







目录
论文地址:
https://www.semanticscholar.org/reader/adccc00dbd0fe63e4e34bc3445a29bc2ec910cbc
代码地址:https://github.com/ultralytics/ultralytics
YOLOv11 网络结构
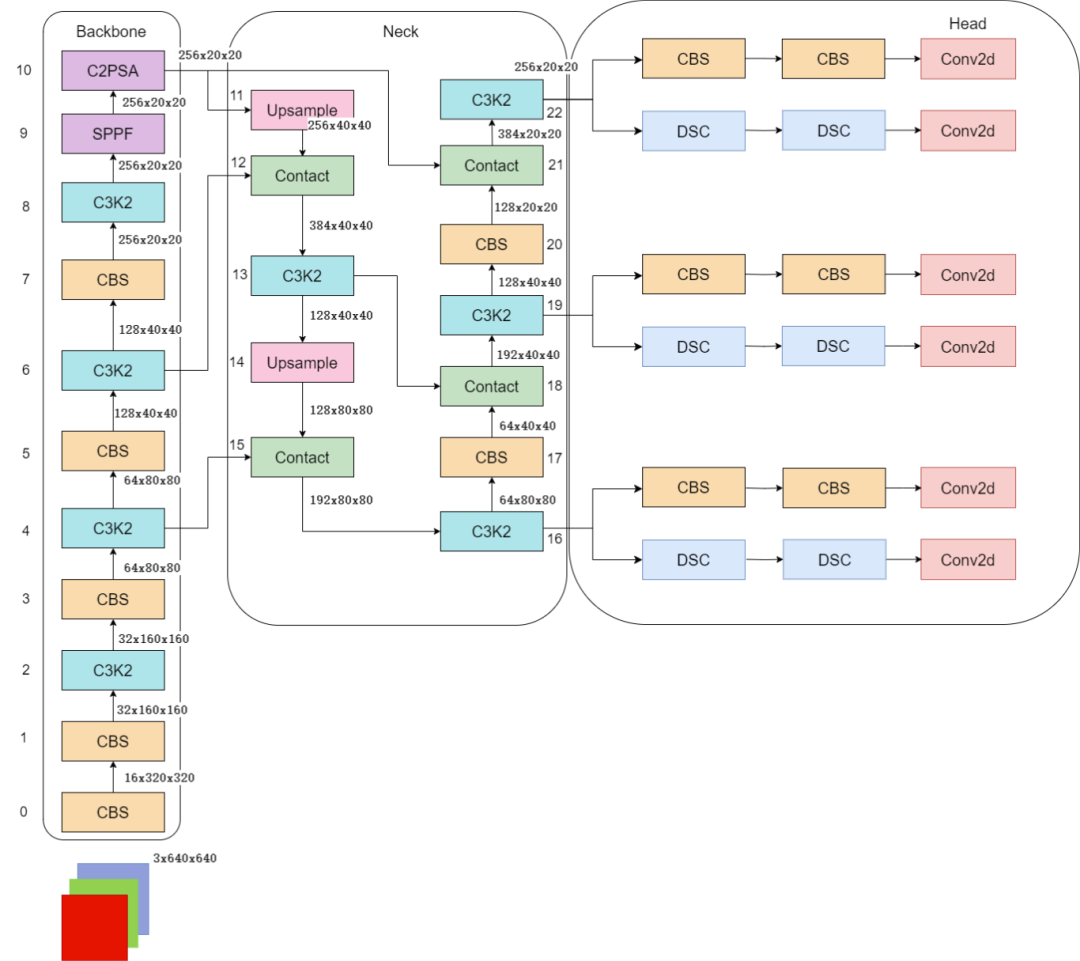
YOLO11采用改进的骨干和颈部架构,增强了特征提取能力,提高了物体检测的精确度和复杂任务的表现。相比较于YOLOv8模型,其将CF2模块改成C3K2,同时在SPPF模块后面添加了一个C2PSA模块,且将YOLOv10的head思想引入到YOLO11的head中,使用深度可分离的方法,减少冗余计算,提高效率。
-
主干网络(Backbone)
-
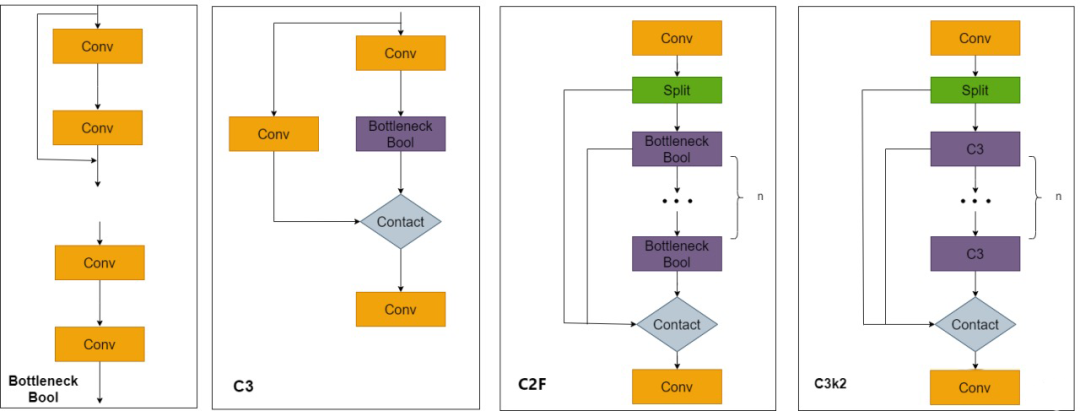
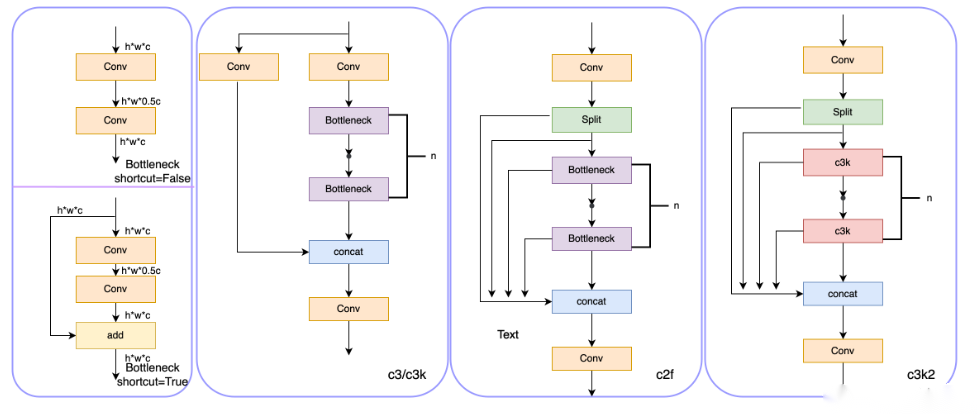
YOLO1增加了一个C2PSA模块,并且将C2f替换为了C3k2。相比于C2f,当超参数c3k=True时,瓶颈块替换为 C3k,否则还是C2f,而C3k相比于C3则是可以让使用者自定义卷积块大小,更加灵活。C2PSA扩展了C2f,通过引入PSA( Position-Sensitive Attention),旨在通过多头注意力机制和前馈神经网络来增强特征提取能力。它可以选择性地添加残差结构(shortcut)以优化梯度传播和网络训练效果。同时,使用FFN 可以将输入特征映射到更高维的空间,捕获输入特征的复杂非线性关系,允许模型学习更丰富的特征表示。
-
颈部网络(Neck)
-
YOLO11使用PAN结构,并在其中也使用了C3K2模块。这种结构设计有助于聚合来自不同尺度的特征,并优化特征的传递过程。C3K2模块其实就是C2F模块转变出来的,它代码中有一个设置,就是当c3k这个参数为FALSE的时候,C3K2模块就是C2F模块,也就是说它的Bottleneck是普通的Bottleneck;反之当它为true的时候,将Bottleneck模块替换成C3模块。
-
头部网络(Head)

YOLOv11 有哪些新特性?
2024年9月30日,Ultralytics在他们的YOLOVision活动上正式发布了YOLOv11。YOLOv11是由位于美国和西班牙的Ultralytics团队开发的YOLO模型的最新迭代版本。YOLOv11带来了大量改进,包括但不限于以下几点:
-
模型架构的增强:模型的架构经过优化,更好地处理输入图像并进行预测。通过改进的架构,模型在图像处理和推理阶段表现更加高效。
-
GPU优化:符合现代机器学习模型的趋势,YOLOv11在GPU上进行了优化训练。与之前版本相比,GPU训练不仅提高了模型的训练速度,还显著提升了模型的精度。
-
速度提升:没错,速度是YOLOv11的一大亮点。通过GPU优化和架构改进,YOLOv11的训练和推理速度比以往版本快得多,延迟减少高达25%。
-
参数减少:模型参数的减少使得YOLOv11运行更加高效,速度更快,同时保持高精度,几乎不影响准确性。
-
更强的适应性和更多支持任务:YOLOv11支持更多类型的任务、更多种类的目标检测和处理更多不同类型的图像。这使得YOLOv11的应用场景更加广泛,几乎可以胜任任何图像识别任务。
YOLOv11 提供了多个模型,涵盖了以下功能:
- 目标检测:经过训练后,能够检测图像中的目标物体。
- 图像分割:不仅能够进行目标检测,还能将图像中的物体进行精确分割。
- 姿态估计:通过训练后可以绘制人体姿态,使用点和线来标识关节和肢体。
- 旋转边界框(OBB):与目标检测类似,但边界框可以进行旋转,适用于具有方向性的物体检测。
- 图像分类:经过训练后能够对图像进行类别分类。
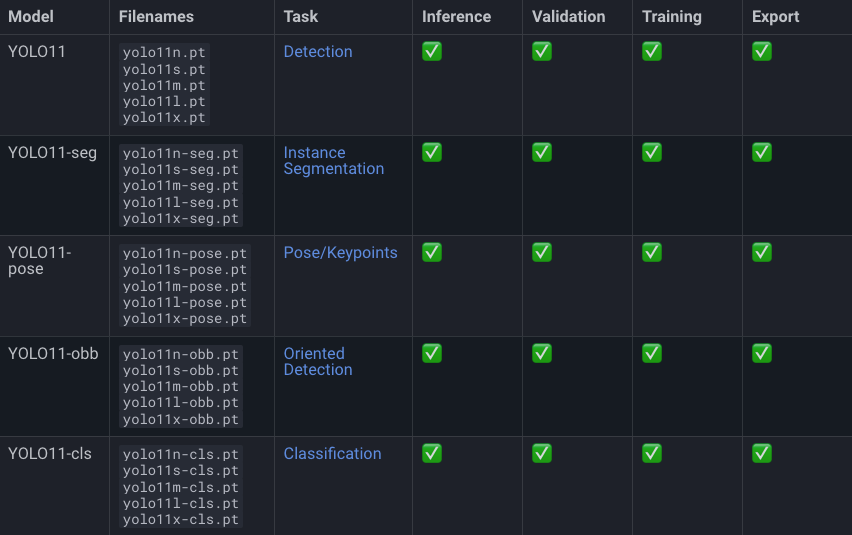
YOLOv11包含哪些模型?
YOLOv11包括以下模型:
- 边界框检测模型(无后缀)
- 实例分割模型(后缀 -seg)
- 姿态估计模型(后缀 -pose)
- 旋转边界框模型(后缀 -obb)
- 图像分类模型(后缀 -cls)
这些模型还分为不同的尺寸版本:Nano (n)、Small (s)、Medium (m)、Large (l)、Extra-Large (x)。
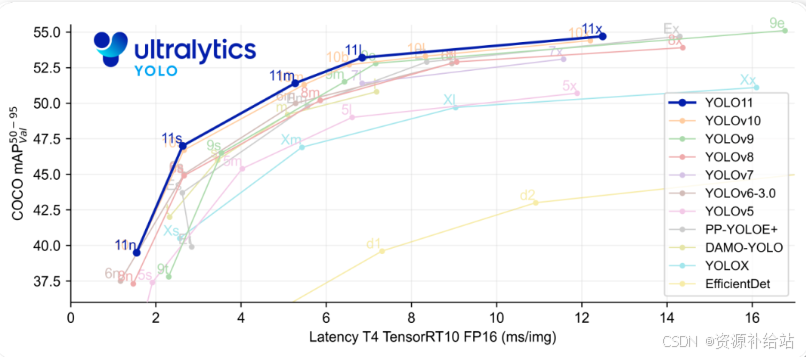
YOLOv11 的性能数据
目标检测:
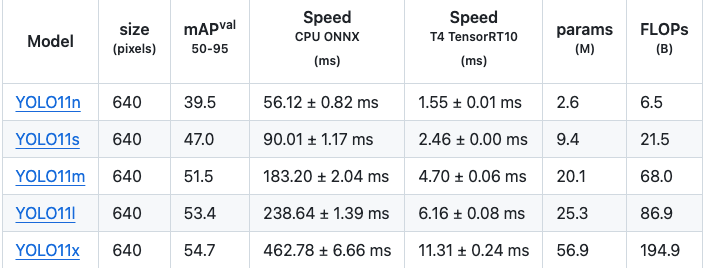
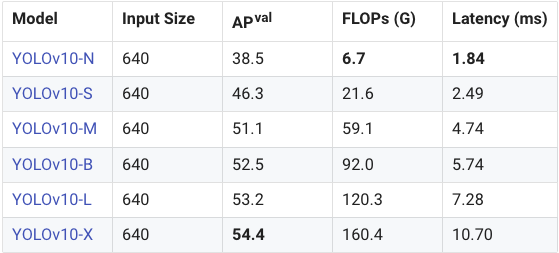
从数据来看,Nano 模型在 YOLOv11 上的 mAPval 为 39.5,而在 YOLOv10 上也是 39.5;Small 模型分别为 47.0 对 46.8;Medium 模型是 51.5 对 51.3;Large 模型在两个版本中均为 53.4;Extra Large 模型为 54.7 对 54.4。这些看似细微的提升,尤其是 mAPval 上的小数点增长,在机器学习模型中往往能带来显著的性能提升。总的来说,YOLOv11 在 mAPval 上超越了 YOLOv10 约 0.3。
接下来我们来看看速度。在延迟方面,Nano 模型在 YOLOv11 上的延迟为 1.55,而在 YOLOv10 上是 1.84;Small 模型分别为 2.46 对 2.49;Medium 模型是 4.70 对 4.74;Large 模型为 6.16 对 7.28;而 Extra Large 模型则为 11.31 对 10.70。延迟越低越好,除了 Extra Large 模型表现稍差之外,YOLOv11 其他尺寸的延迟都比前代低。
总体而言,Nano 模型在速度方面表现极佳,同时性能相当。而 Extra Large 模型尽管性能有所提升,但延迟表现不佳。
图像分割:
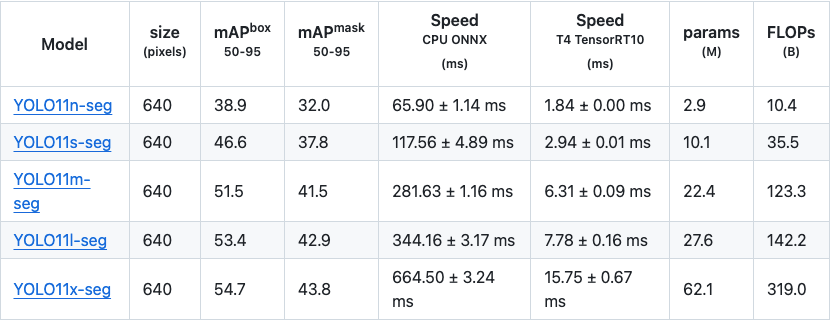
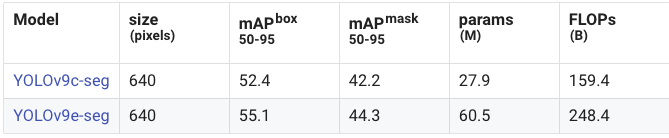
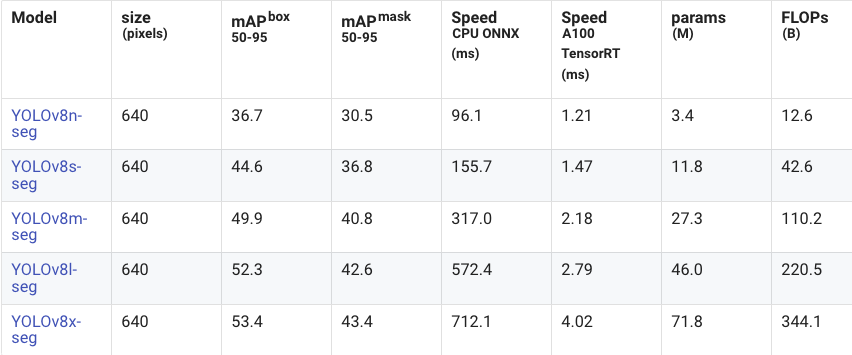
总的来看,YOLOv11 的图像分割模型在 Large 和 Extra Large 模型上相比之前的 YOLOv8 和 YOLOv9 表现更优。YOLOv9 并没有提供延迟方面的统计数据,而 YOLOv11 相比 YOLOv8 的延迟大幅降低。YOLOv11 还引入了大量的 GPU 优化,因此在 CPU 测试的基准之外,GPU 上的速度预计会更快。
姿态估计:
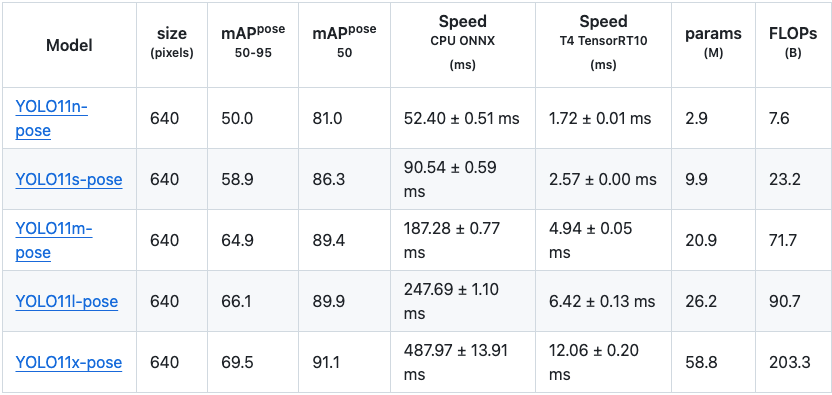
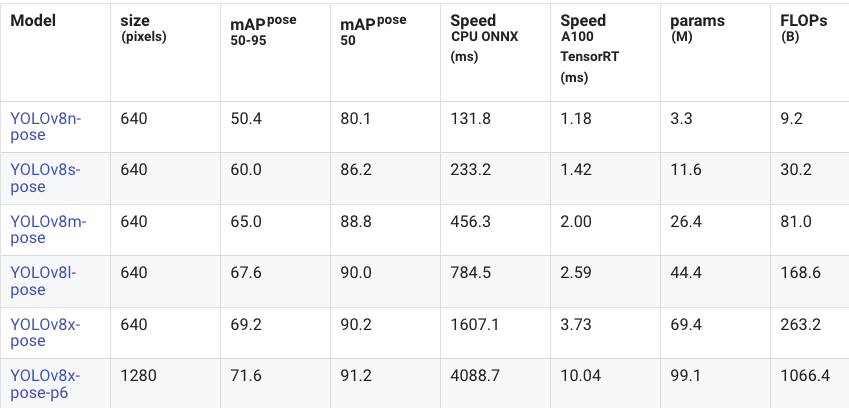
YOLOv11 在 mAP50–95 的统计数据上较 YOLOv8 有小幅提升(Large 模型除外)。然而在速度方面,YOLOv11 的姿态估计模型在延迟上有显著改善,某些延迟数据甚至是前代的四分之一!由于这些模型是针对 GPU 训练优化的,因此预计实际性能会比展示的数据更好。
旋转边界框:
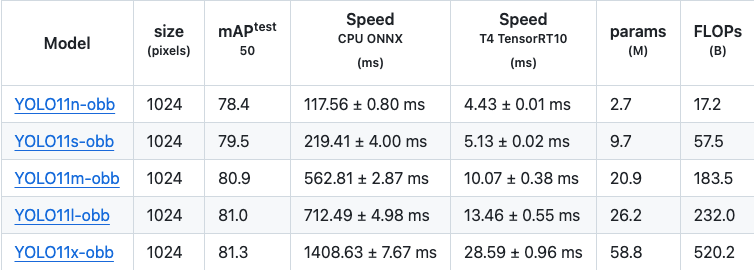
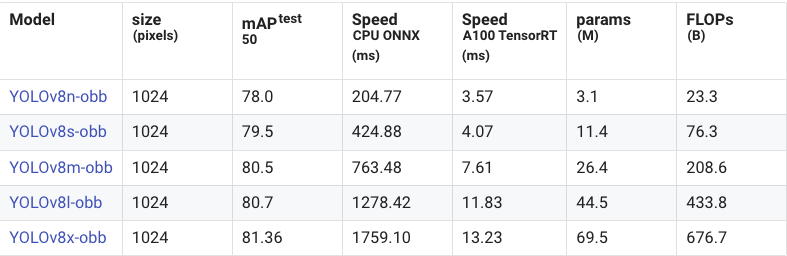
在 mAP50 的统计数据上,旋转边界框模型的提升相对较小,甚至比目标检测的细微改进还要少。然而,YOLOv11 在速度上却提升了一倍,显示出 YOLOv11 为提升速度做出了巨大努力。
图像分类:
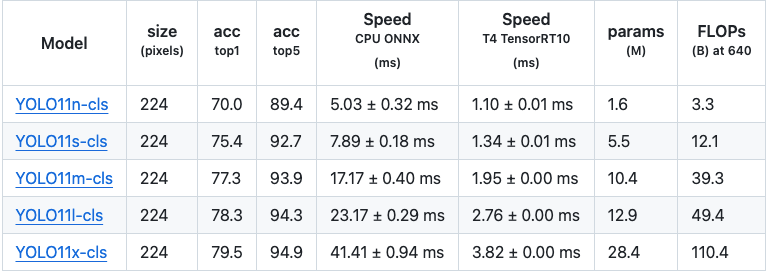
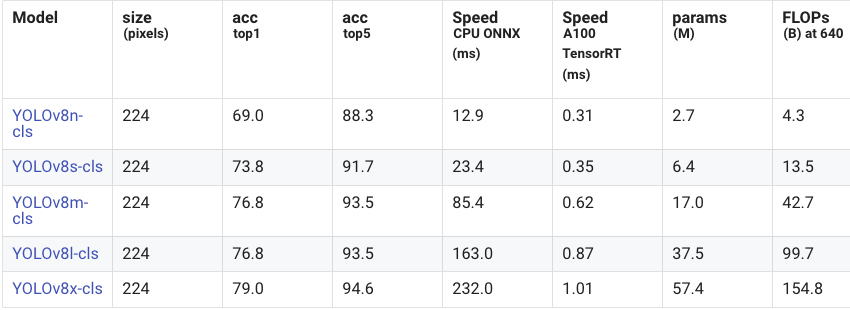
在精度上,从 YOLOv8 到 YOLOv11 的改进微乎其微,但在速度上,YOLOv11 模型在 CPU 上的表现有了巨大的提升。
YOLOv8 vs YOLOv11: 各模型性能比较
用于比较的关键指标
-
**模型版本(n、s、m、l、x):
Ultralytics 开发的 YOLO 模型有不同的尺寸,即纳米(n)、小(s)、中(m)、大(l)和超大(x)。较大的模型往往更复杂、更强大,但它们也需要更多资源并且运行速度较慢。**
-
mAP(平均精度):
mAP分数告诉我们模型检测物体的准确度。*计算基于模型识别与图像中实际物体不同重叠度的物体的能力。平均精度 (mAP) 越高,表示模型的准确度越高,表明其检测和准确定位图像中物体的能力越强。* -
速度(以毫秒为单位):
速度告诉我们模型处理图像的速度。速度有两种类型,
*CPU 速度:这衡量了它在普通计算机处理器 (CPU) 上的运行速度;
GPU 速度:这衡量了它在特定 NVIDIA GPU(例如 A100 或 T4)上的运行速度,这些 GPU 通常用于高性能 AI 任务。* -
Params(M):
表示特定模型的参数数量(以百万为单位)。模型越大,参数越多。 -
FLOPs(B):
FLOPs(浮点运算)表示模型的计算复杂度。FLOP 越高,表示模型需要的计算资源越多。*以十亿为单位。*
YOLOv8n 与 YOLOv11n:
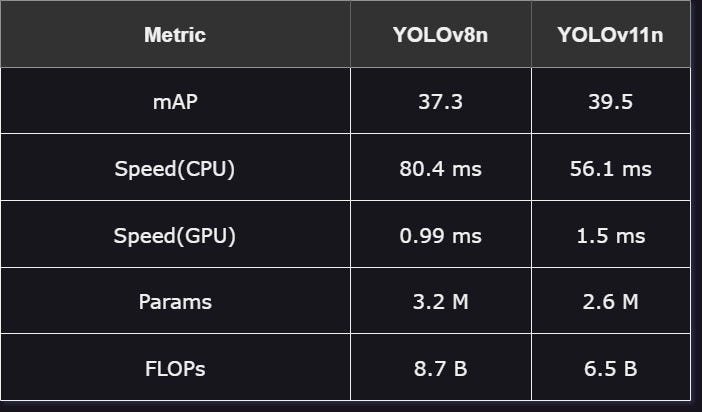
最小、最快、参数最少的模型:
-
性能:YOLOv11n 在精度上超越了 YOLOv8n,平均精度(mAP)为 39.5,而 YOLOv8n 为 37.3,表明 YOLOv11n 在图像中的目标检测能力更强。
-
速度:在标准 CPU 上,YOLOv11n 的运行速度更快,延迟为 56.1 毫秒,但在高性能 GPU 上则略微较慢。
-
效率:YOLOv11n 在保持较高精度的同时,使用了更少的参数和更低的浮点运算次数(FLOPs),展现出比 YOLOv8n 更高的效率。
YOLOv8s 与 YOLOv11s:
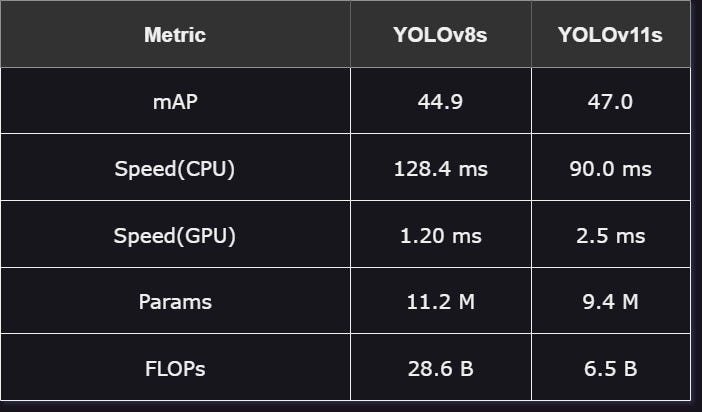
这些模型稍大,旨在平衡速度和精度:
-
性能:YOLOv11s 在精度方面优于 YOLOv8s,平均精度(mAP)为 47.0,而 YOLOv8s 为 44.9,因此在需要高精度的场景下,YOLOv11s 是更好的选择。
-
速度:YOLOv11s 在 CPU 上表现出色,而 YOLOv8s 则在诸如 A100 等高性能 GPU 上表现更快。
-
效率:由于 YOLOv11s 的参数数量更少且计算需求更低,它能够以较少的计算资源提供更高的精度,展示出更高的效率。
YOLOv8m 与 YOLOv11m

中型模型在小型和大型版本之间提供了折衷选择:
-
性能:YOLOv11m 在精度上相比 YOLOv8m 有轻微的提升。
-
速度:YOLOv11m 在 CPU 上的运行速度更快,但在 GPU 上的表现较慢,这可能会影响其在特定应用中的表现。
-
效率:YOLOv11m 使用了较少的参数和浮点运算次数(FLOPs),同时保持了更高的精度,突显了其在任务管理中的高效性。
YOLOv8l 与 YOLOv11l
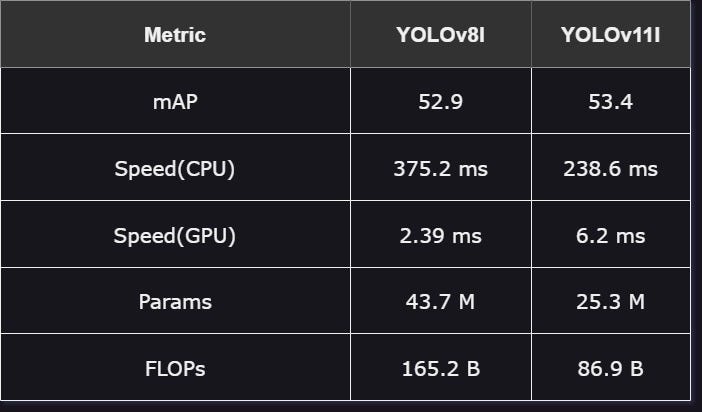
这些大型模型专为需要精度优先于速度的任务而设计:
-
性能:尽管精度差异较小,YOLOv11l 仍保持着轻微的优势。
-
速度:YOLOv11l 在 CPU 上表现更快,但在 GPU 上的速度明显较慢。
-
效率:YOLOv11l 在资源消耗更少的情况下取得了更好的结果,拥有更少的参数和浮点运算次数(FLOPs),仍然超越了 YOLOv8l。
YOLOv8x 与 YOLOv11x

超大型模型是最为精确的,但也消耗最多的资源:
-
性能:YOLOv11x 的精度略微超越了 YOLOv8x,尽管优势不大。
-
速度:YOLOv11x 在 CPU 和 GPU 上的表现较慢,优先考虑精度而非速度。
-
效率:YOLOv11x 在完成相同任务时消耗了更少的资源,使用显著更少的浮点运算次数(FLOPs)和参数,同时实现了更高的精度。
总结
YOLO11算法提高了检测精度和效率。在有很多物体的视频中,YOLO11的检测效果更好,甚至可以检测到领带等细小物品。
-
网络结构与性能提升
YOLO11通过引入C3K2、C2PSA等模块,增强了特征提取能力,提高了检测精度。同时,采用深度可分离卷积等方法优化计算效率,实现了更快的处理速度和更高的性能。这使得YOLO11在多种计算机视觉任务中表现出色,尤其在复杂场景中更具优势。
-
算法改进与任务扩展
YOLO11在算法层面进行了多项优化,包括增强的特征提取、优化的训练流程等,进一步提升了模型的准确性和效率。此外,它还支持多种计算机视觉任务,如实例分割、图像分类等,满足了更广泛的应用需求。
-
灵活部署与广泛应用
YOLO11具有良好的环境适应性,可以在边缘设备、云平台等多种环境中部署。其高效的计算性能和广泛的应用场景,使得YOLO11成为实时目标检测领域的佼佼者,为科研和商业应用提供了有力支持。


















 5617
5617

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









