






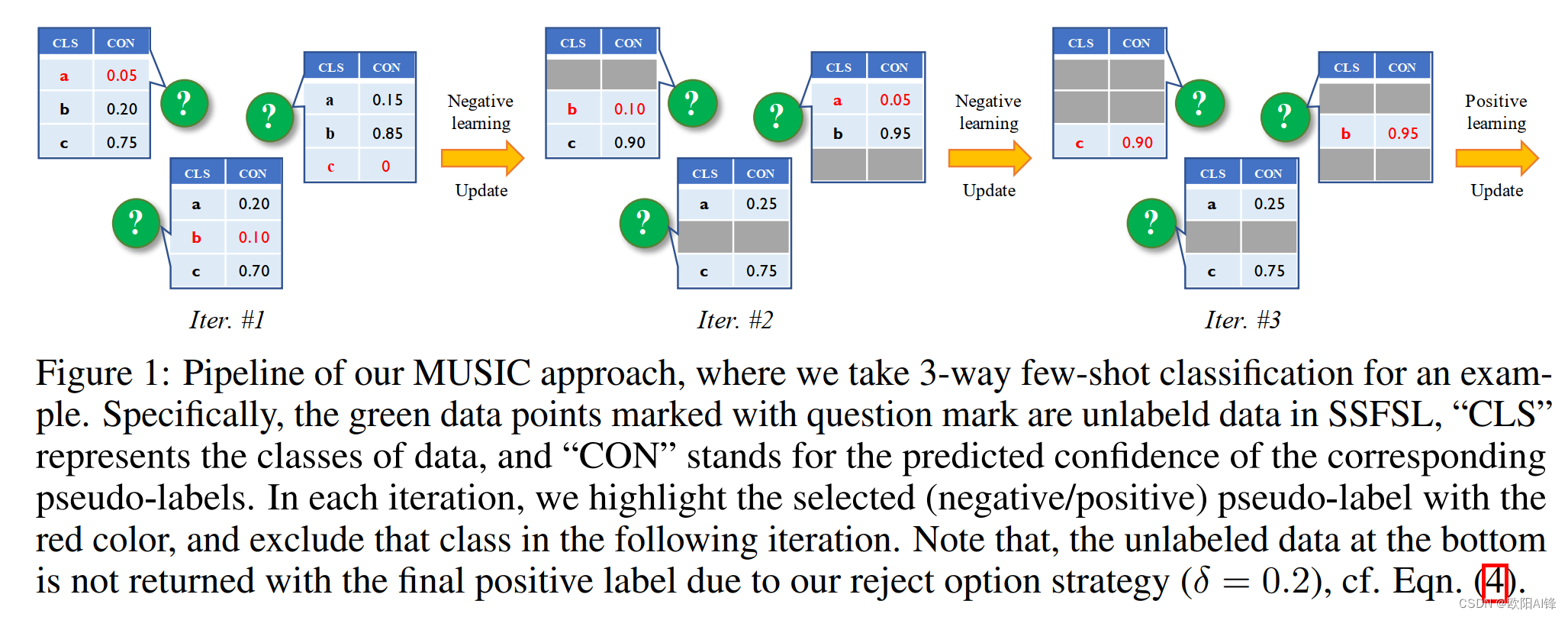
半监督少镜头学习包括训练分类器以适应新的具有有限的标记数据和固定数量的未标记数据的任务。许多的已经开发出复杂的方法来解决这个问题的挑战包括。在本文中,我们提出了一种简单但相当有效的方法来
从间接学习预测未标记数据的精确负伪标签透视图,然后在少镜头分类任务中增强极度标签约束的支持集。我们的方法只需几行代码就可以实现仅通过使用现成的操作,它就能够超越最先进的技术方法在四个基准数据集上。















12-25
 1470
1470
1470
04-14
3469
3469
02-07
2711
2711
07-19
1211
1211
07-20
971
971

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









