







Comparative Study of Domain Driven Terms Extraction Using Large Language Models
使用大型语言模型提取领域驱动术语的比较研究
paper: https://arxiv.org/abs/2404.02330
就是采用pubmed和inspec数据集,然后通过设计prompt调用LLM生成关键词,从而去分析哪个大模型的效果更好,没什么东西的文章
文章目录~
1.背景动机
介绍传统的keywords extraction方法,并引出LLM:
传统的关键词提取方法通常依赖于统计指标和语言模式,LLM可以准确无误地捕捉上下文的细微差别、语义关系和特定领域的复杂性。传统的关键字提取方法包括基于频率的方法、基于图的方法和统计方法:
- TF-IDF 根据文档所属的语料库给单词打分,是一种数字统计方法,能揭示单词在文本中的相对重要性。
- 基于图的方法,如 TextRank,使用图结构来表示术语关系。
介绍本文所做的工作,即对LLM执行关键词抽取性能的研究与分析:
- 本综述论文旨在通过对最先进的大型语言模型进行全面分析。
- 对这些模型在科学文献基准集 Inspec 和 PubMed 数据集上的性能进行了深入评估。
- 本研究旨在深入了解 GPT 3.5、LLama2-7B 和 Falcon-7B 在关键词提取方面的性能,重点关注定量和定性评估。
2.Model
1.介绍关键词抽取选取的评估数据集:
IInspec 包含 1998 年至 2002 年间收集的 500 篇计算机科学科学期刊论文摘要。每篇文献都有两组分配的关键词:uncontrolled keywords是编辑自由分配的关键词,不局限于词库或文献;controlled keywords词是人工控制分配的关键词,出现在 Inspec 词库中,但可能不会出现在文献中。
PubMed 数据集包括精心挑选的 500 篇摘要。用于比较 PubMed 数据的关键词是使用索引词从这 500 篇论文中提取的。
2.介绍评价指标:
采用了 Jaccard 相似度统计。
J
(
A
,
B
)
=
∣
A
∩
B
∣
∣
A
∪
B
∣
(1)
J(A,B)=\frac{|A\cap B|}{|A\cup B|}\tag{1}
J(A,B)=∣A∪B∣∣A∩B∣(1)
Jaccard 相似度为 1 表示模型的关键词与参考关键词完全匹配,而 Jaccard 相似度为 0 则表示模型的关键词没有一个与参考关键词匹配。
3.介绍LLM中的提示工程:
在 LLM 领域,提示工程关注的是为 LLMs 创建最佳指令,使其成功完成任务。本文简要概述了各种提示工程方法:
- 思维链 (CoT) 提示法:引导 LLM 通过逻辑推理过程逐步解决复杂的任务。这种方法尤其适用于将复杂的任务分解为更简单的渐进步骤。
- 思维树(ToT)提示:它能帮助 LLMs 探索一般问题解决的中间步骤,增强其处理复杂推理任务的能力。
- 掐头去尾和前缀提示:这包括创建提示,让 LLM 填空(掐词提示)或根据给定的起始短语生成文本(前缀提示)。
- 定制提示设计:这种方法是根据任务的具体要求设计独特的提示,从而与 LLM 进行更有针对性和更有效的互动。
在本研究中,采用了与任务目标相一致的定制零镜头提示。
4.介绍本文提示工程的构造:
引入了一个函数 f t e x t / K e y w o r d E x t r a c t i o n ( P , L ) f_{text/{KeywordExtraction}}(P,L) ftext/KeywordExtraction(P,L),构建了我们的提示,该函数需要两个参数:
P 是助手的属性,而 L 则是要进行关键词提取的输入文本。该函数的输出是一个结构化的提示,它将这些元素结合在一起,并引入了一个 [MASK] 占位符,表示模型的输出(即提取的关键词)将被填充到哪里。阐明了交互的每个阶段:
- 用户输入对应于输入文本 L。
- 提示模板与属性 P 和应用 KaTeX parse error: Expected 'EOF', got '}' at position 28: …wordExtraction}}̲ 创建提示相关联。
- LLM 表示 LLM 解释和处理提示的计算过程。
- 最后,"生成模板 "反映的是 [MASK] 被填充为输出响应,即提取的关键词集。
5.Llama2-7B:
Llama2-7B模型使用了分组查询关注,预训练语料的大小增加了一倍,模型的上下文长度增加了 40%。拒绝采样和近端策略优化(PPO)这两项技术被用于人类反馈强化学习(RLHF)技术中,用于迭代改进模型
6.Gpt-3.5:
GPT-3.5 是 GPT-3 的改进版,采用了更少的参数,并结合了机器学习算法微调。微调过程包括强化学习和人工反馈。
7.Falcon-7B:
Falcon-7B 是由 TII 建立的 7B 参数因果解码器模型。它是在精炼网络(Refined Web)的 1500B 个词库上训练而成的
8.结果分析:
GPT-3.5 在 Inspec 和 PubMed 数据集上的平均 Jaccard 相似度得分最高。
在从模型中提取特定领域术语的过程中,采用了一个特定的温度参数,其值设为 0.2。温度是调节 LLM 随机性输出的一个参数。温度越高,文本就越有创意和想象力,而温度越低,文本就越准确和符合事实。
8.1.对Llama2-7B结果分析:
Llama2-7B 生成的额外关键词在参考文献 Inspec 和 PubMed 中并不存在。这表明 Llama2-7B 有能力识别参考集中可能被忽略的术语。
8.2.对GPT-3.5结果分析:
GPT-3.5 的输出中没有不必要的信息,这有助于提高用户友好性,而专注于生成关键词则有助于提高模型的清晰度和效率。不过,由于引入了一些可能与幻觉有关的新词汇,而且与 GPT 3.5 提取的关键词相比,参考的 PubMed 索引词非常少,因此 PubMed 集的总体 Jaccard 相似度得分可能较低。
8.3.对Falcon-7B结果分析:
Falcon-7B 的 Jaccard 相似度得分相对较低,这表明与其他模型相比,所识别术语的一致性程度较低。研究发现,在提取极少数相关关键词的同时,也提取了一些不必要的词,这影响了提取关键词的整体质量。此外,检索到的相关关键词相对较少这一发现表明,Falcon-7B 的输出行为类似于幻觉。
3.原文阅读
Abstract
关键词在缩小人类理解与机器处理文本数据之间的差距方面发挥着至关重要的作用。关键词是丰富数据的必要条件,因为它们是详细注释的基础,而详细注释可提供对基础数据更深入的洞察力。关键词/领域驱动的术语提取是自然语言处理中的一项关键任务,有助于信息检索、文档摘要和内容分类。本综述重点介绍关键词抽取方法,强调三大大型语言模型(LLM)的使用: Llama2-7B、GPT-3.5 和 Falcon-7B。我们使用了一个定制的 Python 软件包来连接这些 LLM,从而简化了关键词提取。我们的研究利用 Inspec 和 PubMed 数据集评估了这些模型的性能。评估中使用了 Jaccard 相似性指数,GPT-3.5 的得分分别为 0.64(Inspec)和 0.21(PubMed),Llama2-7B 的得分分别为 0.40 和 0.17,Falcon-7B 的得分分别为 0.23 和 0.12。**本文强调了 LLM 中的提示工程对更好地提取关键词的作用,并讨论了 LLM 中的幻觉对结果评估的影响。**它还揭示了使用 LLMs 提取关键词所面临的挑战,包括模型复杂性、资源需求和优化技术。
1 Introduction
介绍LLM的发展与应用场景:
近年来,由于大型语言模型(LLM)的迅速发展,自然语言处理学科迎来了一场革命。考虑到训练方法看似简单明了,LLMs 的能力令人瞩目。随着 LLM 的发展,它已经开始超越许多传统使用的机器学习模型。这些模型已在相当大的文本语料库中进行了预训练,能够捕捉复杂的语法和语义结构,并在文本生成、情感分析、表格数据嵌入、命名实体识别、药物不良反应检测等众多任务中展现出非凡的能力。关键词提取就是其中一项突出的应用,它是信息检索、文档摘要和内容分类中的一项基本任务。
介绍keywords的重要性:
在这种情况下,我们开发了一个 Python 软件包,专门用于使用这些高级 LLMs 提取关键词。该工具是我们研究的重要组成部分,有助于将 LLMs 实际应用于从各种文本语料库中提取相关关键词。关键词在缩小人类理解与机器处理文本数据之间的差距方面发挥着关键作用。关键词是各种搜索引擎和许多机器学习框架的重要资产,因为它们是 NLP 或任何 ML 任务的主要特征。关键词对数据丰富至关重要,因为它们是详细注释的基础,而详细注释可提供对底层数据更深入的洞察力。关键词可以有效地索引内容、总结文档和检索信息,因为它们可以捕捉作品中的主要观点和主题。战略性地使用关键词是丰富数据的有力工具,因为它可以添加全面的注释,从而增强整体语境。
介绍传统的keywords extraction方法,并引出LLM:
传统的关键词提取方法通常依赖于统计指标和语言模式,这些方法已经产生了有价值的见解。然而,LLM 的出现开创了关键词提取的新时代,它可以准确无误地捕捉上下文的细微差别、语义关系和特定领域的复杂性。传统的关键字提取方法包括基于频率的方法、基于图的方法和统计方法,这些方法在自然语言处理(NLP)领域具有奠基性的作用。信息检索系统经常使用基于词频的技术,例如词频-反文档频率(TF-IDF),它是使用最广泛的术语加权方案之一。
- TF-IDF 根据文档所属的语料库给单词打分,是一种数字统计方法,能揭示单词在文本中的相对重要性[7]。
- 基于图的方法,如 TextRank,使用图结构来表示术语关系[8]。
现代大语言模型(LLM)在捕捉上下文和语义方面的能力得到了增强,因此更适合在复杂的语言领域中提取关键词。
介绍本文所做的工作,即对LLM执行关键词抽取性能的研究与分析:
随着该领域的发展,人们越来越需要进行全面评估和比较分析,以指导研究人员和从业人员为特定任务选择最合适的 LLM。
- 本综述论文旨在通过对最先进的大型语言模型进行全面分析。
- 我们对这些模型在科学文献基准集 Inspec 和 PubMed 数据集上的性能进行了深入评估。
- 我们对每个模型进行了单独研究,以了解其独特的关键词提取方法。
- 本文还强调了在 LLM 中使用提示工程技术来增强关键词提取的创新性。
- 本研究旨在深入了解 GPT 3.5、LLama2-7B 和 Falcon-7B 在关键词提取方面的性能,重点关注定量和定性评估。
- 在 LLM 中,"幻觉 "是一个更为宽泛和全面的概念,主要侧重于事实不准确。本研究也探讨了法律词典中的幻觉现象,它影响着对结果的整体评估和解释。了解并解决这些与幻觉相关的挑战,对于优化 LLM 在领域驱动的术语提取任务中的性能至关重要。
此外,比较分析还揭示了它们的相对性能,突出了它们带来的进步。
2 Methods
2.1.Dataset Selection
介绍关键词抽取选取的评估数据集:
Inspec 和 PubMed 数据集代表了科学文献所涵盖的多个学科,使用这两个数据集进行的实验为本研究提供了启示。Inspec 包含 1998 年至 2002 年间收集的 500 篇计算机科学科学期刊论文摘要。每篇文献都有两组分配的关键词:非控制关键词是编辑自由分配的关键词,不局限于词库或文献;控制关键词是人工控制分配的关键词,出现在 Inspec 词库中,但可能不会出现在文献中。
另一方面,PubMed 数据集包括精心挑选的 500 篇摘要,这些摘要深入探讨了生物膜与材料之间的交集,反映了这些主题在当代生物医学研究中的关键作用。用于比较 PubMed 数据的关键词是使用索引词从这 500 篇论文中提取的。为了进行比较和分析,我们将两组数据的联合作为基本事实。本文在对 Inspec 数据集的 500 篇文本和 PubMed中的 500 篇摘要进行评估时,对所选大型语言模型的性能进行了比较评估。
2.2.Evaluation Metrics
介绍评价指标:
有几种评价指标可以评估关键词提取方法的质量和有效性。在比较从我们的大型语言模型(LLMs)中提取的关键词与从 Inspec 数据集和 PubMed 数据集中提取的参考关键词时,我们采用了 Jaccard 相似度统计。我们在审查工作中使用了 Jaccard 相似性统计量。比较两组数据相似度的指标是 Jaccard 相似度,有时也称为 Jaccard 系数或 Jaccard ndex。其计算方法是用两个集合的交集大小除以它们的结合大小[12]。
J
(
A
,
B
)
=
∣
A
∩
B
∣
∣
A
∪
B
∣
(1)
J(A,B)=\frac{|A\cap B|}{|A\cup B|}\tag{1}
J(A,B)=∣A∪B∣∣A∩B∣(1)
其中,A 和 B 是集合。
A ∩ B ∣ A\cap B| A∩B∣ 是集合 A 和 B 的交集大小,而是A和B的并集
就关键词提取而言,在第一次评估中,集合 A 和 B 分别代表模型提取的关键词集合和参考 Inspec 关键词集合。第二次评估时,集 A 和 B 分别代表模型提取的关键词集和从 Pubmed 论文中提取的索引词集。
2.2.1 Interpretation
对评价指标进一步讲解:
Jaccard 相似度为 1 表示模型的关键词与参考关键词完全匹配,而 Jaccard 相似度为 0 则表示两组关键词没有重叠,即模型的关键词没有一个与参考关键词匹配。
2.2.2 Use in Comparative Analysis
在比较不同的大型语言模型(LLM)(如 GPT 3.5、LLama2-7B 和 Falcon-7B)时,可以计算每个模型的关键词集与参考集的 Jaccard 相似度。这样就可以对模型在关键词提取准确性方面的性能进行量化评估。
2.3.Framework Utilized and Package Architecture
LangChain框架的使用:
LangChain是一个灵活的框架,可用于创建由语言模型驱动的应用程序。我们创建了一个名为 LangChain 的开源框架,以便更轻松地创建使用 LLM 的应用程序。它提供了一系列部件、工具和接口,使构建以 LLM 为核心的应用程序变得更加容易。LangChain 是将语言模型与各种上下文源(如提示说明、外部材料和少量示例)集成的绝佳工具。它旨在为程序提供语境意识[13]。
在研究用于关键词提取的 LLM 的同时,我们还开发了一个专门的 Python 软件包。该软件包与 LangChain 框架无缝集成,便于与各种 LLM(如 Llama-2 7B、GPT-3.5 和 Falcon-7B)进行高效交互。该软件包的核心是 LLM_Keyword Extractor 类,它封装了用于初始化不同 LLM 和根据定制的提示工程技术提取关键词的功能。该软件包设计灵活,可轻松添加新模型或修改现有提示模板。
2.4.Keyword Visualization with Word Clouds
在关键词匹配过程中,我们还使用词云来直观地表示出现频率最高的词。在词云中,单词根据其出现频率以不同大小显示。
2.5.Prompt Engineering Techniques
介绍提示工程:
在 LLM 领域,提示工程的实践对于指导这些模型高效执行特定任务至关重要。提示工程作为一个新领域,关注的是为 LLMs 创建最佳指令,使其成功完成任务。本文简要概述了各种提示工程方法。此外,我们还介绍了在我们的研究中采用的具体技术。下文将讨论一些提示工程技术:
- 思维链 (CoT) 提示法:这种方法是通过精心设计的提示,引导 LLM 通过逻辑推理过程逐步解决复杂的任务。这种方法尤其适用于将复杂的任务分解为更简单的渐进步骤[14]。
- 思维树(ToT)提示:作为 CoT 的延伸,ToT 提示用于需要探索或战略前瞻的任务。它能帮助 LLMs 探索一般问题解决的中间步骤,增强其处理复杂推理任务的能力 [14]。
- 掐头去尾和前缀提示:这包括创建提示,让 LLM 填空(掐词提示)或根据给定的起始短语生成文本(前缀提示)。每种类型都有不同的适应性,并根据任务要求和模型的预训练目标进行选择 [14]。
- 定制提示设计:这种方法是根据任务的具体要求设计独特的提示,从而与 LLM 进行更有针对性和更有效的互动[14]。
在本研究中,我们采用了与任务目标相一致的定制零镜头提示。我们使用标准化的系统提示,指示 LLM 发挥关键词提取专家的作用。该提示既宽泛又具体,足以引导 LLM 识别输入文本中的主要观点、概念、实体或主题。
介绍本文提示工程的构造:
我们引入了一个函数 f t e x t / K e y w o r d E x t r a c t i o n ( P , L ) f_{text/{KeywordExtraction}}(P,L) ftext/KeywordExtraction(P,L),它正式构建了我们的提示,如等式 2 所示。该函数需要两个参数:
P 是助手的属性,而 L 则是要进行关键词提取的输入文本。该函数的输出是一个结构化的提示,它将这些元素结合在一起,并引入了一个 [MASK] 占位符,表示模型的输出(即提取的关键词)将被填充到哪里。
等式 3 定义了与 LLM 的交互,其中输出响应是 LLM 处理由 KaTeX parse error: Expected 'EOF', got '}' at position 28: …wordExtraction}}̲ 生成的提示的结果。
输出响应是 LLM 对任务的解释和执行,从而产生一组最能代表所提供文本中的主要观点、概念、实体或主题的关键词。
从提示到生成响应的整体流程:
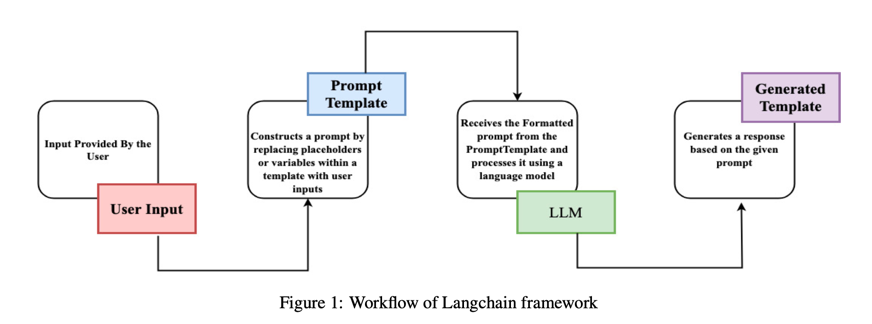
为使这一过程可视化,流程图(参见图 1)阐明了交互的每个阶段:
- 用户输入对应于输入文本 L。
- 提示模板与属性 P 和应用 KaTeX parse error: Expected 'EOF', got '}' at position 28: …wordExtraction}}̲ 创建提示相关联。
- LLM 表示 LLM 解释和处理提示的计算过程。
- 最后,"生成模板 "反映的是 [MASK] 被填充为输出响应,即提取的关键词集。
f t e x t K e y w o r d E x t r a c t i o n ( P , L ) = [ P ] . [ L ] [MASK] (2) f_{text{KeywordExtraction}}(P,L)=[P].[L]\text{ [MASK]}\tag{2} ftextKeywordExtraction(P,L)=[P].[L] [MASK](2)
t e x t O u t p u t r e s p o n s e = LLM ( f t e x t K e y w o r d E x t r a c t i o n ( P , L ) ) (3) text{Output response}=\text{LLM}(f_{text{KeywordExtraction}}(P,L))\tag{3} textOutputresponse=LLM(ftextKeywordExtraction(P,L))(3)
其中, f t e x t K e y w o r d E x t r a c t i o n ( P , L ) f_{text{KeywordExtraction}}(P,L) ftextKeywordExtraction(P,L) 是构建关键词提取提示的函数。
公式中每个符号的具体含义:
- P 表示助手的属性,在我们的语境中,包括乐于助人、尊重他人、诚实和关键词提取专家。阐述这些属性是为了让 LLM 更好地完成任务,从而更有针对性、更准确地提取出代表输入文本中主要观点、概念、实体或主题的关键词。
- L 是要进行关键词提取的输入文本。
- [MASK]是提示符的占位符,表示 LLM 的输出(即提取的关键字)应插入的位置。
- LLM 指的是用于关键词提取任务的特定大语言模型,而输出回复则是 LLM 根据提示生成的关键词集,囊括了输入文本的精髓。
3 Large Language Models
对大语言模型的介绍:
大型语言模型具有很强的理解自然语言和解决复杂任务(通过文本生成)的能力[15]。当我们深入研究大型语言模型的能力和架构时,了解使这些模型能够高效执行关键词提取等任务的底层机制变得至关重要。这些模型的基石,尤其是与 Transformer 架构相关的关注机制。缩放点积注意力是这一机制的关键组成部分,它允许模型动态权衡输入数据不同部分的重要性[16]。其数学表达式为
Attention
(
Q
,
K
,
V
)
=
softmax
(
Q
K
T
d
k
)
V
(4)
\text{Attention}(Q,K,V)=\text{softmax}\left(\frac{QK^{T}}{\sqrt{d_{k}}}\right)V \tag{4}
Attention(Q,K,V)=softmax(dkQKT)V(4)
在这个等式中,
Q
Q
Q、
K
K
K 和
V
V
V 分别代表查询、键值和值矩阵,它们都是从输入的嵌入式数据中导出的。项
d
k
d_{k}
dk 代表键的维度,softmax 函数应用于
Q
Q
Q 和
K
T
K^{T}
KT 矩阵相乘的结果,并按
d
k
d_{k}
dk 缩放,确保权重总和为 1。
在自然语言处理领域,尤其是在关键词提取等任务中,句子中单词的顺序具有重要意义。transformer模型是许多 LLM 的核心,它本身并不考虑输入数据的顺序,而是将输入序列视为集合而非有序列表。为了纠正这种情况,并使模型能够充分利用语言的顺序性,我们使用了位置编码。位置编码向量被添加到嵌入向量中,以提供位置信息[16]。然后,模型可以使用这些向量来确定每个单词在句子中的位置。这对于理解关键字提取等任务所需的上下文和语义至关重要,因为术语的相关性可能取决于位置。
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i model ) (5) PE(pos,2i)=\sin\left(\frac{pos}{10000^{\frac{2i}{\text{model}}}}\right) \tag{5} PE(pos,2i)=sin(10000model2ipos)(5)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i model ) (6) PE(pos,2i+1)=\cos\left(\frac{pos}{10000^{\frac{2i}{\text{model}}}}\right) \tag{6} PE(pos,2i+1)=cos(10000model2ipos)(6)
其中, P E PE PE 是位置编码, p o s pos pos 是序列中的位置, i i i 是维度, d t e x t / m o d e l d_{text/{model}} dtext/model 是模型嵌入的维度。正弦和余弦函数的使用有助于模型轻松确定每个词在序列中的位置。通过将这些函数应用于编码向量中的偶数和奇数位置,模型为每个单词保留了唯一的位置特征。
近年来,自然语言处理学科取得了长足的进步,这主要归功于大型语言模型(LLM)的诞生,它们对人类语言的理解能力无与伦比。这篇综述论文主要关注各种关键词提取方法,并集中讨论了三种重要 LLM 的使用:Llama-2 7B、GPT-3.5 和 Falcon-7B。
3.1.Llama2-7B
Llama2-7B:
Llama2-7B 是 Llama 1 的改进迭代,使用一组新的公开数据进行训练。此外,该模型还使用了分组查询关注,预训练语料的大小增加了一倍,模型的上下文长度增加了 40%。拒绝采样和近端策略优化(PPO)这两项技术被用于人类反馈强化学习(RLHF)技术中,用于迭代改进模型[2]。本文使用的 Llama2 版本是经过预训练和微调的生成式文本模型,拥有 70 亿个参数。
3.2.Gpt-3.5
Gpt-3.5:
自然语言处理领域的新发展,包括 GPT-3 的 1750 亿个参数,推动了 GPT-3.5 模型的开发。GPT-3.5 是 GPT-3 的改进版,采用了更少的参数,并结合了机器学习算法微调。微调过程包括强化学习和人工反馈,这有助于提高算法的准确性和有效性[17]。
3.3.Falcon-7B
Falcon-7B:
Falcon-7B 是由 TII 建立的 7B 参数因果解码器模型。它是在精炼网络(Refined Web)的 1500B 个词库上训练而成的,精炼网络是一个经过高质量过滤和重复的网络数据集,并通过精心策划的语料库进行了增强。该模型以 Apache 2.0 许可[18]发布。
4 Results and Discussion
4.1.Quantitative Results
4.1.1 Jaccard Similarity Scores
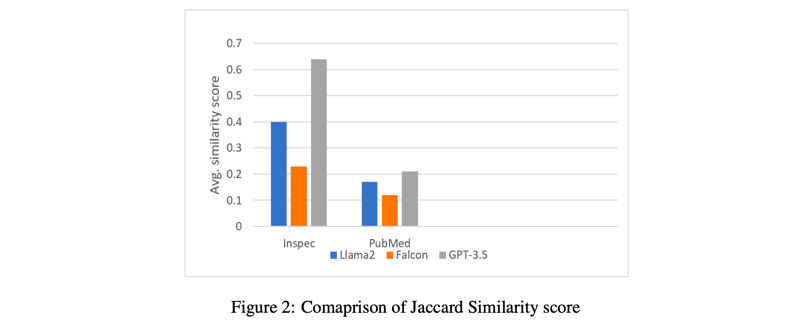
图 2 显示了为每个 LLMs 计算的来自 Inspec 数据集的 500 篇文本和来自 PubMed 数据集的 500 篇摘要的平均 Jaccard 相似度得分。
4.1.2 Observations
从图 2 中可以看出,GPT-3.5 在 Inspec 和 PubMed 数据集上的平均 Jaccard 相似度得分最高,分别为 0.64 和 0.21,这表明其生成的关键字与 Inspec 和 PubMed 的参考关键字有很大的重叠。LLama2-7B 与 Inspec 数据集的比较得分为 0.40,与 PubMed 数据集的比较得分为 0.17,这表明其计算相似性指数的效率较低。Falcon-7B 与参考关键词的重合度很低,与 Inspec 数据集的重合度为 0.23,与 PubMed 数据集的重合度为 0.12。
在从模型中提取特定领域术语的过程中,采用了一个特定的温度参数,其值设为 0.2。在关键词提取过程中,模型的行为在很大程度上受到温度选择的影响。温度是调节 LLM 随机性输出的一个参数。温度越高,文本就越有创意和想象力,而温度越低,文本就越准确和符合事实。在我们的案例中,温度值越低,即 0.2,产生的结果就越容易预测,范围也越窄,这可能会影响所生成关键词的多样性和原创性。由于温度会影响模型输出结果的精确性和多样性之间的平衡,因此在评估和解释关键词提取结果时必须考虑到温度设置的影响。
4.1.3 Package Performance and Utility
我们的软件包能够连接多个 LLM 并有效提取关键词,这对我们的研究非常重要。从 Jaccard 相似度得分可以看出,它不仅具有很高的准确性,而且易于使用,并能适应不同的文本语料库。
4.1.4 Analysis of LLama2-7B
附加关键词:Llama2-7B 生成的额外关键词在参考文献 Inspec 和 PubMed 中并不存在。这表明 Llama2-7B 有能力识别参考集中可能被忽略的术语。尽管生成了额外的关键词,Llama2-7B 在某些情况下仍与参考集保持一定程度的相似性。不过,由于引入了新的术语,而且与 Llama2-7B 提取的关键词相比,参考的 PubMed 索引术语非常少,因此 PubMed 集的总体 Jaccard 相似度得分可能较低。
带定义的关键字:在某些情况下,Llama2-7B 在提取关键字的同时也提取了简短的定义,从而提高了清晰度。虽然这提供了有价值的见解,但由于引入了新术语,导致 Jaccard 相似度得分差异较大
这些观察结果凸显了幻觉对 Llama2-7B 关键字提取的影响,强调了在引入潜在相关的新术语和保持与参考集的相似性之间进行权衡的必要性。
4.1.5 Analysis of GPT-3.5
GPT-3.5 在生成与人工生成的参考集密切匹配的关键词方面表现出了值得称道的能力。这种吻合显示了该模型捕捉内容主旨的能力和准确性。GPT-3.5 的输出中没有不必要的信息,这有助于提高用户友好性,而专注于生成关键词则有助于提高模型的清晰度和效率。不过,由于引入了一些可能与幻觉有关的新词汇,而且与 GPT 3.5 提取的关键词相比,参考的 PubMed 索引词非常少,因此 PubMed 集的总体 Jaccard 相似度得分可能较低。
4.1.6 Analysis of Falcon-7B
Falcon-7B 的 Jaccard 相似度得分相对较低,表明生成的关键词与生成的参考集之间的重叠程度有限。这表明与其他模型相比,所识别术语的一致性程度较低。研究发现,在提取极少数相关关键词的同时,也提取了一些不必要的词,这影响了提取关键词的整体质量。此外,检索到的相关关键词相对较少这一发现表明,Falcon-7B 的输出行为类似于幻觉。
4.1.7 Analysis of factors affecting keyword extraction performance
在考察 Llama2-7B、GPT3.5 和 Falcon-7B 模型的关键词提取能力时,我们注意到了它们在多个领域的能力。模型所表现出的强大语境理解能力影响了关键词的谨慎选择。模型与参考术语紧密配合的能力会受到特定领域问题的影响,例如不断变化的语言使用或微妙的术语,这反过来又会影响相似度得分。由于每个模型的训练数据集存在差异,因此它们对特定关键词提取任务的泛化能力也存在差异。如果训练数据不能完全涵盖关键词提取任务中的文本,模型就很难处理特定领域的术语和上下文,从而导致性能不佳。保持任务相关性与模型复杂性之间的微妙平衡至关重要。对于某些关键词提取任务,需要对模型进行调整,以更好地适应目标领域的具体情况。微调不当可能会导致任务需求与模型预期不匹配。由于关键词提取任务涉及独特的语言和上下文因素,因此模型必须具备强大的机制来适应和可靠地提取信息。
4.2.Qualitative Analysis
4.2.1 Inference Time

推理时间(通常称为延迟或响应时间)是评估大型语言模型(LLM)是否适合各种应用的关键性能指标。它衡量的是 LLM 处理给定输入查询并生成结果所需的时间。在关键词提取方面,了解各种 LLM 的推理时间至关重要,尤其是对于需要快速或实时处理的应用而言。表 I 总结了每种语言模型的推理时间和硬件规格:
4.2.2 Word Cloud Visualization
图 4 显示了使用 Llama2-7B 模型为 PubMed 摘要之一提取关键词的可视化效果。出现较大尺寸的关键词与使用 Llama2-7B 提取的关键词和 PubMed 摘要索引词中出现的关键词相匹配。
5 Challenges and Future Implications
在利用大型语言模型提取关键词方面,有几个障碍需要克服,并会产生长期影响。要解决这些模型之间的差异,就必须制定统一的评估标准和基准。选择合适的衡量标准会给评估程序带来复杂性。Inspec和PubMed等高质量参考数据集的可用性至关重要,但确保它们在不同领域的代表性仍是一个问题。与生成关键词的偏见和潜在滥用有关的伦理考虑也值得关注。展望未来,我们还计划扩展软件包的功能。未来的开发重点将放在优化提取算法、增强软件包的可扩展性以及扩大其对其他 NLP 任务的适用性上。我们还打算探索整合更多的 LLM 和更先进的提示工程技术。
专门为关键词提取开发的大型语言模型在未来是有可能实现的。利用特定领域的数据集对模型进行微调,可以在不久的将来提高关键词提取技术。了解并减轻模型输出中幻觉的影响,对于完善大型语言模型并优化其在特定领域任务中的性能至关重要。此外,整合人类的专业知识并开发交互式、用户友好型工具,可以增强各领域的关键词提取能力,同时保持道德标准并解决偏见问题。
















 6876
6876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









