






Multimodal Unsupervised Image-to-Image Translation(MUNIT)
I Related Works
1 GANs
使用GANs将翻译图像的分布与目标域中的真实图像对齐。
2 Image2image translation
多模态无监督图像到图像生成本质上是不适定的,需要额外的约束。
要求强制保留源域的某些特征:像素值、像素梯度、语义特征、类标签。
cycle consistency loss It enforces that if we translate an image to the target do- main and back, we should obtain the original image.
在**UNIT**框架中,假设存在一个共享的潜在空间,使得两个域的图像能够映射到相同的潜在空间。
3 style transfer
Style transfer aims at modifying the style of an image while preserving its content. 风格转移的目的是在保留图像内容的同时修改图像的风格。
可以理解为源图片和目标域的图片,保留的图像内容来自单个实例,而转移的图像风格来自某一个图像集合。
thanks to its disentangled representation of content and style. 感谢解耦特征表示和内容表示
- Zhu, J.Y., Park, T., Isola, P., Efros, A.A.: Unpaired image-to-image translation using cycle-consistent adversarial networks. In: ICCV. (2017)
4 learning disentagled representations
InfoGAN 和 β-VAE提出无监督地学习解耦表示
一些和工作注重与解耦内容和特征
Although it is difficult to define content/style and different works use dif- ferent definitions, we refer to “content” as the underling spatial structure and “style” as the rendering of the structure
虽然很难定义内容/风格,不同的作品使用不同的定义,但我们认为“内容”是底层的空间结构,“风格”是结构的呈现。
在本文的设置中,有两个域共享同样的**内容content分布但是有不同的风格style分布**
II Multimodal Unsupervised Image2image Translation
1 Assumptions
在无监督学习中只能得到样本的边缘分布,不能得到联合分布
Our goal is to estimate the two conditionals p(x2|x1) and p(x1|x2) with learned image-to-image translation models p(x1→2|x1) and p(x2→1|x2), where x1→2 is a sample produced by translating x1 to X2 (similar for x2→1).
x 1 x_1 x1, x 2 x_2 x2来自两个不同域的图像分布, x 1 → 2 x_{1→2} x1→2表示的是一个样本,它由 X 1 X_1 X1变换到 X 2 X_2 X2域中, p ( x 1 → 2 ∣ x 1 ) p(x_{1→2}|x_1) p(x1→2∣x1)是img2img翻译模型。 p ( x 2 ∣ x 1 ) p(x_2|x_1) p(x2∣x1) 和 p ( x 1 ∣ x 2 ) p(x_1|x_2) p(x1∣x2)是复杂的多模态分布,确定性的翻译模型不能解决。
为了解决这个问题,文章做了一个假设***partially shared latent space assumption即假每一个图像是由两个域共享的内容潜码,对于不同的域有不同的风格样式潜码生成的*。
x
i
∈
X
i
,
c
∈
C
,
s
i
∈
S
i
x_i ∈ X_i, c ∈ C, s_i ∈ S_i
xi∈Xi,c∈C,si∈Si
In other words, a pair of corresponding images (x1,x2) from the joint distribution is generated by x1 = G∗1(c,s1) and x2 = G∗2(c,s2), where c,s1,s2 are from some prior distributions and G∗1, G∗2 are the underlying generators.
对于 G 1 ∗ G_1^* G1∗, G 2 ∗ G_2^* G2∗,假设他们是确定性的函数,并且存在逆编码器 E 1 ∗ = ( G 1 ∗ ) − 1 E_1^∗ = (G_1^*)^{−1} E1∗=(G1∗)−1, E 2 ∗ = ( G 2 ∗ ) − 1 E_2^∗ = (G_2^*)^{−1} E2∗=(G2∗)−1
Our goal is to learn the underlying generator and encoder functions with neural networks.
Note that although the encoders and decoders are deterministic, p(x2|x1) is a continuous distribution due to the dependency of s2.
目标是利用神经网络学习底层的生成器和编码器的两个函数。
区别:UNIT假设完全共享的隐空间,本方法假设一部分跨域的共享空间(content)
2 Model
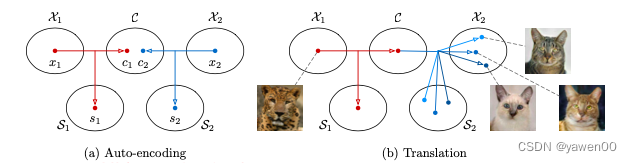
Recombining the content code of the input with a random style code in the target style space. Different style codes lead to different outputs.
翻译模型包含一个encoder E i E_i Ei和一个decoder G i G_i Gi
loss function
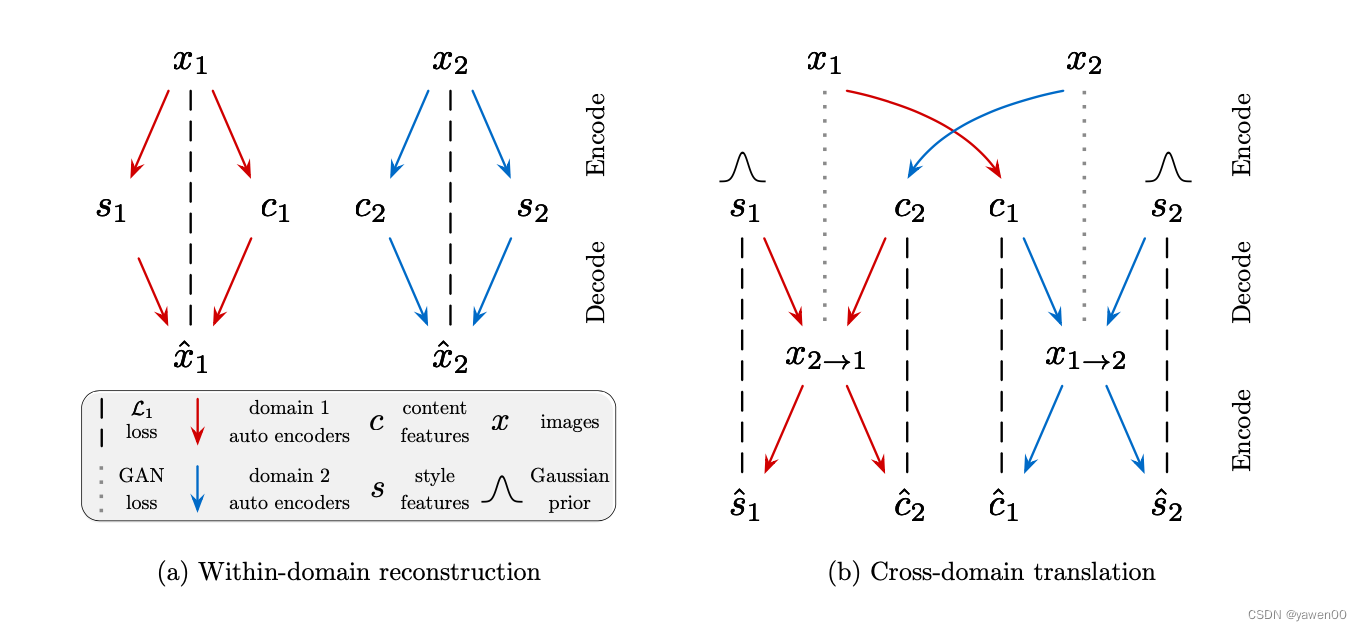
We train the model with adversarial objectives (dotted lines) that ensure the translated images to be indistinguishable from real images in the target domain, as well as bidirectional reconstruction objectives (dashed lines) that reconstruct both images and latent codes.
Fig (a) 红蓝代表两个自编码器,分别对应两个域。将每个自编码器的潜码分解为内容码ci和样式码si,其中 ( c i , s i ) = ( E i c ( x i ) , E i s ( x i ) ) = E i ( x i ) (c_i, s_i) = (E_{i}^{c}{(x_i)}, E_{i}^{s}{(x_i)}) = E_i{(x_i)} (ci,si)=(Eic(xi),Eis(xi))=Ei(xi)。
*Fig (b)*翻译一张图片的步骤:1 提取图片的content潜编码 c 1 = E 1 c ( x 1 ) c_1 = E_{1}^{c}{(x_1)} c1=E1c(x1) 2 随选择一个style潜编码 s 2 s_2 s2 3 用generator生成图片 x 1 → 2 = G 2 c 1 , s 2 x_{1→2} = G_2{c_1,s_2} x1→2=G2c1,s2
Bidirectional reconstruction loss: 双向重建损失,重建图像和潜在代码。用于保证编码器和解码器是可逆的
Adversarial loss: 将翻译图像的分布与目标域中的图像分布相匹配,确保翻译后的图像与目标域中的真实图像无法区分。
Bidirectional reconstruction loss
Image reconstruction
image → latent → image
给一个图像,应该可以通过encode和decode重构这个图像
L
r
e
c
o
n
x
1
=
E
x
1
p
(
x
1
)
[
∣
∣
G
1
(
E
1
c
(
x
1
)
,
E
1
s
(
x
1
)
)
−
x
1
∣
∣
1
]
L_{recon}^{x_1} = E_{x_1}{~}_{p(x_1)}[||G_1(E_1^c(x_1), E_1^s(x_1))-x_1||_1]
Lreconx1=Ex1 p(x1)[∣∣G1(E1c(x1),E1s(x1))−x1∣∣1]
Latent reconstruction
latent → image → latent
给定一个潜表示(contend code/ style code)在翻译过程中,应该可以通过decode和encode重构
L
r
e
c
o
n
c
1
=
E
c
1
p
(
c
1
)
,
s
2
q
(
s
2
)
[
∣
∣
E
2
c
(
G
2
(
c
1
,
s
2
)
)
−
c
1
∣
∣
1
]
L_{recon}^{c_1} = E_{c_1}{~}_{p(c_1),s_2~q(s_2)}[||E_2^c(G_2(c_1,s_2)) - c_1||_1]
Lreconc1=Ec1 p(c1),s2 q(s2)[∣∣E2c(G2(c1,s2))−c1∣∣1]
L r e c o n s 2 = E c 1 p ( c 1 ) , s 2 q ( s 2 ) [ ∣ ∣ E 2 s ( G 2 ( c 1 , s 2 ) ) − s 2 ∣ ∣ 1 ] L_{recon}^{s_2} = E_{c_1}{~}_{p(c_1),s_2~q(s_2)}[||E_2^s(G_2(c_1,s_2)) - s_2||_1] Lrecons2=Ec1 p(c1),s2 q(s2)[∣∣E2s(G2(c1,s2))−s2∣∣1]
使用 L 1 L_1 L1损失保留更多输入图像的语义信息,并且促进输出多样化。
Adversarial loss
L G A N x 2 = E c 1 p ( c 1 ) , s 2 q ( s 2 ) [ l o g ( 1 − D 2 ( G 2 ( c 1 , s 2 ) ) ) ] + E x 2 p ( x 2 ) [ l o g D 2 ( x 2 ) ] L_{GAN}^{x_2} =E_{c_1~p(c_1),s_2~q(s_2)} [log(1−D_2(G_2(c_1,s_2)))]+E_{x_2~p(x_2)} [logD_2 (x_2)] LGANx2=Ec1 p(c1),s2 q(s2)[log(1−D2(G2(c1,s2)))]+Ex2 p(x2)[logD2(x2)]
D 2 D_2 D2是discriminator用以区分 X 2 X_2 X2中生成的图片和真实的图片
Total loss
m i n E 1 , E 2 , G 1 , G 2 m a x D 1 , D 2 L ( E 1 , E 2 , G 1 , G 2 , D 1 , D 2 ) = L G A N x 1 + L G A N x 2 + λ x ( L r e c o n x 1 + L r e c o n x 2 ) + λ c ( L r e c o n c 1 + L r e c o n c 2 ) + λ s ( L r e c o n s 1 + L r e c o n s 2 ) \underset{E_1,E_2,G_1,G_2}{min}\underset{D_1,D_2}{max} L(E_1,E_2,G_1,G_2,D_1,D_2) = L_{GAN}^{x_1} + L_{GAN}^{x_2}+\lambda _x(L_{recon}^{x_1}+L_{recon}^{x_2})+\lambda_c(L_{recon}^{c_1}+L_{recon}^{c_2})+\lambda_s(L_{recon}^{s_1}+L_{recon}^{s_2}) E1,E2,G1,G2minD1,D2maxL(E1,E2,G1,G2,D1,D2)=LGANx1+LGANx2+λx(Lreconx1+Lreconx2)+λc(Lreconc1+Lreconc2)+λs(Lrecons1+Lrecons2)
III Theoretical Analysis
IV Experiments
Details
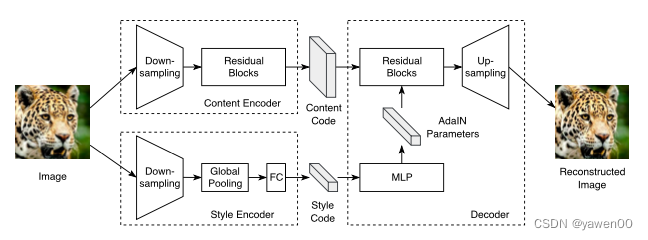
Fig展示了自编码器(auto-encoder)的结构,包含一个content encoder内容编码器,style encoder样式编码器,joint decoder联合解码器。
Content encoder
内容编码器由几个跨行卷积层和残差块组成。
Style encoder
风格编码器包括几个跨行卷积层,然后是一个全局平均池化层和一个全连接层。
在风格编码器中不使用***IN layers***,因为IN去除了代表重要风格信息的原始特征均值和方差
Decoder
通过残差块对内容码进行处理,最后通过多次上采样和卷积生成重构图像。
在残差块中配备了AdaIN层,这个AdaIN参数是通过MLP从style code中动态生成的。style code —> MLP—>AdaIN parameters
Huang,X.,Belongie,S.:Arbitrarystyletransferinreal-timewithadaptiveinstance normalization. In: ICCV. (2017)
仿射参数(AdaIN参数)是由学习网络产生的,而不是从预训练网络的统计数据中计算出来的。
Discriminator
LSGAN
Mao, X., Li, Q., Xie, H., Lau, Y.R., Wang, Z., Smolley, S.P.: Least squares gener- ative adversarial networks. In: ICCV. (2017)
使用多尺度鉴别器来引导生成器生成真实的细节和正确的全局结构
Wang, T.C., Liu, M.Y., Zhu, J.Y., Tao, A., Kautz, J., Catanzaro, B.: High-resolution image synthesis and semantic manipulation with conditional gans. In: CVPR. (2018)
Domain-invariant perceptual loss
感知损失,计算输出和参考图像在VGG特征空间里的距离(被证实有助于img2img翻译)。但是在无监督训练中,没有一个可以参照的目标图像,于是提出一个新的版本感知损失。
具体来说,在计算距离之前,对VGG特征进行实例归一化(Instance Normalization)(不进行仿射变换),以去除原始特征均值和方差,其中包含了许多特定于领域的信息。
结论:我们定量地证明了实例归一化确实可以使VGG特征更具域不变性。我们发现领域不变感知损失加速了高分辨率(≥512 × 512)数据集的训练,从而将其应用于这些数据集。
Evaluation Metrics
Human Preference
比较不同方法生成的翻译输出的真实感和可信度。
LPIPS Distance
为了测量翻译多样性,我们计算了相同输入的随机抽样翻译输出对之间的平均LPIPS距离。
Inception Score
IS是衡量图像生成任务一个流行的指标。
本文提出了一个修改版本,称为条件初始分数Conditional Inception Score(CIS),更适合评价多模态图像翻译任务。
“When we know the number of modes in X2 as well as the ground truth mode each sample belongs to, we can train a classifier p(y2|x2) to classify an image x2 into its mode y2. ”
对于域 X 2 X_2 X2,当知道了模式(modes)的数量,以及每一个样本所属于的真实的mode,就可以训练一个分类器 p ( y 2 ∣ x 2 ) p(y_2|x_2) p(y2∣x2)将一个图片 x 2 x_2 x2划分为它所属于的类别 y 2 y_2 y2中,在单个输入图像x1的条件下,平移样本x1→2应该是模式覆盖的(因此 p ( y 2 ∣ x 1 ) = ∫ p ( y ∣ x 1 → 2 ) p ( x 1 → 2 ∣ x 1 ) d x 1 → 2 p(y_2|x_1)=\int {p(y|x_{1\rightarrow 2})p(x_{1\rightarrow 2}|x_1) dx_{1\rightarrow2}} p(y2∣x1)=∫p(y∣x1→2)p(x1→2∣x1)dx1→2应该具有高熵),每个单独的样本应该属于特定的模式(因此 p ( y 2 ∣ x 1 → 2 ) p(y_2|x_{1\rightarrow2}) p(y2∣x1→2)应该具有低熵)。
IS测量的是所有输出图像的多样性,而CIS测量的是基于单个输入图像的输出多样性。














 920
920











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









