







 本文探讨了深度学习中L2正则化和Dropout技术,展示了它们如何有效防止过拟合。实验结果显示,L2正则化使训练集和测试集的准确率更接近,而Dropout进一步提升了测试集的准确率。
本文探讨了深度学习中L2正则化和Dropout技术,展示了它们如何有效防止过拟合。实验结果显示,L2正则化使训练集和测试集的准确率更接近,而Dropout进一步提升了测试集的准确率。
本次实验着重介绍了L2正则化以及Dropout正则化
没有正则化的表现

此时发生了过拟合,边界出现了很多突起。
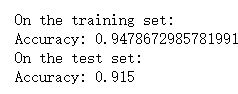
测试集准确率低于训练集,方差较大
L2正则化
计算新的损失函数(利用np.sum消除for循环)
# GRADED FUNCTION: compute_cost_with_regularization
def compute_cost_with_regularization(A3, Y, parameters, lambd):
"""
Implement the cost function with L2 regularization. See formula (2) above.
Arguments:
A3 -- post-activation, output of forward propagation, of shape (output size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
parameters -- python dictionary containing parameters of the model
Returns:
cost - value of the regularized loss function (formula (2))
"""
m = Y.shape[1]
W1 = parameters["W1"]
W2 = parameters["W2"]
W3 = parameters["W3"]
cross_entropy_cost = compute_cost(A3, Y) # This gives you the cross-entropy part of the cost
### START CODE HERE ### (approx. 1 line)
L2_regularization_cost = (np.sum(W2*W2)+np.sum(W1*W1)+np.sum(W3*W3))/2/m*lambd
### END CODER HERE ###
cost = cross_entropy_cost + L2_regularization_cost
return cost
重写反向传播,只需要在原有基础上增加范数部分的导数lambd/m*W即可
# GRADED FUNCTION: backward_propagation_with_regularization
def backward_propagation_with_regularization(X, Y, cache, lambd):
"""
Implements the backward propagation of our baseline model to which we added an L2 regularization.
Arguments:
X -- input dataset, of shape (input size, number of examples)
Y -- "true" labels vector, of shape (output size, number of examples)
cache -- cache output from forward_propagation()
lambd -- regularization hyperparameter, scalar
Returns:
gradients -- A dictionary with the gradients with respect to each parameter, activation and pre-activation variables
"""
m = X.shape[1]
(Z1, A1, W1, b1, Z2, A2, W2, b2, Z3, A3, W3, b3) = cache
dZ3 = A3 - Y
### START CODE HERE ### (approx. 1 line)
dW3 = 1./m * np 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









