









yaml文件解析
yolov5使用yaml文件,通过./models/yolo.py解析
YOLOv5s网络结构:
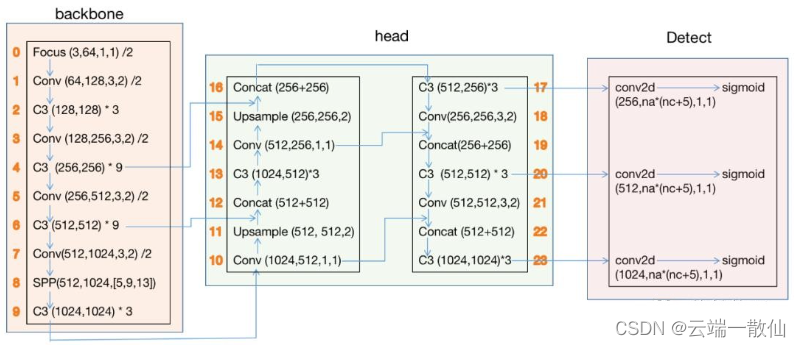
其中橙色的数字表示层号,0-9层构成backbone,10-23层构成head,17、20、23 层的输出是Detect()函数的输入。
- C3后的参数表示(c_in, c_out)* 该模块堆叠的次数
- Conv和Focus参数(c_in, c_out, kernel_size, stride)
- SPP后的参数(c_in, c_out, [kernel_size1,kernel_size2,kernel_size3])
- Concat是axes=1时的合并
- upsample的scale_factor为2,输出图像为输入的2倍
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple(控制子模块数量,模型的深度)
width_multiple: 0.50 # layer channel multiple(控制卷积核数量),用于设置 arguments,例如 yolov5s 设置为 0.5,则 Focus 就变成 [32, 3],Conv 就变成 [64, 3, 2]。以此类推,卷积核的个数都变成了设置的一半
# anchors
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 backbone
backbone:
# [from, number, module, args]
# from 列参数:-1 代表是从上一层获得的输入,-2 表示从上两层获得的输入
# number 列参数:1 表示只有一个,3 表示有三个相同的模块
# module 表示模块:包括 SPP、Conv、Bottleneck、BottleneckCSP,代码在./models/common.py中
# args 这里的输入都省去了,因为输入都是上层的输出。为了修改过于麻烦,这里输入的获取是从./models/yolo.py的def parse_model(md, ch)函数中解析得到的
# [64, 3] 解析得到 [3, 32, 3] ,输入为3(RGB),输出为32,卷积核 k 为3
[[-1, 1, Focus, [64, 3]], # 0-P1/2
# [128, 3, 2] 这是固定的,128 表示输出 128 个卷积核个数。根据 [128, 3, 2] 解析得到 [32, 64, 3, 2] ,32 是输入,64 是输出(128*0.5=64),3 表示3×3的卷积核,2 表示步长为2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, C3, [1024, False]], # 9
]
# YOLOv5 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- Focus(yolov5从6.0版本后使用conv替代Focus)
一种下采样方法,从高分辨率图像中,周期性的抽出像素点重构到低分辨率图像中,即将图像相邻的四个位置进行堆叠,聚焦 wh 维度信息到 c 通道空间,提高每个点感受野,并减少原始信息的丢失。一种 space to depth 方法。
class Focus(nn.Module):
# Focus wh information into c-space
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Focus, self).__init__()
self.conv = Conv(c1 * 4, c2, k, s, p, g, act)
def forward(self, x): # x(b,c,w,h) -> y(b,4c,w/2,h/2)
return self.conv(torch.cat([x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]], 1))
具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长的差不多,但是没有信息丢失,这样一来,将 W、H 信息就集中到了 C 维度,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以yolov5s为例,原始的 640 × 640 × 3 的图像输入Focus结构,采用切片操作,先变成 320 × 320 × 12 的特征图,再经过一次卷积操作,最终变成 320 × 320 × 32 的特征图。
- Conv
CONV层使用的激活函数是 Hardswish;
atuopad 是自动填 padding 的值,在k=1的时候,padding=0,在k=3的时候padding=1,保证了卷积模式为 same。
class Conv(nn.Module):
# Standard convolution
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True): # ch_in, ch_out, kernel, stride, padding, groups
super(Conv, self).__init__()
self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p), groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.Hardswish() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))
def fuseforward(self, x):
return self.act(self.conv(x))
def autopad(k, p=None): # kernel, padding
# Pad to 'same'
if p is None:
p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-pad
return p
- BottleneckCSP
瓶颈层的瓶颈主要体现在通道数上面。一般 1 x 1 卷积具有很强的灵活性,这里用于降低通道数,如膨胀率为 0.5,若输入通道为 640,那么经过1 x 1 的卷积层之后变为 320;经过 3x3 之后变为输出的通道数,这样参数量会大量减少。
Bottleneck:
class Bottleneck(nn.Module):
# Standard bottleneck
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g=g)
self.add = shortcut and c1 == c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
- c1:bottleneck 结构的输入通道维度;
- c2:bottleneck 结构的输出通道维度;
- shortcut:是否给bottleneck 结构添加shortcut连接,添加后即为ResNet模块;
- g:groups,通道分组的参数,输入通道数、输出通道数必须同时满足被groups整除;
- e:expansion: bottleneck 结构中的瓶颈部分的通道膨胀率,使用0.5即为变为输入的1/2;
CSP Bottleneck:
class BottleneckCSP(nn.Module):
# CSP Bottleneck https://github.com/WongKinYiu/CrossStagePartialNetworks
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super(BottleneckCSP, self).__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = nn.Conv2d(c1, c_, 1, 1, bias=False)
self.cv3 = nn.Conv2d(c_, c_, 1, 1, bias=False)
self.cv4 = Conv(2 * c_, c2, 1, 1)
self.bn = nn.BatchNorm2d(2 * c_) # applied to cat(cv2, cv3)
self.act = nn.LeakyReLU(0.1, inplace=True)
self.m = nn.Sequential(*[Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)])
def forward(self, x):
y1 = self.cv3(self.m(self.cv1(x)))
y2 = self.cv2(x)
return self.cv4(self.act(self.bn(torch.cat((y1, y2), dim=1))))
- c1:BottleneckCSP 结构的输入通道维度;
- c2:BottleneckCSP 结构的输出通道维度;
- n:bottleneck 结构 结构的个数;
- shortcut:是否给bottleneck 结构添加shortcut连接,添加后即为ResNet模块;
- g:groups,通道分组的参数,输入通道数、输出通道数必须同时满足被groups整除;
- e:expansion: bottleneck 结构中的瓶颈部分的通道膨胀率,使用0.5即为变为输入的12;
- torch.cat((y1, y2), dim=1):这里是指定在第1个维度上进行合并,即在channel维度上合并;
- c_:BottleneckCSP 结构的中间层的通道数,由膨胀率e决定。
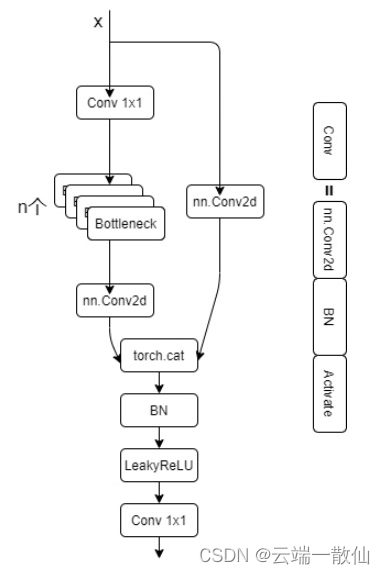
CSP bottleneck 结构在 Bottleneck 部分存在一个可修改的参数 n,标识使用的Bottleneck结构个数。这一条也是我们的主分支,是对残差进行学习的主要结构,右侧分支nn.Conv2d是shortcut分支。
倘若该层后面有BN层的话,一般选择bias=False(因为BN包含偏置),而后面没有的时候bias=True。上面的 Conv 层和 CSPNet 也是这个规律
训练命令:
cfg 设置网络结构的配置文件(如果有.pt,可以忽略)
python train.py --img 640 --batch 32 --epochs 81 --data data/head_tail.yaml --weights yolov5n.pt --device 0,2
- –weights (⭐)指定权重,如果不加此参数会默认使用COCO预训的yolov5s.pt,–weights ''则会随机初始化权重
- –cfg 指定模型文件
- –data (⭐)指定数据文件
- –hyp指定超参数文件
- –epochs (⭐)指定epoch数,默认300
- –batch-size (⭐)指定batch大小,默认16,官方推荐越大越好,用你GPU能承受最大的batch size,可简写为–batch
- –img-size 指定训练图片大小,默认640,可简写为–img
- –name 指定结果文件名,默认result.txt
- –device (⭐)指定训练设备,如–device 0,1,2,3
- –local_rank 分布式训练参数,不要自己修改!
- –log-imgs W&B的图片数量,默认16,最大100
- –workers 指定dataloader的workers数量,默认8
- –project 训练结果存放目录,默认./runs/train/
- –name 训练结果存放名,默认exp 无参:
- –rect矩形训练
- –resume 继续训练,默认从最后一次训练继续
- –nosave 训练中途不存储模型,只存最后一个checkpoint
- –notest 训练中途不在验证集上测试,训练完毕再测试
- –noautoanchor 关闭自动锚点检测
- –evolve超参数演变
- –bucket使用gsutil bucket
- –cache-images 使用缓存图片训练
- –image-weights 训练中对图片加权重
- –multi-scale 训练图片大小+/-50%变换
- –single-cls 单类训练
- –adam 使用torch.optim.Adam()优化器
- –sync-bn 使用SyncBatchNorm,只在分布式训练可用
- –log-artifacts 输出artifacts,即模型效果
- –exist-ok 如训练结果存放路径重名,不覆盖已存在的文件夹
- –quad 使用四分dataloader
测试命令
python val.py --weights ./weights/yolov5s.pt --data ./data/coco.yaml --img 672
- –weights(⭐) 测试所用权重,默认yolov5sCOCO预训练权重模型
- –data(⭐) 测试所用的.yaml文件,默认使用./data/coco128.yaml
- –batch-size 测试用的batch大小,默认32,这个大小对结果无影响
- –img-size 测试集分辨率大小,默认640,测试建议使用更高分辨率
- –conf-thres目标置信度阈值,默认0.001
- –iou-thresNMS的IOU阈值,默认0.65
- –task 指定任务模式,train, val, 或者test,测试的话用–task test
- –device 指定设备,如–device 0 –device 0,1,2,3 –device cpu
- –project 指定结果存放路径,默认./runs/test/
- –name 指定结果存放名,默认exp
- –single-cls 视为只有一类
- –augment 增强识别
- –verbose 输出各个类别的mAP
- –save-txt 输出标签结果(yolo格式)
- –save-hybrid 输出标签+预测混合结果到txt
- –save-conf 保存置信度至输出文件中
- –save-json 保存结果为json
- –exist-ok 若重名不覆盖 ``
















 390
390











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









