







一、模型类型
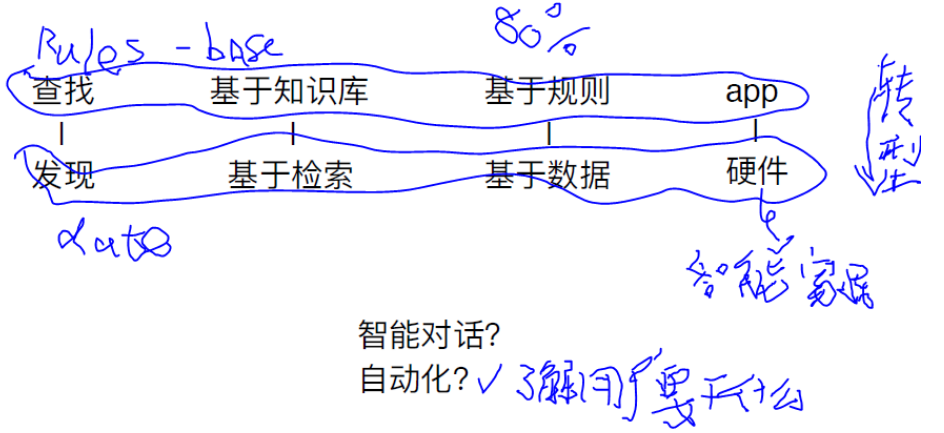
1、基于检索技术的模型:
基于检索技术的模型较为简单,主要是根据用户的输入和上下文内容,使用了知识库(存储了事先定义好的回复内容)和一些启发式方法来得到一个合适的回复。启发式方法简单的有基于规则的表达式匹配,复杂的有一些机器学习里的分类器。通过分类识别出,用户的意图是属于哪种类别,再到对应类别里寻找答案。这些系统不能够生成任何新的内容,只是从一个固定的数据集中找到合适的内容作为回复。
2、生成式模型:
基于生成的聊天机器人则更加复杂。它不依赖于预定义好的回复内容,而是利用生成式的方法逐词(字)生成新的回复内容。生成式模型典型的有基于机器翻译模型的,与传统机器翻译模型不同的是,生成式模型的任务不是将一句话翻译成其他语言的一句话,而是将用户的输入[翻译]为一个回答(response)。
必读paper:A Neural Conbersational Model(用神经网络训练2组对话。film dirlage\IT support。通过2段对话,可以驱动模型可以正常对话并加入某领域的专业对话)。自然对话+专家对话(电影对白+专业知识)
3、总结
以上两种模型均有优缺点。对于基于检索技术的模型,由于使用了知识库且数据为预先定义好的,因此进行回复的内容语法上较为通顺,较少出现语法错误;但是基于检索技术的模型中没有会话概念,不能结合上下文给出更加[智能]的回复。而生成式模型则更加[智能]一些,它能够更加有效地利用上下文信息从而知道你在讨论的东西是什么;然而生成式模型比较难以训练,并且输出的内容经常存在一些语法错误(尤其对于长句子而言),以及模型训练需要大规模的数据。
深度学习技术都能够用于基于检索技术的模型和生成式模型中,但是目前的研究热点在生成式模型上。深度学习框架例如Sequence to Sequence非常适合用来生成文本,非常多的研究者希望能够在这个领域取得成功。然而目前这一块的研究还在初期阶段,工业界的产品更多的还是使用基于检索计算的模型。
4、入模型前的数据处理:
中文和英文的库除了中文要分词外,其他没有区别。因为对于计算机,输入的都是数字。
中文分词:jieba、hanLP
库:ChatterBot(pip)
二、ChatBot-Generative的知识框架
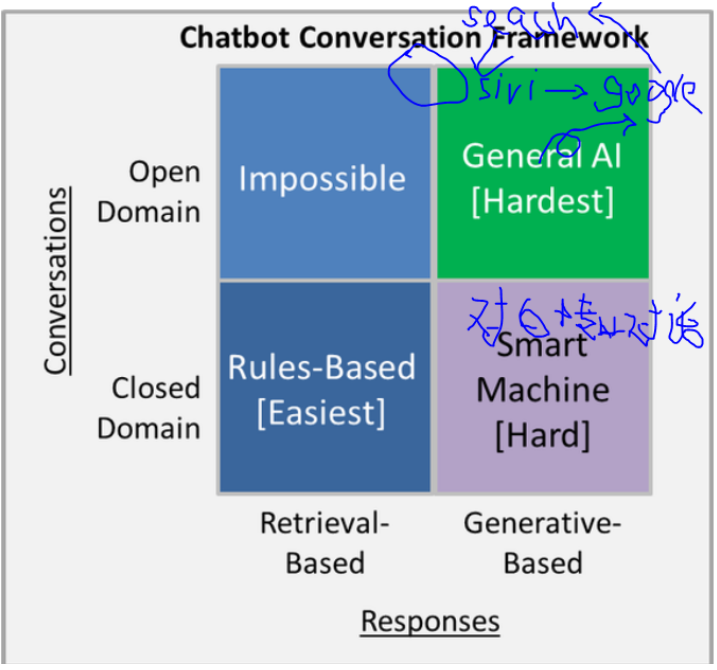
1、Open Domain:
广义对话,什么都可以聊
2、Closed Domain:
专业对话。局限在某个领域
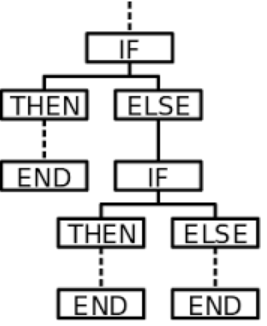
3、Rules-Based:
通过人为设定的东西,进行升级
4、Generative Based:
回答是靠数据驱动的,自己在数据里学习如何对话。有些大厂通过谷歌的api,把所有问题通过Google API搜索出一个结果,再进行回复答案。
siri在Open Domain和Generative Based之间。;
三、ChatBot玩法:LONG VS SHORT
文本长度、记忆范围(输入法提示)
Short:Y/N------可以基于Rules-Based
Long:小李说了啥?----基于人设、生成模型
四:学术界聊天机器人的挑战
1、语境
(1)内容
语言语境:这句话在说什么内容(语言属于哪个分类模块。涉及对语言的embed,比如word vector)
物理语境:这计划在哪里说的(涉及到物理环境,比如在哪里,现在几点)
(2)相关paper:
Building End-To-End Dialogue Systems Using Generative Hierarchical Neural Network Models(Lulian et al., 2015)
https://arxiv.org/abs/1507.04808
Attention with Intention for a Neural Network Conversation Model(Yao, 2015)
https://arxiv.org/abs/1510.08565
(3)自然语言比较重要的会:ACL
https://cloud.tencent.com/developer/article/1092557
2、统一的语言个性
(1)可能是很多人一起说的(高质量的数据–需要大量的人力清洗)

(2)相关paper:
A Persona-Based Neural Conversation Model (Li et al., 2016)
https://arxiv.org/abs/1603.06155
如何通过文本来归类人物性格
IBM–>Alchemy软件(基于BIG5)
3、模型验证
(1)我们自己对模型的正误判断需要人类智慧的解读
比如,你跟amazon的Alexa说,我要睡了,这时候,alexa帮你调整灯光。
(2)不存在完美定义的方案
比如,你说我饿了,机器人给你定了外卖。但定的并不是你想吃的。
(3)一般使用BLEU模型进行回复的评价得分。但有的时候如问题(2),评分是高的但并不是用户需要的。
相关paper:
How NOT To Evaluate Your Dialogue System: An Empirical Study of Unsupervised Evaluation Metrics for Dialogue Response Generation(Liu, 2016)
https://arxiv.org/abs/1603.08023
4、多样性

相关paper
A Diversity-Promoting Objective Function for Neural Conversation Models(Li et al. 2015)
https://arxiv.org/abs/1510.03055
五:工业应用综述
1、语音助手
苹果siri:被动。基于搜索。需要按HOME键你问什么,它答什么
谷歌now:主动。全程follow你手机上的信息。帮提前部署好。比如你收到一封邮件,说今天要开会,他会在日志里记录。比如你开车经过火车站,会自动给你推送该火车站的列车时刻表
2、餐饮
必胜客:基于FBM框架订pizza,告诉你家住哪儿,他会直接把餐送过来
Fackbook 推出的FBM
3、旅游、医疗(因为涉及责任问题一般:前台自动化+后台人工对接)、新闻(类似一个播报员一直在与你聊天)、财经(meet cleo.财务顾问,用户作为后台防错本身。如,本月消费在哪几个模块,每个模块多少钱。)、健身(安全隐患小,可以全自动化)。
旅游:https://viewfinder.expedia.com/features/introducing-expedia-bot-skype/
医疗:https://www.healthtap.com/
新闻:https://qzprod.files.wordpress.com/2016/02/quartz-app-featured-image.png?w=1600
4、工业上的近况
目前80%的企业还是在做更稳定的Rules-base机器人。仅几年在不断向基于数据的生成式转型。产品上再由手机转硬件。
微软小冰:学习到一些脏话。后来对于关键词、敏感词加入黑名单,不进行学习。
六、应用:基于Rule-based
七、实战案例
1、文字匹配
2、意识(关键字提取、语句相似性等)
3、知识图谱
Python自己的graph数据结构、python版本的prolog:PyKE 构建一种复杂的逻辑网络,方便提取信息
4、语音<——>文字转化
不仅仅是语音前端,包括应用场景:微信,slack,Facebook Messager,等等 都可以把我们的ChatBot给integrate进去。
参考文献:文本为七月在线《自动聊天机器人项目班》学习笔记














 2466
2466











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









