







numpy ndarray是一个普通的n维array。它不知道任何关于深度学习或者梯度(gradient)的知识,也不知道计算图(computation graph),只是一种用来计算数学运算的数据结构。
一、神经网络结构图:
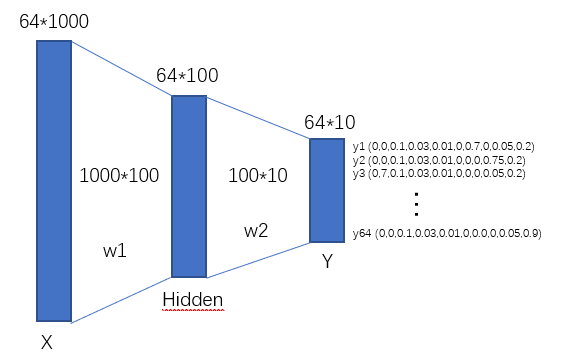
二、神经网络的构建:
(1)一个输入向量,一个隐藏层,一个全连接ReLU神经网络,没有bias。用来从x预测y,使用L2 Loss。
- h = W 1 X h = W_1X h=W1X
- a = m a x ( 0 , h ) a = max(0, h) a=max(0,h)
- y h a t = W 2 a y_{hat} = W_2a yhat=W2a
(2)使用Numpy实现计算前向神经网络,loss,和反向传播。
- forward pass
- loss
- backward pass
(3)复核函数求导:
三、代码实现
N, D_in, H, D_out = 64, 1000, 100, 10 #定义常量
# 随机创建一些训练数据
x = np.random.randn(N, D_in) #创建输入矩阵(64,1000)。64个样本,每个样本是(1,1000)维
y = np.random.randn(N, D_out)#创建输出矩阵(64,10)。对于分类任务,D_out是类别的个数。
w1 = np.random.randn(D_in, H) #创建矩阵(1000,100)
w2 = np.random.randn(H, D_out)#创建矩阵(100,10)
learning_rate = 1e-6 #定义学习率,一般1e-4/1e-6较佳。
for it in range(500):
# Forward pass 前向运算
h = x.dot(w1) # N * H (64,1000)*(1000,100)------->(64,100)
h_relu = np.maximum(h, 0) # N * H relu不改变维度
y_pred = h_relu.dot(w2) # N * D_out (64,100)*(100,10)------->(64,10)
# compute loss 随机生成的回归问题,采用均方差损失
loss = np.square(y_pred - y).sum()
print(it, loss)
# Backward pass 反向传,反别对w1、w2进行复核函数求导。
# compute the gradient
grad_y_pred = 2.0 * (y_pred - y)
grad_w2 = h_relu.T.dot(grad_y_pred)
grad_h_relu = grad_y_pred.dot(w2.T)
grad_h = grad_h_relu.copy()
grad_h[h<0] = 0
grad_w1 = x.T.dot(grad_h)
# update weights of w1 and w2
w1 -= learning_rate * grad_w1
w2 -= learning_rate * grad_w2















 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









