(六)基于python的JPEG图像压缩
6.1 RGB转YUV
JPEG会将彩色图像执行YUV或YIQ的颜色空间转换,二次采样JPEG采用4:2:0,所以这里使用YUV420的颜色空间。在JPEG中使用的颜色模型是YCbCr(由YUV调整而来)。对于一个2*2的块,将会保存4个Y值,1个Cb值(取0行0列的Cb)与1个Cr值(取1行0列的Cr),6个值保存信息,因此Cb与Cr会有一定损失。
其中在RGB2YUV.py中用函数rgb2yuv 来实现颜色模型转换与二次采样。并分别用三个二维数组保存采取的Y、U、V值。于是我们能得到三张分别用Y、U、V生成的灰度图(由于U和V损失为原来的1/4,因此其图像的长宽也分别为原来的1/2)(为了减少绝对值将Y值减去128):
def rgb2yuv(img, width, height):
Y = [[0 for i in range(width)] for i in range(height)]
U = [[0 for i in range((width - 1) // 2 + 1)] for i in range((height - 1) // 2 + 1)]
V = [[0 for i in range((width - 1) // 2 + 1)] for i in range((height - 1) // 2 + 1)]
for i in range(height):
flag = False
if i % 2 == 1 or i == height - 1:
flag = True
for j in range(width):
B = img[i][j][0]
G = img[i][j][1]
R = img[i][j][2]
Y[i][j] = (0.299 * R + 0.587 * G + 0.144 * B - 128)
if i % 2 == 0 and j % 2 == 0:
U[i // 2][j // 2] = (-0.168736 * R + (-0.331264) * G + 0.5 * B) + 128
if flag:
V[i // 2][j // 2] = (0.5 * R + (-0.418688) * G + (-0.081312) * B) + 128
return Y, U, V
处理效果:

RGB转YUV:

6.2 离散余弦变换
(1)图像边长填充为8的倍数并等分
用DCT.fill(img)函数对二次采样得到的Y、U、V图像分别用0填充知道其矩阵的height和width都是8的倍数,因为DCT函数的参数是一个8*8的矩阵。
同样用DCT.split(img)函数将图像以左到右,上到下的顺序分成多个8*8矩阵,并返回这些矩阵连成的数组:
def fill(self, img):
width = len(img[0])
height = len(img)
if height % 8 != 0:
for i in range(8 - height % 8):
img.append([0 for i in range(width)])
if width % 8 != 0:
for row in img:
for i in range(8 - width % 8):
row.append(0)
return img
def split(self, img):
width = len(img[0])
height = len(img)
blocks = []
for i in range(height // 8):
for j in range(width // 8):
temp = [[0 for i in range(8)] for i in range(8)]
for r in range(8):
for c in range(8):
temp[r][c] = img[i * 8 + r][j * 8 + c]
blocks.append(temp)
return blocks
(2)离散余弦变换,用DCT.FDCT(block)函数对一个8*8矩阵进行二维离散余弦变换,保存得到的矩阵:
def FDCT(self, block):
temp = [[0 for i in range(8)] for i in range (8)]
for u in range(8):
for v in range(8):
n = 0
for i in range(8):
for j in range(8):
n += math.cos((2 * i + 1) * u * math.pi / 16) * math.cos((2 * j + 1) * v * math.pi / 16) * \
block[i][j]
temp[u][v] = round(self.C(u) * self.C(v) / 4 * n)
return temp
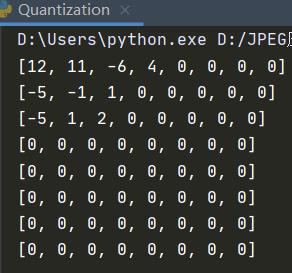
6.3 量化
在类 Quantization 中保存成员变量 table0 与 table1 作为亮度和色度的量化表,调 用 Quantization.quanY(img)与 Quantization.quanUV(img)分别用于对 Y 图像与 U、 V 图像量化:
def quanY(self, img):
temp = [[0 for i in range(8)] for i in range(8)]
for i in range(8):
for j in range(8):
temp[i][j] = round(img[i][j] / self.table0[i][j])
return temp
def quanUV(self, img):
temp = [[0 for i in range(8)] for i in range(8)]
for i in range(8):
for j in range(8):
temp[i][j] = round(img[i][j] / self.table1[i][j])
return temp
6.4 AC 系数,DC 系数
(1)AC系数
用 AC 类中的 ZScan(img)对一个图像进行 Z 型扫描,得到一个长度为 63 的数组(图 像第一个像素并不需要,它将在 DC 系数中保存)。之后通过 RLC(array)对上面得 到的数组 array 进行 RLC 得到处理的的游长编码:
def ZScan(self, img):
Z = []
i = j = 0
while i < 8 and j < 8:
if j < 7:
j = j + 1
else:
i = i + 1
while j >= 0 and i < 8:
Z.append(img[i][j])
i = i + 1
j = j - 1
i = i - 1
j = j + 1
if i < 7:
i = i + 1
else:
j = j + 1
while j < 8 and i >= 0:
Z.append(img[i][j])
i = i - 1
j = j + 1
i = i + 1
j = j - 1
return Z
def RLC(self, a):
temp = []
numof0 = 0
for num in a:
if num == 0:
numof0 += 1
else:
temp.append([numof0, num])
numof0 = 0
if numof0 != 0:
temp.append([0, 0])
return temp
Test:
test = AC()
a = [11, -5, -5, -1, -6, 4, 1, 1, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
rlc = test.RLC(a)
rle = test.RLE(rlc)
print(a)
print(rle)
 (2)DC 系数
(2)DC 系数
用DC 类中的 DPCM(blocks)函数对所有图像的DC 系数提取并返回它们的DPCM 编 码数组:
def DPCM(self, blocks):
temp = []
temp.append(blocks[0][0][0])
for i in range(1, len(blocks)):
temp.append(blocks[i][0][0] - blocks[i-1][0][0])
return temp
Test:
test = DCT.DCT()
img = cv2.imread("D:\Data\school.jpg")
Y, U, V = RGB2YUV.rgb2yuv(img, img.shape[1], img.shape[0])
Y = test.fill(Y)
blocks = test.split(Y)
for block in blocks:
print(block[0][0], end=' ')
print('')
test = DC()
a = test.DPCM(blocks)
print(a)
blocks = test.DPCM2(a)
for block in blocks:
print(block[0][0], end=' ')
 (3)熵编码
(3)熵编码
压缩部分是无损压缩,对 DC 系数(一个数组)采用可变字长整数编码。将一个 DC 系数分成 size 和 amplitude 两部分,配合 VLI(num)和 toB(num)函数将一个 DC 系数 转换为一个[size(num), s(string(B))]。
def toB(self, num):
num = int(num)
s = bin(abs(num)).replace('0b', '')
if num < 0:
s2 = ''
for c in s:
s2 += '0' if c == '1' else '1'
return s2
else:
return s
def VLI(self, num):
if num == 0:
return [0, '']
s = self.toB(num)
return [len(s), s]
这里的 s 已经是二进制串了(暂且用字符串存储方便操作), size 需要用哈夫曼编码 压缩。这里使用 JPEG 推荐的哈夫曼编码(亮度与色度两个表)。
对于 AC 系数, AC 系数采用有偿编码,由两个数 runlength 与 value 组成。 先将 value 如同 DC 系数一样采用可变字长整数编码拆分成 size 与 amplitude,然后 runlength 与 size 合并为 symbol1,smplitude 独立为 symbol2。对于 runlength 大 于 15 的数情况,在 symbol1 添加(15,0)表示(为了解码时能识别,应在前端添加)。然后对 symbol1 采用哈夫曼编码,对于 symbol2 则直接用可变字长整数编码得到的二进制码。Symbol1 采用的哈夫曼编码同样用 JPEG 推荐的哈夫曼编码。最终可用函数 AllCompressY 与 AllcompressUV将一个表格的数据转换为二进制字符串:
def AllCompressY(self, DC, arr):
s = ''
DC = self.VLI(DC)
s += self.DC_Y[DC[0]] + DC[1]
for num in arr:
runlength = num[0]
value = num[1]
temp = self.VLI(value)
while runlength > 15:
runlength -= 15
s += self.AC_Y[(15, 0)]
s += self.AC_Y[(runlength, temp[0])]
s += temp[1]
return s
def AllCompressUV(self, DC, arr):
s = ''
DC = self.VLI(DC)
s += self.DC_UV[DC[0]] + DC[1]
for num in arr:
runlength = num[0]
value = num[1]
temp = self.VLI(value)
while runlength > 15:
runlength -= 15
s += self.AC_UV[(15,0)]
s += self.AC_UV[(runlength, temp[0])]
s += temp[1]
return s
综合压缩测试
Z = AC.ZScan(first)
DC = first[0][0]
AC = AC.RLC(Z)
print('Z : ' + str(Z))
print('DC: ' + str(DC))
print('AC: ' + str(AC))
print('AClen: ' + str(len(AC)))
8*8矩阵:

该矩阵的 DCT 变换结果(取整):

量化结果(取整):

Z 字形扫描,DC 系数,AC 系数(未列全),二进制字符串,串长:
 可以看到此处二进制长 27位,意思是已经将一个 8 * 8 * 8(512)bit 的图像压缩为 27bit。
可以看到此处二进制长 27位,意思是已经将一个 8 * 8 * 8(512)bit 的图像压缩为 27bit。
6.5 译码解压缩
现在考虑译码,首先需要事先保存图片的长宽,图片位流里会保存,以此计算 出 Y,U,V 图像的矩阵数,才能在译码过程中对整个二进制流正确分割。 在 Compress 类的 encoding 函数中,参数是位流(字符串形式)与宽,高(整型)。 实验根据宽高得到 Y、 U、 V 图像的 8*8 矩阵的数量(我们知道 U 和 V 是一样多的), 然后从位流头部开始移动两个指针。同样可先用字典得到上面使用的四个哈夫曼编码表的反向映射。已知两个指针之间的二进制码的含义必定在几个状态之间转换:读取 DC 系数的 size(通过不断比较两个指针之间的位流是否为字典的 key,是的话得到其 value(这里指字典的 value),即 size,不是则移动尾指针; 通过 size 得到新的头尾指针,得到 amplitude;然后开始读取 AC 系数的 (runlength,size),如同上面得到DC系数的size一样,获得size后以此得到amplitude; 循环读取 AC 系数直到读取翻译到的(runlength, value)为(0,0)或得到 63 个 AC 系数 为止,将 DC 系数与 AC 系数都加进各自的列表中(这两列表将存储全部 Y 矩阵的 DC 系数与 AC 系数)。U 与 V 同理,最终我们得到 Y、U、V 的 DC 系数与 AC 系数 的数据:
def encoding(self, s, height, width):
Yheight = (height - 1) // 8 + 1
Ywidth = (width - 1) // 8 + 1
UVheight = (height - 1) // 2 // 8 + 1
UVwidth = (width - 1) // 2 // 8 + 1
iterHead = 0
iterTail = 1
DCY = []
DCU = []
DCV = []
ACY = []
ACU = []
ACV = []
while len(ACY) < Yheight * Ywidth:
while s[iterHead:iterTail] not in self.DC_Y2.keys():
iterTail += 1
size = self.DC_Y2[s[iterHead:iterTail]]
iterHead = iterTail
iterTail += size
if size == 0:
amplitude = 0
else:
amplitude = self.VLIEncoding(s[iterHead:iterTail])
DCY.append(amplitude)
iterHead = iterTail
iterTail += 1
ACBlockY = []
length = 0
while True:
runlength = 0
amplitude = 0
while True:
while s[iterHead:iterTail] not in self.AC_Y2.keys():
iterTail += 1
t = self.AC_Y2[s[iterHead:iterTail]]
if t == (15, 0):
runlength += 15
iterHead = iterTail
iterTail += 1
else:
runlength += t[0]
size = t[1]
break
iterHead = iterTail
iterTail += size
if size == 0:
amplitude = 0
else:
amplitude = self.VLIEncoding(s[iterHead:iterTail])
ACBlockY.append([runlength, amplitude])
iterHead = iterTail
iterTail += 1
length += 1
length += runlength
if [runlength, amplitude] == [0, 0] or length == 63:
break
ACY.append(ACBlockY)
while len(ACU) < UVheight * UVwidth:
while s[iterHead:iterTail] not in self.DC_UV2.keys():
iterTail += 1
size = self.DC_UV2[s[iterHead:iterTail]]
iterHead = iterTail
iterTail += size
if size == 0:
amplitude = 0
else:
amplitude = self.VLIEncoding(s[iterHead:iterTail])
DCU.append(amplitude)
iterHead = iterTail
iterTail += 1
ACBlockU = []
while True:
runlength = 0
amplitude = 0
while True:
while s[iterHead:iterTail] not in self.AC_UV2.keys():
iterTail += 1
t = self.AC_UV2[s[iterHead:iterTail]]
if t == (15, 0):
runlength += 15
iterHead = iterTail
iterTail += 1
else:
runlength += t[0]
size = t[1]
break
iterHead = iterTail
iterTail += size
if size == 0:
amplitude = 0
else:
amplitude = self.VLIEncoding(s[iterHead:iterTail])
ACBlockU.append([runlength, amplitude])
iterHead = iterTail
iterTail += 1
if [runlength, amplitude] == [0, 0]:
break
ACU.append(ACBlockU)
while len(ACV) < UVheight * UVwidth:
while s[iterHead:iterTail] not in self.DC_UV2.keys():
iterTail += 1
size = self.DC_UV2[s[iterHead:iterTail]]
iterHead = iterTail
iterTail += size
if size == 0:
amplitude = 0
else:
amplitude = self.VLIEncoding(s[iterHead:iterTail])
DCV.append(amplitude)
iterHead = iterTail
iterTail += 1
ACBlockV = []
while True:
runlength = 0
amplitude = 0
while True:
while s[iterHead:iterTail] not in self.AC_UV2.keys():
iterTail += 1
t = self.AC_UV2[s[iterHead:iterTail]]
if t == (15, 0):
runlength += 15
iterHead = iterTail
iterTail += 1
else:
runlength += t[0]
size = t[1]
break
iterHead = iterTail
iterTail += size
if size == 0:
amplitude = 0
else:
amplitude = self.VLIEncoding(s[iterHead:iterTail])
ACBlockV.append([runlength, amplitude])
iterHead = iterTail
iterTail += 1
if [runlength, amplitude] == [0, 0]:
break
ACV.append(ACBlockV)
return DCY, DCU, DCV, ACY, ACU, ACV
然后通过 DC 类中的 DPCM2(DC)函数,传入各自的 DC 系数,得到三个其元素是一 个矩阵的列表,每个矩阵的[0][0]都通过 DC 系数还原为编码前:
def DPCM2(self, arr):
blocks = []
for i in range(len(arr)):
temp = [[0 for i in range(8)] for i in range(8)]
if i == 0:
temp[0][0] = arr[0]
else:
temp[0][0] = arr[i] + blocks[i-1][0][0]
blocks.append(temp)
return blocks
然后对每个矩阵分别通过对应的 DC 系数还原为 63 个数:
def RLE(self, a):
temp = []
for s in a:
zero = s[0]
num = s[1]
if num == 0:
for i in range(63 - len(temp)):
temp.append(0)
break
for i in range(zero):
temp.append(0)
temp.append(num)
return temp
再 Z 形填进矩阵中
分别逆量化(Quantization.reY(img)与 Quantization.reUV(img)),因为亮度与色度量 化表不一样因此要分别操作:
def reY(self, img):
temp = [[0 for i in range(8)] for i in range(8)]
for i in range(8):
for j in range(8):
temp[i][j] = round(img[i][j] * self.table0[i][j])
return temp
def reUV(self, img):
temp = [[0 for i in range(8)] for i in range(8)]
for i in range(8):
for j in range(8):
temp[i][j] = round(img[i][j] * self.table1[i][j])
return temp
再二维逆离散余弦变换(DCT.IDCT(img):
def IDCT(self, block):
temp = [[0 for i in range(8)] for i in range(8)]
for i in range(8):
for j in range(8):
n = 0
for u in range(8):
for v in range(8):
n += math.cos((2 * i + 1) * u * math.pi / 16) * math.cos((2 * j + 1) * v * math.pi / 16) * \
block[u][v] * self.C(u) * self.C(v) / 4
temp[i][j] = round(n)
return temp
这段操作每个函数的对象都是单个矩阵 。
通过对所有矩阵进行同样的操作我们能得到所有当初刚分割完的 8*8 矩阵(不算损失的话)。 同样通过对这些矩阵进行合拼并将当初填充的 0 割掉,得到 Y、U、V 图像 ,注意需要图像的长宽作为参数:
def merge(self, imgY, imgU, imgV, height, width):
Yheight = (height - 1) // 8 + 1
Ywidth = (width - 1) // 8 + 1
UVheight = (height - 1) // 2 // 8 + 1
UVwidth = (width - 1) // 2 // 8 + 1
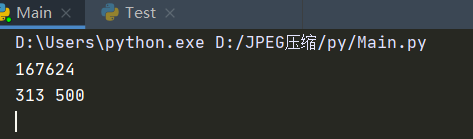
综上处理后:
 解压后:
解压后:

实验结果分析:如果直接用 RGB 的 24 位保存313 * 500像素 将要 3756000bit ,而现在只需167624bit,压缩效率还是不错的。
然而压缩的代价也十分明显。其中黑色变为其他颜色的点主要是 YUV420 中大量色度损失导致的,直接将图片从 RGB 转为 YUV 再直接转为 RGB 就会有这些点的损失,颜色也同样有不少损失,建筑和倒影能看到明显的格子化。















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









