







A Systematic Survey of Text Summarization: From Statistical Methods to Large Language Models
文本摘要的系统综述:从统计方法到大型语言模型
paper: https://arxiv.org/abs/2406.11289
文章目录~
- 原文阅读
- Abstract
- 1.Introduction
- 2. Background
- 3. Summarization Methods Prior to LLMs
- 4. Llm-Based Summarization Research
- 5. Open Problems and Future Directions
- 6 CONCLUSION
原文阅读
Abstract
随着深度神经网络、预训练语言模型 (PLM) 和最近的大型语言模型 (LLM) 的出现,文本摘要研究经历了几次重大转变。因此,本综述通过这些范式转变的视角,全面回顾了文本摘要的研究进展和演变。它分为两个主要部分:(1)详细概述 LLM 时代之前的数据集、评估指标和摘要方法,涵盖传统统计方法、深度学习方法和 PLM 微调技术;(2)首次详细研究 LLM 时代基准测试、建模和评估摘要的最新进展。通过综合现有文献并提出一个有凝聚力的概述,本综述还讨论了研究趋势、未解决的挑战,并提出了摘要方面的有希望的研究方向,旨在指导研究人员了解摘要研究的不断发展。
1.Introduction
文本摘要是自然语言处理 (NLP) 中最关键、最具挑战性的任务之一。它被定义为从一个或多个来源提炼出最重要的信息,为特定用户和任务生成精简版本的过程。自互联网出现以来,随着网上文本信息量的激增,摘要研究引起了广泛关注。
构建自动文本摘要 (ATS) 系统的早期努力可以追溯到 20 世纪 50 年代。随后,随着 20 世纪 90 年代和 21 世纪初统计机器学习的进步,无监督的基于特征的系统应运而生。在 2010 年代,摘要研究的重点转向以监督方式训练深度学习框架,利用大规模训练数据的可用性。最近,BERT 和 T5 等自监督预训练语言模型 (PLM) 的出现,通过“预训练,然后微调”的流程显著提高了摘要性能。这一进程最终导致了当前大型语言模型 (LLM) 主导的时代。回顾摘要方法的发展历史,我们通常可以根据底层范式将其分为四个阶段:统计阶段、深度学习阶段、预训练语言模型微调阶段和当前的大型语言模型阶段,如图 1 所示。
最近,LLM 的出现彻底改变了学术界的 NLP 研究和工业产品,因为它们具有理解、分析和生成具有大量预训练知识的文本的卓越能力。通过利用大量文本数据,LLM 可以捕捉复杂的语言模式、语义关系和上下文线索,从而能够生成可与人类编写的摘要相媲美的高质量摘要。毫无疑问,LLM 已经将摘要领域推向了一个新时代。
与此同时,许多 NLP 研究人员正在经历由 LLM 系统惊人成功引发的生存危机。文本摘要无疑是受影响最严重的领域之一,研究人员认为摘要(几乎)已消亡。**在我们对摘要领域的理解发生如此颠覆性的变化之后,我们还能做什么?**LLM 的格局不断发展,其特点是不断发展更大、更强大的模型,这为摘要领域的研究人员和从业者带来了机遇和挑战。
这篇综述论文旨在全面概述 LLM 新时代最先进的摘要研究工作。我们首先对现有方法进行分类,并讨论问题的表述、评估指标和常用数据集。接下来,我们系统地分析 LLM 时代之前的代表性文本摘要方法,包括传统统计方法、深度学习方法和 PLM 微调技术。此外,我们综合了 LLM 时代最近的摘要文献的见解,讨论了研究趋势和未解决的挑战,并提出了摘要方面的有希望的研究方向。本调查旨在加深对利用 LLM 进行文本摘要的进步、挑战和未来前景的了解,最终促进 NLP 研究的持续发展和完善。

1.1.Major Differences
已经进行了多项调查来研究摘要的各个方面。然而,现有的调查主要集中在研究传统的统计方法和基于深度学习的摘要方法。缺乏全面的最新调查研究和缺乏共识继续阻碍进展。随着预训练语言模型和最近的大型语言模型引发的重大范式转变,仍然缺乏全面涵盖新时代摘要领域持续进步的深入调查。
例如,早期的调查论文 [54, 151] 对基于统计和深度学习的自动文本摘要模型进行了全面的调查,讨论了它们的详细分类和应用。随后,Cajueiro 等人对 ATS 的方法、数据、评估和编码进行了全面的文献综述,直至预训练语言模型的出现。
研究人员还制作了具有更具体重点的调查。调查论文重点关注学术文章和商业报告等长文档的数据集、方法和评估指标。另一项工作 [181] 侧重于基于图神经网络 (GNN) 的自动文本摘要方法。曹 [17] 对神经抽象摘要方法进行了调查,并探讨了抽象摘要系统的事实一致性。
考虑到摘要方法的快速发展和 LLM 带来的颠覆性变化,我们认为有必要回顾 LLM 时代之前和期间的代表性方法的细节,分析每种方法的独特性,并讨论开放的挑战和未来方向,以促进该领域的进一步发展。
1.2.Main Contributions

本调查报告的主要贡献在于从范式转变的角度研究文本摘要方法,并回顾 LLM 时代的最新研究成果。本调查报告的详细贡献包括
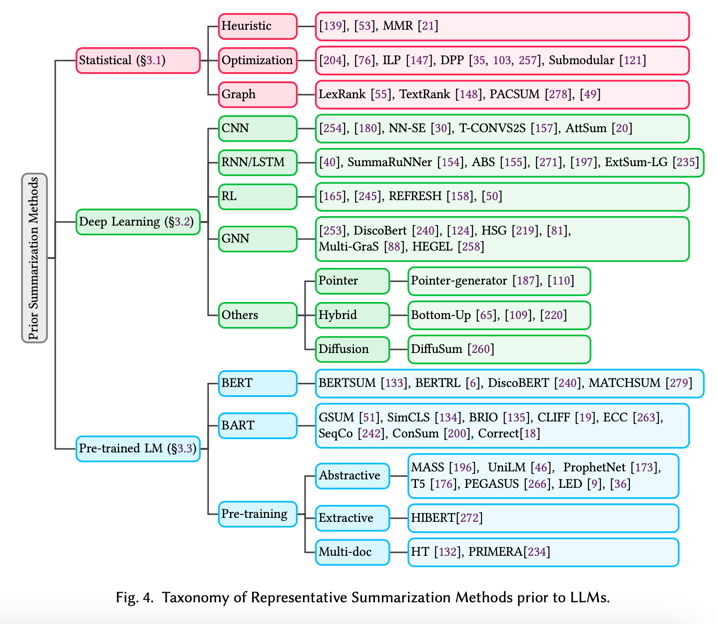
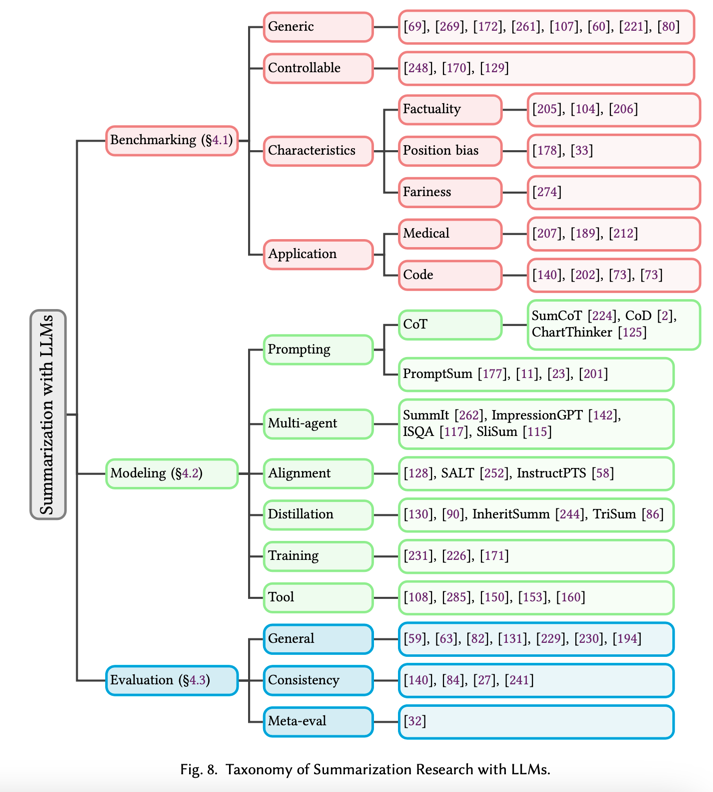
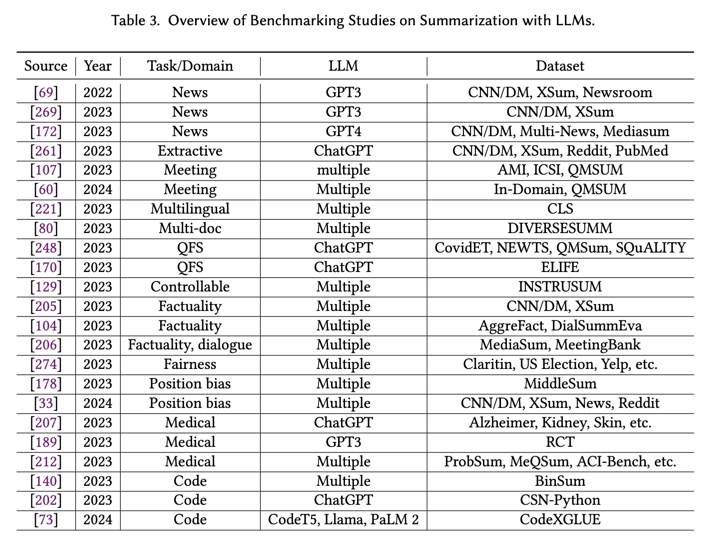
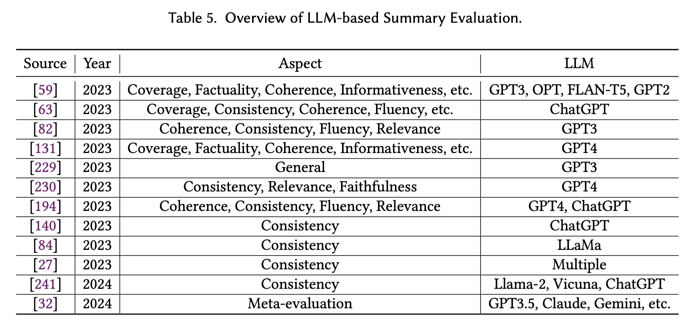
- 本调查报告是对新时代 LLM 文本摘要任务的首次全面研究。我们在图 8 中根据目标和方法首次提出了基于 LLM 的摘要文献分类法。表 3、表 4 和表 5 还列出了研究工作的必要详细信息,包括基准研究、建模研究和基于 LLM 的摘要评估研究。
- 从传统统计模型到深度学习模型,再到 PLM 微调方法。这些作品的分类如图 4 所示,详细信息如表 2 所示。
- 此外,我们还讨论了摘要方法的分类,在表1中总结了带URL链接的文本摘要常用数据集,回顾了流行的摘要评价指标,并在表6中介绍了CNN/DM数据集的量化结果比较。
- 最后,我们分析了摘要研究的基本趋势,讨论了该领域中尚未解决的挑战,并勾勒出新时代 LLM 的前瞻性研究方向,以促进进一步发展。
1.3.Organization
本综述的组织结构如下:第 2 节介绍文本摘要的背景,包括方法分类、问题表述、评估指标和常用数据集。第 3 节回顾了 LLM 时代之前的主要摘要方法,包括统计方法、基于深度学习的方法和 PLM 微调方法。第 4 节探讨了 LLM 摘要基准测试(§4.1)、开发基于 LLM 的摘要系统(§4.2)以及使用 LLM 评估摘要(§4.3)方面的最新进展。最后,第 5 节讨论了摘要方面的未解决问题和未来研究方向。
2. Background


本节提供文本摘要的基本背景信息。首先,我们在图 2 中概述了文本摘要任务的一般分类,并讨论了提取和抽象摘要的典型问题表述。此外,我们回顾了在 LLM 出现之前用于评估摘要性能的常见评估指标。最后,我们概述了广泛使用的摘要基准数据集,如表 1 所示。
2.1.Categorization
文本摘要方法分类:
文本摘要是一项任务,用于为较长的文本文档创建简短、准确且流畅的摘要。它广泛应用于新闻聚合、文档摘要、社交媒体分析等各个领域。它的主要目标是帮助用户快速掌握文档或内容的要点,而无需通读整个文本。然而,文本摘要面临着诸多挑战,例如保持连贯性和保留重要细节、处理各种类型的内容以及确保摘要准确而简洁。
如图 2 所示,根据输入文档的格式、摘要输出的样式和底层范式,文本摘要方法可分为不同的类型。
2.1.1. Input: Single-document vs. Multi-document vs. Query-focused
根据输入不同分类:单文档/多文档/聚焦查询
常见的文本摘要方法可根据输入源文档的格式分为单文档摘要 (SDS)、多文档摘要 (MDS) 和以查询为中心的摘要 (QFS):
- SDS 摘要一篇文章,
- 而 MDS 则以一组文档(通常为同一主题)作为输入。
- QFS 旨在生成专门针对输入查询(例如主题、关键字或实体)的摘要。
- 此外,一些摘要任务涉及多语言输入(例如从中文翻译成英文)和多模态输入(例如结合文本和图像)。
2.1.2. Output: Extractive vs. Abstractive vs. Hybrid

根据输出不同分类:抽取/生成/混合:
根据输出摘要的生成方式,文本摘要方法还分为提取式、抽象式和混合式。如图 3 中的示例所示:
- 提取式方法通过从原始文档中提取句子来创建摘要:
- 抽象式方法逐字生成具有新内容的摘要。
- 混合方法结合了提取和抽象技术。
具体而言,提取式摘要系统旨在从原始文档中识别和选择重要的文本跨度和句子来形成摘要。这些摘要本质上是忠实、流畅和准确的,但它们可能存在冗余和不连贯等问题。基于统计和深度学习的摘要系统 大多是提取式的,通常将提取式摘要构建为序列标记和排名问题,以识别最突出的句子。
相比之下,抽象式摘要系统从头开始生成摘要,类似于人类撰写摘要的方式。这些系统可以生成更灵活、更简洁的摘要,但可能会遇到幻觉和不忠实等问题。抽象摘要通常被表述为序列到序列 (seq2seq) 问题,并使用编码器-解码器框架或自回归语言模型。
混合摘要方法试图结合提取和抽象方法的优势,以实现更平衡的结果。这些系统通常首先从源文档中提取关键信息,然后使用提取的信息来指导抽象摘要生成过程。
2.1.3. Backbone Paradigm: Statistical vs. Deep learning vs. PLM fine-tuning vs. LLM
根据backbone不同分类:统计/深度/预训练/大模型:
如前所述,文本摘要的发展可以根据底层范式分为四个主要阶段:统计阶段、深度学习阶段、预训练语言模型微调阶段和当前的大型语言模型阶段。
- 统计阶段采用无监督摘要方法,包括基于启发式的方法、基于优化的方法和基于图的方法。手工制作的特征和基于频率的特征(如词频-逆文档频率 (TF-IDF))是常用的。
- 深度学习阶段的方法依赖于源文档-摘要对形式的领域特定训练数据,以监督方式训练神经网络。词嵌入技术 也很常用。在此阶段,研究人员引入了各种训练语料库来推进摘要的发展。
- PLM 微调阶段:此阶段依赖于大规模、自监督预训练语言模型的进步。来自 Transformer 的双向编码器表示 (BERT) 的引入标志着此阶段的开始,从而显著提高了性能。使用大量文本数据进行预训练使 PLM 具备语言模式和参数知识,这对于文档理解和文本生成非常重要,从而使下游任务受益。此阶段采用“预训练,然后微调”流程,根据任务特定数据对预训练语言模型进行微调,以进一步提高下游任务的性能。
- LLM 阶段:最近,大型语言模型的进步重塑了摘要研究。这些模型强大的理解和指令遵循能力推动了零样本和少样本摘要系统的发展,为这个新兴时代带来了新的机遇。这一阶段的开始以 OpenAI 推出的生成式预训练 Transformer 3 (GPT-3) 为标志,其模型大小为 1750 亿个参数,具有强大的少样本能力。
2.2.Problem Formulation
问题描述:
2.2.1. Extractive Summarization Formulation
抽取式摘要总结公式:
抽取式摘要通过识别并直接从源文档中提取关键句子来生成摘要。在不失一般性的情况下,我们在此介绍单个文档𝐷的抽取式摘要问题公式。
正式地,给定一个包含𝑛个句子的文档,𝐷 = {𝑠𝑑 , 𝑠𝑑 , …, 𝑠𝑑 },抽取式摘要系统旨在通过直接从源文档中提取𝑚个句子来形成包含𝑚(𝑚≪𝑛)个句子的摘要𝑆 = {𝑠 , 𝑠 , …, 𝑠 }。大多数现有方法将抽取式摘要公式化为二元序列标记问题,并为每个句子分配一个{0, 1}标签。这里,标签 1 表示该句子是突出的,将包含在摘要𝑆中,而标签 0 表示该句子不突出,将被忽略。
然而,以句子级二进制标签 (ORACLE) 形式提取的基本事实很少可用,因为大多数现有基准数据集都使用人工编写的摘要作为黄金标准。因此,通常使用贪婪算法来生成次优 ORACLE,该 ORACLE 由多个句子组成,这些句子可以最大化 ROUGE-2 分数 [120] 相对于参考摘要,如 [154] 所述。具体而言,将句子一次一个地逐步添加到摘要中,以便当前选定句子集的 ROUGE 分数相对于整个黄金摘要最大化。此过程持续到没有剩余的候选句子在添加到当前摘要集后能够提高 ROUGE 分数。
2.2.2. Abstractive Summarization Formulation
生成式摘要总结公式:
抽象摘要通常被定义为序列到序列问题,通常使用编码器-解码器神经架构来解决。在此设置中,**编码器将源文档𝐷处理为连续向量表示。随后,解码器使用这些表示以自回归方式逐字生成摘要。**大多数抽象摘要系统采用顺序模型并利用教师强制训练策略。
抽象摘要系统旨在根据相应的源文档𝐷逐字生成摘要𝑆。模型参数𝜃经过训练以最大化输出的条件似然:
a
r
g
max
θ
l
o
g
p
(
s
i
∣
D
;
θ
)
arg\max_{\theta}log p(s^{i}\mid D;\theta)
argθmaxlogp(si∣D;θ)
其中,
s
i
s^{i}
si 表示生成的摘要
S
S
S 中的第 i 个单词。
2.2.3. Hybrid
混合式摘要总结公式:
混合摘要方法通常采用提取然后生成的流程,其中关键信息𝐺首先从源文档中提取,然后用于指导解码过程。正式地,它可以被视为通过在源文档𝑆之外加入附加信号𝐺来增强抽象模型,以指导生成过程:
a
r
g
max
θ
l
o
g
p
(
s
i
∣
D
,
G
;
θ
)
arg\max_{\theta}log p(s^{i}\mid D,G;\theta)
argθmaxlogp(si∣D,G;θ)
常用的指导信号𝐺包括提取的摘要、关键词、关系和从外部来源检索的信息。
2.3.Evaluation Metrics
评价指标:
早期研究主要使用人工评判来评估摘要的质量。由于手动评估生成的摘要既昂贵又不切实际,研究人员转而开发了自动指标。一般来说,摘要的整体质量从四个维度进行评估:连贯性、一致性、流畅性和相关性 [281]。最近,Fabbri 等人[56]对常见的自动评估指标进行了全面的元评估,并结合了众包人工注释。
2.3.1. Similarity-based Summary Evaluation
基于相似性的摘要评价指标:
现有的摘要评估指标主要依赖生成的摘要与参考黄金摘要(人工编写)之间的相似性作为主要标准。
ROUGE F 分数 [120] 长期以来一直是评估摘要模型性能的标准方法。它们测量参考摘要和候选摘要之间的 n-gram 词汇重叠。具体而言,ROUGE-1 和 ROUGE-2 分数分别指单字母和双字母重叠,表示摘要的信息量。ROUGE-L 分数指的是最长的公共序列,表示摘要流畅性。然而,由于 ROUGE 基于精确的 n-gram 匹配,因此它会忽略同义词短语之间的重叠,并惩罚生成新措辞和短语的模型。
研究人员还探索了基于上下文嵌入的相似性指标来评估摘要质量,例如 BERTScore [268]、MoverScore [277] 和 Sentence Mover 的相似性 [39]。这些指标严重依赖于预训练的编码器来矢量化候选和基本事实摘要,可能会引入固有的偏见并导致可解释性低。
另一方面,Belz 和 Gatt [10] 认为这种相似性反映了“人性”,可能与生成任务的最终表现无关。BartScore [256] 随后将生成文本的评估概念化为文本生成问题。它认为,当生成的文本更好时,经过训练以将生成的文本转换为参考输出或源文本/从参考输出或源文本转换的模型将获得更高的分数。同时,研究人员也在探索无参考的自动评估指标,例如 SummaQA [186]、BLANC [213] 和 SUPERT [64]。
2.3.2. Factual Consistency
事实一致性:
生成的摘要的事实一致性对于其实际应用至关重要 [102, 146, 263]。研究人员已经深入研究了基于文本蕴涵或问答 (QA) 自动评估摘要忠实度的指标。
基于文本蕴涵的方法通过根据原始文档验证摘要来评估事实不一致性。FactCC [102] 是一种基于 BERT 的弱监督模型指标,它使用基于规则的转换应用于源文档句子。DAE [68] 在依赖弧级别分解蕴涵,检查生成的输出和输入中的语义关系。SummaC [105] 将文档分割成句子单元并汇总句子对之间的分数。
另一方面,基于 QA 的指标采用问题生成模型从给定的摘要生成问题,并根据摘要提供足够信息来回答这些问题的程度来评估事实一致性。 FEQA [52] 和 QAGS [218] 通过确定摘要对其相应源文档所提出问题的回答效果来衡量摘要事实一致性。Questeval [185] 统一了基于准确率和召回率的 QA 指标,通过评估摘要可以回答多少生成的问题来衡量摘要事实一致性。
2.3.3. Coherence and Redundancy
连贯性和冗余性:
SNaC [70] 是一个基于细粒度注释的叙述连贯性评估框架,专门用于长摘要。Peyrard 等人 [167] 建议使用摘要的唯一 n-gram 比率(即唯一 n-gram 的百分比)来测量摘要的冗余程度。Xiao 和 Carenini [236] 引入了另一个度量来测量摘要冗余度,它是具有长度归一化的多样性度量的倒数,其中多样性定义为文档中 unigram 的熵。
2.4.Summarization Datasets
摘要总结数据集:
近年来,文本摘要的公共数据集的可用性一直是其快速发展的主要推动力。这些数据集在多个维度上各不相同,包括领域、格式、大小以及它们提供的黄金摘要数量。在这里,我们总结了这些数据集的特征,并在表 1 中提供了概述,其中包括标准训练-验证-测试拆分、语言、领域、摘要格式和 URL 链接等详细信息。我们主要关注包含用英语编写的文本摘要的数据集。
2.4.1. Short News Summarization Dataset
短新闻摘要数据集:
CNN/DM [75] 是用于摘要的最广泛使用的数据集。它包含新闻文章和相关亮点,这些摘要由 CNN 和 DailyMail 的记者撰写。原始数据集是为机器理解而创建的,并由 [155] 改编为摘要。
XSum [157] 是一个由 BBC 发布的在线文章中的一句话摘要组成的数据集。然而,有人指出,XSum 数据集中的一些摘要存在低忠实度的问题,并且包含无法从源文档直接推断出的信息 [146]。
NYT [182] 包含来自纽约时报的带有抽象摘要的新闻文章。输入文档通常会在 [272] 之后被截断为 768 个标记。
NEWSROOM [71] 是一个大型数据集,其中包含 1998 年至 2017 年间 38 家主要出版物新闻编辑室的作者和编辑撰写的文章摘要对。
Gigaword [180] 包含从 Gigaword 语料库的新闻文章(七家出版商)中提取的约 400 万个标题文章对。
CCSUM [87] 是一个较新的新闻摘要数据集,包含 130 万篇高质量的近期训练新闻文章,这些文章是从 CommonCrawl 新闻文章中筛选出来的。
2.4.2. Other Domains
其他领域:
WikiHow [100] 是从在线知识库中提取的多样化数据集。每篇文章都包含多个步骤,每个文档的黄金标准摘要是粗体语句的串联。
Reddit [94] 包含来自 TIFU 在线讨论论坛 subreddit 的 120K 条非正式故事帖子。摘要高度抽象和非正式。
SAMSum [67] 包含大约 16,000 个单文档、类似文本消息的对话。这些文档由精通英语的语言学家创建,涵盖了广泛的形式级别和讨论主题。
AESLC [267] 是一个电子邮件域数据集,用于从电子邮件正文自动生成电子邮件主题行。
2.4.3. Long Document Summarization Dataset
长文档摘要数据集:
PubMed 和 arXiv [40] 是来自 arXiv.org 和 PubMed 的两个广泛使用的科学出版物长文档数据集。任务是从正文内容生成论文摘要。
BIGPATENT [193] 包含 130 万项美国专利以及九个专利分类类别下的人工摘要。
BillSum [99] 包含 23000 份美国国会和加利福尼亚州法案以及来自第 103 至 115 届(1993-2018 年)国会会议的人工撰写的参考摘要。
FINDSum [127] 是一个用于长文本和多表摘要的新型大型数据集,基于来自 3,794 家公司的 21,125 份年度报告。
2.4.4. Multi-document Summarization Dataset
多文档摘要数据集:
DUC [163] 概述了文档理解会议 (DUC) 提供的数据集。2005 年至 2007 年的 DUC 数据集包括新闻领域的多文档摘要数据集,每个集群有 10-30 个文档和 3-4 个人工撰写的摘要。
MultiNews [57] 是一个来自 newser.com 网站的大型多文档新闻摘要数据集,其中包含人工撰写的摘要。每个摘要均由编辑专业撰写,数据集涵盖了各种新闻来源。
WikiSum [126] 是一个多文档摘要数据集,其中每个摘要都是一篇维基百科文章,源文档是参考部分中的引文或部分标题的网络搜索结果。
WCEP [66] 是基于维基百科时事门户 (WCEP) 中的新闻事件和 CommonCrawl 新闻数据集中的类似文章构建的。它与现实世界中的多个工业用例高度一致,平均每个集群有 235 篇文章。
Multi-XScience [138] 是一个由科学文章创建的多文档摘要数据集。摘要是相关工作部分的段落,而源文档包括查询和参考论文的摘要。
Yelp [37] 是一个由 Yelp 数据集挑战赛创建的客户评论数据集。任务是总结一家企业的多条评论。
2.4.5. Query-focused Summarization Dataset
QMSum [283] 是一个会议摘要数据集,包含 232 场会议的 1,808 个查询摘要对,涉及多个领域。该数据集还包含每次会议的主要主题以及注释主题和每个查询的相关文本跨度范围。
NewTS [7] 是一个以方面为重点的摘要数据集,源自 CNN/DM 数据集,包含两个针对同一新闻的不同主题的摘要。
TD-QFS [8] 以医学文本为中心,包含 4 个集群中的短关键字查询,每个集群包含 185 个文档。TD-QFS 中的集群表现出较低的主题集中度,具有大量与查询无关的信息。
2.4.6. Others
XL-Sum [74] 是一个全面而多样化的数据集,包含来自 BBC 的 100 万个专业注释的文章摘要对。该数据集涵盖 44 种语言,具有高度抽象性、简洁性和高质量。
3. Summarization Methods Prior to LLMs
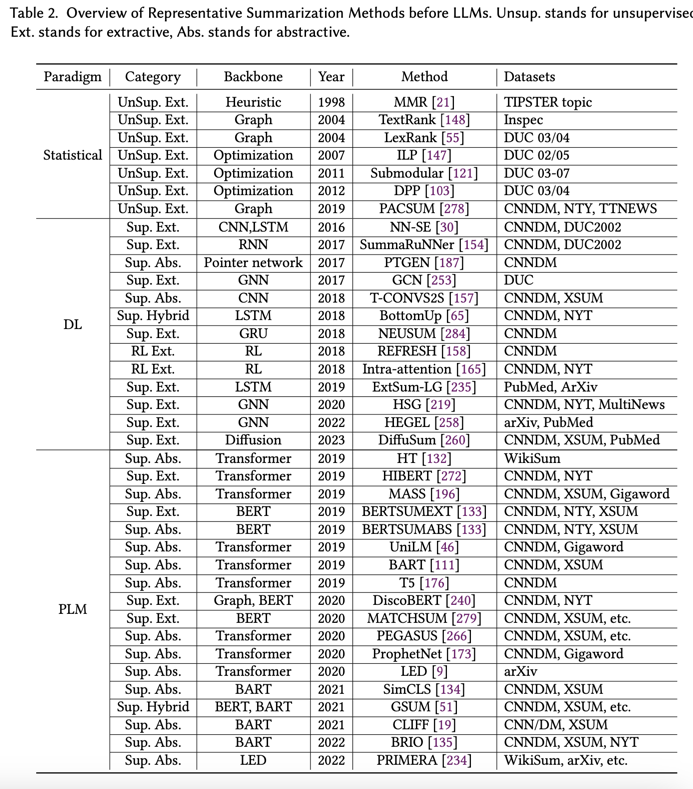
在深入探讨 LLM 最新进展带来的新机遇之前,本节将通过研究代表性摘要方法和算法回顾先前在摘要方面取得的重大进展,如图 4 所示的概述分类法所示。这一全面讨论涵盖了 LLM 之前的三种主要摘要范式:统计方法(§ 3.1)、基于深度学习的方法(§ 3.2)和基于 PLM 的微调方法(§ 3.3)。表 2 总结了这些代表性方法的详细信息,包括方法类别、主干和数据集。
3.1.Statistical Summarization Methods
基于统计的摘要总结方法:
在文本摘要系统的早期阶段,研究主要集中在提取摘要上,并依靠传统的统计方法来自动创建摘要。这些系统大多使用基于频率的特征(例如 TF-IDF)和手工制作的特征 [53] 来对文本数据进行建模。此阶段的代表性方法包括基于启发式的方法、基于优化的方法和基于图的排名方法。
3.1.1. Heuristic-based Methods
1.基于启发式的方法:
最早的摘要方法之一是由 Luhn [139] 提出的。该方法假设可以通过特定内容词(关键词)的频率来衡量句子的重要性。它根据重要性对句子进行评分,然后提取高分句子以生成文献摘要。
Edmundson [53] 后来提出基于手工制作的特征组合对句子进行建模,包括文章中的词频、句子位置、文章标题或章节标题中的单词数量以及提示词(关键词)的频率。然后应用简单的线性求和对句子进行评分和排名。
最大边际相关性(MMR)致力于在选择用于提取摘要的句子时减少冗余,同时保持查询相关性。它采用贪婪方法将句子相关性与信息新颖性结合起来。
3.1.2. Optimization-based Methods
2.基于优化的方法:
摘录摘要中的句子选择问题已被公式化为一个约束优化问题,以获得一组全局最优的句子。选择摘要句子是为了最大限度地覆盖重要的源内容,同时最小化冗余并遵守长度约束。文本摘要已被形式化为各种优化问题,例如最大覆盖率问题 [204] 和树背包问题 [76],并使用包括整数线性规划 (ILP) [147]、行列式点过程 (DPP) [35, 103] 和子模函数 [121] 在内的优化方法来解决。
3.1.3. Graph-based Methods
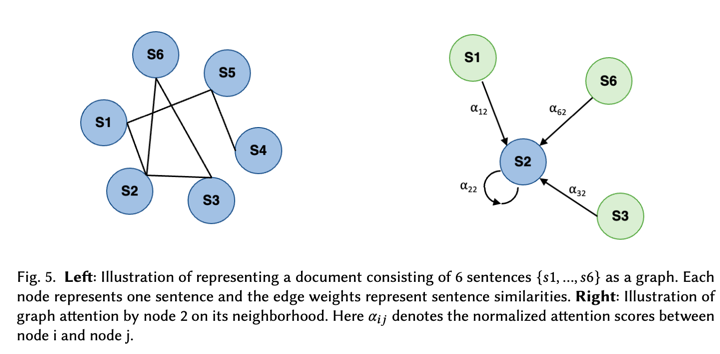
3.基于图的方法:
LexRank [55] 和 TextRank [148] 是两项开创性的工作,它们引入了将文档表示为图形的概念,并将抽取摘要公式化为识别图形中最中心的节点,灵感来自 PageRank 算法 [13]。基本前提是,图中节点的中心性可以作为其在文档中对应句子重要性的近似值。
在图 5 的左侧,我们展示了文档的图形表示。要从文档构建图 𝐺 = (𝑉 , 𝐸),每个节点 𝑣 ∈ 𝑉 表示文档中的一个句子,每条边 𝑒 ∈ 𝐸 表示连接的节点对之间的相似性。在进行图计算之前,会修剪权重低于预定义阈值的边,以避免出现完全连通的图。随后,对边权重进行归一化,并将马尔可夫链迭代应用于图以确定节点中心性。最后,根据句子的中心性对句子进行排名和选择,以将其纳入摘要。
最近,PACSUM [278] 重新审视了 TextRank 算法,并提出构建具有有向边的图。他们认为,文档中节点的相对位置会影响任意两个节点对其中心性的贡献。此外,PACSUM 还集成了神经表征来改进句子相似度计算。
3.2.Deep Learning Summarization Methods
基于深度学习的方法:
深度神经网络的进步和大规模文本语料库的出现显著加速了各种 NLP 任务的进展。词嵌入技术(如 Word2Vec [149] 和 GloVe [166])的发展使得深度学习模型能够将文本数据表示为标记序列,自动从数据中学习连续的句子和文档表示,而无需人工设计特征。NLP 中使用的常见深度学习框架包括卷积神经网络 (CNN)、循环神经网络 (RNN)、长短期记忆 (LSTM) 网络 [77]、强化学习 (RL) 和图神经网络 (GNN)。深度学习阶段的摘要研究仍然主要集中在有监督的提取摘要上。然而,抽象摘要方法开始出现,利用诸如序列到序列 (seq2seq) 模型 [203]、指针网络 [216] 和注意机制等框架。
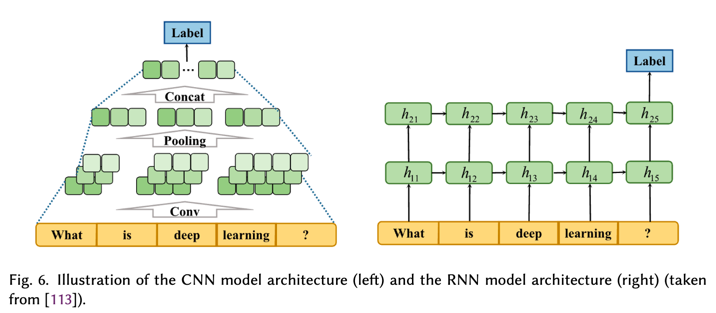
3.2.1.CNN-based Methods
1.基于CNN的方法:
在 CNN 成功应用于文本分类任务中的连续文档表示学习 [95] 之后,Yin 和 Pei [254] 提出了一种基于 CNN 的神经网络语言模型。该模型将句子投影到密集的分布式表示中,并采用多样化的选择过程来提取较少的冗余句子用于摘要。Rush 等人 [180] 使用序列到序列模型结构将CNN应用于抽象摘要。它使用 CNN 对源进行编码,并使用上下文敏感的注意前馈神经网络来生成摘要。
NN-SE [30] 引入了一种分层文档编码器,它将用于学习句子表示的卷积句子编码器与用于学习文档表示的循环文档编码器相结合。此外,NN-SE 还结合了基于注意力机制的神经句子提取器来选择要进行总结的句子或单词。
T-CONVS2S [157] 提出了一种主题感知的卷积序列到序列学习方法,用于极端总结任务。从潜在狄利克雷分配 (LDA) [12] 获得的分布用作附加输入。卷积编码器将每个单词与主题向量相关联,而卷积解码器则根据文档主题向量对每个单词的预测进行条件化。
对于以查询为中心的总结,AttSum [20] 提出了一种联合对查询相关性和句子显着性进行排序的方法。它使用 CNN 自动学习潜在空间内句子和查询的分布式表示。
3.2.2. RNN/LSTM-based Methods
2.基于RNN/LSTM的方法:
SummaRuNNer [154] 是一个基于RNN的代表性提取摘要模型。它采用两层双向 RNN,底层在每个句子的单词级别上运行,顶层在句子上运行。通过对句子表示的加权和生成累积的文档表示,并使用逻辑分类器进行预测。
ABS [155] 首先将注意力编码器-解码器 RNN 应用于抽象摘要,提出使用切换生成器指针机制对罕见或未见过的单词进行建模,并使用分层注意力来捕获文档结构。
对于长文档摘要,Cohan 等人 [40] 提出了一种用于长文档抽象摘要的开创性模型。他们的方法采用分层编码器来捕获文档的话语结构(科学论文部分),并使用注意力话语感知解码器来生成摘要。在此基础上,ExtSum-LG [235] 提出将整个文档的全局上下文与局部上下文结合使用。它应用 LSTM-Minus 方法来捕捉每个句子的局部上下文。
3.2.3. RL-based Methods
3.基于强化学习的方法:
强化学习是训练抽象和提取摘要系统的一种流行替代方法,解决了与负对数似然 (NLL) 训练损失相关的曝光偏差和目标不匹配问题 [61]。
该领域的一项开创性工作是 REFRESH [158],它将 RL 应用于提取摘要,将其概念化为句子排名任务。这项研究引入了一个目标函数,将最大似然交叉熵损失与来自策略梯度强化学习的奖励相结合。Paulus 等人 [165] 通过引入一种具有新颖的内部注意机制的神经网络模型进一步推进了这一方向,该机制分别关注输入和连续生成的输出。他们还提出了一种将标准监督词预测与强化学习相结合的新训练方法。此外,Yadav 等人 [245] 提出了从问题类型识别和问题焦点识别的下游任务中获得的两个新奖励来规范生成模型。
3.2.4. GNN-based Methods
4.基于GNN的方法:
研究人员还探索了将图神经网络 (GNN)用于 NLP,因为它们能够更好地捕获文档的结构信息,并且具有可扩展性和可解释性。GNN 通常使用邻接矩阵和初始节点表示矩阵作为输入,通过空间或谱卷积在图上执行信息聚合。如图 5 右侧所示,图注意网络 (GAT) 是最流行的 GNN 之一,它将注意力机制引入空间卷积以过滤不重要的邻居。这里𝛼𝑖𝑗 表示节点 i 和节点 j 之间的归一化注意力分数。
Yasunaga 等人是将 GNN 应用于提取摘要任务的先驱之一。他们的方法包括将文档建模为近似话语图,并利用图卷积网络 (GCN) 对句子表示进行编码,随后用于预测句子显着性。同样,DiscoBert [240] 引入了一种方法,该方法在由修辞结构理论 (RST) 树和共指提及构建的结构化话语图上使用 GCN。此外,HSG [219] 提出了一种将文档视为异构图的方法,结合了各种粒度级别(单词、句子、文档)的语义节点。该模型构建了单词-文档异构图,并使用单词节点作为句子之间的中介,从而能够更细致地表示文档语义。
研究人员还探索了各种图形变体以增强文档建模。Multi-GraS [88] 引入了多路复用图的利用来捕获多种类型的句子间关系,例如语义相似性和自然连接,同时还建模句子内关系。此外,HEGEL [258] 提出了一种新方法,将文档表示为超图,以捕捉高阶跨句关系而非成对关系。该方法整合了多种类型的句子依赖关系,包括章节结构、潜在主题和关键字共指,从而提供了文档语义的全面视图。
3.2.5. Others
除了上述模型外,我们在此介绍一些具有代表性的个体模型。
See 等人 [187] 引入了指针生成器网络 [216],以缓解 seq2seq 模型对事实细节再现不准确的问题。这种方法使模型既可以使用生成器从词汇表中生成单词,也可以使用指针从源中选择性地复制内容。 Lebanoff 等人 [110] 进一步将模型调整为具有 MMR 的多文档摘要设置。
Bottom-Up [65] 引入了一种数据高效的内容选择器,用于识别源文档中的潜在输出词。该选择器作为指针生成器网络中的自下而上的注意机制集成,代表了一种结合提取和抽象方法的混合方法。后来,Lebanoff 等人 [109] 提出选择句子并将其融合到摘要中。
DiffuSum [260] 提出了一种提取摘要的方法,即使用扩散模型直接生成所需的摘要句子表征,并基于匹配这些表征提取句子。该方法优化了句子编码器,使用匹配损失来对齐句子表征,使用多类对比损失来促进表征多样性。
3.4.Pre-trained Language Model Summarization Methods
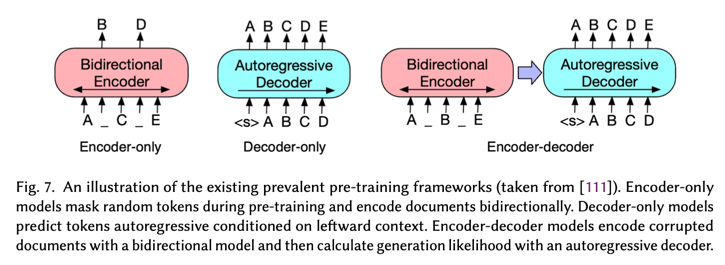
基于预训练模型的方法:
随着基于 Transformer 的架构和强大的大规模自监督预训练的出现,摘要系统在过去几年中经历了性能的大幅飞跃。Transformer 架构中的自注意力机制促进了并行计算并提高了学习效率,从而可以在大规模未标记语料库上进行有效训练。PLM 可以通过这种无监督训练学习通用语言表示,为下游任务提供卓越的模型初始化,并且无需从头开始学习每个新任务。在此阶段,摘要系统通常会调整在大型语料库上以自监督方式训练的 PLM 检查点,然后在特定于领域或任务的训练数据集上对这些 PLM 进行微调。
如图 7 所示,通常使用三种流行的预训练架构:仅编码器、编码器解码器和仅解码器。所有这些架构都采用与 vanilla Transformers 相同的自注意力层来编码单词标记。 Transformer 的双向编码器表示 (BERT) [45] 标志着这一阶段的开始,它是第一个被广泛采用的 PLM,它具有仅编码器的架构 [133],可用于提取和抽象摘要。使用 PLM 的摘要研究越来越多地集中在使用编码器-解码器架构模型(如 T5 [176] 和 BART [111])作为骨干的抽象摘要。OpenAI 引入了具有生成预训练的仅解码器模型 [175]。此外,研究人员还开发了特定于摘要的 PLM,如 PEGASUS [266]、长上下文 PLM,如 LED [9],以及多文档摘要 PLM,如 PRIMERA [234]。
在本讨论中,我们使用 BERT 作为仅编码器 PLM 的代表,使用 BART 作为编码器-解码器模型的代表,以探索它们在第 3.3.1 节和第 3.3.2 节中在文本摘要中的应用。我们还在第 3.3.3 节中研究了从头开始的预训练中的代表性努力。
3.3.1. BERT-based Methods
1.基于BERT的方法:
仅编码器的 PLM(如 BERT)主要用于将自然语言转换为连续的语境化表示(嵌入),然后可以进一步操纵这些表示以用于下游任务。BERT 使用下一句预测 (NSP) 和掩码语言建模 (MLM) 目标在大规模未标记语料库上进行自监督预训练。这种仅编码器的架构使 BERT 非常适合各种预测建模任务,例如文本分类和提取摘要。其他流行的仅编码器 PLM 包括 RoBERTa [136]、DistilBERT [183]、ALBERT [106] 和 Sentence-BERT [179]。
PreSum [133] 是一篇开创性的论文,也是基于 PLM 的摘要最受欢迎的基线模型。它展示了如何将 BERT 有效地应用于文本摘要,并提出了一个用于提取和抽象摘要的综合框架。他们使用多个句子间 Transformer 层进行提取摘要,并引入了一种新颖的微调计划,该计划对编码器和解码器采用了不同的优化器,旨在解决这两个组件之间的不匹配问题。在 PreSum 的基础上,Bae 等人 [6] 进一步使用强化学习技术对其进行了增强,以实现摘要级评分。他们提出使用基于策略的强化学习来桥接提取和重写模型。
DiscoBERT [240] 通过结合专注于结构化话语图的图形编码器,对 BERT 的文档编码器进行了增强。此增强旨在捕获文档中的长距离上下文依赖关系。
MATCHSUM [279] 通过将任务定义为语义文本匹配问题,引入了一种新颖的提取摘要方法。此方法不是单独提取句子,而是将源文档与语义空间中的候选摘要进行匹配。该模型采用 Siamese-BERT 架构,包含两个具有绑定权重的 BERT 模型,以及推理阶段的余弦相似层。
3.3.2. BART-based Methods
2.基于BART的方法:
像 BART 这样的编码器-解码器 PLM 被广泛用于 NLP 任务,这些任务涉及理解输入序列和生成输出序列,因为它们能够捕获这些序列之间的映射。BART 是通过对大规模未标记语料库上的任意噪声函数破坏的文本进行去噪和重建来进行自我监督预训练的。编码器-解码器架构使 BART 非常适合各种序列到序列生成任务,例如机器翻译和抽象摘要。其他流行的编码器-解码器 PLM 包括 MASS [196]、T5 [176]、UL2 [208] 和指令调整版本,例如 Flan-T5 和 Flan-UL2 [38]。
除了直接将 PLM 应用于抽象摘要之外,Aghajanyan 等人[3]提出了植根于信任区域理论的正则化微调方法,以缓解表征坍塌,即在微调阶段预训练模型的通用表征退化。GSUM [51] 引入了一种引导式摘要框架,将外部引导作为额外输入,以提高生成摘要的忠实性和可控性。
此外,一些研究工作还探索了对比学习在微调 BART 中的应用。SimCLS [134] 引入了一个两阶段框架,其中 BART 模型生成候选摘要,而经过微调作为评估模型的 RoBERTa 模型利用对比学习对最佳候选摘要进行评分和选择。SeqCo [242] 和 ConSum [200] 提出利用对比学习来改进 BART 微调,特别是为了缓解曝光偏差。 BRIO [135] 引入了一种新的训练范式,该范式假设非确定性分布,根据不同候选摘要的质量为其分配概率质量。
另一方面,对 BART 模型的调整研究已开始侧重于微调技术,以提高生成的摘要的忠实度。这些技术包括错误校正 [18]、CLIFF [19] 中实现的对比训练、后处理方法 [28]、知识图谱方法 [145, 286]、数据过滤方法 [156],以及 ECC [263] 和 Spancopy [237] 中控制生成的进一步进展。
3.3.3. Pre-training Methods
3.从头开始预训练方法:
除了在特定任务的训练数据上微调预训练语言模型的努力外,研究人员还尝试从头开始预训练具有自监督目标的 Transformer 模型,以更好地与下游任务保持一致。
对于提取摘要,HIBERT [272] 提出了一种用于文档编码的分层 BERT 模型,使用文档掩码和未标记数据的句子预测进行预训练。它利用文档的层次结构来提高提取摘要的质量。
在抽象摘要的预训练语言模型方面的早期努力包括 MASS [196] 中的掩码 seq2seq 预训练、UniLM [46] 中的统一预训练和 ProphetNet [173] 中的 n-gram 预测预训练。PEGASUS [266] 是一种专为摘要设计的流行 PLM。在 PEGASUS 中,重要的句子被从输入文档中删除或屏蔽,并从剩余的句子中一起生成一个输出序列,模仿创建提取摘要的过程。
Longformer-Encoder-Decoder (LED) [9] 是一种专门为处理长文档而设计的 PLM。Longformer 用局部窗口注意力和任务驱动的全局注意力的组合取代了 Transformers 中的标准自注意力机制。这种修改允许模型随序列长度线性扩展,使其能够更有效地处理由数千个标记组成的文档。Cho 等人 [36] 后来通过与分割的联合训练扩展了 LED,Liu 等人 [137] 使用异构图改进了稀疏注意力。
对于多文档摘要,HT [132] 使用分层段落间注意力和文档图表示增强了 vanilla Transformers。 PRIMERA [234] 提出了第一个专门为多文档表示而设计的 PLM,基于 LED 架构。它引入了一个针对多文档设置量身定制的全新间隙句子生成预训练目标,教模型使用实体金字塔掩码跨文档连接和聚合信息。
4. Llm-Based Summarization Research
基于LLM的摘要方法:
最近,GPT-X 等大型语言模型的出现彻底改变了 NLP 的格局,并显著影响了文本摘要的研究方向。目前,大多数摘要研究都采用 LLM 作为骨干模型,利用零样本或少样本设置,而不是以前的微调方法。鉴于 LLM 在生成连贯且上下文相关的文本方面具有强大的能力,研究现在主要集中在抽象摘要上。本节旨在全面概述基于 LLM 的文本摘要的最新研究成果,概述进展并深入了解不断发展的研究趋势。
图 8 概述了基于 LLM 的摘要的当前研究格局。现有的研究工作可以根据研究目标大致分为三类:LLM 基准研究、摘要建模研究和摘要评估研究:
- 基准研究:这些研究侧重于评估 LLM 在各种摘要任务中的表现。它们旨在建立基线和性能指标,以帮助比较不同的模型和方法。基准研究对于理解 LLM 在总结方面的优势和局限性以及指导未来的研究方向至关重要。它们通常涉及跨不同数据集和领域的大量实验和分析,从而提供现有模型的全面性能概况。代表性基准研究在第 4.1 节中介绍,并在表 3 中总结。
- 建模研究:此类别包括致力于利用 LLM 开发新型总结算法和架构的研究。这些研究探索了各种增强总结过程的技术,例如快速工程、多智能体系统、模型对齐和知识提炼。建模研究旨在突破 LLM 在总结方面所能实现的界限,重点是提高生成的总结的质量、连贯性和信息量。他们还研究了不同的架构修改和训练策略如何优化 LLM 在特定总结任务中的性能。代表性建模研究在第 4.2 节中介绍,并在表 4 中进行了总结。
- 评估研究:这些研究关注的是设计新的指标和方法来评估生成的摘要的质量和有效性。与 ROUGE 等传统指标不同,LLM 时代的评估研究侧重于开发更复杂、更人性化的指标。代表性评估研究在第 4.3 节中介绍,并在表 5 中进行了总结。
4.1.Benchmarking Studies
随着功能强大的新型 LLMs 作为骨干模型的出现,许多研究工作现在都旨在对它们的性能进行基准测试,并了解它们在摘要方面的能力。现有研究已经探索了通用和可控摘要的 LLM 基准,检查了忠实度和位置偏差等特征,并研究了它们在医学和代码摘要等专业领域的应用。
4.1.1. Generic Summarization
GPT-3 的出现标志着 LLM 时代的一个关键时刻,展示了推动 NLP 研究范式转变的重大生成能力。其中一项开创性的基准研究 [69] 对 GPT-3 的文本摘要进行了评估,特别是在新闻摘要的经典基准领域。这项研究将 GPT-3 与之前经过微调的模型进行了比较,并通过人工评估发现,即使只提供任务描述,注释者也绝大多数更喜欢 GPT-3 的摘要。然而,这种偏好并没有反映在自动指标中,GPT-3 的摘要在基于参考和无参考的评估中都获得了较低的分数。
张等人的进一步大规模人工评估。[270] 呼应了这些发现,强调了由于低质量参考摘要而导致的局限性。这些限制导致低估了人类的表现,并降低了小样本和微调的有效性。他们的研究强调,LLM 生成的摘要被认为与人类编写的摘要相当,并强调了指令调整在增强 LLM 的零样本摘要能力方面的重要性。同样,人工评估 [172] 也得出了类似的结论,认为 LLM 生成的摘要具有更好的事实一致性和更少的外在幻觉实例。
对于提取摘要,Zhang 等人 [261] 对 ChatGPT 的提取性能与传统微调方法进行了全面评估。他们的研究结果表明,虽然 ChatGPT 在 ROUGE 分数方面的表现不如现有的监督系统,但它在 LLM 特定的评估指标上取得了更高的性能。该研究还探讨了情境学习 (ICL) 的好处,并提出了一种提取然后生成的流程来提高 LLM 生成的摘要的真实度。在这里,ICL 是一种提示工程方法,它允许 LLM 通过使用示例作为提示的一部分来学习新任务而无需进行微调 [47]。
对于会议摘要,Laskar 等人。[107] 进一步对会议摘要的 LLM 进行了评估,讨论了成本效益和计算需求。这项研究为在实际应用中使用 LLM 所涉及的权衡提供了实用的视角,强调了性能和资源需求之间的平衡。此外,Fu 等人。[60] 研究了更小、更紧凑的 LLM 作为其较大同类产品的替代品的可行性。他们发现,大多数较小的 LLM,即使经过微调,在总结任务中也没有超越较大的零样本 LLM。
此外,在多语言环境中对 LLM 的评估 [221] 表明,ChatGPT 和 GPT-4 倾向于生成详细、冗长的摘要,并且可以通过交互式提示在信息量和简洁性之间取得更好的平衡。 Huang 等人 [80] 探索将 LLM 应用于多文档摘要,并指出由于 LLM 的覆盖范围有限,这项任务对于 LLM 来说仍然是一个复杂的挑战。
4.1.2. Controllable/query-focused Summarization
Yang 等人 [248] 对 ChatGPT 在基于查询的摘要上的表现进行了评估,结果表明 ChatGPT 在 ROUGE 分数方面的表现可与传统微调方法相媲美。Liu 等人 [129] 对 LLM 进行了指令可控文本摘要评估,其中模型输入包括源文章和所需摘要特征的自然语言要求。研究发现,指令可控文本摘要对于 LLM 来说仍然是一项具有挑战性的任务,因为生成的摘要中存在持续的事实错误,基于 LLM 的评估方法与人工注释者在评估候选摘要质量时缺乏很强的一致性,以及不同 LLM 之间的性能差异。
此外,Pu 和 Demberg [170] 对 ChatGPT 在使其输出适应不同目标受众(专家与外行)和写作风格(正式与非正式)方面的表现进行了系统检查。他们的发现表明,人类产生的文体变化比 ChatGPT 所展示的要大得多。此外,ChatGPT 在调整文本以适应特定风格时有时会加入事实错误或幻觉。
4.1.3. LLM Summarization Characteristics
最近的基准研究还探讨了 LLM 在生成摘要时的特征,包括生成忠实性、公平性和立场偏见。这些研究旨在了解 LLM 生成的摘要如何准确地反映源内容,以及源文本中信息的位置如何影响生成的摘要。
忠实性和事实性:Tam 等人 [205] 提出了一个事实不一致基准来衡量 LLM 在摘要中的事实性偏好。该基准包括人工验证的事实摘要和带注释的不一致摘要,提供了一种评估模型事实一致性的方法。研究发现,虽然现有的 LLM 通常更喜欢事实一致的摘要,但它们往往无法检测到逐字复制内容时的不一致。
Tang 等人 [206] 介绍了一个以主题为中心的对话摘要评估基准,其中包括事实一致性的人工注释以及详细解释。他们的分析表明,LLM 通常会在对话领域产生大量事实错误,并且作为二元事实评估器表现不佳。
Laban 等人 [104] 得出了类似的结论,发现大多数 LLM 都难以检测出事实不一致,其表现接近随机机会。此外,他们强调,一些现有的竞争性结果是由现有评估基准的问题引起的。总体而言,LLM 在推理事实和检测不一致方面的能力仍然存在差距。
公平性:Zhang 等人 [274] 将摘要公平性定义为不低估任何人群的观点,并发现模型生成的和人工编写的参考摘要都存在较低的公平性。
位置偏见:导语偏见是新闻摘要中的常见现象,文章的早期部分通常包含最突出的信息。Ravaut 等人[178] 对 LLM 的上下文利用和位置偏差进行了全面的研究,结果表明模型倾向于偏向输入的开头和结尾部分,而很大程度上忽略了中间部分,从而导致 U 形性能模式。同样,Chhabra 等人 [33] 通过测量位置偏差来研究零样本抽象摘要,位置偏差指的是模型倾向于不公平地优先考虑输入文本某些部分的信息。他们的研究表明,LLM 在极端摘要任务中表现出明显的领先偏差。
4.1.4. Applications
最近的研究还探索了将 LLM 应用于跨学科领域,例如医疗文档处理和源代码。
医疗文档摘要:Van Veen 等人 [212] 使用 LLM 来总结临床文档,包括放射学报告、患者问题、进度记录和医患对话。他们的临床读者研究发现,最适合的 LLM 的摘要被认为与医学专家的摘要相当或更优秀。然而,这些 LLM 生成的摘要面临着安全挑战,例如幻觉和事实错误,这可能会导致医疗伤害。
相比之下,Tang 等人 [207] 将 LLM 应用于不同临床领域的零样本医学证据摘要。他们表明,LLM 容易生成事实不一致的摘要并做出过于令人信服或不确定的陈述,这可能会导致错误信息。此外,这些模型难以识别显着信息,并且在总结较长的文本时更容易出错。
Shaib 等人[189] 邀请领域专家评估 GPT-3 在单文档和多文档设置中生成的生物医学文章摘要。研究发现,虽然 GPT-3 可以忠实地总结和简化单个生物医学文章,但它很难提供跨多个文档的准确发现汇总。
代码摘要:Ahmed 和 Devanbu [4] 首先研究了使用 GPT Codex 进行少样本训练的应用,并展示了它通过利用特定于项目的训练超越最先进的代码摘要模型的能力。随后,Sun 等人。[202] 评估了 ChatGPT 在广泛使用的 Python 数据集 CSN-Python 上的表现,发现其代码摘要性能在 BLEU 和 ROUGE-L 指标方面与当代模型相比有所欠缺。
此外,Luo 等人。[140] 深入研究了 LLM 在理解二进制代码方面的潜力。他们发现,与 IR 代码、汇编代码和原始字节相比,LLM 在应用于反编译代码时表现出更优异的性能。值得注意的是,他们发现函数名称在塑造反编译代码的语义方面起着重要作用。此外,他们的研究表明,对于大规模任务,零样本提示在性能和成本效率方面都超过了少样本提示和思路链提示。同样,Haldar 和 Hockenmaier [73] 观察到模型在单个实例上的性能通常取决于代码和相应的自然语言描述之间的子词标记重叠,这在函数名称中尤为普遍。
4.2.Modeling Studies
如第 3 节所述,在过去十年中,文本摘要研究取得了重大进展,这主要归功于向深度学习方法和微调预训练语言模型的范式转变。以前的摘要研究大多侧重于开发新的模型、算法、系统或架构,并在标准数据集上验证其有效性,即建模研究。摘要研究的最新进展还引入了使用 LLM 的新建模方法,主要是在零镜头和少镜头设置中。这些研究涵盖多种方法,包括基于提示、基于多代理和基于排列的技术,以提高生成摘要的质量。此外,还提出了基于蒸馏的方法和创新的训练策略,以提高模型效率。此外,在文本摘要任务中,LLM 越来越多地被用作提高系统性能的工具。
4.2.1. Prompting-based Method
PromptSum [177] 提出了一种将提示调整与多任务目标和离散实体提示相结合的方法,用于抽象摘要。这种方法使用软提示生成实体链,然后将其与另一个软提示一起用于摘要生成,从而提高模型效率和可控性。随后,Bhaskar 等人 [11] 研究了用于长篇观点摘要的提示流水线方法,包括通过主题聚类-分块-生成流水线使用提取摘要模型进行分块和预提取的层次化摘要。此外,Chang 等人 [23] 引入了一种提示方法来层次化合并块级摘要并逐步更新正在运行的摘要,重点研究了 LLM 在书籍长度摘要中的应用。Sun 等人 [24] [201] 研究了提示链,它通过一系列三个离散提示执行起草、批评和细化阶段,而不是将这些阶段集成在单个提示中的分步提示。
思路链:思路链 (CoT) 方法在引出 LLM 的推理能力方面表现出巨大潜力,从而提高了生成的摘要的质量 [225]。在此基础上,SumCoT [224] 将 CoT 扩展为一种元素感知的摘要方法,该方法提示 LLM 首先列举重要事实,然后将这些事实整合成一个连贯的摘要,确保最终输出既全面又井井有条。此外,密度链 (CoD) [2] 迭代地将缺失的显着实体合并到最初实体稀疏的摘要中,同时保持固定长度,从而产生更具信息量的摘要,并减少引导偏差。此外,ChartThinker [125] 提出综合基于 CoT 的深度分析和上下文检索策略,旨在提高生成的摘要的逻辑连贯性和准确性。
4.2.2. Multi-agent based Method
最近的研究探索了利用 LLM 构建多智能体系统来提高摘要质量。SummIt [262] 引入了一个基于 ChatGPT 的迭代文本摘要框架,该框架结合了多个 LLM 智能体,例如摘要器和评估器。该系统通过自我评估和反馈过程来细化生成的摘要,并研究了整合知识和主题提取器以提高摘要的忠实度和可控性的好处。同样,ImpressionGPT [142] 设计了一种迭代优化算法来自动评估生成的印象,并制定相应的指令提示以进一步细化模型的输出。这种方法利用 LLM 的上下文学习能力,通过使用特定领域的个性化数据创建动态上下文。
此外,ISQA [117] 提出了迭代事实性细化,以实现信息丰富的科学问答 (ISQA) 反馈。它以详细的方式运行,指示摘要代理强化正面反馈中经过验证的陈述,并纠正负面反馈中强调的不准确之处。SliSum [115] 使用滑动窗口和 LLM 的自洽性。它将源文章划分为重叠窗口,允许 LLM 为每个窗口的内容生成本地摘要,然后使用聚类和多数投票算法将它们聚合起来。
4.2.3. Alignment
摘要技术的最新进展主要集中在利用反馈机制和基于指令的微调来提高生成的摘要的质量和用户一致性 [162]。刘等人 [128] 首先研究了使用来自自然语言中人类注释的信息反馈来提高生成质量和事实一致性。随后,SALT [252] 引入了一种方法,通过模拟人工编辑,在训练循环中整合人工编辑的数据和模型生成的数据。InstructPTS [58] 建议使用 LLM 的指令微调来实现跨不同维度的可控产品标题摘要,利用从并行数据集中自动生成的指令。
4.2.4. Distillation-based Method
尽管 LLM 的总结性能很强,但它们的资源需求限制了它们的广泛使用。此外,使用 LLM 即服务 API 时,尤其是对于敏感数据,还会出现隐私问题。这强调了对更紧凑的本地模型的需求,这些模型仍然可以有效地捕捉总结能力。
刘等人 [130] 建议使用对比学习来训练 BART 或 BRIO 等较小的模型,其中 ChatGPT 等 LLM 充当评估器,以表明哪个生成的总结候选更优越。
TriSum [86] 首先使用 LLM 提取一组方面三重原理和总结,然后使用课程学习策略在这些任务上训练一个较小的本地模型。这里的三重结构将一段自由文本格式化为主题、关系和对象。
此外,InheritSumm [244] 通过使用 GPT-3 模型中的知识提炼进行训练,模拟 GPT 在一般文档上生成的摘要,实现了一个紧凑的摘要模型,该模型具有跨不同设置的各种功能。同样,Jung 等人 [90] 提出了不可能提炼 (Impossible Distillation),利用 GPT-2 等预训练语言模型固有的释义相似性,从这些子空间中识别和提炼出高质量的释义。
4.2.5. Training Strategy
最近的研究还探索了微调 LLM 的训练策略。例如,Xia 等人 [231] 提出了一种使用幻觉多样性感知主动学习来缓解 LLM 输出中的幻觉的方法。这种方法在 LLM 微调的主动学习过程中选择不同的幻觉进行注释。
Whitehouse 等人 [226] 研究了参数高效微调 (PEFT) 与低秩自适应 (LoRA) [79] 在多语言摘要领域的潜力。此外,Pu 和 Demberg [171] 建议将修辞结构理论 (RST) 与 LoRA 相结合,以增强长文档摘要性能。
4.2.6. Others
最近的研究工作还探索了利用 LLM 作为摘要任务工具的创新方法,例如 [108] 中用于 QFS 摘要的数据清理、[285] 中用于对话摘要预训练的数据注释,以及 [150] 中用于微调较小模型的对话伪标签生成。
4.3.Evaluation Studies
准确评估生成的摘要的质量确实是摘要研究的一大挑战。如第 2.3 节所述,研究人员已经探索了基于参考和无参考的自动指标,但与人类判断的相关性仍然有限,无法可靠地评估摘要质量 [56]。随着 LLM 的出现,研究人员也在研究其在摘要质量评估中的应用。
4.3.1. General Summary Evaluation
GPTScore [59] 代表了利用 LLM 作为摘要评估指标的开创性努力。它通过结合任务规范和详细的方面定义来利用 LLM 的新兴能力,这些定义可作为对生成文本进行评分的指令。在此基础上,Gao 等人 [63] 研究了 ChatGPT 进行类似人类摘要评估的能力。他们的研究结果表明,ChatGPT 可以使用各种方法相对流畅地进行注释,包括李克特量表评分、成对比较、金字塔方法和二元事实性评估。
同样,Jain 等人 [82] 建议通过上下文学习将 LLM 用作文本摘要的多维评估器,评估流畅性、连贯性和事实性等方面。G-Eval [131] 是另一个值得注意的基于 LLM 的摘要评估指标,它使用思路链和表格填写范式。 G-Eval 在摘要任务上表现出与人类评估的高 Spearman 相关性,明显优于以前的方法。吴等人 [229] 引入角色扮演者提示机制,从客观和主观角度评估摘要。吴等人 [230] 提出的另一种方法旨在通过提取然后评估的方法降低评估成本。
尽管取得了这些进步,沈等人 [194] 仍在研究 LLM 作为抽象摘要自动评估器的稳定性和可靠性。他们发现,尽管 ChatGPT 和 GPT-4 等模型的表现优于传统的自动指标,但它们还不是人类评估者的可靠替代品。LLM 评估者在不同的候选系统和维度上表现出不一致的评分,难以进行密切的性能比较,并且随着摘要质量的提高,与人类判断的相关性降低。
4.3.2. Factual Consistency Evaluation
Luo 等人 [140] 首先探索了 ChatGPT 在零样本设置下评估事实不一致性的能力。他们发现 ChatGPT 实现了令人满意的性能,但更喜欢词汇相似的候选词和错误推理的实例。Chen 等人 [27] 使用不同的 LLM 和不同的提示技术进一步扩展了设置。
随后,Jia 等人 [84] 提出了一种零样本忠实度评估方法,该方法使用基础语言模型,无需提示或指令调整。Xu 等人 [241] 提出了三种用于事实一致性评估的零样本范式,包括对整个摘要或每个摘要窗口的直接推理,以及通过问题生成和回答进行实体验证。
4.3.3. Others
hang 等人 [23] 提出了一种自动指标 BOOOOKSCORE 来评估图书长度摘要生成中的摘要连贯性。Huang 等人 [80] 探索了在多文档摘要设置下使用基于 LLM 的自动指标。
此外,Chern 等人 [32] 进行了一项元评估,该评估可以通过代理辩论有效、可靠且高效地评估 LLM 作为评估者在不同任务和场景中的表现。
5. Open Problems and Future Directions
本节讨论了最近基于 LLM 的文本摘要的趋势、尚未解决的文本摘要的一般挑战,并指出了未来的潜在研究方向,以吸引从业者的注意力并提高我们在 LLM 新时代对文本摘要的理解和技术。
5.1.Quantitative Results
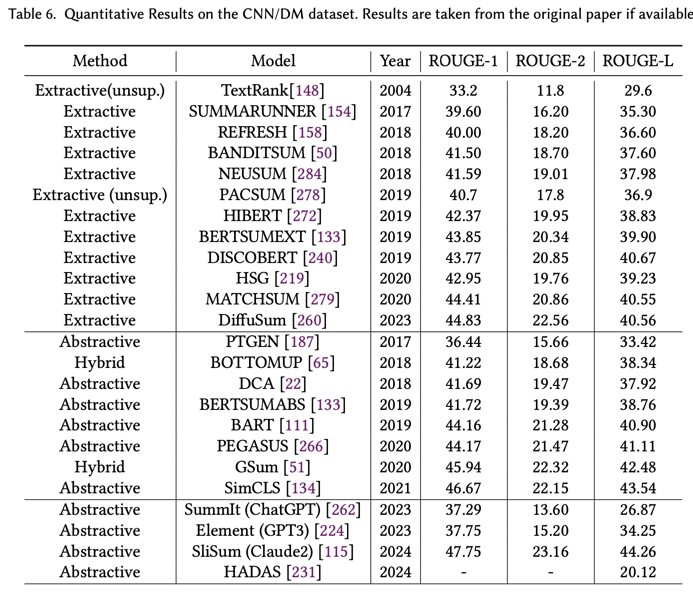
近年来,CNN/DM 数据集 [75] 已被用作评估摘要质量和比较摘要方法有效性的主要基准。在这里,我们还回顾了代表性摘要方法的定量结果(如表 6 所示),以了解研究进展的轨迹。尽管存在第 2.3 节中讨论的局限性,但 ROUGE F 分数仍然是评估摘要质量的标准和最广泛采用的方法,因此我们在表中报告了 ROUGE 分数以进行全面评估。
表 6 中的定量结果显示,近年来摘要系统取得了重大进展,这得益于向深度学习和基于 PLM 的方法的范式转变,这些方法显著提高了 ROUGE 的性能。尽管 CNN/DM 已成为以提取为主的数据集 [282],但与提取方法相比,抽象摘要系统表现出了卓越的灵活性和性能。然而,值得注意的是,ROUGE 评分可能不足以反映摘要质量,特别是在 LLM 的新时代以及参考摘要质量较低的情况下,如 [69, 269] 中所述。因此,最近的研究已将重点转向人工评估,以便在不断发展的语言模型背景下更准确地评估摘要系统的性能。
5.2.Research Trends
基于第 4 节中讨论的现有基于 LLM 的摘要研究的调查和分类,我们总结了现有文献中的一些研究趋势。
基于 LLM 的摘要仍处于起步阶段:尽管已经对基于 LLM 的摘要进行了大量研究,但我们仍处于充分利用 LLM 完成这些任务的早期阶段。大多数现有研究侧重于基准研究,评估 LLM 在各种摘要任务中的表现,并分析这些“黑匣子”工具的行为和特征。这与深度学习和 PLM 微调阶段看到的更先进的建模研究形成了鲜明对比,这些研究提出了更好地利用这些模型构建摘要系统的方法。最近开源 LLM(如 LLaMa [211])的出现促进了这种研究。下一步的重点将是为各种场景开发更有效的基于 LLM 的摘要系统,并提高 LLM 在这些任务中的有效性。
摘要正在拓展视野:虽然深度学习和 PLM 阶段的大多数摘要研究主要集中在新闻和对话等特定领域,但现在人们的注意力正转向探索更广泛的领域和应用,包括跨学科主题。研究人员正在研究如何创建更全面、更通用的系统,为其在金融 [164]、法律 [43, 93]、医疗保健 [89, 222] 等领域的应用开辟新途径 [29]。
人类参与的作用日益增强:人类参与在摘要研究中的作用变得越来越重要。由于自动指标的局限性 [56, 131],研究人员现在严重依赖人工评估来评估摘要输出的质量。人工反馈对于改进模型以更好地满足用户需求至关重要。此外,人们正在探索将人类专业知识与 LLM 功能相结合的混合方法,以提高摘要的质量和可靠性 [198, 228]。人机交互系统(不断使用人类反馈来提高模型性能)正在获得越来越多的关注 [25, 190]。
摘要正在向现实世界的应用过渡:随着范式转向基于 LLM 的摘要,新的研究机会已经出现,使该领域处于显着增长和现实世界应用的边缘 [29]。新闻、法律、医疗保健和教育等各个行业对高效信息处理工具的需求不断增长,推动了用于实际用途的强大摘要系统的开发。
当前的模型(如 GPT-4)在生成连贯且适合上下文的摘要方面表现出令人印象深刻的能力,从而使这些系统能够实际部署 [107]。现实世界的应用开始出现,我们可以期待大量针对特定领域量身定制的基于 LLM 的摘要工具,从而提高生产力和决策过程。
5.3.Open Challenges
尽管近年来文本摘要研究取得了重大进展,但在新的 LLM 时代,文本摘要研究仍面临挑战。
5.3.1. Hallucination:
幻觉是阻碍 LLM 在现实世界中部署的最重要问题之一。它指的是模型生成的信息在事实上不正确或源文本中不存在的情况,包括捏造原始文档中从未提及的事实、事件或细节。这个问题在医学和法律等关键领域尤其严重,因为准确性至关重要。研究人员已经探索了各种方法,通过基准 [123] 来测量和量化幻觉水平,并通过增强训练协议 [83, 273]、检索增强生成 (RAG) [26, 112, 118, 255]、自我反思 [195, 262] 和后处理技术 [24, 28] 来减轻 LLM 生成中的幻觉。然而,要实现忠实和事实的摘要生成,我们还需要付出更多的努力。
5.3.2. Bias:
大型语言模型可以反映和放大其训练数据中存在的偏见,从而导致生成有偏见的摘要 [62, 159, 274]。解决这些道德问题需要开发方法来检测生成过程中的偏见并减轻摘要生成过程中的偏见内容。人们越来越需要能够生成公平、无偏见摘要的模型,特别是在社会敏感领域。
5.3.3. Computational Efficiency:
LLM 的计算效率是影响其性能、可扩展性和实际应用的关键因素。由于参数规模大、训练和推理复杂,这些模型需要大量计算资源。可以通过硬件加速 [249, 250] 和模型剪枝 [143, 199]、量化 [116, 232]、参数高效微调 (PEFT) [44, 79] 和知识提炼 [72, 90, 243] 等技术来提高效率。尽管取得了这些进展,但平衡计算效率与模型准确性和泛化能力仍然是一个具有挑战性且正在进行的研究领域。
5.3.4. Personalization:
根据个人用户偏好创建个性化摘要是另一项重大挑战 [97, 227]。这项任务涉及了解用户的兴趣、阅读习惯和先验知识,以生成与特定用户相关且有用的摘要。它需要 NLP 技术,这些技术不仅可以浓缩信息,还可以使其与用户的独特个人资料保持一致。个性化摘要在教育、新闻和媒体等领域特别有用,它可以使内容适应不同的学习风格,并呈现与读者兴趣相符的信息 [15, 31, 169]。然而,这种个性化必须与隐私考虑相平衡,确保用户数据得到安全和合乎道德的处理。
5.3.5. Interpretability and explainability:
基于 LLM 的摘要的可解释性和可说明性对于建立信任和确保 AI 生成内容的透明度至关重要 [141]。可解释性是指理解模型如何做出决策的能力,而可解释性则涉及阐明特定输出背后的原因。在摘要的背景下,这些方面有助于用户理解为什么突出显示或省略了某些信息 [114, 184]。为摘要输出提供清晰的解释在医疗保健和法律等敏感领域尤为重要,因为理解摘要背后的原因可能会影响决策过程 [29]。尽管取得了进步,但由于 LLM 的复杂性和黑箱性质,实现高水平的可解释性和可说明性仍然具有挑战性。
5.4.Future Directions
在此,我们还强调了 LLM 时代摘要的一些未来发展方向,以拓宽现有摘要系统的范围,从而扩大其应用场景和影响。
5.4.1. Summarization beyond text
在过去的几十年中,文本摘要研究领域取得了重大进展。能够处理各种数据格式的强大 LLM(如 GPT-4 和 GPT-4o [1])的出现催化了多模态摘要的进步。这个新兴领域扩展了传统的文本摘要,包括其他形式的数据,例如图像 [85、152、174、233、288、289]、表格 [127]、源代码 [217、223]、音频 [91] 和视频 [101、122]。多模态摘要系统旨在通过整合各种数据源来提供更全面、上下文更丰富的摘要。这些系统能够生成包含视频中关键视觉元素或播客中重要音频片段的摘要,从而增强用户理解并扩展现实世界的应用。这种整体方法有可能彻底改变信息消费,使其更易于通过各种形式获取和参与,并代表着向人工智能助手发展迈出的重要一步。
5.4.2. New tasks in summarization
传统的摘要研究主要侧重于通用和提取方法。然而,随着强大的 LLM 的出现,文本摘要的前景充满了解决超出传统设置的新任务的希望。新兴研究正朝着针对特定用户场景和实际应用的更细致入微的方向发展。
这些技术包括符合个人偏好、兴趣和阅读历史的个性化和定制化摘要 [31, 280]、支持用户参与和验证的人机交互摘要(适用于法律和医学等高风险领域)[5, 191, 192]、可提高实时事件或突发新闻模型速度和效率的实时摘要 [34, 188, 247, 275]、可反映源材料潜在情绪的情绪感知摘要 [239, 246],以及整合多篇文章信息的多样化摘要 [80] 等等。这些新领域不仅拓宽了摘要任务的范围,而且在提高 LLM 生成的摘要在各个领域和应用的复杂性和实用性方面具有巨大潜力。
5.4.3. Ethical and responsible studies
制定合乎道德的人工智能实践对于摘要的未来至关重要 [62, 119]。这包括创建能够解释其摘要过程的透明模型,确保摘要的公平性,不低估任何人群的观点,并积极努力减轻偏见 [78, 274]。此外,还迫切需要从认知科学、社会科学、心理学和语言学的角度为模型生成提供更多的理论基础和伦理考量。有效、安全地将最新的世界知识和常识纳入摘要生成周期,这对确保摘要准确、最新和事实正确也很重要 [28]。道德考量对于建立信任和确保负责任地使用摘要技术至关重要。
5.4.4. Domain Specific Summarization LLM
得益于使用网络数据进行大规模预训练,当前的 LLM 在不同领域和主题中表现出非凡的泛化能力。然而,由于缺乏特定领域的知识、规则、模式和术语,这种泛化能力可能会限制它们在零样本设置下在特定领域的实际应用。因此,对基于特定领域 LLM 的摘要系统的需求日益增长,并且对于实际部署必不可少 [41, 92, 210, 238]。有效且高效地将开源 LLM 适应特定领域的应用是构建值得信赖的专家摘要系统的一个重要方向。
6 CONCLUSION
总之,文本摘要研究领域见证了深度神经网络、PLM 和最近出现的 LLM 带来的深刻进步。本调查详细记录了文本摘要范式的演变,对 LLM 之前和 LLM 时代进行了全面的考察。此外,调查还强调了研究趋势并描述了尚未解决的挑战,提出了对推进摘要技术至关重要的未来研究方向。通过这种全面的综合,本调查旨在为研究人员和爱好者提供宝贵的资源,促进不断发展的文本摘要领域的明智探索和创新。


















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









