






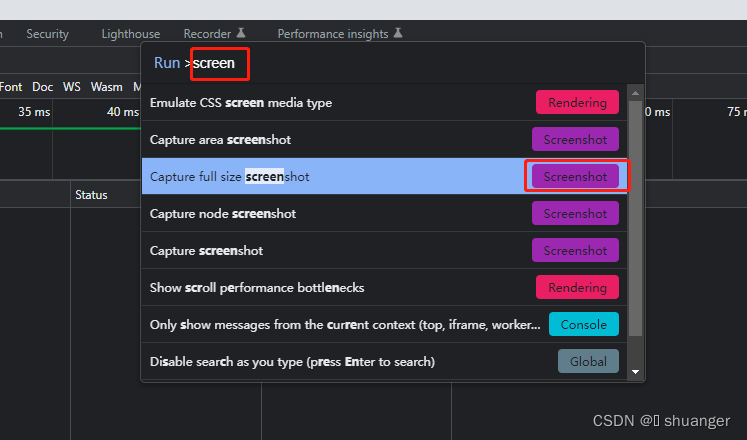
 通过F12打开浏览器开发者工具,然后使用Ctrl+Shift+P组合键触发命令面板,输入screen筛选并选择capturefullsizescreenshot选项,可以方便地进行全屏网页截图。
通过F12打开浏览器开发者工具,然后使用Ctrl+Shift+P组合键触发命令面板,输入screen筛选并选择capturefullsizescreenshot选项,可以方便地进行全屏网页截图。
- F12打开控制台
- 同时按下ctrl+shift+p ,在弹出的窗口处输入 screen 筛选
- 选择 capture full size screenshot 项进行全屏截取
谷歌浏览器网页截屏(大分辨率页面截全屏)
最新推荐文章于 2025-03-03 15:07:16 发布

 2743
594
2743
594

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























