







Generating a Structured Summary of Numerous Academic Papers: Dataset and Method
生成大量学术论文的结构化摘要: 数据集和方法
paper: https://arxiv.org/abs/2302.04580
github: https://github.com/StevenLau6/BigSurvey
本文介绍了一种学术论文多文档摘要总结的数据集,BigSurvey-MDS:综合总结;BigSurvey-Abs:survey论文的摘要是其正文的简短总结。并提出了一种多文档摘要总结方法:基于类别对齐和稀疏transformer(CAST)的方法。
任务1: 生成多目标综合总结
- 使用survey论文的参考文献论文的摘要作为input,survey论文的引言部分中的重点内容作为output
- 使用基于BERT的句子分类模型SSC分类参考摘要中的:background, method,其他,并使用对齐方法,将归位一类的句子合并;分类survey论文引言中的background,
method,其他,同理。然后使用BigBird或Longformer做为解码器生成目标总结。任务2: 生成简短总结
- 使用survey引言部分作为input,survey摘要作为目标output
- 然后使用BigBird或Longformer做为解码器生成总结。
1.背景动机
介绍多文档摘要的背景:
研究课题的论文摘要可以帮助研究人员快速浏览这些论文中的关键信息。作为一种人工撰写的摘要,survey论文可以对每个研究课题的众多论文进行综述,并指导人们学习该课题。多文档摘要(MDS)技术可用于自动生成摘要,作为人工撰写摘要的补充。
介绍本文提出的数据集工作,即多论文摘要的大规模数据集:
虽然已有一些 MDS 数据集,但大多侧重于生成短且无结构的摘要,无法满足对一个研究课题的大量论文进行综述的实际需求。本文提出了 BigSurvey,包含七千多篇调查论文及其 43.4 万份参考文献摘要。
介绍结构化摘要:
摘要通常包含多个方面的内容,包括背景、方法、目标和结果。与无结构摘要相比,结构化摘要包含多个部分,概括了输入内容的特定方面,更易于阅读。为了兼顾全面性和简洁性,本文建立了 BigSurvey 的两个子集,用于生成两级摘要。BigSurvey-MDS 侧重于生成全面的摘要,BigSurvey-Abs 则是为生成 BigSurvey-MDS 中这些摘要的更简洁摘要。
本文提出的结构化摘要假设:
对于同一主题的多篇论文的结构化摘要,本文有两个假设:
- 研究课题在某一方面的描述是相关论文在这一方面内容的子集(例如,研究课题的背景应该是所有相关论文背景的一部分)。
- 结构化摘要的每个部分都更侧重于 1) 中提到的子集中的突出内容(例如,摘要的背景部分侧重于所有参考文献背景中的突出内容)。
基于这些假设,本文提出了基于类别对齐(CA)的方法,将结构化摘要的每个部分与被归类为同一类型的输入句子集进行对齐。
介绍本文提出的稀疏transformer:
BigSurvey的每个输入文档的平均字数总和约1.2 万。更长的输入会带来更多的噪音,突出内容也会更分散,这就增加了捕捉和编码突出内容的难度。现有神经模型的时间或空间复杂度通常与输入序列长度高度相关,因此长输入序列也会降低摘要模型的效率。
为解决上述问题,本文提出了一种名为基于类别对齐和稀疏transformer(CAST)的方法:
- 使用基于BERT的句子分类法(SSC)和带上下文的句子分类法(SCC)对输入和输出句子进行分类。
- 使用基于类别的对齐方法,对归类为同一类型的输入句子集和目标输出句子集进行对齐,并组成用于训练摘要模型的示例。
- 采用带有稀疏注意力机制的transformer进行抽象总结。稀疏注意力支持对长输入序列建模。
BigSurvey 数据集和 CAST 方法可以生成涵盖数十个输入文档的结构化摘要。
2.Model
2.1. Dataset介绍
1.介绍数据的收集与预处理:
收集:
- 从 arXiv上收集了七千多篇survey论文PDF,用 science-parse的工具对pdf进行解析。
- 从解析结果中提取参考文献的标题和作者。根据这些信息,从MAS和Semantic Scholar中收集参考文献的摘要。总共收集超过 43.4 万篇参考文献。
预处理:
- 首先过滤掉收集数据中的无效样本:删除重复或无法正确解析的下载PDF;过滤掉survey论文中解析文本过短或收集的参考文献极少的异常值。
- 对于每篇被选中的survey论文,去除噪音(例如,第一节版权信息和特殊符号),提取survey论文的摘要和引言部分,并截断其参考文献的摘要。
- 将这些文本小写,并使用 NLTK来分割句子和单词。
- 之后,将以训练集(80%)、验证集(10%)和测试集(10%)分开。
长摘要旨在全面涵盖参考文献在不同方面的突出内容,而短摘要则更为简洁,可视为长摘要的总结。
2.BigSurvey-MDS数据集—结构化总结(长总结):
BigSurvey-MDS:综合总结。BigSurvey-MDS 中的每个示例都与 arXiv中的一篇survey论文相对应。这些survey论文通常有数十篇或数百篇参考文献,BigSurvey-MD使用其摘要作为输入文件。
2.1.BigSurvey-MDS—目标总结的构造:
survey论文的引言部分通常介绍研究的背景、方法和其他方面的内容。本文将survey论文引言的内容分为三个部分(background, method和其他),并将它们作为 BigSurvey-MDS 每个示例的目标来编写结构化总结。(有关objective, result和其他的内容被合并到名为其他的部分)。
为了编写目标摘要中的这三个部分,首先收集survey论文中的引言部分。如果没有引言部分,我们则提取调查论文摘要部分之后的前1,024 个单词。然后,我们对引言部分的句子进行分类,并将分类为同一类型的句子连接起来,形成目标摘要中的三个部分。过滤掉输入序列或目标摘要太短的示例。
3.BigSurvey-Abs数据集—简洁总结(短总结):
BigSurvey-Abs. survey论文的摘要是其正文的简短总结。BigSurvey- Abs将这些survey论文的摘要作为目标总结,旨在为survey论文的正文生成更简洁的总结。
考虑到 GPU 内存的限制,将前 1,024 个单词作为不使用稀疏注意力的tansformer模型的输入,将前 3,072 个单词作为使用稀疏注意力的tansformer的模型的输入。
2.2.Method
1.介绍本文提出的方法:
提出了 “基于类别对齐和稀疏transformer”(CAST)的解决方案,用于总结一个研究课题的众多学术论文。CAST 包含三个主要部分:基于BERT的带上下文句子分类(SCC)模型、句子分类(SSC)模型和基于transformer的抽象摘要模型。
2.基于BERT的SCC模型:
结构化总结的每个部分通常侧重于输入文档内容的一个特定方面。为了准备每个总结部分的内容,对survey论文中提取的引言部分的句子进行分类,并将同一类型的句子进行合并。
本文设计了 “上下文句子分类法”(SCC)的方法来对这些句子进行分类:
- 给定一个句子及其前后的句子,根据预训练模型(BERT或 RoBERTa )将它们连接起来,作为句子分类模型的输入。
- 使用 CSABST 数据集中的标注句子训练 SCC 模型,其中每个句子都被标注为 5 个类别之一:背景、目标、方法、结果和其他。
3.类别对齐方法(CA):
使用基于类别对齐(CA)的方法,将每个总结部分与归类为同一类型的输入句子进行对齐。对齐后的输入文本和目标总结构成了模型训练的示例。CA 可视为基于句子分类的内容选择操作,支持摘要模型关注输入文档的特定方面。
考虑到结构化总结的不同部分可以用不同的方式编写,本文训练了多个模型,在目标总结中产生单独的部分。BigSurvey MDS中每个示例的输入文本通常包含多个方面的内容,这些文本来自数十篇参考论文的摘要。对于关注特定方面的总结部分,输入内容的其他方面可以被视为噪声。使用相同的输入生成不同的总结要部分可以使生成的部分混合不同方面的内容。
4.句子分类SSC模型:
对参考文献摘要中的句子进行分类可定义为句子分类(SSC)问题。在 CSABST的数据集上训练基于 BERT 的 SSC 模型:
首先使用 SSC 模型对每篇参考文献摘要中的句子进行分类,然后将分类为同一类型的句子合并。SSC模型在摘要句分类方面可以优于SCC模型。考虑到 BigSurvey-MDS 中的目标总结通常比 CSABST 中的样本要长得多,以及 BERT 模型的最大长度限制,使用在 CSABST中训练的 SSC 模型对目标总结的句子进行分类并不合适。因此,我们使用 SSC 模型对输入句子进行分类,并使用 SCC 模型对目标总结中的句子进行分类。
5.基于transformer的抽象总结生成:
原始transformer不能处理长输入序列。一些transformer模型的变体采用稀疏关注机制来降低复杂性。例如,BigBird 和 Longformer。本文的 CAST 模型有两个版本,CAST-BigBird 采用 BigBird作为编码器,而 CAST-LED 的编码器来自 Longformer。
2.3.实验设置
- 使用 0.1 的 dropout。优化器为 Adam, β 1 \beta_{1} β1=0.9, β 2 \beta_{2} β2=0.999。总结模型使用的学习率为 5e^{-5} ,分类器使用的学习率为 2 e − 5 ,分类器使用的学习率为 2e^{-5} ,分类器使用的学习率为2e−5。采用了学习率预热和衰减。
- 在解码过程中,我们使用波束搜索,波束大小为 5。使用三格阻塞来减少重复。
- 采用 HuggingFace’s Transformers中的 PEGASUS、BigBird 和 LED 实现。BART 的实现来自 fairseq。
2.4.结果
- BigBird-PEGASUS 和 LED 的表现优于其他不使用稀疏关注的基于transformer的模型,这表明引入较长的输入文本有利于提高生成摘要的质量。
- 生成的摘要部分往往混合了多个方面的内容,并且在不同的部分有重叠的内容。这表明这些摘要模型虽然有目标摘要的监督,但在内容选择方面仍然存在困难。
- 在 BigSurvey-MDS 上,CAST-LED 将 CA 与带有稀疏关注机制的transformer模型相结合,其性能优于其他基线模型。
- 对较长的输入文本进行建模对 BigSurvey-Abs 中survy论文的摘要也很重要。
- 增加输入序列长度也不能取代 CA。较长的输入会引入更多的噪声,而如果没有 CA,摘要模型仍然难以选择特定方面的突出内容。
3.原文阅读
Abstract
就一个研究课题撰写调查论文时,通常需要涵盖众多相关论文中的突出内容,这可以模拟为一项多文档摘要(MDS)任务。现有的多文档摘要数据集通常侧重于生成涵盖少数输入文档的无结构摘要。同时,以往的结构化摘要生成工作侧重于将单篇文档总结为多节摘要。这些现有的数据集和方法无法满足将大量学术论文总结为结构化摘要的要求。为了解决可用数据稀缺的问题,我们提出了 BigSurvey,这是第一个用于生成每个主题的大量学术论文综合摘要的大规模数据集。我们收集了七千多篇调查论文的目标摘要,并将其中 43 万篇参考文献的摘要作为输入文档。为了组织数十篇输入文档中的不同内容,并确保长文本序列的处理效率,我们提出了一种名为基于类别的对齐和稀疏变换器(CAST)的摘要方法。实验结果表明,我们的 CAST 方法优于各种先进的摘要方法。
1 Introduction
介绍多文档摘要的背景:
已发表的学术论文数量一直在快速增长。这给研究人员阅读他们感兴趣的研究课题的大量论文带来了困难。研究课题的论文摘要可以帮助研究人员快速浏览这些论文中的关键信息。作为一种人工撰写的摘要,调查论文可以对每个研究课题的众多论文进行综述,并指导人们学习该课题。但撰写调查论文需要耗费大量时间和精力,很难涵盖最新论文和所有研究课题。多文档摘要(MDS)技术可用于自动生成摘要,作为人工撰写摘要的补充。为了以较低的成本覆盖最新的论文和更多的研究课题,人们可以灵活地调整输入论文,让摘要方法为这些论文生成摘要。我们的目标是为同一研究主题的众多论文生成全面、有序、非冗余的摘要。要实现这一目标,需要解决一些具有挑战性的问题,包括可用数据的稀缺性、不同来源内容的组织以及摘要模型处理长文本的效率。
介绍本文的工作,即多论文摘要的大规模数据集:
虽然已有一些 MDS 数据集,但它们大多侧重于生成短小且无结构的摘要,覆盖的输入文档少于十篇,无法满足对一个研究课题的大量论文进行综述的实际需求。为了解决可用数据稀缺的问题,我们提出了 BigSurvey,这是第一个用于众多学术论文摘要的大规模数据集。它包含七千多篇调查论文及其 43.4 万份参考文献摘要。考虑到版权问题,我们收集了这些参考文献摘要作为 MDS 的输入文档。这些摘要可视为其作者撰写的摘要,其中包含这些参考文献的突出信息。
介绍结构化摘要:
这些输入摘要通常包含多个方面的内容,包括背景、方法、目标和结果。摘要要组织和呈现来自数十份输入文件的各种内容,具有很大的挑战性。与无结构摘要相比,有结构摘要包含多个部分,概括了输入内容的特定方面,更易于阅读,也更受读者欢迎。为了兼顾全面性和简洁性,我们建立了 BigSurvey 的两个子集,用于生成两级摘要。BigSurvey-MDS 侧重于生成全面的摘要,而 BigSurvey-Abs 则是为生成 BigSurvey-MDS 中这些摘要的更简洁摘要而构建的。
引出本文的结构化摘要假设:
对于同一主题的多篇论文的结构化摘要,我们有两个假设。1) 研究课题在某一方面的描述是相关论文在这一方面内容的子集(例如,研究课题的背景应该是所有相关论文背景的一部分)。2) 结构化摘要的每个部分都更侧重于 1) 中提到的子集中的突出内容(例如,摘要的背景部分侧重于所有参考文献背景中的突出内容)。基于这些假设,我们提出了基于类别的对齐(CA)方法,将结构化摘要的每个部分与被归类为同一类型的输入句子集进行对齐。
介绍本文提出的稀疏transformer:
如表 1 所示,在 BigSurvey 数据集的每个实例中,输入文档的平均字数总和接近 1.2 万。更长的输入会带来更多的噪音,突出内容也会更加分散,这就增加了捕捉和编码突出内容的难度。由于现有神经模型的时间或空间复杂度通常与输入序列长度高度相关,因此长输入序列也会降低摘要模型的效率。为解决上述问题,我们提出了一种名为基于类别对齐和稀疏transformer(CAST)的方法。如图 2 所示,我们使用基于 BERT 的序列句子分类法(SSC)和带上下文的句子分类法(SCC)对输入和输出句子进行分类。然后,我们使用基于类别的对齐方法,对归类为同一类型的输入句子集和目标输出句子集进行对齐,并组成用于训练摘要模型的示例。我们采用带有稀疏注意力机制的transformer进行抽象总结。稀疏注意力支持编码器在 GPU 内存有限的情况下对较长的输入序列进行建模。我们的 BigSurvey 数据集和 CAST 方法可以对预先训练的大模型进行微调,从而在现成的 GPU 上生成涵盖数十个输入文档的结构化摘要。
我们以 BigSurvey 数据集为基准,对先进的抽取式和抽象式摘要方法进行了基准测试。为了比较它们的性能,我们进行了自动评估和人工评估。实验结果表明,我们提出的 CAST 方法优于这些基线模型,而且添加基于类别的对齐可以为各种摘要方法带来额外的性能提升。
我们的贡献体现在三个方面:
- 我们建立了 BigSurvey,这是第一个用于众多学术论文摘要的大规模数据集。
- 我们提出了一种名为 "基于类别的对齐和稀疏transformer(CAST)"的方法,用于归纳每个研究课题的大量学术论文。
- 我们在数据集上对各种摘要方法进行了基准测试,发现添加基于类别对齐可以为各种方法带来额外的性能提升。
2 Related Work
近年来,一些大规模的 MDS 数据集 [19, 14, 15] 已经发布,这使得为 MDS 训练大型神经模型成为可能。其中一些数据集与我们的工作相关。Multi-XScience [14] 是一个科学论文摘要数据集。它的目标摘要是科学论文相关工作部分的各个段落。每个摘要的输入文档平均少于 5 篇。另一个数据集 WikiSum [14] 的目标是生成维基百科文章的第一部分。由于这些文章大多只有少量参考文献,因此它们用更多的搜索结果来补充输入。与这些现有的 MDS 数据集不同,我们的 BigSurvey 数据集用于生成全面的摘要,涵盖每个研究课题的大量学术论文。
关于结构化摘要的制作,已有许多单篇文档摘要(SDS)作品。Gidiotis 和 Tsoumakas [2019] 建立了 PMC-SA 数据集,其中的目标摘要是包含多个部分(如引言、方法、结果和讨论)的论文结构化摘要。为了组成输入和输出对,他们通过章节标题匹配正文章节和摘要章节。Meng 等人[2021]也将输入文档的章节与目标摘要的章节对齐。这些 SDS 作品可以利用输入文档和目标摘要的明确格式(如章节划分)来确定输入和输出之间的重新对齐关系。对于多文档摘要,输入文档可以从不同来源(期刊或会议)收集,并遵循不同的格式。我们收集的参考文献摘要通常没有章节,因此无法在数据集上使用章节级对齐。寻找输入和输出内容之间的对齐关系成为了一项挑战。
3 BigSurvey Dataset
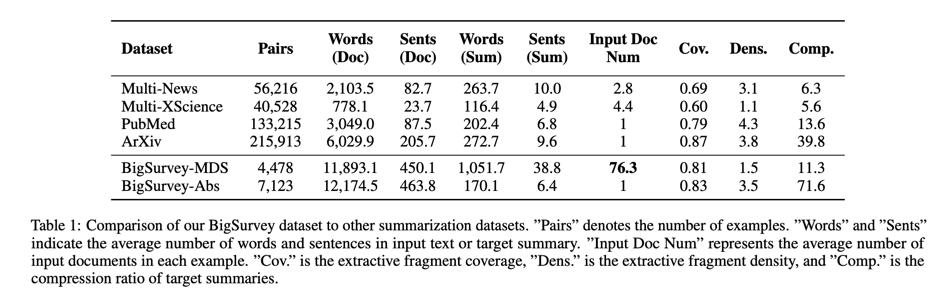
在本节中,我们首先介绍我们的数据来源以及数据收集和预处理程序。然后,介绍我们的 BigSurvey 数据集。我们还对数据集进行了描述性统计和深入分析,并与其他常用的文档摘要数据集进行了比较。
3.1.Data Collection and Pre-processing
介绍数据的收集与预处理:
我们从 arXiv上收集了七千多篇调查论文,按其 dois 下载 PDF 文件,并用名为 science-parse的工具对这些文件进行解析。我们可以从解析结果中提取书目信息(如参考文献的标题和作者)。根据这些调查论文的书目信息,我们从微软学术服务(MAS)[21] 和语义学者(Semantic Scholar)中收集其参考文献的摘要。我们总共收集了超过 43.4 万篇参考文献。
在预处理阶段,我们首先要过滤掉收集数据中的无效样本。具体来说,我们会删除重复或无法正确解析的下载文件(例如,某些 PDF 文件是扫描文件或不完整文件)。我们还过滤掉survey论文中解析文本过短或收集的参考文献极少的异常值。对于每篇被选中的survey论文,我们都会去除噪音(例如,第一节前的版权信息和用于撰写文体的特殊符号),提取这些survey论文的摘要和引言部分,并截断其参考文献的摘要。我们将这些文本小写,并使用 NLTK来分割句子和单词。之后,我们将训练集(80%)、验证集(10%)和测试集(10%)分开。
3.2.Dataset Description
收集的数据集的描述:
BigSurvey 是一个大型数据集,包含数十篇同一主题学术论文的两级目标摘要。长摘要旨在全面涵盖参考文献在不同方面的突出内容,而短摘要则更为简洁,可视为长摘要的总结。针对这两级摘要,我们建立了两个子集:BigSurvey-MDS 和 BigSurvey-Abs。它们的统计信息如表 1 所示。我们将分别介绍它们的定义和属性。
BigSurvey-MDS—结构化摘要:
BigSurvey-MDS. 这个子集的重点是制作涵盖一个研究课题的大量学术论文的综合摘要。BigSurvey-MDS 中的每个示例都与 arXiv中的一篇survey论文相对应。这些survey论文通常有数十篇或数百篇参考文献。考虑到版权问题,BigSurvey-MDS不包含这些参考文献的正文部分,而是使用其摘要作为输入文件。这些摘要可视为其作者撰写的摘要,其中包括这些论文的主要信息。对于每篇survey论文,我们最多收集 200 份参考文献摘要,并将每份摘要截短至不超过 200 字。这些经过截短的摘要被用作 BigSurvey-MDS 的输入文档。
BigSurvey-MDS—目标摘要的构造:
survey论文的引言部分通常介绍研究课题的背景、方法和其他方面的内容。我们将survey论文引言的内容分为三个部分(背景、方法和其他),并将它们作为 BigSurvey-MDS 每个示例的目标来编写结构化摘要。有关目标、结果和其他的内容被合并到名为其他的部分,因为我们观察到这些类型的内容在survey论文的引言部分出现的频率低于背景和方法。为了编写目标摘要中的这三个部分,我们首先收集survey论文中的引言部分。如果没有引言部分,我们则提取调查论文摘要部分之后的前1,024 个单词。然后,我们对引言部分的句子进行分类,并将分类为同一类型的句子连接起来,形成目标摘要中的三个部分。我们会过滤掉输入序列或目标摘要太短的示例。如表 1 所示,BigSurvey-MDS 的平均输入长度、平均输出长度和平均输入文档数都远远大于以前的 MDS 数据集。
介绍BigSurvey-Abs数据集—简洁摘要:
BigSurvey-Abs. survey论文的正文可以看作是对其参考文献的全面而冗长的总结。同时,survey论文的摘要是其正文的简短摘要。名为 BigSurvey- Abs 的子集将这些survey论文的摘要作为目标摘要,旨在为这些survey论文的正文生成更简洁的摘要。考虑到 GPU 内存的限制,我们在实验中对这些survey论文进行了截断。具体来说,我们按照[Zhang and others, 2020; Zaheer et al., 2020]中的设置,将前 1,024 个单词作为不使用稀疏注意力的tansformer模型的输入,将前 3,072 个单词作为使用稀疏注意力的tansformer的模型的输入。在这种情况下,BigSurvey-Abs 的输入文档与 BigSurvey-MDS 中的目标摘要高度重合。因此,BigSurvey-Abs 中的短摘要可视为 BigSurvey-MDS 中长摘要的摘要。此外,输入和输出的平均长度与以前的学术文献摘要数据集相似。以前的文本摘要方法应该能够适应 BigSurvey-Abs 数据集。
3.3.Diversity Analysis of Dataset
数据集分析:
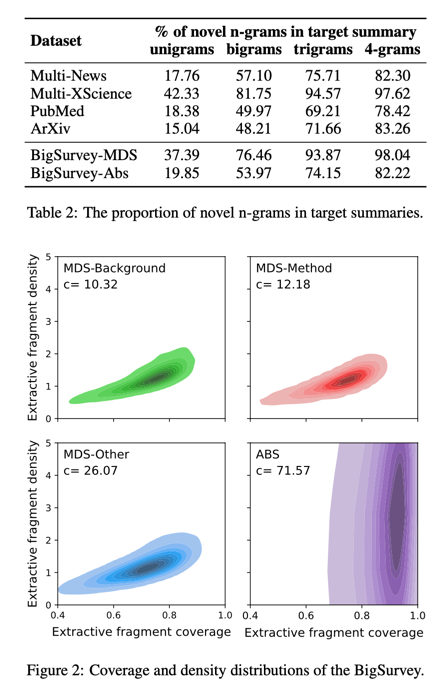
为了衡量目标摘要的抽象程度,我们报告了目标摘要中未出现在输入文档中的新颖 n-gram 的百分比。表 2 显示,BigSurvey-MDS 子集的抽象性与 Multi-XScience 类似。BigSurvey-Abs 子集的抽象性低于 BigSurvey-MDS 和 Multi-XScience,与其他现有数据集相似。
此外,我们还使用 Grusky 等人[2018]定义的三种测量方法来评估 BigSurvey 子集的提取性,包括提取片段覆盖率、提取片段密度和压缩率。提取片段覆盖率衡量的是摘要中属于输入文档提取片段的单词百分比。提取片段密度评估目标摘要中每个词所属提取片段的平均长度。压缩率是输入文档与其目标摘要之间的词数比。使用核密度估计可以直观地看到这三个测量结果。图 2 显示,BigSurvey-MDS 子集中的三个摘要部分的覆盖率和密度分布相似。它们的密度较低,覆盖率的变化范围相对较大。BigSurvey-Abs 子集中沿 y 轴(提取片段密度)的变化很大,这表明目标摘要的写作风格各不相同。
4 Method
介绍本文提出的方法:
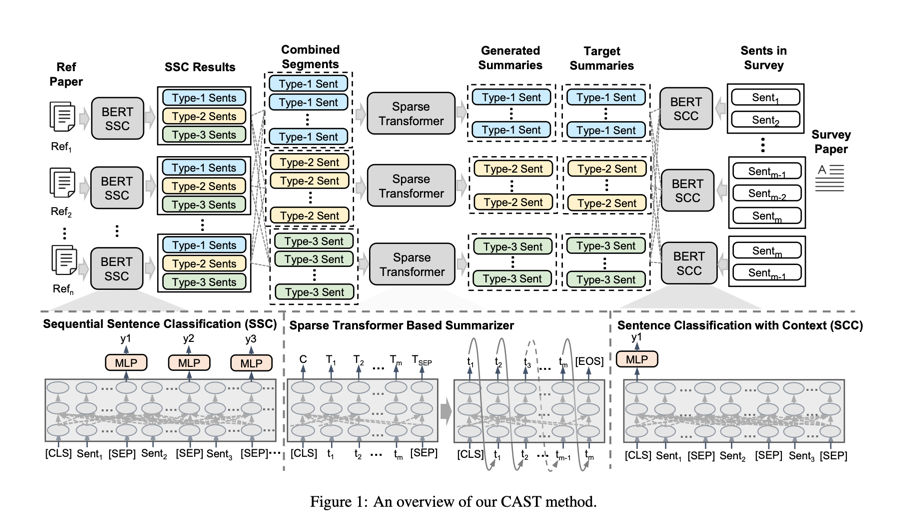
在本文中,我们提出了一种名为 “基于类别对齐和稀疏transformer”(CAST)的解决方案,用于总结一个研究课题的众多学术论文。CAST 包含三个主要部分:基于 BERT 的带上下文句子分类(SCC)模型、顺序句子分类(SSC)模型和基于transformer的抽象摘要模型。
结构化摘要的每个部分通常侧重于输入文档内容的一个特定方面。为了准备每个摘要部分的内容,我们会对survey论文中提取的引言部分的句子进行分类,并合并归类为同一类型的句子。我们设计了一种名为 “上下文句子分类法”(SCC)的方法来对这些句子进行分类。给定一个句子及其前后的句子,我们根据预训练好的模型(如 BERT [13] 或 RoBERTa [15])将它们连接起来,作为句子分类模型的输入。我们使用 CSABST 数据集[10]中的标注句子来训练 SCC 模型,其中每个句子都被标注为 5 个类别之一:背景、目标、方法、结果和其他。
为了解决上述问题,我们使用基于类别的对齐(CA)方法,将每个摘要部分与归类为同一类型的输入句子进行对齐。对齐后的输入文本和目标摘要构成了模型训练的示例。CA 可视为基于句子分类的内容选择操作,支持摘要模型关注输入文档的特定方面。
考虑到结构化摘要的不同部分可以用不同的方式编写,我们训练了多个模型,在目标摘要中产生单独的部分。为了准备模型训练的输入和输出对,将所有摘要部分与相同的输入(一对多)对齐是很简单的。BigSurvey MDS中每个示例的输入文本通常包含多个方面的内容,这些文本来自数十篇参考论文的摘要。对于关注特定方面的摘要部分,输入内容的其他方面可以被视为噪声。使用相同的输入生成不同的摘要部分可以使生成的部分混合不同方面的内容。
对参考文献摘要中的句子进行分类可定义为顺序句子分类(SSC)问题。我们按照文献 [14] 中的设置,在名为 CSABST [15] 的数据集上训练基于 BERT 的 SSC 模型。我们首先使用 SSC 模型对每篇参考文献摘要中的句子进行分类,然后合并被分类为相同类型的句子。评估结果表明,在摘要句子分类方面,SSC 模型优于 SCC 模型。考虑到 BigSurvey-MDS 中的目标摘要通常比 CSABST 中的样本要长得多,以及 BERT 模型的最大长度限制,使用在 CSABST 中训练的 SSC 模型对目标摘要的句子进行分类并不合适。因此,我们使用 SSC 模型对输入句子进行分类,并使用 SCC 模型对目标摘要中的句子进行分类。
原始transformer模型的编码器采用的是自注意机制,与输入序列中的标记数呈二次scaling关系。对于长输入序列来说,这种方法的成本过高[15],而且无法利用有限的计算资源对大型预训练模型进行微调。一些transformer模型的变体采用稀疏关注机制来降低复杂性。例如,BigBird [17] 和 Longformer [1] 结合了三种不同类型的注意机制,并随序列长度线性扩展。考虑到 GPU 内存的限制,我们的 CAST 模型采用预训练好的编码器和稀疏注意力来编码较长的输入文本。我们的 CAST 模型有两个版本,CAST-BigBird 采用 BigBird [17] 作为编码器,而 CAST-LED 的编码器来自 Longformer [1]。
5 Experiments
5.1.Baselines
在实验中,我们在 BigSurvey 数据集上比较了各种抽取式和抽象式摘要模型。
LexRank 和 TextRank. 两种无监督提取式摘要器建立在基于图的排序方法之上 [1, 2]。
CopyTransformer. 在转换器模型中添加复制机制 [13],用于抽象总结。
BART 建立了一个序列到序列去噪自编码器,该编码器经过预先训练,可以从损坏的文本中重建原始输入文本。
**PEGASUS.**以间隙句生成(GSG)和屏蔽语言模型(MLM)为目标,对基于转换器的模型进行预训练。
BigBird-PEGASUS. 将 BigBird 编码器与 PEGASUS 模型的解码器相结合。
**Longformer-Encoder-Decoder(LED)**建立在 BART 的基础上,在编码器部分采用了局部和全局注意机制,而其解码器部分仍利用原有的自注意机制。
我们在 BigSurvey 的训练集上对这些预训练摘要器的大型模型进行了微调。
5.2.Experimental Setting
这些抽象概括模型的最大词汇量设置为 50,265 个,而基于 BERT 的分类器默认使用 30,522 个。我们使用概率为 0.1 的 dropout。优化器为 Adam, β 1 \beta_{1} β1=0.9, β 2 \beta_{2} β2=0.999。总结模型使用的学习率为 5e^{-5} ,而分类器使用的学习率为 2 e − 5 ,而分类器使用的学习率为 2e^{-5} ,而分类器使用的学习率为2e−5。我们还采用了学习率预热和衰减。在解码过程中,我们使用波束搜索,波束大小为 5。使用三格阻塞来减少重复。我们采用 HuggingFace’s Transformers中的 PEGASUS、BigBird 和 LED 实现。BART 的实现来自 fairseq。所有模型均在一台 NVIDIA RTX8000 上进行训练。
5.3.Results and Discussion
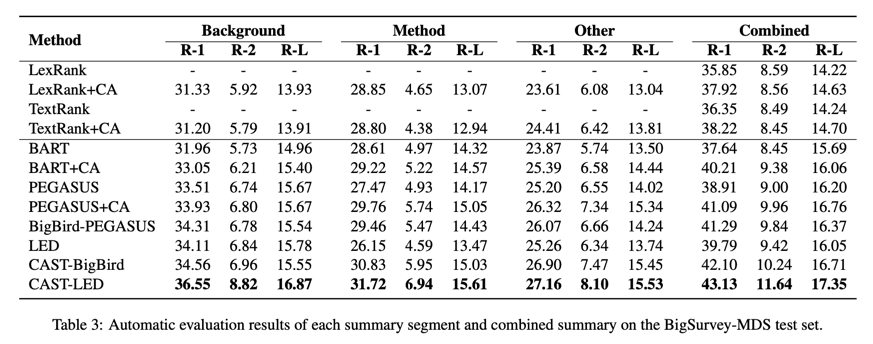
在实验中,我们在 BigSurvey-MDS 和 BigSurvey-Abs 上训练和评估了各种摘要模型。我们将 BigSurvey-MDS 分成三个子集,训练三个模型,分别生成目标摘要中的不同部分。在本节中,我们将报告和分析实验结果。
为了比较这些模型生成的摘要的质量,我们进行了自动评估,并报告了 ROUGE F 1 \mathrm{F}_{1} F1 分数[11],包括单字词(R-1)、大词(R-2)和最长公共子序列(R-L)的重叠度。我们在表 3 中报告了为 BigSurvey-MDS 生成的三个摘要部分和合并摘要的 ROUGE 分数。这表明这些抽象摘要模型在 BigSurvey-MDS 上的表现优于这些提取模型。用稀疏关注机制取代编码器的自注机制,可以让我们在 GPU 内存有限的情况下,在较长的输入文本上训练基于transformer的模型。BigBird-PEGASUS 和 LED 的表现优于其他不使用稀疏关注的基于transformer的模型,这表明引入较长的输入文本有利于提高生成摘要的质量。
输入的参考文献摘要通常包含多个方面的内容。这就要求摘要方法具有很强的内容选择能力,以产生精确覆盖指定方面的摘要部分。我们比较了不同对齐方式(一对多对齐或基于类别的对齐)对各种摘要模型的影响。在使用一对多对齐方式时,我们发现生成的摘要部分往往混合了多个方面的内容,并且在不同的部分有重叠的内容。这表明这些摘要模型虽然有目标摘要的监督,但在内容选择方面仍然存在困难。表 3 显示,引入 CA 可以为各种摘要模型带来额外的性能提升。这反映了 CA 的有效性和增强摘要模型内容选择能力的必要性。在 BigSurvey-MDS 上,CAST-LED 将 CA 与带有稀疏关注机制的transformer模型相结合,其性能优于其他基线模型。
表 4 显示了 BigSurvey-Abs 的评估结果。这些基于转换器的抽象摘要模型与稀疏关注机制的表现也优于其他基线模型。这表明,对较长的输入文本进行建模对 BigSurvey-Abs 中调查论文的摘要也很重要。此外,预训练的序列到序列模型优于从头开始训练的模型。
除自动评估外,我们还进行了人工评估,从信息量(输入文档内容的覆盖率)、流畅性(内容组织和语法正确性)和非冗余性(较少重复)方面比较了两种摘要模型生成的摘要。我们从 BigSurvey-MDS 的测试集中随机抽取了 50 个样本。需要四名注释者对匿名提交的两个模型生成的摘要进行比较。我们还通过 Fleiss’ kappa [14]来评估他们的一致性。表 5 中的人工评估结果表明,我们的 CAST-LED 方法在信息量和非冗余性方面优于原始 LED 模型。
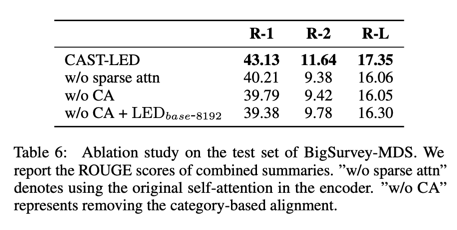
我们还进行了消减研究,以验证我们方法中各个组成部分的有效性。表 6 显示,在编码器部分使用原始的自我注意来替代稀疏注意机制,或者取消基于类别的配准,都会导致性能下降。此外,增加输入序列长度也不能取代 CA。较长的输入会引入更多的噪声,而如果没有 CA,摘要模型仍然难以选择特定方面的突出内容。结果验证了稀疏关注机制和 CA 的有效性。

6 Conclusion
本文介绍了BigSurvey,这是第一个用于众多学术论文摘要的大规模数据集。BigSurvey建立在人工撰写的调查论文及其参考论文的基础上。BigSurvey包括两个子集,用于生成两级摘要。此外,我们提出了一种名为基于类别的对齐和稀疏变换(CAST)的方法来生成涵盖数十篇研究主题论文的结构化摘要。数据集分析和实验结果揭示了采用基于类别的对齐和稀疏注意力机制的重要性。在观察生成的摘要时,我们发现这些摘要模型仍然缺乏批判性和推理能力,它们生成的摘要还不能与人类编写的摘要相媲美。


















 612
612

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









