







1.两个栈实现一个队列
思路:
不用每次出队完后都把栈B的元素倒腾回栈A。而是依照以下原则:
入队都进栈A,出队都从栈B出,一旦要出队但栈B为空,就将栈A元素依次弹出并入栈B
复杂度分析:由于每个元素都经历了进A出A和进B出B,因此时间复杂度o(n),空间复杂度o(n)

代码实现:
class Solution:
def __init__(self):
self.stack1 = []
self.stack2 = []
def push(self, node):
# write code here
self.stack1.append(node)
def pop(self):
if not self.stack2:
if not self.stack1:
raise
while self.stack1:
self.stack2.append(self.stack1.pop())
return self.stack2.pop()
2.两个队列实现一个栈
思路:
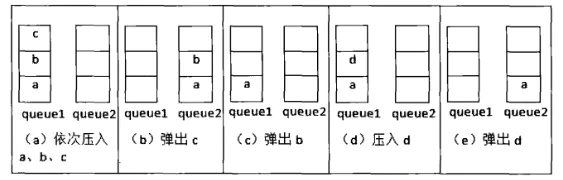
栈是遵循后入先出,而队列是先入先出。可以考虑两个队列,当要出栈时将队列1中的元素逐个出队列并加入队列2中,弹出最后一个队尾元素值返回,那么这个就是栈顶元素。入栈则直接将元素加入到队列中。总的来说,每次执行出栈操作时都要将队列元素倒腾一遍,才能获得队尾元素。【其中一个小细节技巧是,每次倒腾完,交换两个队列变量的引用,保证queue1始终是指向有元素的,这样在入队列时就统一加在queue1中,而不用根据是否有元素去判断加在哪一个queue了】
3.获取栈的最小/最大值
思路:
最直观的思路是维护一个最小值,但如果出栈的元素为最小值,又要重新去找栈中的最小值,比较麻烦。因此可考虑外加一辅助栈保存当前栈高的最小值,与数据栈同步执行入栈和出栈操作。
辅助栈的维护规则为:若进栈的元素比mival栈顶元素小则更新栈顶元素,否则重复mival栈顶元素。
这样做的本质是将每一时刻的最小值都保存了下来,所以即使当前最小值元素出栈了,也能直接得到剩余元素的最小值【根据栈的特性,出栈时的元素状态一定在当初进栈时存在过,因此在进栈时就已经得到过当前状态的最小值。而队列不满足该特性,所以该方法对队列不适用】。


代码实现:
# -*- coding:utf-8 -*-
class Solution:
def __init__(self):
self.stack, self.stackMin = [], []
def push(self, node):
# write code here
self.stack.append(node)
if self.stackMin:
self.stackMin.append(min(self.stackMin[-1], node))
else:
self.stackMin.append(node)
return node
def pop(self):
# write code here
self.stackMin.pop()
return self.stack.pop()
def top(self):
# write code here
return self.stack[-1]
def min(self):
# write code here
return self.stackMin[-1]
4.获取队列的最小/最大值
相关题目:JZ59 滑动窗口的最大值
思路:
由于队列先进先出的特点,当前状态并没有相应的历史状态。因此上述栈的方法并不适用于队列。前面提到过队列可以用两个栈实现。那么我们可以考虑对两个栈分别设置最值辅助栈,来实现这一功能。
栈A和栈B中的所有元素集合为队列中的元素。而最值辅助栈A和栈B的栈顶元素分别代表两个栈中的最值,只需对这两个值进行比较即可。
可以看到在4、2、1分别出队时,依旧能从栈maxvalB中快速获得最值。这样做的本质是把队列看成了一个反向栈,在将队列反向入B栈时,把所有数据正向出队列的情形都遍历了一遍并保存。

注:也可以用JZ59的方法。新开一个队列,后入队的大元素可以把队列中的小元素挤出去。这是因为后入队的一定比先入队的元素后出去,如果还比前面元素大的话,那就永远轮不上前面元素了,所以可以直接排除,这样队列的第一个值一定是最大值。但要注意这个最大值随时可能会出队,所以每次出队后都要判断一下该元素是否还在队列中,不在则要弹出。















 1635
1635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









