







梯度下降
1 激活函数
神经网络隐藏层常用的激活函数有三种:sigmoid、tanh、relu,输出层的激活函数,后面会介绍
import torch
from torch.nn import functional as F
z = torch.linspace(-1, 1, 6)
print(z)
a1 = torch.sigmoid(z)
a2 = torch.tanh(z)
a3 = F.relu(z) # 也可以用torch.relu(z)
print(a1)
print(a2)
print(a3)
'''激活函数可以用torch里面的,也可以用F中的,但建议使用torch,
因为用torch或者torch.nn代替F是趋势'''
输出
tensor([-1.0000, -0.6000, -0.2000, 0.2000, 0.6000, 1.0000])
tensor([0.2689, 0.3543, 0.4502, 0.5498, 0.6457, 0.7311])
tensor([-0.7616, -0.5370, -0.1974, 0.1974, 0.5370, 0.7616])
tensor([0.0000, 0.0000, 0.0000, 0.2000, 0.6000, 1.0000])
2 梯度与自动求导
(1)梯度(导数)
梯度其实就是导数,如果y = x1w1 + x2w2 + x3*w3 + b,若X=[x1,x2,x3],X是一个向量,那么y对X的梯度就是
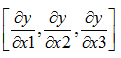
这也是一个向量。
(2)通过torch.autograd.grad获得梯度
pytorch中自动求导有三个步骤:1 对需要求导的变量,告诉系统其需要导数信息,2 绘制计算图(即计算过程), 3 求导
自动求导有下面两种方式,下面是第一种的程序
import torch
x = torch.arange(3).float()
w = torch.tensor([2, 1, 3.])
print('x=')
print(x)
print('w=')
print(w)
print('----------------------第1步-----------------------')
'''如果x需要求导,那就对其调用requires_grad_()函数,
使其requires_grad=True,告诉系统,这个变量需要导数信息
可以对比一下设置前后x的变化'''
x.requires_grad_() # 两个下划线
print('调用x.requires_grad_()后,x=')
print(x)
print('----------------------第2步-----------------------')
'''绘制计算图'''
y = x @ w
print('y=')
print(y)
print('----------------------第3步-----------------------')
'''求导,调用torch.autograd.grad(因变量,自变量)
这里的自变量,必须指定requires_grad为True'''
dx = torch.autograd.grad(y, x) # y对x求导,返回的是导数组成的张量
print('dx=')
print(dx)
print('-----------------同时对x和w求导---------------------')
'''如果说,我还想求 y 对 w 的导数,也要设定w的requires_grad'''
w.requires_grad_()
'''如果有自变量的requires_grad被更新第,那么必须重新绘制计算图,
否则报错'''
y = x @ w
'''求导,这里可以同时对x和y求导'''
dx, dw = torch.autograd.grad(y, [x, w]) # 将x和w封装成列表或元组
print('dx=')
print(dx)
print('dw=')
print(dw)
输出
x=
tensor([0., 1., 2.])
w=
tensor([2., 1., 3.])
----------------------第1步-----------------------
调用x.requires_grad_()后,x=
tensor([0., 1., 2.], requires_grad=True)
----------------------第2步-----------------------
y=
tensor(7., grad_fn=<DotBackward>)
----------------------第3步-----------------------
dx=
(tensor([2., 1., 3.]),)
-----------------同时对x和w求导---------------------
dx=
tensor([2., 1., 3.])
dw=
tensor([0., 1., 2.])
上面的程序段中,如果也可以在初始化的时候,指定x的requires_grad,
x = torch.tensor([0., 1., 2.], requires_grad=True)
(3)通过反向传播,将梯度复制到需要求导的变量上
第二种求导方法比上面的稍微简单一点,只需要在绘制计算图之前,把需要梯度信息的变量的requires_grad设为True,最后统一调用backword函数,就可以把整个计算图中的梯度给求出来。
import torch
'''除了可以用autograd.grad()来求导之外,还有一种函数,也能实现自动求导'''
'''将需要导数信息的张量,指定其requires_grad=True'''
# 张量初始化时指定其requires_grad=True
x = torch.tensor([0, 1., 2.], requires_grad=True)
# 通过requires_grad_()方法设定其requires_grad=True
w = torch.tensor([2, 1, 3.])
w.requires_grad_()
print("x=")
print(x)
print("w=")
print(w)
'''建图'''
y = x @ w
'''求导'''
y.backward()
'''backward并没有返回功能,它是将求导的结果直接赋值到变量的属性上面'''
print("w.grad")
print(w.grad)
print("x.grad")
print(x.grad)
输出
x=
tensor([0., 1., 2.], requires_grad=True)
w=
tensor([2., 1., 3.], requires_grad=True)
w.grad
tensor([0., 1., 2.])
x.grad
tensor([2., 1., 3.])
有时可以用w.grad.norm()来查看梯度的范数
(4) 保留计算图
无论用哪种方法求导,如果求导的时候没有设置retain_graph,那么获得导数之后,计算图将被清除,也就是说,无法再次通过autograd.grad和backward获得梯度。
有两种方法可以再次通过autograd.grad和backward求导,一种是重新绘制计算图,另外一种是指定retain_graph=True。
当在求导的时候,如果指定retain_graph=True,例如:
dx = torch.autograd.grad(y, x, retain_graph=True)
或者
y.backward(retain_graph=True)
那么可以保证此次求导结束之后,计算图能够得到保留,还能继续通过上面两种方法得到梯度。
3 softmax
(1)softmax过程
softmax函数的计算过程如下

例如,最后一层的线性结果为z,对z使用softmax函数,结果如下
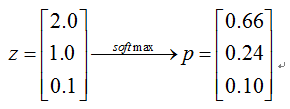
从上面的例子可以看到,z中原来第一个元素2.0比第二个元素1.0大一倍,但经softmax处理后,p的第一个元素是第二个元素的2.75倍,也就是说,softmax功能,是将绝对突出最大的那个元素,通俗点说就是拉大第1名和第2名的差距。
可以认为最后一层的激活函数是softmax,调用torch.softmax函数。
(2)softmax函数求导
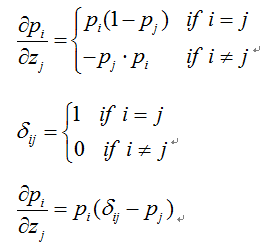
从上式可以看到,Pi对z求导,结果肯定是一个元素为正(当i=j时),其余元素为负(i≠j),可以在草稿纸上证明。
(3)softmax的求导程序
使用上面说的自动求导方法来求梯度
import torch
a = torch.rand(3, 4)
a.requires_grad_()
p = torch.softmax(a, dim=0)
'''dim=0表示每列一个样本,这里a是三行四列,即有4个样本
遍历样本时,为a[:, i],遍历i,第一个维度用冒号代替'''
print(a)
print(p)
'''autograd.grad的第一个参数必须是一个标量,不能是张量'''
da1 = torch.autograd.grad(p[0, 0], a, retain_graph=True)
'''如果等号右边改成torch.autograd.grad(p[0, 0], a[:, 0], retain_graph=True),
那么就会报错,因为计算图中,只出现了a,没有出现切片a[:, 0],
对a的切片单独求导就会报错'''
print(da1)
da2 = torch.autograd.grad(p[0, 1], a, retain_graph=True)
print(da2)
输出

红框的列只有一个元素为正,蓝框的列也同样如此。
4 损失函数
常用的损失函数分两种:均方差和交叉熵
(1)均方差Mse_Loss

调用F.mse_loss可以计算均方差,如果里面的两个张量维度不一样,那么看是否符合广播的原则,符合的话,先广播后计算,否则报错。
import torch
from torch.nn import functional as F
x = torch.ones(2, 3)
w = torch.full([3, 2], 2.)
mse = F.mse_loss(torch.ones(3, 3), w @ x)
print(mse)
输出
tensor(9.)
这个9是怎么来的?

(2)二分类交叉熵nn.BCELoss
二分类中的交叉熵如下式所示:
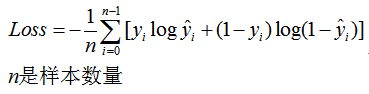
需要注意的是,这里的yi是一个数,非0即1,而不是向量。如果标签y是向量,即one-hot编码(比如在多分类中,二分类也可以把标签写成one-hot编码),那么需要用下面的公式

这就是为何交叉熵有两种公式的缘故
# coding=utf-8
import torch
import torch.nn as nn
import torch.nn.functional as F
z = torch.rand(4, 1) # 最后一层的线性结果,因为是逻辑回归,因此只能一个神经元
pred = torch.sigmoid(z) # 最后一层的输出值
y = torch.tensor([1, 0, 1, 0], dtype=torch.float).view(4, 1) # 标签
loss = nn.BCELoss() # 损失函数为BECLoss,表示二分类的交叉熵
bce = loss(pred, y) # pred是预测值,y是标签
print(bce)
# 再按定义计算一下交叉熵
ce_define = -1/4 * (y*torch.log(pred) + (1-y)*torch.log(1-pred)).sum()
print(ce_define)
# F中也有二分类的交叉熵
print(F.binary_cross_entropy(pred, y))
输出
tensor(0.8264)
tensor(0.8264)
tensor(0.8264)
可以看到,三个输出相等
(3)多分类交叉熵F.cross_entropy或nn.CrossEntropyLoss
F.cross_entropy,这里的交叉熵与之前学的不一样,F.cross_entropy是torch.log_softmax与F.nll_loss两个函数的综合
这里先介绍一下nll_loss

而log_softmax则是先求softmax,再求log

F.cross_entropy是torch.log_softmax与F.nll_loss两个函数的叠加

至于为什么这里的交叉尚函数要设计成这样,这个我也不知道
我们以前求交叉熵的时候,是先求出线性结果,然后套上softmax激活函数,最后根据激活值与标签值求交叉熵。
但由于pytorch中交叉熵函数所使用的公式和我们以前学的不一样,为了能获得与和下面公式同样的效果,所以pytorch中,是将最后一层的线性结果(注意不是softmax激活后的结果)与标签值加入到F.cross_entropy中。
可以用下面的程序验证:
# coding=utf-8
# coding=utf-8
import torch
from torch.nn import functional as F
# 假设z是最后一层的线性结果
z = torch.tensor([[4., 3., 2., 1.],
[3., 1., 4., 5.]])
# 最后一层的线性结果经过softmax激活后,得到y_hat
y_hat = torch.softmax(z, dim=1)
'''求预测值的时候,将z[i,:]当成一个样本,遍历i
dim是多少,就把对应的维度当成冒号,然后遍历张量z
dim不能省略'''
ce = F.cross_entropy(z, torch.tensor([0, 2])) # 直接将线性结果和标签值当参数
'''这里使用z,不是用y,也就是说,多分类问题,
其交叉熵是直接输入激活前的线性结果和标签值,
torch.tensor([0, 2])表示将one-hot矩阵压缩成向量后的标签
第一个样本是[1, 0, 0, 0],第0个元素是1
第二个样本是[0, 0, 1, 0],第2个元素是1'''
print("y_hat=softmax(z)")
print("y_hat=")
print(y_hat)
y_true = torch.tensor([[1, 0, 0, 0],
[0, 0, 1, 0]])
print("y_true=")
print(y_true)
print("log(y_hat)=")
print(torch.log(y_hat))
print()
print("ce=-1/2*sum(y_true * log(y_hat))")
print("ce=", ce) # 可以看到,这是两个样本损失函数的平均值
输出

可以看到,最后ce=0.93,也就是说,直接将线性结果和标签值当F.cross_entropy的参数,得到的结果与下面的公式等效

除了F中的的损失函数外,torch.nn中也有,如
import torch.nn as nn
criteon = nn.CrossEntropyLoss() # 建立一个CrossEntropyLoss对象
loss = criteon(logits, target) # logits是线性结果,target是标签
只要是nn中的函数,都要先得到一个函数对象,通过这个函数对象调用,不能直接用 nn.CrossEntropyLoss(logits, target) 调用
5 用梯度下降法实现优化
函数的表达式及图像如下所示,求最小值对应的x和y

程序如下(看不懂没关系,后面会讲解):
# coding=utf-8
import torch
'''编写函数,即计算图'''
def himmelblau(x):
return (x[0] ** 2 + x[1] - 11) ** 2 + (x[0] + x[1] ** 2 - 7) ** 2
"""指定自变量与优化器"""
# 自变量的初始值,要将requires_grad置为True
x = torch.tensor([-4., 0.], requires_grad=True)
# 优化器,指定优化方法为Adam,要改变的参数为x,学习率为10^-3
optimizer = torch.optim.Adam([x], lr=1e-3)
# params argument given to the optimizer should be an iterable of Tensors or dicts
# 这里x必须为可迭代对象,因此需要把x做成列表,即使自变量只有一个,也要做成列表
"""梯度下降"""
for step in range(20000): # 20000次迭代
pred = himmelblau(x) # 绘制计算图,向前传播
optimizer.zero_grad() # 梯度信息清零,注意梯度清零是通过优化器实现的
pred.backward() # 求导,这里之所以不设置retain_graph=True,是因为每次循环都重新画了一遍计算图
optimizer.step() # 更新参数,即更新x
if step % 2000 == 0:
print ('step {}: x = {}, f(x) = {}'
.format(step, x.tolist(), pred.item())) # .tolist()是将张量转化为列表
# 按格式输出
输出
step 0: x = [-3.999000072479248, -0.0009999999310821295], f(x) = 146.0
step 2000: x = [-3.526559829711914, -2.5002429485321045], f(x) = 19.4503231048584
step 4000: x = [-3.777446746826172, -3.2777843475341797], f(x) = 0.0012130826944485307
step 6000: x = [-3.7793045043945312, -3.283174753189087], f(x) = 5.636138666886836e-09
step 8000: x = [-3.779308319091797, -3.28318190574646], f(x) = 7.248672773130238e-10
step 10000: x = [-3.7793095111846924, -3.28318452835083], f(x) = 8.822098607197404e-11
step 12000: x = [-3.7793102264404297, -3.2831854820251465], f(x) = 8.185452315956354e-12
step 14000: x = [-3.7793102264404297, -3.2831859588623047], f(x) = 0.0
step 16000: x = [-3.7793102264404297, -3.2831859588623047], f(x) = 0.0
step 18000: x = [-3.7793102264404297, -3.2831859588623047], f(x) = 0.0
之所以没有输出第20000次迭代的结果,是因为循环变量是从0开始,step 最多只能达到19999,需要注意的是,本例中的函数,有四个局部最小值,因此不同的初始化,得到的最小值位置未必相同。
上面的程序可以分为四个步骤,这也是解决优化问题的四个步骤:
1 编写函数(计算图)
2 自变量(参数)初始化,设置为需要梯度信息
3 设置优化器,包括制定优化方法、学习率,指定需要更新的变量(参数)
4 编写循环,在循环包含4个部分:绘制计算图、梯度信息清零、反向传播、变量(参数)优化
之所以要梯度信息清零,如果不清零,那么每次求导之后,梯度将会累加。
x.tolist()是将张量转换成列表
pred.item()是将张量转化为Python自带的数据类型,官网的介绍是:Returns the value of this tensor as a standard Python number. This only works for tensors with one element.
.tolist()和.item()的实例程序如下
import torch
a = torch.full((2, 3), 7.)
print('a= {}'.format(a.tolist()))
print(type(a.tolist()))
b = torch.tensor([2])
c = torch.tensor(5.)
print(b.item()) # 一维张量可以转
print(c.item()) # 0维张量也可以转
# print(a.item()) # 如果a中有多个元素,那么就会报错
总结
1 sigmoid,tanh,relu,softmax四种激活函数在pytorch中如何实现?
2 梯度是什么?由偏导数组成的向量或张量
3 使用autograd.grad实现自动求导的步骤是什么?如何通过反向传播获得梯度?
4 如果计算图中的某个变量,其requires_grad被更新,原来的计算图需要重新绘制吗?如何保留计算图
5 均方差、二分类交叉熵、多分类交叉熵的API分别是什么,多分类交叉熵损失函数的参数,与均方差、二分类交叉熵有什么区别?
6 优化问题(梯度下降)的四个步骤是什么?















 844
844











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









