










目录

论文链接:
https://arxiv.org/pdf/2501.13400作者单位:Computer Engineering and Informatics Department,Kab. Bandung Barat,Indonesia e Stunning Vision AI,Kota Cimahi,Indonesia
在基于深度学习的计算机视觉领域,YOLO具有革命性意义。相对于其他深度学习模型,YOLO也是发展最快的模型之一。不幸的是,并非每个YOLO模型都有学术论文发表。此外,还存在一些缺乏公开可访问官方架构图的YOLO模型。这自然会带来挑战,例如使人们难以理解该模型在实践中的工作原理。目前可用的综述文章也没有深入探讨每个模型的细节。
本研究的目标是介绍最近四个YOLO模型(即YOLOv8到YOLO11)的全面而深入的架构比较,以便读者能够快速了解每个模型的功能以及它们之间的区别。为了分析每个YOLO版本的架构,我们仔细检查了相关的学术论文、文档并审查了源代码。分析表明,尽管每个YOLO版本在架构和特征提取方面都有改进,但某些块保持不变。缺乏学术出版物和官方图表给理解模型功能和未来增强带来了挑战。鼓励未来的开发人员提供这些资源。
关键词: YOLO 架构 · 计算机视觉 · 深度学习 · 人工智能
1 简介
YOLO (You Only Look Once) 是深度学习领域最先进的模型之一,拥有最多开发版本的模型,从2015年的YOLOv1到2024年,它一直在不断发展,目前正在使用的版本是第11版。尽管 YOLO 在研究人员和开发人员中获得了成功,但理解其架构和组件仍然存在挑战。一个重大障碍是缺乏某些 YOLO 版本的学术出版物和全面的架构图,迫使研究人员和从业者依赖于辅助资料和经验分析来理解这些模型。此外,现有的综述论文经常缺乏架构细节的深度,并提供有限的见解。这些挑战强调了进行彻底比较以填补知识空白的必要性。对架构进行彻底的比较对于理解每个模型的功能以及识别它们独特的改进至关重要。
本研究旨在通过对YOLOv8和YOLOv11进行全面系统的比较来弥补这些缺陷。 本研究旨在阐明每个模型的工作原理,从而加深人们对YOLO发展历程的理解。 本研究旨在促进计算机视觉领域的创新和发展。
2 文獻综述
YOLO 系列自问世以来发展迅速,每一版都带来了重要的改进和创新,旨在提高性能和效率。
• YOLOv8 (2023) 引入了无锚点检测方法,简化了模型架构,提高了对小对象的性能。 多任务计算机视觉框架的统一性增强了其在各个领域的适用性 [1]。YOLOv8 包括目标检测、实例分割和图像分类等任务,得益于无锚点检测。 它由 Ultralytics 于 2023 年首次发布。当前的 YOLOv8 支持各种视觉 AI 任务,并添加了新的功能,包括目标跟踪、姿态估计和定向边界框 [2]。
• YOLOv9 在 2024 年引入了 PGI(可编程梯度信息)框架和 GELAN(广义高效层聚合网络)架构。它们解决了信息瓶颈问题,提高了轻量级模型的精度 [3]。
• YOLOv10 (2024) 是一个重大进步,因为它使用无 NMS(非最大抑制)训练,这使得从头到尾部署更加容易,并减少了计算量 [4]。空间通道解耦下采样和大型卷积核使性能和效率有了很大提升 [4]。用于无 NMS 训练的双重分配策略始终提高了精度,降低了延迟,支持实时目标检测 [4]。该模型由清华大学研究人员开发。
• YOLO11 是 Ultralytics 最新的 YOLO 模型,在各种计算机视觉任务中表现出色,包括目标检测、特征提取、实例分割、姿态估计、跟踪和分类。它们还代表了实时目标检测技术的重大突破 [5]。根据 [6],YOLOv11 添加了 C3k2 块、SPPF(空间金字塔池化 - 快速)和 C2PSA(具有并行空间注意力的卷积块)组件,这些组件提高了提取特征和查找对象的的能力。改进实例分割、姿态估计和定向目标检测等计算机视觉任务使其在更广泛的场景中更有用 [7]。
许多评论文章都研究了YOLO架构的发展和进展。[8]对YOLO的演变进行了全面的分析,重点关注版本1到8以及最新的YOLO-NAS。他们提供了一个简洁的历史背景,探讨了速度与准确性的权衡,并强调了在选择YOLO版本时应用需求的重要性。尽管如此,他们的研究仅限于YOLOv8,并没有全面探索每个迭代的架构细节。[6]对版本1到11进行了全面的评估,而[7]则专注于版本1到10,特别强调农业领域。[9]也涉及版本1到10,简要总结了架构的发展历程。[10]明确分析了YOLOv5、YOLOv8和YOLOv10,而[5]仅关注YOLOv11。
[5] 对YOLOv1到YOLOv10的变体进行全面回顾,重点关注它们如何用于改进光伏 (PV) 缺陷检测。随着 YOLO 架构的不断改进,该研究仔细分析了这些变化对光伏行业质量控制的影响。论文主要讨论了可编程梯度信息、路径聚合网络和广义高效层聚合拓扑结构等因素,这些因素使每个变体有效运作。根据该综述,未来研究的主要趋势是改进 YOLO 变体以涵盖更广泛的光伏故障场景。目前讨论主要集中在识别微裂纹上,但公认地存在进一步扩展的潜力。研究人员将探讨 YOLO 架构中的注意力机制,他们认为这可以显著提高检测能力,尤其是在处理细微和复杂缺陷方面。
尽管如此,这些评论通常缺乏对最新YOLO版本(v8到v11)的全面审查。 [8] 对YOLO从第一版到YOLOv8的变化进行了深入探讨。然而,他们没有研究后续架构的复杂性,而这些架构显著增强了网络的设计和训练。[7] 也未提供YOLOv10与其前身或后继者的完整架构比较,这使得理解其独特之处以及它带来的改进更加困难。 [6] 对YOLOv11进行了概述,但没有详细说明其架构部分及其对性能的影响。
由于本研究以集中且彻底的方式比较和对比了 YOLOv8 和 YOLOv11,它通过关注这两种模型之间的主要差异和架构变化来解决这些问题。 通过分析每种版本的架构细节并分析源代码,本研究旨在使最近的改进更容易理解和在现实生活中使用。
3 研究方法
为了准确绘制架构示意图,我们仔细阅读了相应的文献。然而,仅仅阅读文献不足以全面理解模型的工作原理。因此,我们深入研究了每个 YOLO 版本的源代码。 .yaml 文件包含整体架构块,而 Python 源代码包含架构块实现,这些实现以 Python 模块的形式出现。
我们从每个 YOLO 版本的 GitHub 存储库克隆源代码。我们分析了位于 ultralytics/cfg/models/文件夹中的对应 .yaml 文件,了解了每个 YOLO 版本的整体架构,其中 vX 是 YOLO 版本。至于 YOLO 架构块,我们使用位于 ultralytics/nn/modules 文件夹中的 conv.py、block.py 和 head.py,除了 YOLOv9 外。YOLOv9 的 .yaml 文件位于 models/detect 文件夹中,而其架构块位于 models/detect/common.py 中。随后,我们创建了 YOLO 整体架构和架构块图。
4 结果与讨论
在本节中,我们将详细阐述每个YOLO版本的整体架构及其基于相应论文、源代码和技术文档的块。
4.1 YOLO 总体架构
YOLO 架构通常由三个部分组成:主干、颈部和头部。 YOLO 架构的一个重要部分,主干负责从多尺度输入图像中提取特征。在这个过程中,卷积层和专门的块被堆叠在一起,以创建不同分辨率的特征图。来自不同尺度的特征被整合到颈部并传递到头部进行预测。通常,这个过程包括连接和上采样来自多个级别的特征图,使模型能够有效地捕获多尺度数据。头部生成最终的对象检测和分类预测。经过从颈部提供的特征图处理后,图像中对象的边界框和类别标签最终输出 [5]。
stem、下采样层、由基本构建块组成的阶段以及头是构成 YOLO [4] 的要素。网络的第一个组件,称为 stem,负责接收和处理原始输入数据,例如图像或视频。为了提高计算效率并扩大模型的感受野,下采样层被分配降低特征的空间分辨率。YOLO 架构的每个阶段通常由多个称为基本构建块或结构的卷积块组成。 通常,每个步骤都会生成更高抽象层次的特征,并处理不同分辨率的数据。
4.1.1 YOLOv8
该图是基于位于 ultralytics/cfg/models/v8 (Glenn Jocher & Paula Derrenger, 2023) 的 yolov8.yaml 创建的。 YOLOv8 变体的确定取决于三个参数:depth_multiple、width_multiple 和 max_channels。 depth_multiple 参数决定了 C2f 块中包含多少个瓶颈块。 width_multiple 和 max_channels 参数定义输出通道数。 YOLOv8 的主干部分由两个步幅为 2,核大小为 3 的卷积块组成。这两个块将数据转换为初始特征并降低输入分辨率。
YOLOv8 的阶段组件使用 C2f 块。共有 8 个阶段,分别是块编号 2、4、6、8、12、15、18 和 21。主干中的阶段(块编号 2、4、6 和 8)使用快捷连接,而颈部(块 12、15、18 和 21)不使用快捷连接。使用或不使用快捷连接是由试错实验的经验结果指导的,以找到最佳方案 [13]。YOLOv8 的下采样过程利用步幅为 2、核大小为 3 的卷积块。当使用步幅 2 时,输出空间分辨率将减半。
SPPF(空间金字塔池化快速)块位于颈部,紧接骨干网络的最后一个块之后,旨在提供特征图的多尺度表示。 SPPF 通过不同尺度的池化使模型能够捕获不同抽象层次的特征[14]。 颈部有一些连接和上采样块。通过上采样增加特征图的分辨率。 YOLOv8 使用最近邻上采样技术。这种技术重复相邻像素的值来填充较大特征图中新创建的像素。 连接用于组合特征图。 分辨率保持不变,但当组合特征图时,通道总数会增加。
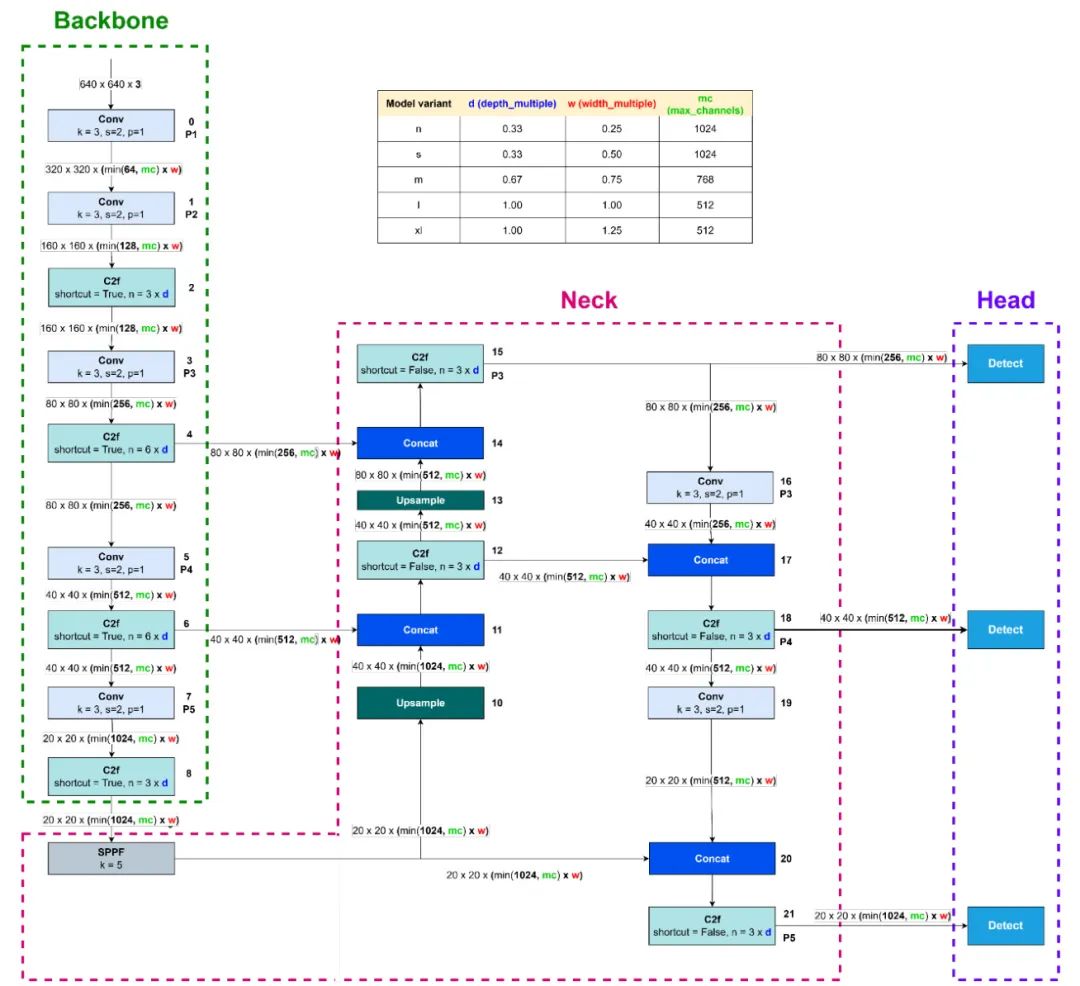
图 1:YOLOv8 架构(改编自[11],[12])
在 YOLOv8 中,有三个头。第一个头连接到第 15 个块,用于检测小物体。第二个头连接到第 18 个块,用于检测中型物体。第三个头连接到第 21 个块,用于检测大型物体。需要注意的是,在每个 YOLO 版本中,物体的尺寸都是相对于图像或视频帧的。
4.1.2 YOLOv9
该图是基于位于 models/detect/ 文件夹中的 yolov9-c.yaml 创建的[15]。在 YOLOv9 中,有一个额外的部分称为辅助部分。此部分用于生成可靠的梯度并更新网络参数。通过提供将输入数据与输出目标连接的额外信息,可以解决深度学习网络层传递时信息丢失的问题[3]。该辅助部分仅在训练过程中使用。推理过程中可以删除此部分,以加快模型速度而不会牺牲精度。
YOLOv9 从 Silence 块开始。该块简单地返回输入;不执行任何变换操作。该块将 YOLOv9 输入连接到辅助和主干部分。YOLOv9 中的 stem 组件由两个核大小为 3、步幅为 2 的卷积块组成。这两个块将数据转换为初始特征并降低输入分辨率。
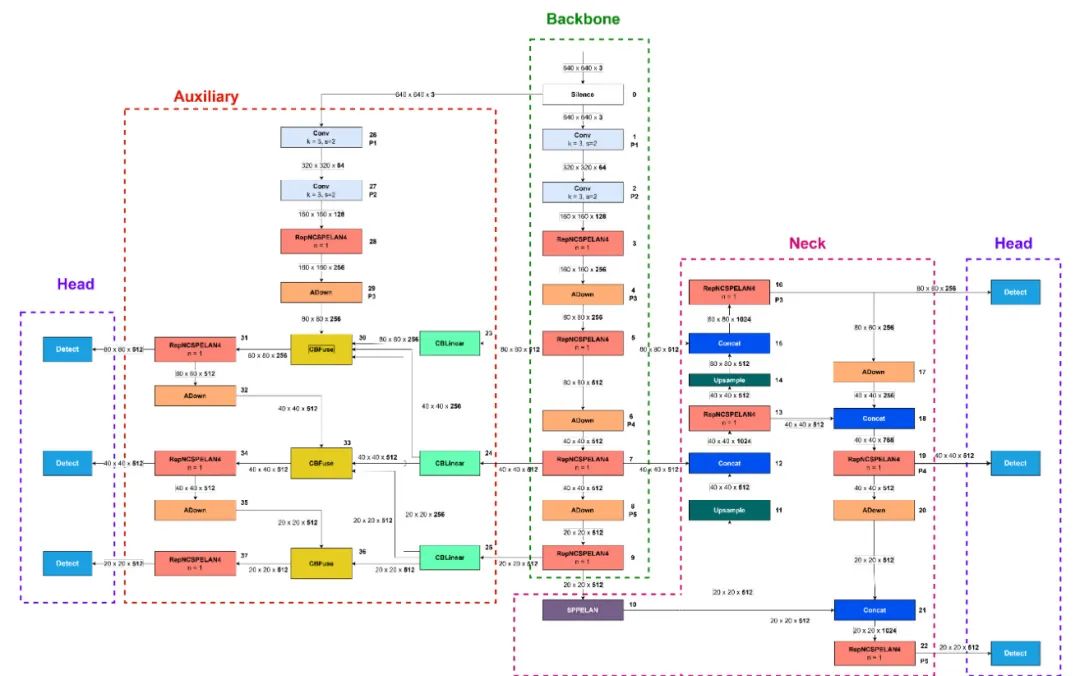
图 2:YOLOv9-c 架构(改编自 [16])
YOLOv9 的阶段组件使用 RepNCSPELAN4 块。RepNCSPELAN4 是 YOLOv9 中 GELAN 概念的实现。GELAN 将 CSPNet 和 ELAN(在 YOLOv7 上)结合起来,设计了梯度路径规划,考虑轻量级、推理速度和精度。GELAN 概括了 ELAN 的能力。ELAN 只使用卷积层的堆叠,而 GELAN 可以使用各种计算块,例如残差块或更复杂的块(C.-Y. 王等,2024)。 YOLOv9 有 8 个阶段,分别是块 3、5、7、9、13、16、19 和 22。 YOLOv9 中的下采样过程使用 ADown 块。
在颈部,紧接脊柱最后一个区块之后,有一个SPPELAN区块。这个区块与YOLOv8中的SPPF(空间金字塔池化快)相同。还有一些上采样和连接块。就像YOLOv8一样,YOLOv9使用最近邻上采样。
YOLOv9 有3个头。第一个头连接在第16个block,用于检测相对于帧或图像的小物体。第二个头连接在第19个block,用于检测中等大小的物体。第三个头连接在第22个block,用于检测大物体。
辅助部分提供额外的信息,将输入数据链接到目标输出。因此,该部分从Silence块获取输入,并添加几个与主干中相同的块,这些块包括两个卷积层、RepNCSPELAN4 和 ADown。
有三个CBLinear块。这些块用于创建不同的金字塔特征图,并用于从第一个主干中获取更高层次的特征。CBFuse块是主要部分,它包含可逆特性,将第一个主干的高级特征与第二个主干的低级特征结合起来。
除了辅助部分,YOLOv9 的另一个新颖之处是添加了额外的头部。总共有三个额外的头部。连接到第 31、34 和 37 个块的头部分别用于检测小、中和大物体。
4.1.3 YOLOv10
该图是基于位于 ultralytics/cfg/models/v10 文件夹 [17] 的 yolov10l.yaml 创建的。YOLOv10 架构是基于 YOLOv8 构建的,因此它与 YOLOv8 参数具有相似的 stem 组件和参数。区别在于 YOLOv10 中的 depth_multiple 参数用于定义 C2f 块中包含多少个 bottleneck 块以及 C2fCIB 块中包含多少个 CIB 块。
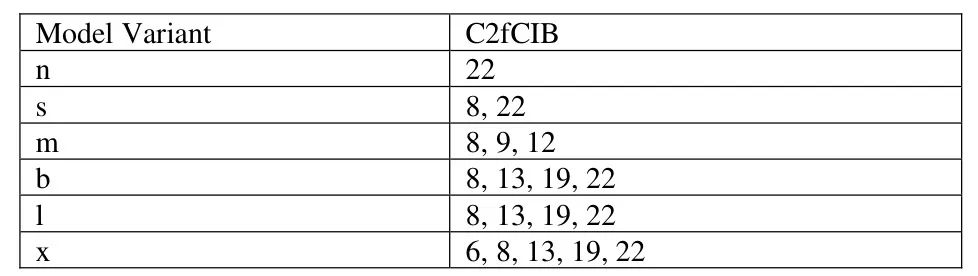
图 3 显示了 YOLOv10l 的架构。其他变体的区别在于使用 C2fCIB 块。每个变体中 C2fCIB 块的使用细节见表 1。
YOLOv10 的阶段组件使用 C2f 或 C2fCIB 块。有八个阶段,分别是块 2、4、6、8、13、16、19 和 22。 YOLOv10 中存在了一种名为 rank-guided block 设计的概念,该概念旨在通过考虑模型每个阶段基本块的复杂性来优化 YOLO 架构,这种复杂性基于内在秩分析。内在秩是一个数值,表示基本块末尾显著奇异值的个数。大型模型和 YOLO 模型更深层的阶段通常存在更多冗余。在高冗余阶段,CIB(紧凑逆置块)将被用于替换 C2f 中的瓶颈块,将其转换为 C2fCIB(A. 王等,2024)。例如,如上图所示,YOLOv10l 变体的块 8、13、19 和 22 使用 C2fCIB。表 1 展示了每个 YOLOv10 变体中 C2fCIB 的使用情况。
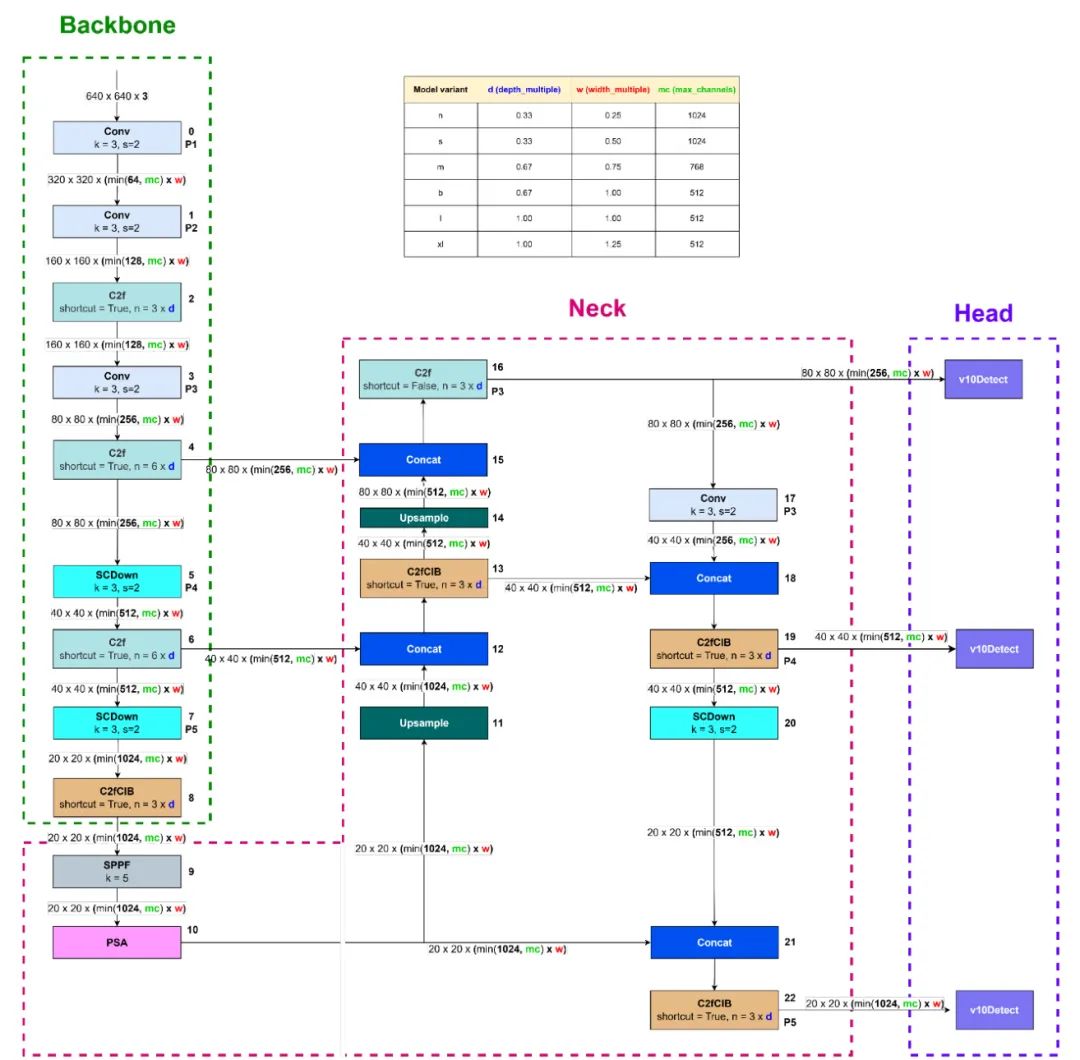
图 3:YOLOv10l 架构(改编自[18])
表 1:C2fCIB 块使用情况
一个空间金字塔池化快 (SPPF) 块,类似于 YOLOv8 架构,位于主干最后模块之后的颈部。接下来引入了部分自注意力 (PSA) 块。PSA 将全局建模能力与自注意力机制相结合,以提高性能 [4]。为了减轻二次自注意力带来的复杂计算负担,PSA 仅在第 4 个阶段之后实施,使用最低分辨率 [4]。
如同 YOLOv8 一样,颈部内存在多个 concat 和 upsample 块。upsample 块采用最近邻上采样。有三个头。连接到块 No. 16、No. 19 和 No. 22 的头部分别用于检测小、中和大物体。
4.1.4 YOLO11
该图是基于位于 ultralytics/cfg/models/11 文件夹 [19] 的 yolo11.yaml 创建的。在 YOLO11 中存在三个变量来决定 YOLO11 变体。这些变量与 YOLOv8 中的变量相同,具体来说是 depth_multiple、width_multiple 和 max_channels。区别在于 depth_multiple 变量确定了 C3k2 块和 C2PSA 块中瓶颈或 C3k 块的数量。width_multiple 和 max_channels 变量确定输出通道数。YOLO11 的干节部分与 YOLOv8 的一致。
YOLO11 中的阶段组件采用 C3k2 块。C3k2 代表了在 YOLOv8 和 YOLOv10 中 C2f 的改进。与 C2f 相比,C3k2 参数数量更少。在 C3k2 块中,存在一个 参数,用于确定 c3k 模块的实现。如果为 True,则将使用 C3k 模块。相反,如果 为 False,它将使用与 C2f 中相同的 Bottleneck。然而,在 m、l 和 x 变体中, 的值始终为 True。这个发现不在 YOLO11 文档 [2] 中。我们是在分析源代码后发现的。由此经验可知,检查源代码对于理解 YOLO 模型的工作原理至关重要。
共有八个阶段,具体是编号为 2、4、6、8、13、16、19 和 22 的块。YOLO11 中的下采样过程采用一个核尺寸为 3 且步幅为 2 的卷积块。当使用步幅为 2 时,所得的空间分辨率将减少 50%。
在颈部,紧接脊柱末端之后,存在一个类似于YOLOv8中的SPPF(空间金字塔池化快)块。接下来是C2PSA块。类似于YOLOv10中的PSA,C2PSA采用自注意力机制,通过结合全局建模能力来提高效率。C2PSA仅位于分辨率最小的第4阶段之后。与YOLOv8和YOLOv10一样,颈部内存在多个concat和upsample块。 upsample块也使用最近邻上采样。 YOLO11的头部在功能和块数量方面与YOLOv10一致。
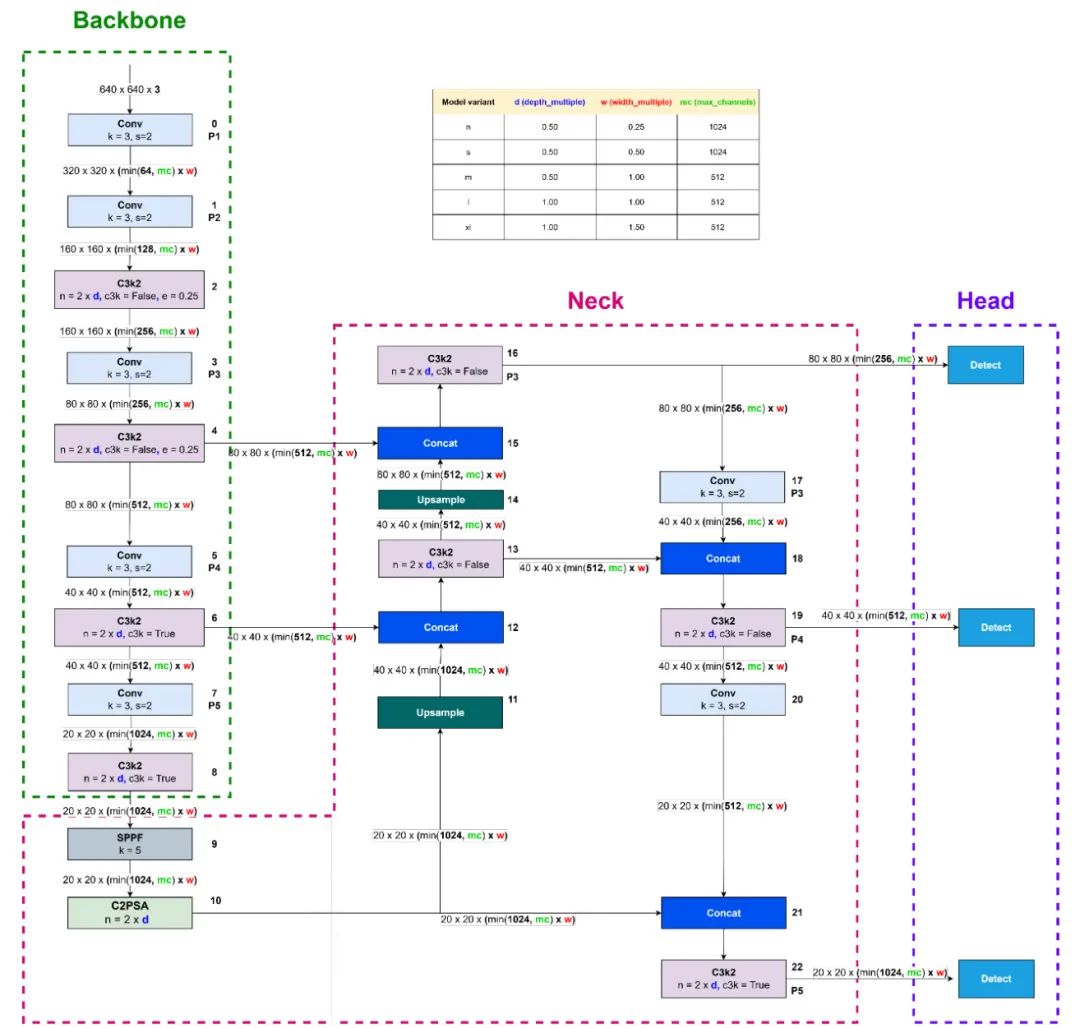
图 4:YOLO11 架构(改编自[20])
4.2 YOLO 架构块
YOLOv8 的架构块图绘制参考自[11]、[12],而 YOLOv9 到 YOLOv11 架构块图绘制参考自[16]、[18]、[20]。
4.2.1 输入图像调整大小
与 YOLOv4 及其前身不同,YOLOv8 到 YOLOv11 的输入图像将被调整大小,同时保持图像纵横比。为了保持纵横比,图像将用灰色像素填充。如果输入图像为正方形,则无需填充即可调整大小。图 5 说明了图像调整大小过程的示例。

图 5:图像调整大小 (a) 正方形图像 (b) 横向图像 (c) ritratto 图像
4.2.2 卷积(Conv)块
在本研究中所有YOLO版本中,卷积块如图6所示。它包含一个二维卷积层、二维批量归一化和SILU激活函数。它们被融合成单个卷积块。然而,YOLO11有两个新的卷积块。第一个是没有激活函数的卷积块,第二个是深度可分离卷积块(DWConv)。
PSABlock(位置敏感注意力块)中的前馈网络(FFN)使用不带激活函数的卷积块。深度可分离卷积只使用一个核对单个通道进行操作,这使得DWConv更轻量化。每个核的矩阵值都不同。
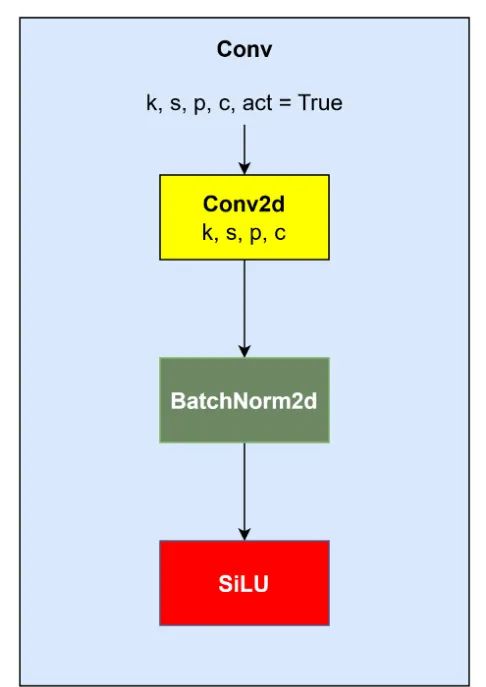
图 6:标准最近 YOLO 卷积块
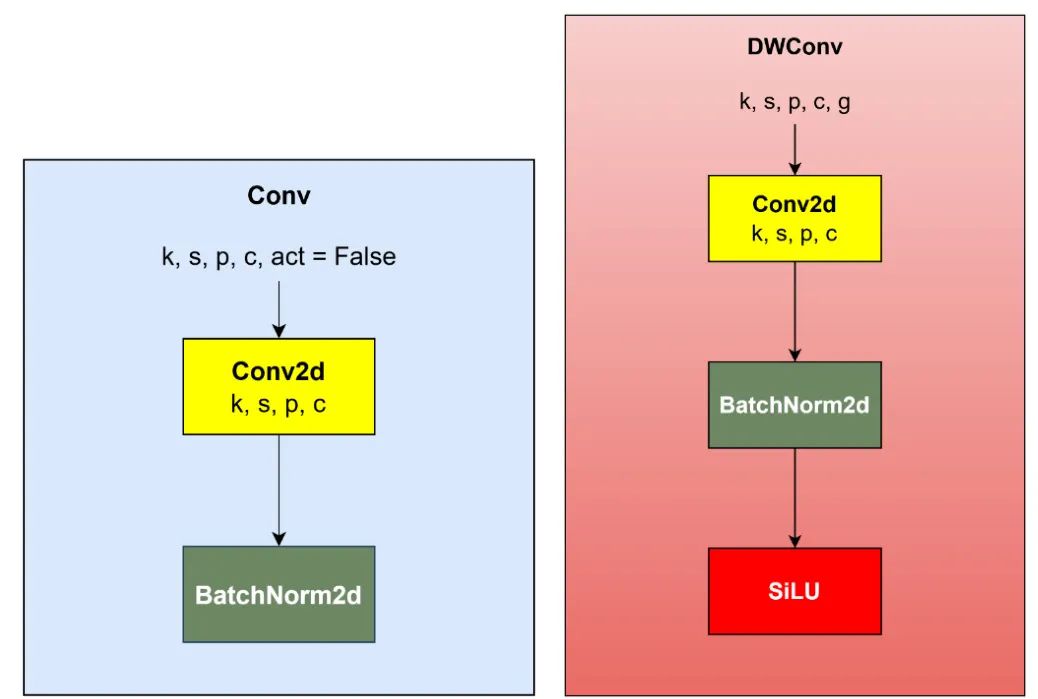
图 7:两个新的 YOLO11 卷积块
4.2.3 降采样块
YOLOv8 和 YOLO11 版本都采用典型的 卷积,步长为 2 进行下采样。然而,这种传统方法由于计算成本高和参数数量相对较多,资源消耗大且效率可能较低。
空间通道分离下采样(SCDown)将空间降采样和通道增加操作分开,用于YOLOv10。首先,使用逐点卷积 改变通道数而不会影响空间分辨率。然后,通过深度卷积(例如 )降低空间分辨率,同时不改变通道数。这种策略减少了计算成本和参数数量 [4]。图 8 是 SCDown 的示意图。
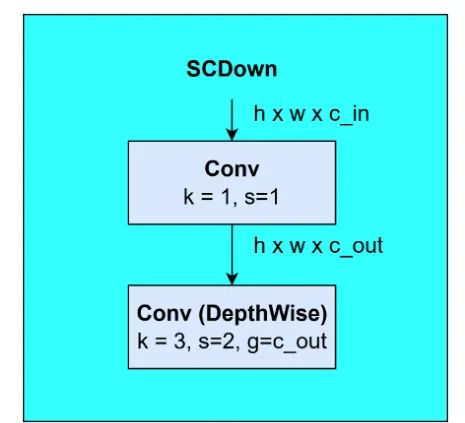
图 8:YOLOv10 中的 SCDown 块
YOLOv9 使用自适应下采样 (ADown)。该模块使用平均池化和最大池化的组合进行下采样。在 ADown 中,参数数量相对较低,因为池化不涉及任何参数。[21]。图 9 是 ADown 的示意图。
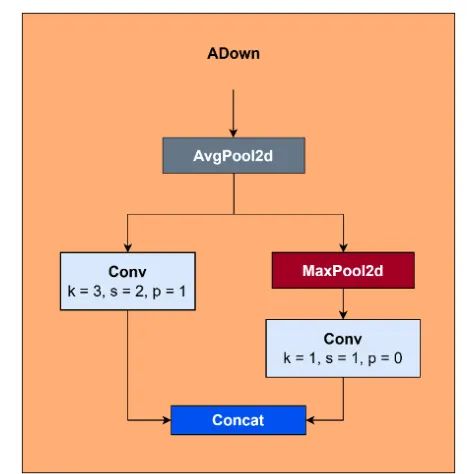
图 9:YOLOv9 中的ADown 块
4.2.4 瓶颈
瓶颈是一个类似于 Resnet 块的块。该块在 YOLOv8、YOLOv10 和 YOLO11 中可用。瓶颈通过堆叠额外的层来实现更深的网络,而计算成本增加很少。有些瓶颈使用快捷方式,而没有使用快捷方式的则如图 10 所示。
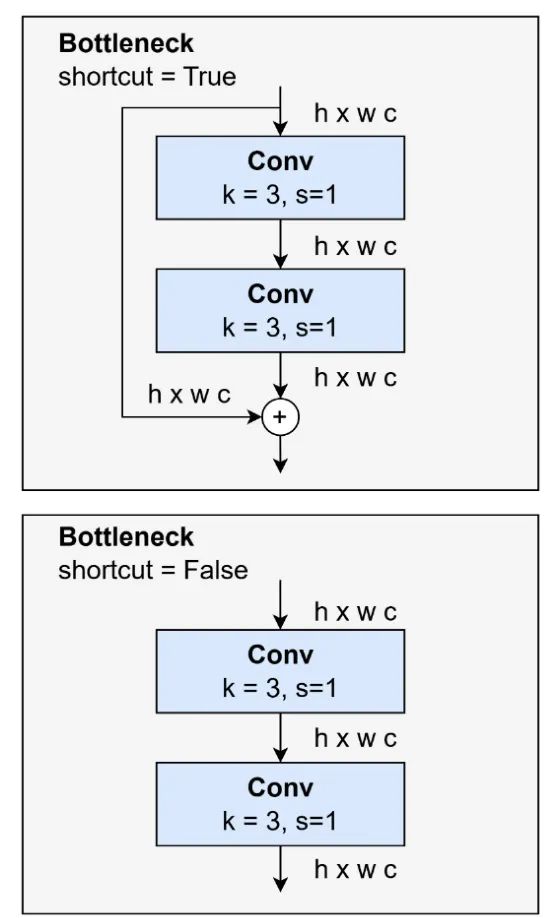
图 10:瓶颈块
4.2.5 C2f 块
C2f 是 CSP 瓶颈的更快实现,包含 2 个卷积层。C2f 用于所有阶段的特征提取。C2f 的模块可以通过使用特征向量切换和多层卷积成功学习多尺度特征并扩大感受野范围。C2f 可用于 YOLOv8 和 YOLOv10。如图 11 所示。
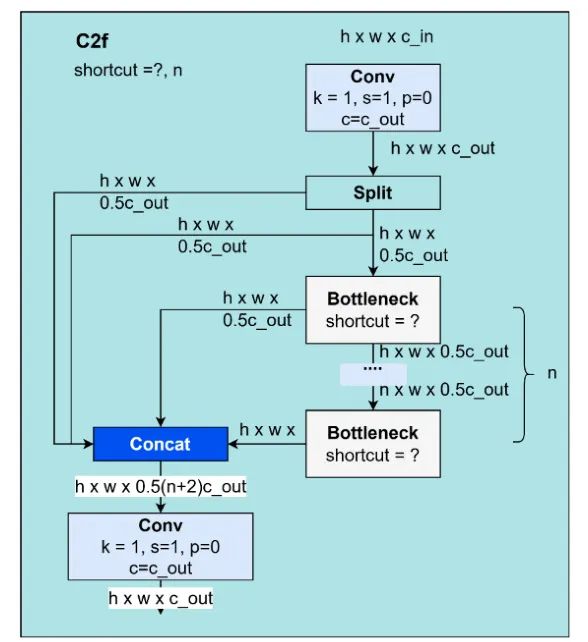
图 11:C2f 块
4.2.6 C2fCIB, CIB, RepVGGDW
除了 C2f,YOLOv10 还引入了 C2fCIB。 YOLOv10 使用了一种基于等级引导块设计的范式。 这是一种通过使用内在秩分析修改每个模型阶段基本块的复杂性来优化 YOLO 模型架构的策略。 内在秩是一个数值度量,它计算基本块最终卷积中显著奇异值的个数。
YOLO 模型和其他大型模型在深度增加时往往存在更大的冗余。 在具有显着冗余的阶段,C2f 中的瓶颈块将被 CIB(紧凑反向块)替换,形成 C2fCIB。 例如,在 YOLOv10l 版本中,C2fCIB 用于第 8、13、19 和 22 个块。 此策略提高了模型效率,即与 YOLOv8 [4] 相比,它增加了模型训练速度。 图 12 说明了 C2fCIB 块。
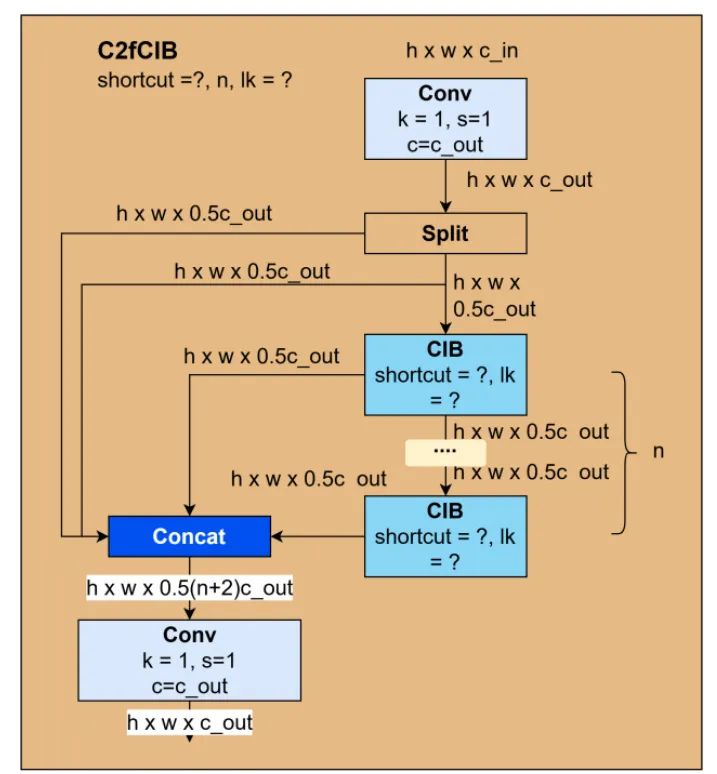
图 12:C2fCIB 块
CIB 使用深度可分离卷积。块结构为深度可分离卷积、卷积、深度可分离卷积、卷积和深度可分离卷积。一些 CIB 使用跳跃连接,而另一些则不使用。
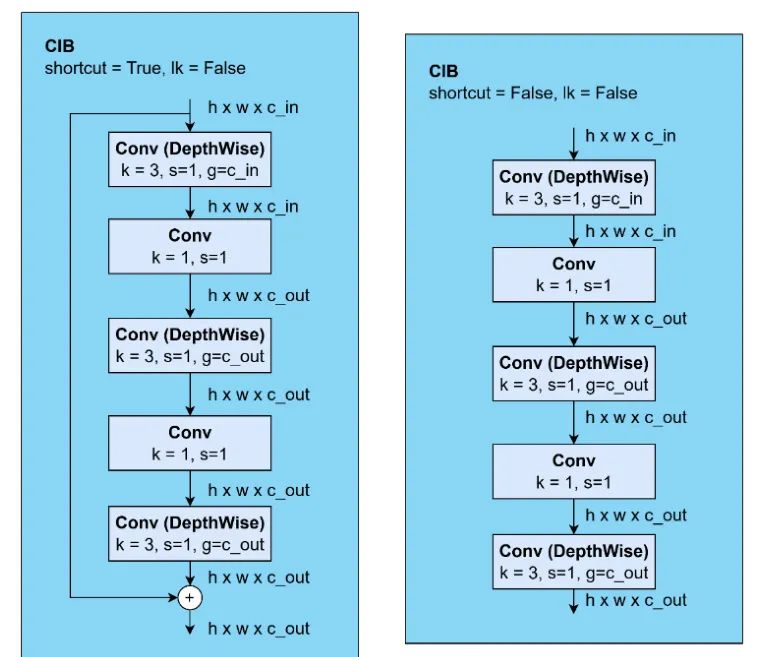
图 13:CIB 块
YOLOv10 提出了大核卷积的概念。通过这种方法,可以扩展影响卷积层神经元输出的输入区域。大核卷积仅用于模型的深层阶段。在实现中,CIB 中的第二个深度卷积被更改为 RepVGGDW。RepVGGDW 包含两个具有 3 和 7 个内核大小的深度卷积块。由于应用于更大版本时没有收益,因此大核卷积仅用于 Yolov 和 s 变体。
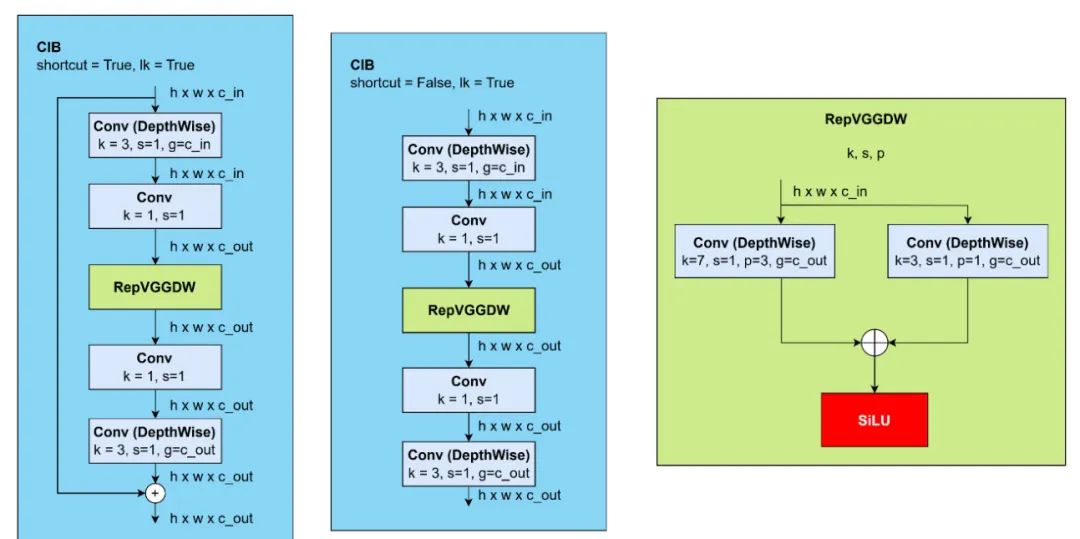
图 14:带有 RepVGGDW 的 CIB 块
这个块在 YOLO11 中全新引入。C3k2 是 YOLOv8 中 C2f 块的替代方案。C3k2 的结构与 C2f 相似。此外,第一版 C3k2 与 C2f 一致。第二版 C3k2 将瓶颈替换为一个如图 15 所示的 块。
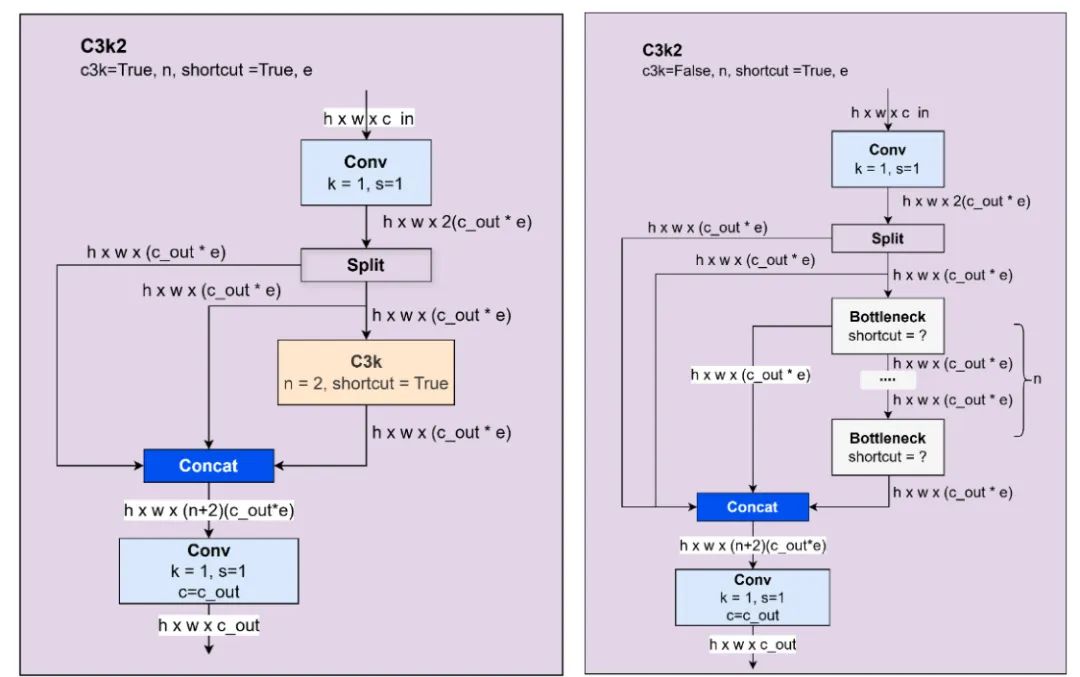
图 15:C3k2 阻断第一和第二版本
本身是一个包含 3 个卷积块和多个瓶颈的块。瓶颈有两种版本,一种带有捷径(shortcut=true),另一种没有捷径(shortcut=false)。 块有效地捕获了更复杂的特征,使其适用于不同大小的对象。 的示意图见图 16。
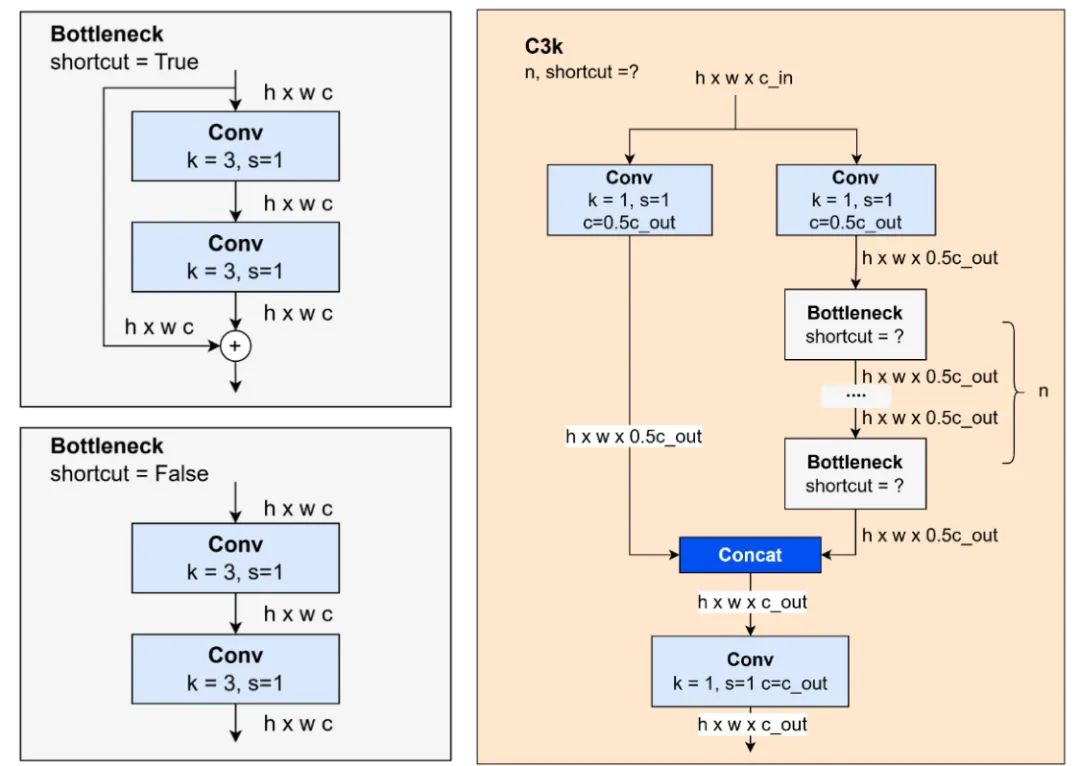
图 16:瓶颈和 C3k 块
4.2.8 SPPF & SPPELAN
空间金字塔池化——快速(SPPF)是一种块,允许特征图在多个尺度上进行表示。通过在不同尺度下进行池化,SPPF 使模型能够捕获不同抽象层次的特征。该块首先在 YOLOv8 中引入,后来被用于 YOLOv10 和 YOLO11。
SPPF 代表了一种对SPP(空间金字塔池化)的修改,该方法在YOLOv8之前的YOLO模型中可用。SPP中的最大池核大小为3、5和9。相比之下,SPPF采用5的大小内核。这种修改减少了相对于SPP的SPPF中的浮点运算(FLOP)数量。一些YOLOv9块具有类似于SPPF的结构和功能。然而,在YOLOv9中,它被称为SPPELAN。图17展示了SPPF和SPPELAN块。
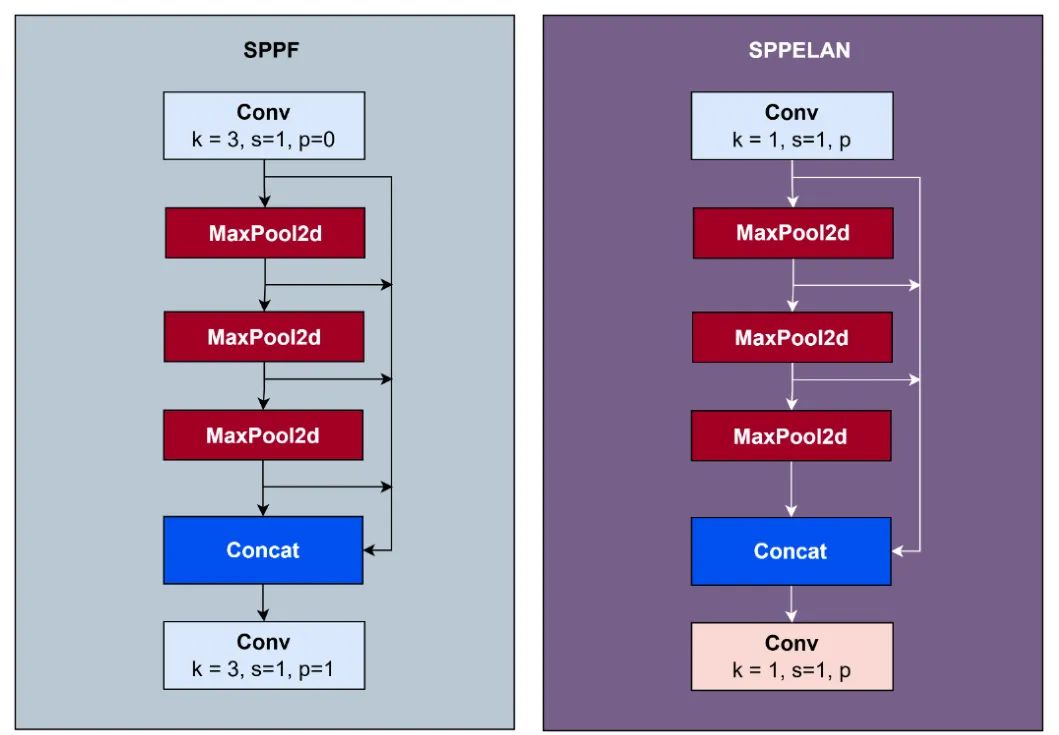
图 17:SPPF 和 SPPELAN 块
4.2.9 C2PSA & PSABlock
注意力模块用于确定图像或视频帧中像素之间的相互关系。查询、键和值构成了每个像素保留的三种参数。将对所有其他像素的键应用点积,将用于对特定像素执行查询。从点积产生的概率将用于确定哪些像素需要关注。换句话说,观察到的像素类似于这些像素。
Attention 块最初在 YOLOv10 和 YOLOv11 中引入。在 YOLOv11 中,注意力过程表示为 C2PSA。该块有两个卷积块分别位于开头和结尾。初始卷积块的结果被分割。结果的第一部分将由多个 PSABlocks 处理,以确定哪些组件需要关注。PSABlock 的结果将使用 concat 块与结果的第二部分合并。
PSABlock 包含一个注意力块和 FFN(前馈网络)。FFN 由两个连续的卷积块组成。然而,第二个卷积块不包含激活函数。
YOLOv10 同样拥有识别需要关注的图像区域的模块,称为 PSA(部分自注意力)。这个模块类似于 C2PSA;然而,它结构更简单。 它以一个卷积块开头,将结果分成两半,一半直接进入连接块,而另一半由注意力块和卷积块处理。 在块末尾,它使用一个卷积块来处理连接的结果。
YOLOv10 中的 PSA 由一个包含一个注意力层和一个前馈层的单一模块组成。C2PSA 是一个高级模块,由多个 PSA 块组成。与 PSA 相比,C2PSA 更复杂,因为它迭代执行 PSA 操作,从而捕获更深层次的特征关系。C2PSA 可以有效地捕获更深层次的特征,而不会增加时间开销,因为初始的分裂输出卷积将输入分成两个路径:快捷路径和深度处理路径。
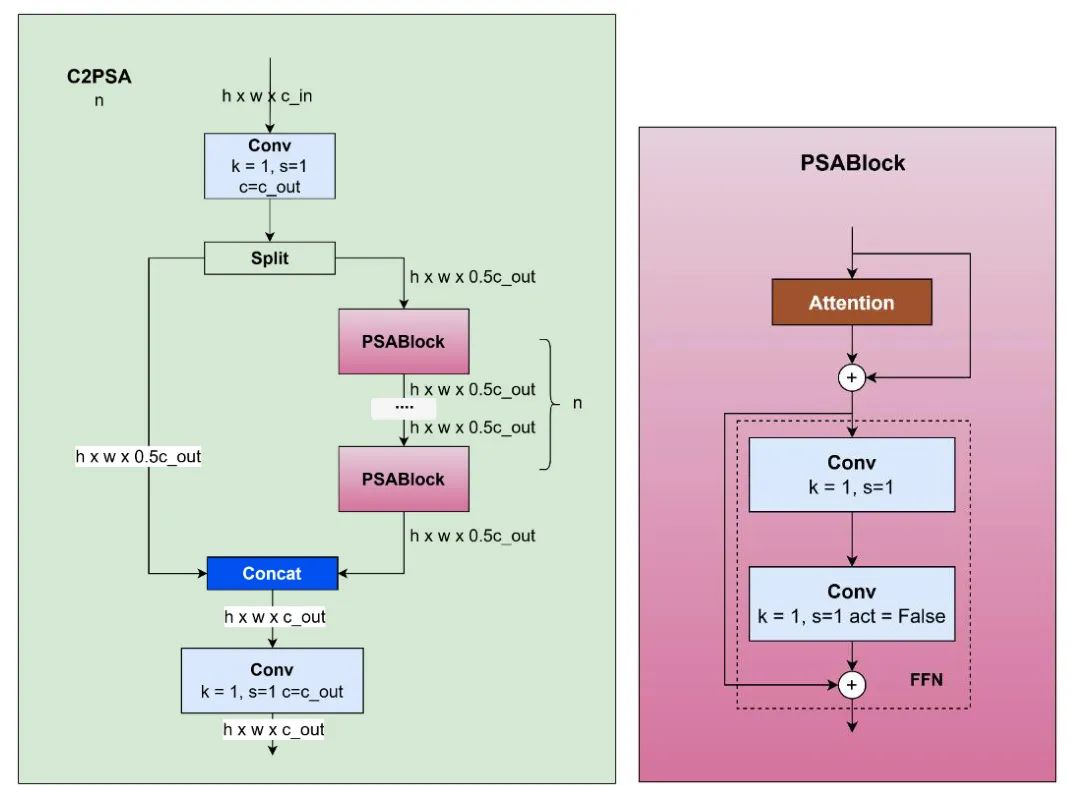
图 18:C2PSA 和注意力块
4.2.10 检测块
在 YOLOv8 和 YOLOv9 中,检测块由两个组成部分构成:分类头和回归头。分类头生成类别概率,而回归头生成边界框坐标预测。每个头都由两个卷积块组成,后面跟着一个二维卷积层。
在YOLOv10检测块中,分类头和回归头具有不同的架构。这种差异是由于计算成本的差异而造成的。分类头可能比回归头大两倍。
尽管如此,回归头在确定性能方面起着更关键的作用。因此,可以使用深度可分离卷积来优化分类头的架构,使其更加轻量化。通过这种策略,模型参数的数量减少了。图 19 说明了 YOLOv8、YOLOv9 和 YOLOv10 的 Detect 块。
YOLOv10 引入了无NMS训练的“一致双重分配”概念。该概念将一对多和一对一方法整合到模型训练中,利用一致的匹配度量。该策略在训练期间使用两个头:一个实现一对多分配以提供稳健的监督,而另一个使用一对一匹配。在推理过程中,仅使用采用一对一匹配的头,从而消除了对NMS的需求,提高了推理效率,同时没有牺牲性能。 [4]
YOLO11 的检测块使用分类头中的 depthwise 卷积,与 YOLOv10 几乎相同。然而,YOLO11 集成了一个新颖的块,即 DWConv。图 20 说明了 YOLO11 检测块。

图 19:(a) YOLOv8 和 YOLOv9 检测块 (b) YOLOv10 检测块。
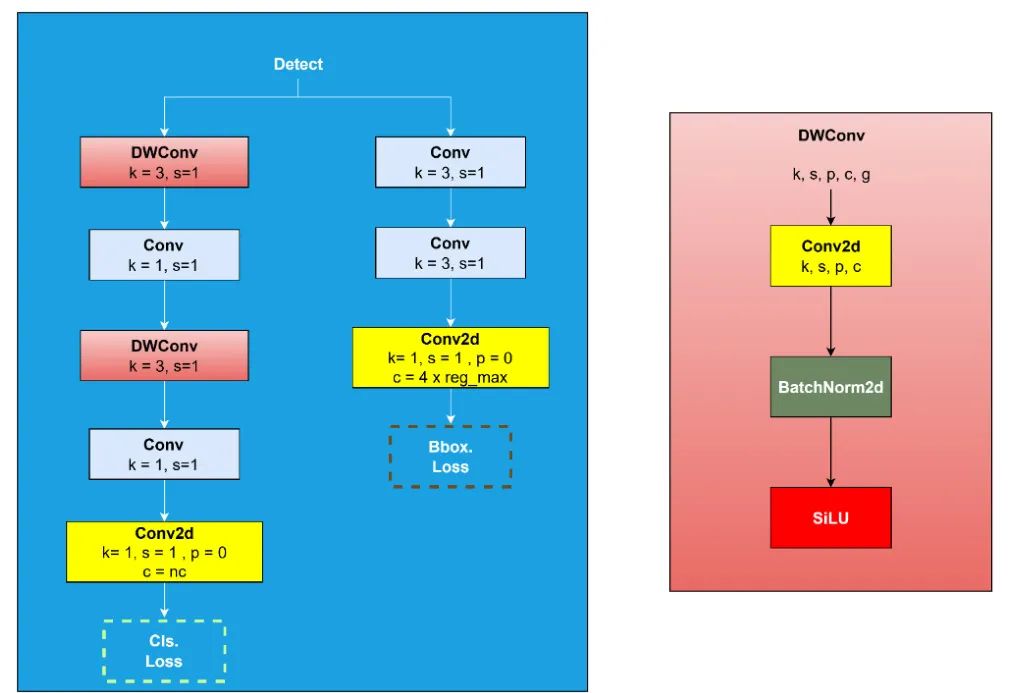
图 20:YOLO11 检测块
从上述比较可以得出表 2 所呈现的四个 YOLO 版本之间的全面比较。
表 2:YOLO 综合比较

4.3 图像处理架构示例
此插图利用YOLO11l进行演示。我们选择该模型是因为YOLO11是YOLO的最新版本,缺乏官方架构图和已发表论文。l变体因其计算比其他变体更简单而被选中。
模型采用深度倍数为 1、宽度倍数为 1 和最大通道数为 512,如表 3 所示。输入图像尺寸为 像素,包含 3 个通道。初始输入图像经过 Block 0 处理,Block 0 是一个卷积块,内核大小为 3,步幅为 2。步幅为 2 会将输出的空间分辨率降低到 。输出通道数由基准输出通道值与最大通道数的较小值乘以宽度倍数决定。在 Block 0 中,基准输出通道总数为 64,因此输出尺寸为 。该过程如图 21 所示。
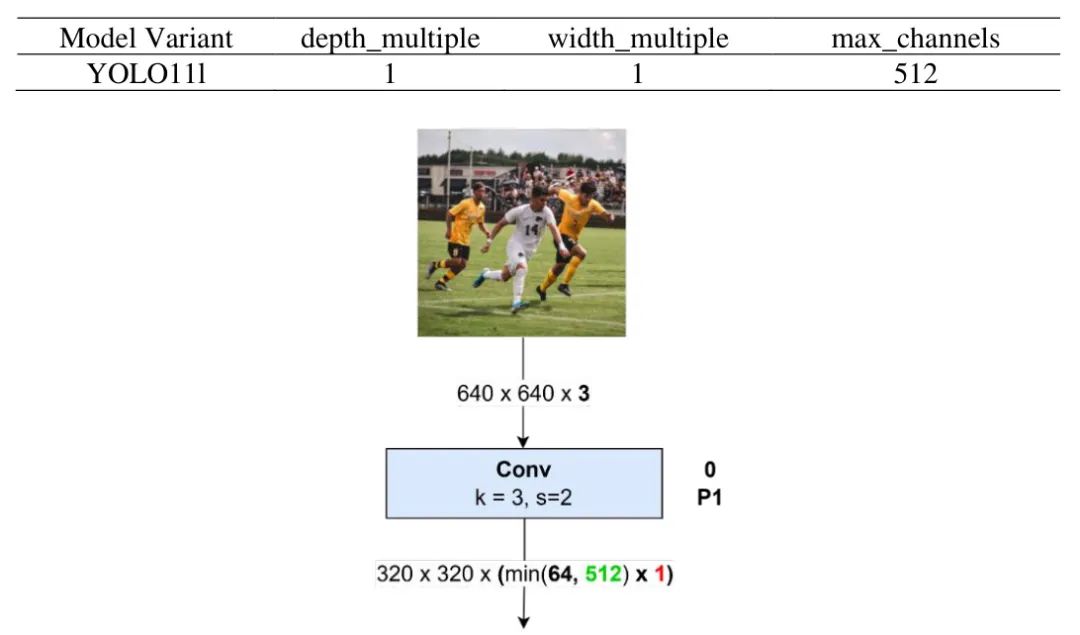
图 21:输入和块卷积 No. 0
图像随后经过 Block 1 处理,该块是一个额外的卷积块,内核大小为 3,步幅为 2。空间分辨率进一步降低到 ,通道数调整为 128。Block No. 1 的输出传输到 Block C3k2(Block No. 2)。在这个块中,进行更深层的特征提取。输出保持 的空间分辨率,而通道数增加到 256。该过程如图 22 所示。
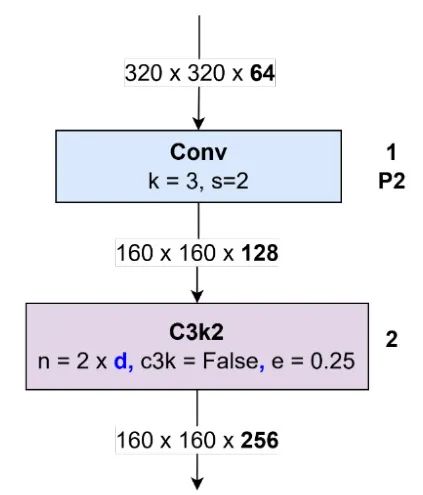
图 22:块卷积 No.1 和 C3k2 No. 2
这个过程逐渐持续到骨干网络后续的各个块,空间大小依次减小至 (块号 3)、(块号 5)和 (块号 7),具体取决于卷积层和步长的配置。此外,还有一些 C3k2 块(块号 4、6 和 8)连接到颈部部分。该过程如图 23 所示。
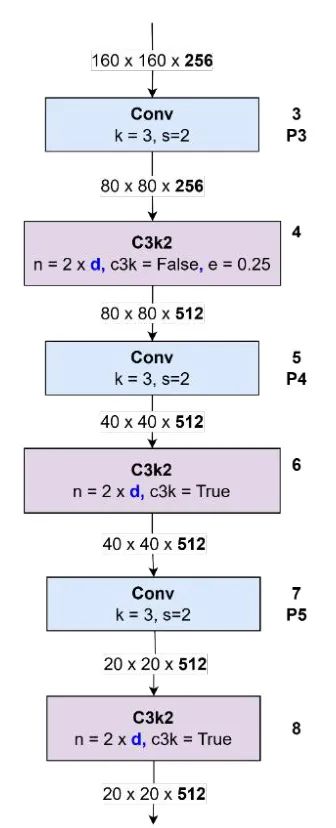
图 23:区块 No. 3 - 8
主干网络的输出,即 Block C3k2 的第 8 个块的输出,为 。该输出被传输到颈部,具体是 SPPF 块的第 9 个。输出保持为 。SPPF 提高了整合空间信息的效率。该过程如图 24 所示。
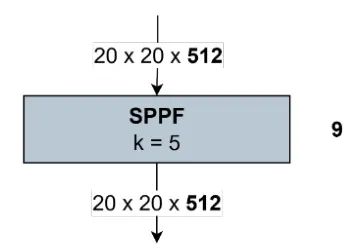
图 24:SPPF 块
随后,它继续进入 C2PSA 块 9。此块仅位于最低分辨率阶段。这样做是为了减轻自注意力复杂性带来的过量计算。该块的输出始终为 。 该过程如图 25 所示。
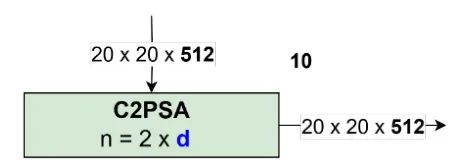
图 25:C2PSA 块
C2PSA 块的输出将被上采样到 ,然后将此特征与 C3k2 块第 6 号 的输出进行连接。在连接过程中,总通道数被聚合,而分辨率保持不变。Concat(块编号 12)的输出为 。上采样和连接的过程执行特征金字塔网络 (FPN),其目标是整合来自不同分辨率和抽象级别的特征的信息。该过程如图 26 所示。
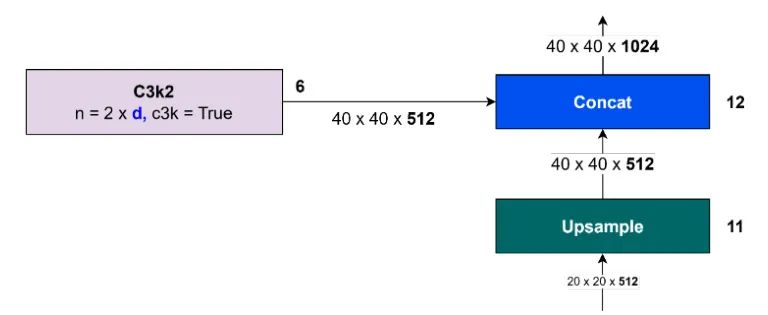
图 26:上采样和连接
过程继续到块 C3k2 No. 13,得到一个输出为 。该输出随后被上采样到 ,并将特征与来自块 C3k2 No. 4 的输出连接。第 15 号 Concat 的输出为 。该过程如图 27 所示。
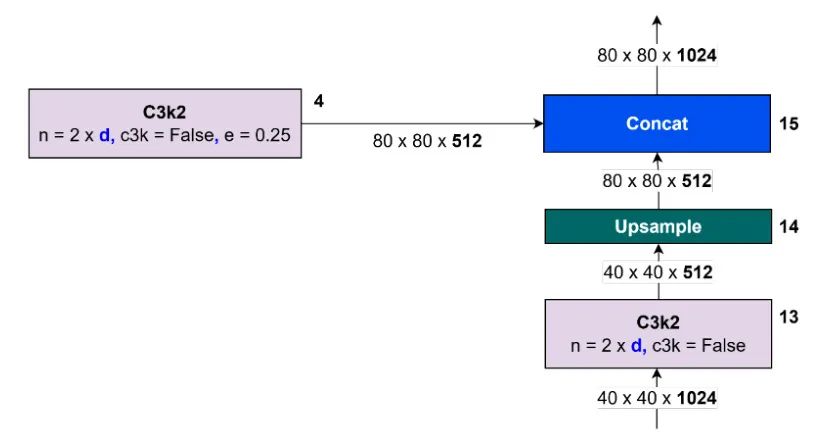
图 27:拼接块 No. 15
Concat No. 15 的输出传输到 Block C3k2 No. 16,生成一个 的特征图。该块的输出作为 Detect 块的输入,该块旨在识别图像中相对较小的物体。使用 尺寸来识别小物体,因为更高的空间分辨率保留了原始图像中的更多细节。该过程如图 28 所示。
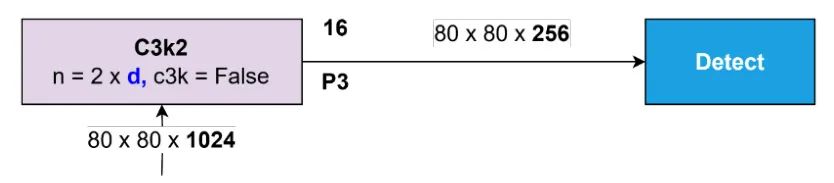
图 28:小型物体检测块
C3k2 块编号 16 的输出随后传输到 Conv 块编号 17。空间分辨率降低为 ,而通道数保持在 256。较大的物体通常占据图像中更广泛的区域。降低分辨率可以使物体的特征表示更加紧凑,从而增强模型捕获正确尺度模式的能力。Conv 块编号 17 的输出与 C3k2 块编号 14 的输出进行连接,生成尺寸为 的特征图。该过程如图 29 所示。
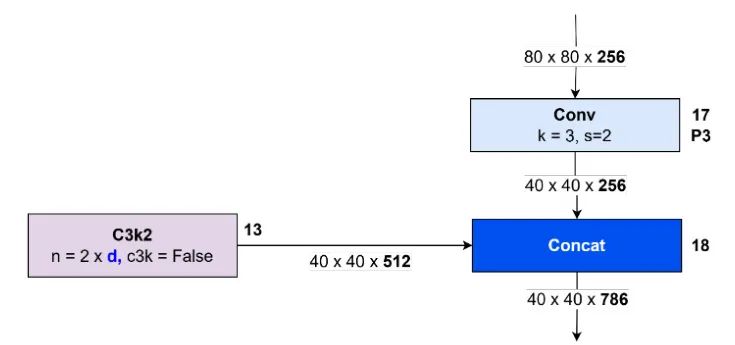
图 29:拼接块 No. 18
Concat No. 18 的输出随后传输到 Block C3k2 No. 19,生成一个 特征图。该块的输出作为 Detect 块的输入,Detect 块专门用于识别中等大小的对象。该过程如图 30 所示。
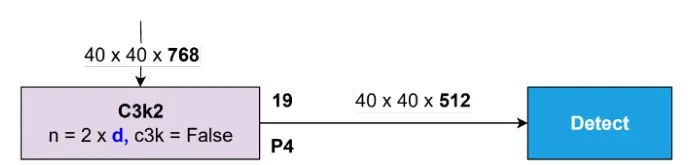
图 30:检测中等物体块
C3k2 块编号 19 的输出随后经过 Conv 块编号 20 处理,空间分辨率为 ,同时保持 512 个通道。Conv 块编号 20 的输出与 C2PSA 块编号 10 的输出进行连接,生成尺寸为 的特征图。Concat 块编号 21 的输出随后传输到 C3k2 块编号 22,生成尺寸为 的特征图。该块的输出作为 Detect 块的输入,该块专门用于识别大型物体。整个过程如图 31 所示。
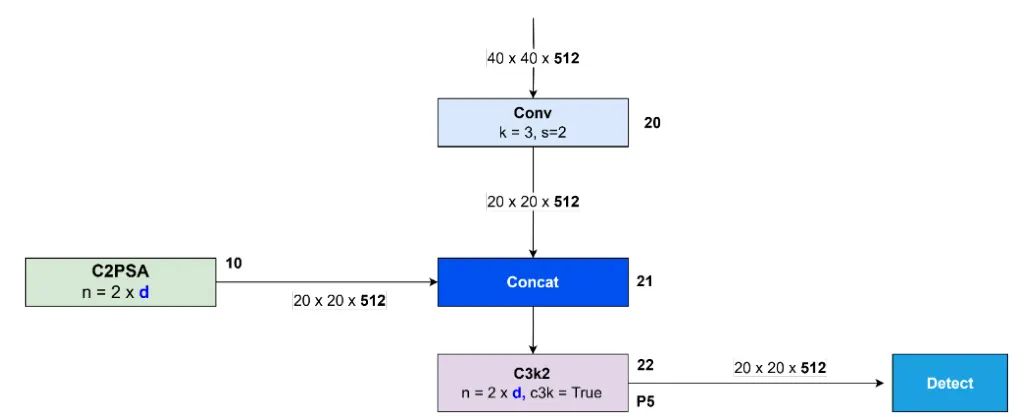
图 31:大对象检测块
5 结论
我们的深入全面分析表明,每个版本在架构和特征提取方面都表现出改进和精细化。然而,我们发现某些架构块与前一个版本相同。缺乏学术出版物和官方架构图对于研究人员和从业者理解模型功能提出了挑战。这个问题也给未来的模型增强带来了挑战。
我们还发现 YOLO 存在一种进化趋势,从 YOLOv10 开始引入注意力层。我们敦促未来的 YOLO 开发者提供架构图和学术出版物,以加速研究人员、从业者和开发人员对模型的理解,并促进其未来性能的提升。


















 5112
5112

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









