







再次复习一下
一、BeautifulSoup库的基本使用
1.1简介
正则表达式对于我们来说用起来是不方便的,而且需要记很多规则,所以用起来不是特别熟练。BeautifulSoup库一个灵活又方便的网页解析库,处理高效,支持多种解析器。利用它就不用编写正则表达式也能方便的实现网页信息的抓取。
为什么很多人将BeautifulSoup作为自己学习Python网络爬虫的第一个解析库。因为学习BeautifulSoup会加强你对标签树、子标签、父标签、后代标签以及标签的结构的认识,为日后学习Xpath打下基础,当你学习了Xpath后,你会发现BeautifulSoup是非常不友好的,而学了Xpath之后,基本不用BeautifulSoup了,但是这些全是学习Xpath的基础。
BeautifulSoup是将HTML代码当做一个便签树来处理,BeautifulSoup对应一个HTML/XML文档的全部内容 。其中的每一个标签的结构如下:
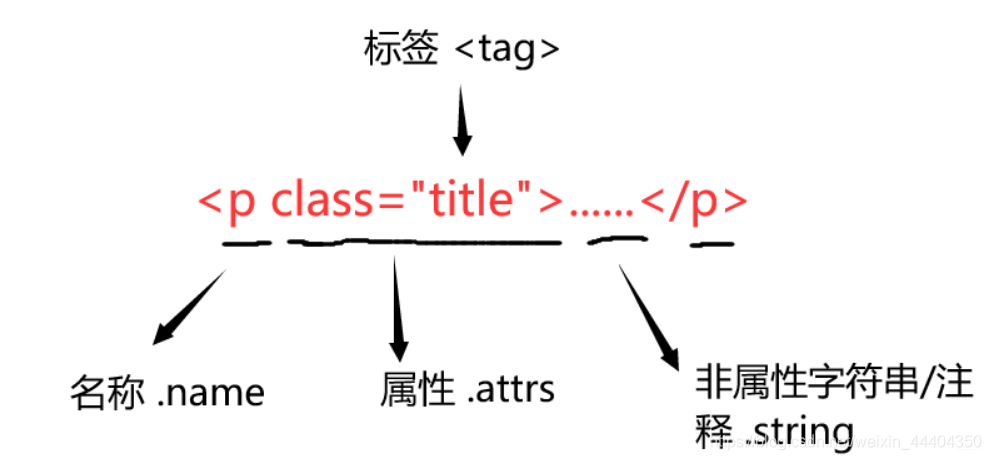
1.2 BeautifulSoup的安装
在cmd命令行中:
pip install beautifulsoup4
导入方式:
from bs4 import BeautifulSoup # 或着 import bs4
1.3解析器用法和解释
soup = BeautifulSoup(html_test,'html.parser')
soup = BeautifulSoup(html_test,'lxml')
soup = BeautifulSoup(html_test,'xml')
soup = BeautifulSoup(html_test,'html5lib')
| 解析器 | 使用方法 | 条件 | 优势 | 劣势 |
|---|---|---|---|---|
| Python标准库(bs4的HTML解析器) | BeautifulSoup(html_test,‘html.parser’) | 安装bs4库 | Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3 or 3.2.2)前的版本中文档容错能力差 |
| lxml HTML解析器 | BeautifulSoup(html_test,‘lxml’) | pip install lxml | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML解析器 | BeautifulSoup(html_test,‘xml’) | pip install lxml | 速度快、·唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib的解析器 | BeautifulSoup(html_test,'html5lib‘) | pip install html5lib | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档 | 速度慢、不依赖外部扩展 |
1.4 BeautifulSoup的基本使用
from bs4 import BeautifulSoup
import re
html = '''
<body>
<header id="header">
<h3 id="name">小鱼儿与花无缺</h3>
<title>标题</title>
<div class="sns">
<a class="a-current-menu-item" href="http://www.mytieba.com/feed/" target="_blank" rel="nofollow" title="RSS">a_test</a>
<a class="a-current-menu-item" href="http://mytieba.com/mytieba" target="_blank" rel="nofollow" title="Weibo">b_test</a>
<a href="https://www.mytieba.com/in/mytieba" target="_blank" rel="nofollow" title="Linkedin">c_test</a>
<a href="mailto:[email protected]" target="_blank" rel="nofollow" title="envelope">d_test</a>
;
<f><!--This is a comment--></f>
<c>This is not a comment</c>
</div>
<div class="nav">
<ul><li class="current-menu-item"><a href="http://www.mytieba.com/">hello</a></li>
<li><a href="http://www.mytieba.com/about-me/">word</a></li>
<li><a href="http://www.mytieba.com/post-search/">nihao</a></li>
<li><a href="http://www.mytieba.com/wp-login.php">kkb</a></li>
</ul> </div>
</header>
</body>
'''
html = html.replace('\n', '')
print("方法一,使用soup.<tag>来获取指定的标签---------------------------------------")
#使用soup.<tag>来获取指定的标签:
#soup.a来获取HTML中的a标签,如果结果有多个,取第一个
soup = BeautifulSoup(html, "html.parser")
print(soup.a)
#获取标签的属性
print("a标签的名字是:", soup.a.name)
print(type(soup.a.attrs))
print("a标签的属性为:", soup.a.attrs)
print("a标签的class属性是", soup.a.attrs['class'])
print(type(soup.a.string))
print("a标签中的非属性字符串为:", soup.a.string)
print(type(soup.f.string))
print("f标签中的注释为:", soup.f.string)
print(type(soup.c.string))
print("c标签中的注释为:", soup.c.string)
print("方法二---------------------------------------")
#方法二---------------------------------------:
soup = BeautifulSoup(html,'lxml')
# 格式化输出 soup 对象的内容
# print(soup.prettify())
# 根据标签名获取整个标签(但是拿出的是第一个)
print(soup.li)
# 获取标签的名字
print("获取标签的名字:",soup.title.name)
# 获取标签中的文本
print("获取标签中的文本:",soup.title.string)
# 获取标签title的父标标签
print("获取标签title的父标标签:",soup.title.parent.name)
# 获取li标签的子标签
print("获取li标签的子标签:",soup.li.contents)
# 获取便签的属性值的两种方式
print(soup.li["class"])
print(soup.li.attrs['class'])
# 使用select,css选择器
print(soup.select('li'))
# 类名前加.,id名前加#
print("类名前加.,id名前加#:",soup.select('.current-menu-item'))
# 获取内容
print("获取内容",soup.select('.current-menu-item')[0].get_text())
# 获取li标签下面的子标签
print(soup.select('li > a')[2].get_text())
# 获取属性值
print(soup.select('.current-menu-item')[0].attrs['class'])
# 使用find和findall进行查找
print(soup.find('li',attrs={
'class':'current-menu-item'}))
print(soup.find_all('li',attrs={
"class":"current-menu-item"})[0])
1.5 总结
基本用法:
from bs4 import BeautifulSoup
soup=BeautifulSoup(html,'lxml')
1.调用soup.prettify()方法
把要解析的字符串以标准的缩进格式输出
2.节点选择器
soup.title.string
(1)选择元素:
soup.title、soup.title.sring soup.head soup.p
(2)提取信息:
1)获取节点名称:soup.title.name
2) 获取属性:soup.p.attrs、soup.p.attrs['name']
3) 获取内容:soup.p.string
(3)嵌套选择:
soup.head.title.string
(4)关联选择:
enumerate() //生成器类型
--------------------------------------
(1)soup.p.contents //p节点下的直接子节点列表
(2)soup.p.descendants //p节点下的所有子孙节点(生成器类型)
(3)父节点和祖先节点:soup.p.partent、soup.p.parents
(4)兄弟节点:
soup.a.next_sibling
soup.a.previous_sibling
soup.a.next_siblings
enumerate(soup.a.pervious_siblings)
(5)提取信息:soup.a.next_sibling.string
3.方法选择器
find_all(name,attrs,recursive,text,**kwargs)
(1)name:find_all(name='li')
(2)attrs:find_all(attrs={
'id':'list-1'})、find_all(class_='element')
(3)text:匹配节点的文本,find_all(text='字符串或正则表达式')
注:
find()的用法与find_all()一样,只不过find()只匹配第一个元素,find_all()匹配所以元素
4.css选择器,调用select()方法
soup.select('.head')
soup.select('ul li') //所有ul下的所有li
soup.select('#list-element')
(1)嵌套选择:
for ul in soup.select('ul'):
ul.select('li')
(2)获取属性:
for ul in soup.select('ul')
ul.attrs['id']
ul['id']
(3)获取文本:
for li in soup.select('li'):
li.get_text()
lli.string
1.6 实战篇
from bs4 import BeautifulSoup
import requests
from fake_useragent import UserAgent
# 使用BeautifulSoup爬取
url = 'https://y.qq.com/'
response = requests.get(url=url, headers={
'user-Agent': "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.100 Safari/537.36"})
soup = BeautifulSoup(response.text, 'html.parser')
# #1.find查找第一个元素
# divs_1 = soup.find('div', {'class': 'debutlist__cont'})
# print(divs_1.text)
# #————————————————————————————
#2. find_all 查找所有
# li_all = soup.find_all('li',{'class':"debutlist__item"})
# for li_all in li_all:
# print('---')
# # print('匹配到的li:',li_all)
# print('li的内容:',li_all.text)
# # print('li的属性:',li_all.attrs)
#————————————————————————————
#3. 最灵活的使用方式
li_quick = soup.find_all(attrs={
'class':'debutlist__cont'})
for li_quick in li_quick:
print('最灵活的查找方法:',li_quick)
print('li.text(返回标签的内容):',li.text)
names = divs_1.select('span.playlist__title_txt > a')
authors = divs_1.select('div.playlist__author > a' 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 5015
5015











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









