







Transformer最开始是为解决NLP问题提出的,ViT直接将图像展成patch化图像的二维结构为一维序列放进transformer进行训练也取得了不错的效果,但是由于图片信息不同于语言信息,其中包含很多冗余信息,本文就是通过端到端的学习来去掉图片中的冗余操作,达到精简注意力的目标。
论文在这:DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification
代码在这:DynamicViT code
由于ViT将图片展成互相之间没有重复的patch,这样很自然能够去掉冗余信息,实现非结构采样,下图是结构采样和非结构采样的对比:
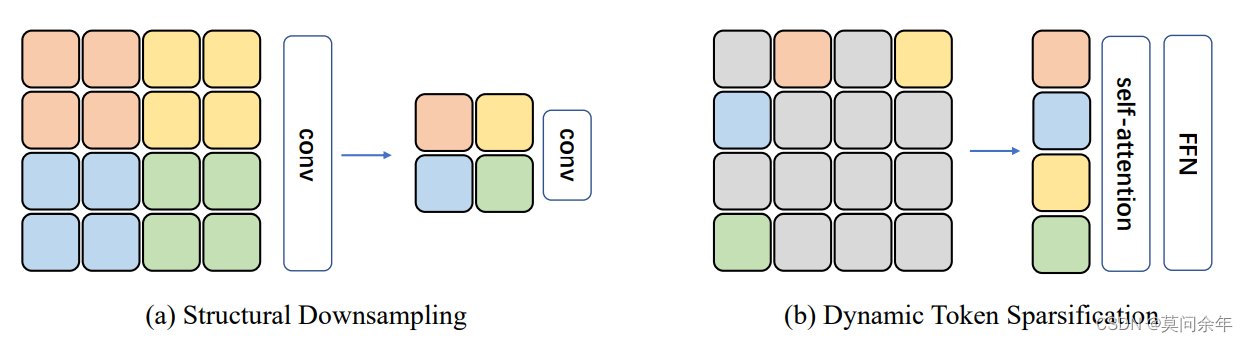
非结构采样可以更有效的让神经网络关注图片中对下游任务更有帮助的patch,从而减少计算量。
总体架构如下:
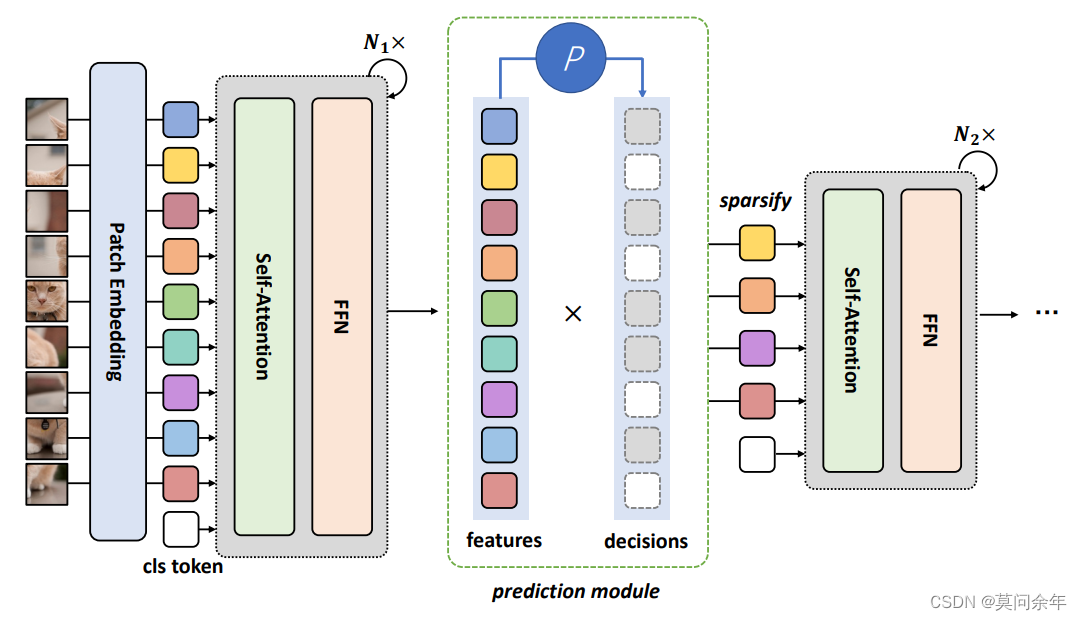 其实就是在FNN层之后接了一个类似下采样的网络,根据掩码来计算保留下patch之间的注意力,可以类比为CNN的下采样操作。
其实就是在FNN层之后接了一个类似下采样的网络,根据掩码来计算保留下patch之间的注意力,可以类比为CNN的下采样操作。
然后是一系列公式:
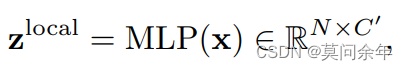
这里的x就是FFN之后的特征,N为patch数目,C为输入特征的维度,= C/2。

其中:
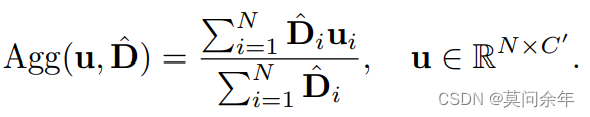
是二进制掩码。
在得到局部和全局特征之后开始端到端进行保留token筛选:

根据所得结果更新掩码:
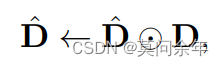
以上涉及一个问题,就是得到的采样概率在前向传播时没问题,但是采样过后反向传播时无法计算梯度,作者采用Gumbel-Softmax进行采样,是的采样过程可微,可以进行端到端的学习,关于Gumbel-Softmax可以参考漫谈重参数:从正态分布到Gumbel Softmax,这里不做赘述。
公式如下:
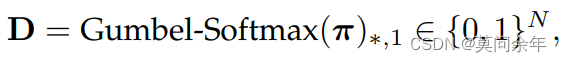
解决了梯度的问题,还涉及到如何处理保留patch和丢弃patch,单纯的将丢弃patch特征置0显然无法解决问题,因为根据注意力公式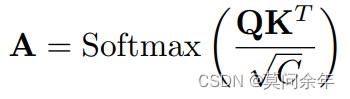 它们还会对保留token产生影响,这里作者采取了注意力掩码机制,仅保留下的patch可以互相影响:
它们还会对保留token产生影响,这里作者采取了注意力掩码机制,仅保留下的patch可以互相影响:
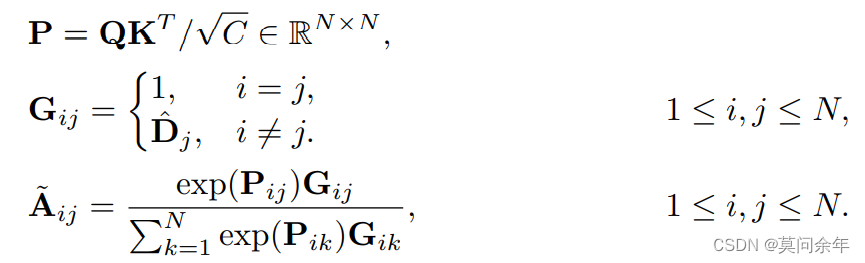
作者为了减少剔除冗余patch对模型的影响,使用原模型作为教师模型进行蒸馏学习,总体损失函数如下:
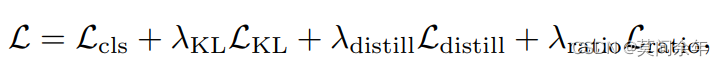 其中分类损失:
其中分类损失:
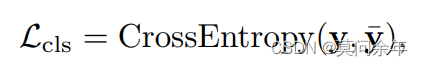
KL散度(使分类结果同教师模型相近):

蒸馏损失(使保留patch特征同教师模型输出的特征相近):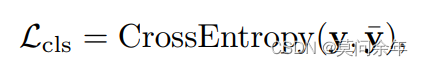
MSE损失: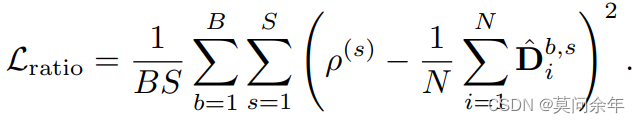
其中B代表batchsize,S代表stage。
最后附上ImageNet的实验结果:
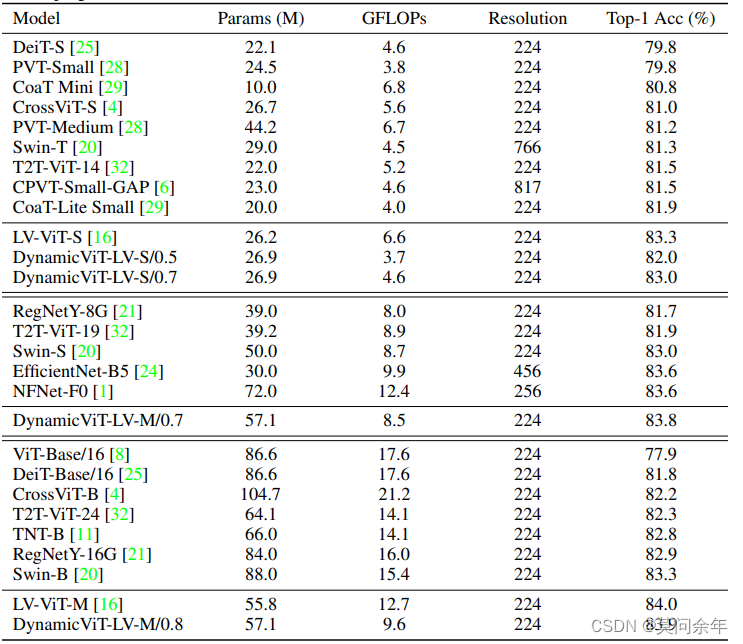
通过最后一组对照,可以看出DynamicViT在同参数的情况下,减少了32%的FLOPs但是精度仅下降了0.1%。
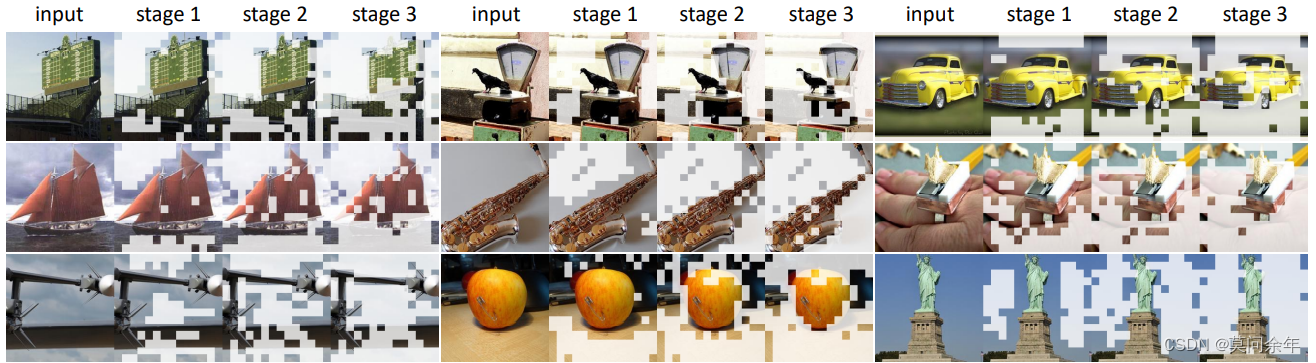
部分输入可视化:
 前一段时间作者又更新了该方法,使得这种动态采样技术可以在窗口类型的ViT和CNN上都可以适用,附链接:Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
前一段时间作者又更新了该方法,使得这种动态采样技术可以在窗口类型的ViT和CNN上都可以适用,附链接:Dynamic Spatial Sparsification for Efficient Vision Transformers and Convolutional Neural Networks
以上。















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









