







词梯问题的例子
使用图的 宽度优先算法 解决 词梯问题。
词梯问题介绍:考虑这样一个任务:将单词 FOOL 转换成 SAGE。在解决词梯问题时,必须每次只替换一个字母,并且每一步的结果都必须是一个单词,而不能是不存在的词。
例子:
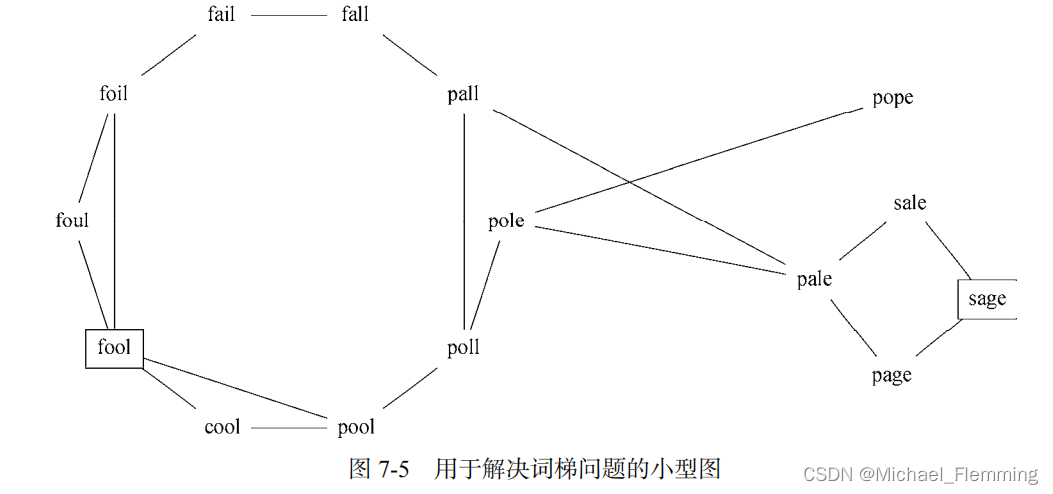
第一步:构建图,只有一个字母不同的单词连边
思路:
方法1:先将每一个单词赋予顶点对象。将每一个单词与其他单词对比,只相差一个字母的两个单词添加边。
但是这种办法复杂度太高,进行O(n^2)次比较。×
方法2:用词桶的办法。一边读单词,一边就把单词放到对应的桶里面,同一个桶里面的单词肯定是邻接的。
这样就不用做比较了。(其实这时候比较蕴含在,通配字符串是否存在于字典中,但是复杂度会小很多。)

# 词梯
from pythonds.graphs import Graph
def build_graph(file_name):
g = Graph()
f = open(file_name)
buckets_dict = {}
# 读取单词,并将其放入词桶
for line in f.readlines():
word = line[:-1]
for i in range(len(word)):
bucket = word[i] + '_' + word[i + 1:]
if bucket in buckets_dict:
buckets_dict[bucket].append(word)
else:
buckets_dict[bucket] = [word]
# 创建图
for b_list in buckets_dict.values():
for w in b_list:
for v in b_list:
if w != v:
g.addEdge(w, v)
return g
第二步:找到最短路径–宽度优先搜索BFS
(breadth first search)
- 我先用算法形式,描述一遍代码过程:
初始化:
将开始点的pre设置为None,distance设置为0,入队。
循环:
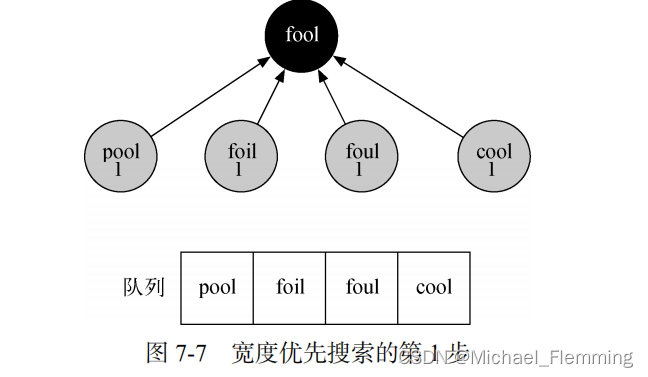
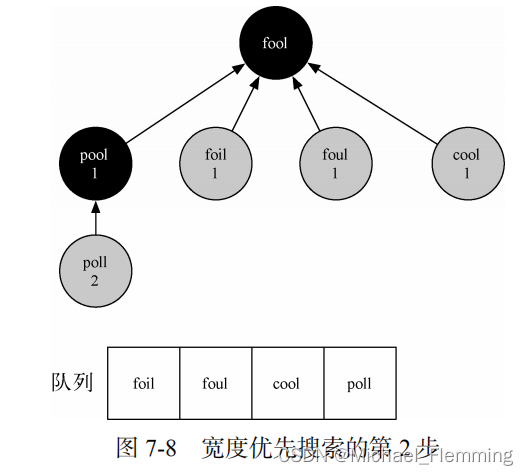
出队一个点作为当前节点,标记为黑色。
遍历其邻接表,如果nbr是白色,就将其标记为灰色,将其pre设置为当前节点,将其distance设置为当前顶点+1,并入队。
以上循环直到队列为空。
评价:出队的顶点黑色;在队列里的灰色,还没入队的白色。
上述过程可以用一个树来表示,其实是建立了一棵宽度优先搜索树。
书上的描述语言是这样的:

用图形来解释:

下面是代码 dfs 函数:
def dfs(g, start):
"""
g:要进行宽度优先搜索的图
start:搜索的起始顶点
"""
# 初始化
# 先将g中所有顶点的颜色设置成白色
[vert.setColor('white') for vert in g]
q = Queue()
start.setDistance(0)
start.setPred(None)
q.enqueue(start)
while q.size() > 0:
current_vert = q.dequeue()
current_vert.setColor('black')
for nbr in current_vert.getConnections():
if nbr.getColor() == 'white':
nbr.setColor('gray')
nbr.setPred(current_vert)
nbr.setDistance(current_vert.getDistance() + 1)
q.enqueue(nbr)
第三步:找到fool转sage的最短词梯–回溯宽度优先搜索树
我们可以用从上面建立的宽度优先搜索树的任意节点开始,沿着pred回溯到根节点,来找到fool转换成任意单词的最短路径。
注意:我们设置了根节点的pred是None。
下面是回溯函数:
def traverse(x):
"""回溯"""
print('distance:', x.getDistance())
print('route:')
while x.getPred():
print('\t', x.getId())
x = x.getPred()
print('\t', x.getId())
最后:测试结果
# 创建图
words_graph = build_graph('words.txt')
# 建立宽度优先搜索树
dfs(words_graph, words_graph.getVertex('fool'))
# 回溯寻找路径
traverse(words_graph.getVertex('sage'))
distance: 6
route:
sage
sale
pale
pall
poll
pool
fool
注: 文本文件中单词顺序不同,创建的搜索树也可能不同。但是最短距离肯定是一样的,因为图是唯一的。
宽度优先搜索复杂度分析
while循环遍历的是队列元素,每个顶点就入队一次,出队一次,所以这个复杂度是O(V)。
for循环遍历每个顶点的邻接表,复杂度是O(E).
总的时间复杂度就是O(V+E)















 4093
4093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









