







欠拟合:算法没有很好的拟合数据,算法有较大的偏差 。
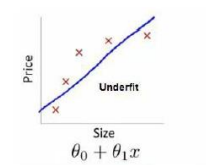
房子大到一定尺度时,房价变化幅度不大,但我们的房价模型函数为一元线性函数,房价永远随尺寸增加而增加,所以此算法并不能很好的拟合数据,称之为欠拟合。
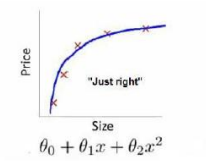
过拟合:算法具有高方差。就以多项式理解,𝑥 的次数越高,拟合的越好,但相应的预测的能力就可能变差。
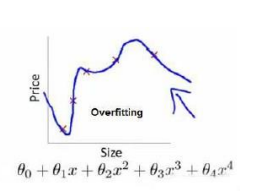
高阶多项式能拟合所有的数据,但函数太过庞大变量太多。而且,此函数虽然能非常好地适应我们的训练集但在新输入变量进行预测时可能会效果不好。
过拟合在逻辑回归中的表现:

当我们有太多特征变量但是只有少量数据时,容易出现过拟合问题。
解决:①减少选取变量的数量②正则化,保留所有的特征,但是减少参数的大小。
正规则化
对比图6-2、图6-3的函数,我们可以看出正是那些高次项导致了过拟合的产生,所以如果我们能让这些高次项的系数接近于 0 的话,我们就能很好的拟合了。
在一定程度上减小参数𝜃 的值,降低这些高次项对预测值的影响,这就是正则化的基本方法。
例如图6-3的函数,我们要减小参数𝜃3、𝜃4 的值,修改代价函数,给参数𝜃3 𝜃4 加上惩罚,我们在尝试最小化代价时也需要将这个惩罚纳入考虑中,并最终导致选择较小一些的𝜃3和𝜃4。
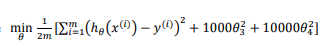
为了使得代价值最小化,𝜃3、𝜃4近似于0;通过这样的代价函数选择出的𝜃3和𝜃4 对预测结果的影响就比之前要小许多。
假如我们有非常多的特征,我们并不知道其中哪些特征我们要惩罚,我们将对所有的特征进行惩罚,并且让代价函数最优化的软件来选择这些惩罚的程度。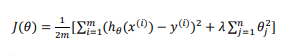
其中𝜆 ∑ 𝜃为正规则项,𝜆又称为正则化参数(Regularization Parameter),控制两个不同目标之间的取舍;根据惯例,我们不对𝜃0 进行惩罚。
𝜆的大小对函数造成的影响:
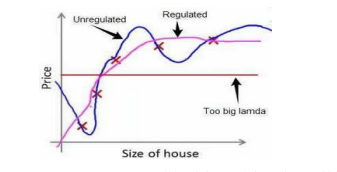
如果选择的正则化参数 λ 过大,则会把所有的参数都最小化了,导致模型变成 ℎ𝜃(𝑥) =𝜃0,也就是上图中红色直线所示的情况,造成欠拟合。
而 λ 过小,正规则化就没有意义了,函数依旧会过拟合。
所以对于正则化,我们要取一个合理的 𝜆 的值,这样才能更好的应用正则化。
正则化线性回归
基于梯度下降

因为正则化惩罚对象是𝜃1、𝜃2…,而不影响𝜃0,所以我们对线性回归的梯度函数进行正规则化时只用更新上面的算法中𝑗 = 1,2, . . . , 𝑛 ,进行调整可得:
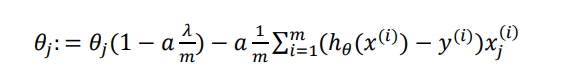
原式为:
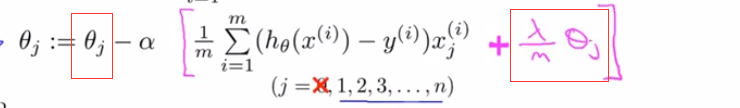
其中,1 − 𝑎𝜆/𝑚是一个只比1略小一点的数,通常学习率𝑎很小,m很大,所以𝑎𝜆/𝑚很小。
正则化线性回归的梯度下降算法的变化在于,每次都在原有算法更新规则的基础上令𝜃值减少了一个额外的值。
于正规方程
线性回归的正规方程:
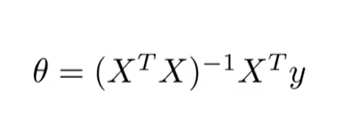
将正规方程规则化:
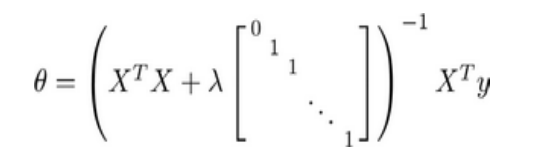
矩阵尺寸为 (𝑛 + 1) ∗ (𝑛 + 1)。
在这里。只要𝜆>0,那么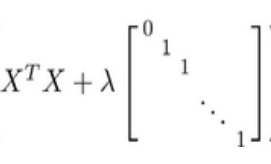 一定是可逆矩阵。
一定是可逆矩阵。
正则化逻辑函数
我们也给代价函数增加一个正则化的表达式,得到代价函数: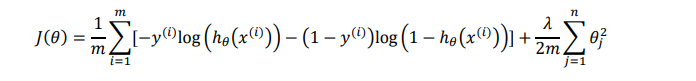
要最小化该代价函数,通过求导,得出梯度下降算法为:

注意:
- 虽然正则化的逻辑回归中的梯度下降和正则化的线性回归中的表达式看起来一样,但由于两者的**ℎ𝜃(𝑥)**不同所以还是有很大差别。
- 𝜃0不参与其中的任何一个正则化。
无论是线性回归问题,还是逻辑回归问题,都可以构造多项式来解决。你将逐渐发现还有更强大的非线性分类器,可以用来解决多项式回归问题。















 809
809











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









