







摘要
链接预测是图上一项非常基本的任务。本文在传统基于路径方法的启发下,提出了一种基于路径的通用、灵活的表征学习框架,用于链路预测。具体来说,我们将一对节点的表示定义为节点之间所有路径表示的广义和,其中每个路径表示为路径中边缘表示的广义积。在求解最短路径问题的Bellman-Ford算法的激励下,我们证明了所提出的路径公式可以用广义Bellman-Ford算法有效地求解。为了进一步提高路径制定的能力,我们提出了神经Bellman-Ford网络(Neural Bellman-Ford Network, NBFNet),这是一种通用的图神经网络框架,它使用广义Bellman-Ford算法中的学习算子来解决路径制定问题。NBFNet将广义Bellman-Ford算法参数化为3个神经分量,即INDICATOR、MESSAGE和AGGREGATE函数,分别对应边界条件、乘法算子和求和算子1。NBFNet涵盖了许多传统的基于路径的方法,可以应用于同质图和多关系图(例如,知识图)的转换和归纳设置。在同质图和知识图上的实验表明,所提出的NBFNet在传感和感应设置上都大大优于现有方法,获得了新的最先进的结果2。
1.介绍
预测节点之间的相互作用(又称链接预测)是图机器学习领域的一项基本任务。鉴于图的普遍存在,这样的任务有很多应用,如推荐系统[34],知识图补全[41]和药物再利用[27]。
传统的链路预测方法通常在一对节点之间的路径上定义不同的启发式度量。例如,Katz index[30]被定义为两个节点之间路径的加权计数。个性化PageRank[42]将两个节点的相似性度量为从一个节点到另一个节点的随机游走概率。图距离Graph distance[37]使用两个节点之间最短路径的长度来预测它们的关联。这些方法可以直接应用于新图,即归纳设置,具有良好的可解释性,并且可以扩展到大型图。然而,它们是基于手工制作的指标设计的,对于现实世界的图表链接预测可能不是最佳的。
为了解决这些局限性,一些链路预测方法采用图神经网络(gnn)[32,48,59]从局部邻域中自动提取重要特征进行链路预测。由于gnn的高表达性,这些方法表现出了最先进的性能。然而,这些方法只能用于预测训练图上的新链接,即换能性设置,缺乏可解释性。虽然最近的一些方法[73,55]使用gnn从局部子图中提取特征并支持归纳设置,但这些方法的可扩展性受到损害。
因此,我们想知道是否存在一种既具有传统的基于路径的方法又具有最近基于图神经网络的方法的优点的方法,即归纳设置中的泛化,可解释性,高模型容量和可扩展性。
在本文中,我们提出了这样一个解决方案。受传统基于路径方法的启发,我们的目标是开发一个通用的、灵活的基于两个节点之间路径的链接预测表示学习框架。具体来说,我们将一对节点的表示定义为它们之间所有路径表示的广义和,其中每个路径表示定义为路径中边缘表示的广义积。许多链接预测方法,如Katz索引[30]、个性化PageRank[42]、图距离[37],以及最宽路径[4]、最可靠路径[4]等图论算法,都是该路径公式的特殊实例,使用了不同的求和和乘法运算符。在最短路径问题[5]的多项式时间算法的激励下,我们证明了这种公式可以在温和的条件下通过广义Bellman-Ford算法[4]有效地求解,并扩展到大型图。
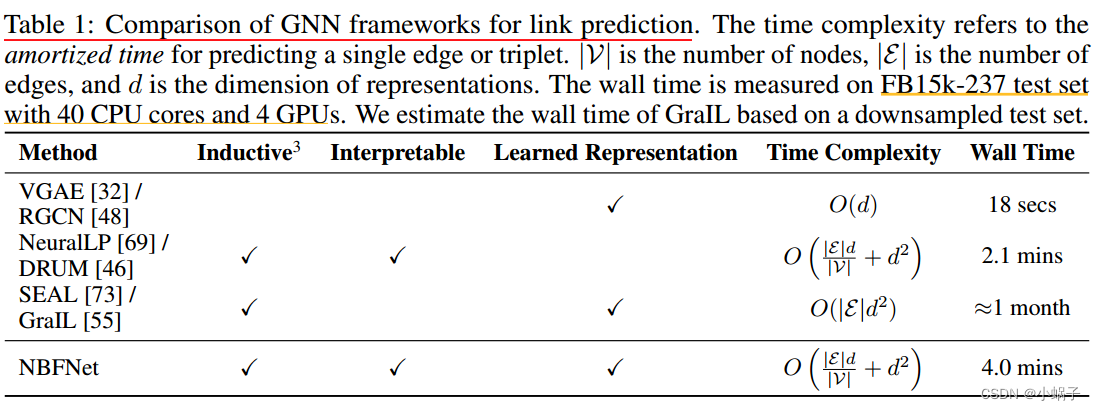
我们证明了MESSAGE函数可以根据知识图嵌入中的关系算子来定义[6,68,58,31,52],例如,作为由TransE[6]的关系算子诱导的欧几里得空间中的平移。AGGREGATE函数可以定义为可学习集合聚集函数[71,65,9]。通过这样的参数化,NBFNet可以推广到归纳设置,同时实现归纳GNN方法中时间复杂度最低的方法之一。表1显示了用于链路预测的nbnet和其他GNN框架的比较。通过MESSAGE和AGGREGATE函数的其他实例化,我们的框架还可以恢复一些现有的学习逻辑规则的工作[69,46],用于知识图的链接预测(表2)。
我们的nbnet框架可以应用于几种链接预测变体,不仅涵盖单级关系图(例如,同构图),还涵盖多关系图(例如,知识图)。我们对所提出的NBFNet在同质图和知识图上的链接预测进行了经验评估,包括转导和归纳设置。实验结果表明,所提出的NBFNet在所有设置下都大大优于现有的最先进的方法,在知识图谱完成(HITS@1)和归纳关系预测(HITS@10)上的平均相对性能提高了18%。我们还表明,通过可视化知识图上链接预测的top-k相关路径,所提出的nbnet确实是可解释的。

2.Related Work
现有的链路预测工作大致可分为三种主要范式:基于路径的方法、嵌入方法和图神经网络。
基于路径的方法。早期的同质图方法基于路径加权计数(Katz index[30])、随机行走概率(personalpagerank[42])或最短路径长度(图距离[37])来计算两个节点之间的相似性。 SimRank[28]使用高级指标advanced metrics,如在同构图上的预期相遇距离,由PathSim[51]扩展到异构图。在知识图上,Path Ranking[35,15]直接使用关系路径作为预测的符号特征。规则挖掘方法,如NeuralLP[69]和DRUM[46],学习概率逻辑规则来加权不同的路径。路径表示方法,如Path- rnn[40]及其后继方法[11,62],使用递归神经网络(rnn)对每个路径进行编码,并聚合路径进行预测。然而,这些方法需要遍历指数数量的路径,并且限于非常短的路径,例如≤3条边。为了扩展基于路径的方法,All-Paths[57]提出用动态规划有效地聚合所有路径。然而,全路径算法仅限于双线性模型,模型容量有限。另一个工作流[64,10,22]学习代理来收集有用的路径用于链接预测。虽然这些方法可以产生可解释的路径,但它们的奖励非常稀疏,需要仔细设计奖励函数[38]或搜索策略[50]。其他一些作品[8,44]采用变分推理学习寻径器和路径推理器进行链接预测。
嵌入方法。嵌入方法通过保留图的边缘结构来学习每个节点和边缘的分布式表示。代表性方法有齐次图上的DeepWalk[43]和LINE[53],知识图上的TransE[6]、DistMult[68]和RotatE[52]。后来的工作改进了嵌入方法,使用新的分数函数[58,13,31,52,54,76]来捕获关系的共同语义模式,或者在一般设计空间中搜索分数函数[75]。嵌入方法在链路预测方面取得了令人满意的结果,并且可以使用多个gpu扩展到非常大的图[78]。但是,嵌入方法不能显式地对节点对之间的局部子图进行编码,因此不能应用于归纳设置。
图神经网络。图神经网络(gnn)[47,33,60,65]是一组表示学习模型,用于编码图的拓扑结构。对于链路预测,流行的框架[32,48,12,59]采用自编码器公式,该公式使用gnn对节点表示进行编码,并将边作为节点对的函数进行解码。如果数据集提供节点特征,这些框架是潜在的归纳性的,但只有当节点特征不可用时,这些框架才具有转导性。另一种框架流,如SEAL[73]和GraIL[55],显式地对每个节点对周围的子图进行编码以进行链接预测。虽然这些框架被证明比自编码器公式[74]更强大,并且可以解决归纳设置,但它们需要为每个链接实现一个子图,这不能扩展到大型图。相比之下,我们的NBFNet明确捕获两个节点之间的路径进行链路预测,同时实现了相对较低的时间复杂度(表1)。ID-GNN[70]将链路预测形式化为条件节点分类任务,并通过源节点的身份增强了gnn。虽然NBFNet的架构与ID-GNN有一些共同点,但我们的模型是由广义Bellman-Ford算法驱动的,并且与传统的基于路径的方法有理论联系。也有一些工作试图通过动态修剪消息传递中的节点集来扩大gnn用于链路预测[66,20]。这些方法是对NBFNet的补充,并且可以合并到我们的方法中以进一步提高可伸缩性。·
3.方法
在本节中,我们首先定义用于链接预测的路径公式。我们的路径公式推广了几种传统的方法,可以用广义Bellman-Ford算法有效地求解。然后,我们提出了神经Bellman-Ford网络,利用神经函数学习路径公式。
3.1 Path Formulation for Link Prediction

Path Formulation。链接预测的目的是预测头部实体u和尾部实体v之间是否存在查询关系q。从表示学习的角度来看,这需要学习一对表示![]() ,它捕获
,它捕获![]()
![]() 之间的局部子图结构。在传统方法中,这种局部结构是通过计数从u到v的不同类型的随机游走来编码的[35,15]。受此构造的启发,我们将对表示形式化为u和v之间的路径表示的广义和,并带有可交换和算子⊕。每个路径表示
之间的局部子图结构。在传统方法中,这种局部结构是通过计数从u到v的不同类型的随机游走来编码的[35,15]。受此构造的启发,我们将对表示形式化为u和v之间的路径表示的广义和,并带有可交换和算子⊕。每个路径表示![]() 被定义为路径中边缘表示与 multiplication operator乘法算子⊗的广义乘积generalized product。
被定义为路径中边缘表示与 multiplication operator乘法算子⊗的广义乘积generalized product。
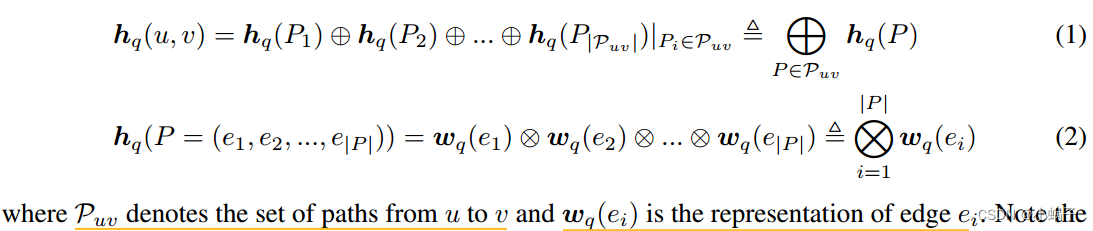
其中![]() 表示从u到v的路径集合,
表示从u到v的路径集合,![]() 表示边ei。注意乘法运算符⊗不需要是可交换的(例如,矩阵乘法),因此我们定义
表示边ei。注意乘法运算符⊗不需要是可交换的(例如,矩阵乘法),因此我们定义![]() 来计算精确顺序的乘积。直观地,路径公式可以解释为深度优先搜索(DFS)算法,其中搜索从u到v的所有可能路径,计算它们的表示(公式2)并汇总结果(公式1)。这种公式能够建模几种传统的链路预测方法,以及图论算法。形式上,定理1-5分别表述了3种链路预测方法和2种图论算法对应的路径表达式。见附录A的证明。
来计算精确顺序的乘积。直观地,路径公式可以解释为深度优先搜索(DFS)算法,其中搜索从u到v的所有可能路径,计算它们的表示(公式2)并汇总结果(公式1)。这种公式能够建模几种传统的链路预测方法,以及图论算法。形式上,定理1-5分别表述了3种链路预测方法和2种图论算法对应的路径表达式。见附录A的证明。

广义Bellman-Ford算法。虽然上述公式能够为链路预测建立重要的启发式模型,但由于路径的数量随着路径长度呈指数增长,因此计算成本很高。以往的研究[40,11,62]直接计算路径的指数数,只能提供最大路径长度为3。一个更可扩展的解决方案是使用广义Bellman-Ford算法[4]。具体来说,假设算子![]() 满足
满足![]() ,我们有如下的算法:
,我们有如下的算法:
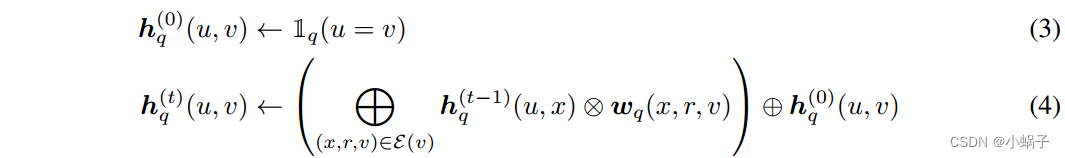
其中![]() 是指示函数,
是指示函数,![]() 。
。![]() 是
是![]() 的表示r是边的关系类型。式3称为边界条件 boundary condition,式4称为Bellman-Ford迭代。广义Bellman-Ford算法的高级思想是计算
的表示r是边的关系类型。式3称为边界条件 boundary condition,式4称为Bellman-Ford迭代。广义Bellman-Ford算法的高级思想是计算 并利用乘法除以求和的分配律减少总计算量。
并利用乘法除以求和的分配律减少总计算量。

3.2 Neural Bellman-Ford Networks
虽然广义Bellman-Ford算法可以解决许多经典方法(定理6),但这些方法使用手工制作的运算符实例化路径公式(表2),对于链路预测可能不是最优的。为了提高路径表述的能力,我们提出了一个通用的框架——神经Bellman-Ford网络(Neural Bellman-Ford Networks, nbbfnet)来学习对表示中的算子。
Neural Parameterization
我们放宽了半环假设semiring assumption,将广义Bellman-Ford算法(式3和式4)参数化为3个神经函数,即INDICATOR、MESSAGE和AGGREGATE函数。INDICATOR函数取代indicator函数![]() 。MESSAGE函数取代二元乘法运算符⊗。AGGREGATE函数是一个集合上的置换不变函数,它取代了n元求和运算符
。MESSAGE函数取代二元乘法运算符⊗。AGGREGATE函数是一个集合上的置换不变函数,它取代了n元求和运算符![]() 。注意,我们也可以将AGGREGATE定义为可交换二进制运算符⊕,并将其应用于消息序列。然而,这将使参数化更加复杂。
。注意,我们也可以将AGGREGATE定义为可交换二进制运算符⊕,并将其应用于消息序列。然而,这将使参数化更加复杂。
现在考虑给定实体u和关系q的广义Bellman-Ford算法。在这种情况下,我们缩写![]() ,
,![]() 。需要强调的是,
。需要强调的是,![]() 仍然是一个对表示,而不是一个节点表示。通过将神经函数代入方程3和4,我们得到了神经Bellman-Ford网络。
仍然是一个对表示,而不是一个节点表示。通过将神经函数代入方程3和4,我们得到了神经Bellman-Ford网络。
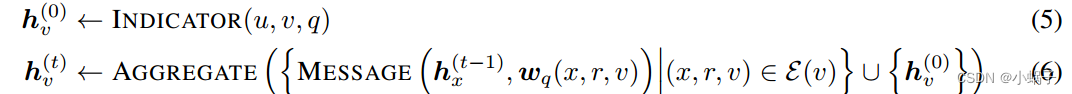
NBFNet可以被解释为一种用于学习对表示的新型GNN框架。常见的GNN框架[32,48]将对表示计算为两个独立的节点表示![]() ,与之相比,NBFNet在源节点u上初始化一个表示,并在目标节点v上读出对表示。直观地,我们的框架可以被视为一个特定于源的消息传递过程,其中每个节点都学习源节点条件下的表示。算法1给出了NBFNet的伪代码。
,与之相比,NBFNet在源节点u上初始化一个表示,并在目标节点v上读出对表示。直观地,我们的框架可以被视为一个特定于源的消息传递过程,其中每个节点都学习源节点条件下的表示。算法1给出了NBFNet的伪代码。

Design Space.
现在我们通过借鉴传统方法来讨论MESSAGE、AGGREGATE和INDICATOR函数的一些原则性设计。请注意,NBFNet的潜在设计空间比这里展示的要大得多,因为人们总是可以从消息传递gnn的库中借用MESSAGE和AGGREGATE[19,16,60,65]。
对于MESSAGE函数,传统方法将其实例化为自然求和、自然乘法或最小除以标量。因此,我们可以使用求和或乘法的矢量化版本。直观地说![]() 可以解释为
可以解释为![]() 被
被![]() 在对表示空间中,而乘法对应于缩放。这种转换对应于知识图嵌入中的关系算子[18,45][6,68,58,31,52]。例如,TransE[6]和DistMult[68]中分别使用的关系运算符是平移和缩放。我们还考虑RotatE[52]中的旋转操作符。
在对表示空间中,而乘法对应于缩放。这种转换对应于知识图嵌入中的关系算子[18,45][6,68,58,31,52]。例如,TransE[6]和DistMult[68]中分别使用的关系运算符是平移和缩放。我们还考虑RotatE[52]中的旋转操作符。
在传统方法中,AGGREGATE函数被实例化为自然求和、max或min,这让人想起gnn中使用的集合聚合函数[71,65,9]。因此,我们将AGGREGATE函数指定为sum、mean或max,然后进行线性变换和非线性激活。我们还考虑了在最近的工作[9]中提出的主邻域聚合(PNA),它共同学习聚合函数的类型和尺度。
INDICATOR函数的目的是提供源节点u作为边界条件的非平凡表示。因此,我们学习![]() ,并定义INDICATOR函数为
,并定义INDICATOR函数为![]() 。注意,也可以额外学习
。注意,也可以额外学习![]() 的嵌入。然而,我们发现单查询嵌入在实践中效果更好。
的嵌入。然而,我们发现单查询嵌入在实践中效果更好。
在传统方法中,边缘表示被实例化为转移概率或长度。我们注意到,在回答不同的查询关系时,一条边可能有不同的贡献。因此,我们将边缘表示参数化为查询关系上的线性函数,即![]() 。对于齐次图或关系很少的知识图,我们将参数化简化为
。对于齐次图或关系很少的知识图,我们将参数化简化为![]() 防止过拟合。注意,也可以参数化
防止过拟合。注意,也可以参数化![]() ,但这种参数化不能解决归纳设置。与NeuralLP[69]和DRUM[46]类似,我们对不同的迭代使用不同的边表示,这能够区分路径中的非交换边,例如,
,但这种参数化不能解决归纳设置。与NeuralLP[69]和DRUM[46]类似,我们对不同的迭代使用不同的边表示,这能够区分路径中的非交换边,例如,![]()
链接预测。现在我们展示如何应用学习到的成对表示![]() 链路预测问题。我们预测尾部实体v的条件似然为
链路预测问题。我们预测尾部实体v的条件似然为![]()
![]() ,其中σ(·)为s型函数,f(·)为前馈神经网络。头部实体u的条件似然可以用
,其中σ(·)为s型函数,f(·)为前馈神经网络。头部实体u的条件似然可以用![]() 用相同的模型。根据之前的工作[6,52],我们最小化了正三元组和负三元组的负对数似然(公式7)。负样本是根据部分完备性假设(PCA)[14]生成的,它破坏了正三元组中的一个实体来创建负样本。对于无向图,我们对称表示并定义了
用相同的模型。根据之前的工作[6,52],我们最小化了正三元组和负三元组的负对数似然(公式7)。负样本是根据部分完备性假设(PCA)[14]生成的,它破坏了正三元组中的一个实体来创建负样本。对于无向图,我们对称表示并定义了![]() 。方程8给出了齐次图的损失。
。方程8给出了齐次图的损失。
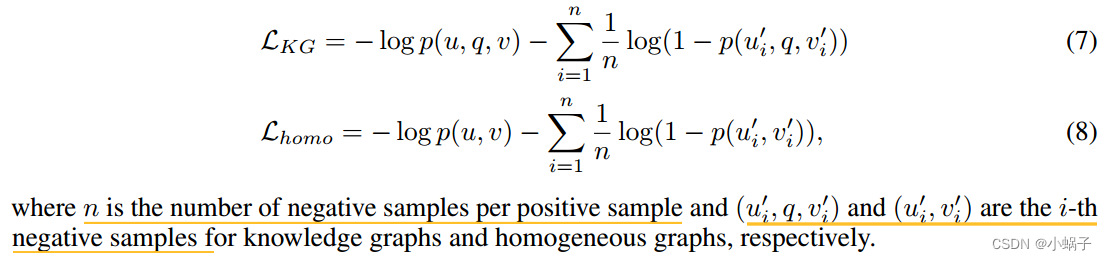
Time Complexity.
nbnet的一个优点是它在推理过程中具有相对较低的时间复杂度。考虑一个场景,其中需要一个模型来推断所有可能的三元组![]() .我们将具有相同条件u的三胞胎分组q在一起,其中每组包含
.我们将具有相同条件u的三胞胎分组q在一起,其中每组包含![]() 个三元组。对于每一组,我们只需要执行一次算法1就可以得到他们的预测结果。
个三元组。对于每一组,我们只需要执行一次算法1就可以得到他们的预测结果。
由于少量的常数次迭代T就足以使nbbfnet收敛(表6b),因此算法1的时间复杂度![]() ,其中d为表示维数。因此,单个三元组的平摊时间复杂度为
,其中d为表示维数。因此,单个三元组的平摊时间复杂度为![]() 。有关其他GNN框架时间复杂度的详细推导,请参阅附录C。
。有关其他GNN框架时间复杂度的详细推导,请参阅附录C。
4 Experiment
4.1 Experiment Setup
我们在知识图谱补全、同构图链接预测和归纳关系预测三种设置下对nbbfnet进行了评价。前两种设置是换能型(直推)设置,而最后一种设置是感应型(归纳)设置。对于知识图,我们使用FB15k-237[56]和WN18RR[13]。我们使用这些数据集的标准直推分裂[56,13]和归纳分裂[55]。对于齐次图,我们使用Cora、Citeseer和PubMed[49]。根据之前的工作[32,12],我们将边缘分成训练/有效/测试,比例为85:5:10。数据集的统计数据见附录E。nbbfnet在OGB[25]数据集上的其他实验见附录G。
实现细节。我们的实现通常遵循知识图完备5和同构图链接预测6的开源代码库。对于知识图,我们遵循[69,46],用一个翻转的三元组![]() 扩充每个三元组
扩充每个三元组![]() 。对于齐次图,我们遵循[33,32],用自循环
。对于齐次图,我们遵循[33,32],用自循环![]() 扩展每个节点u。我们用6层实例化nbnet,每层有32个隐藏单元。前馈网络f(·)设置为具有64个隐藏单元的2层MLP。ReLU被用作所有隐藏层的激活函数。我们在训练过程中去掉直接连接查询节点对的边,以鼓励模型捕获更长的路径并防止过拟合。我们的模型在4个Tesla V100 gpu上进行了20次epoch的训练。我们根据模型在验证集上的表现来选择模型。详见附录F。
扩展每个节点u。我们用6层实例化nbnet,每层有32个隐藏单元。前馈网络f(·)设置为具有64个隐藏单元的2层MLP。ReLU被用作所有隐藏层的激活函数。我们在训练过程中去掉直接连接查询节点对的边,以鼓励模型捕获更长的路径并防止过拟合。我们的模型在4个Tesla V100 gpu上进行了20次epoch的训练。我们根据模型在验证集上的表现来选择模型。详见附录F。
评估。我们采用过滤排序协议[6]来补全知识图谱。对于一个测试三元组![]() ,我们将它与所有没有出现在知识图中的负三元组
,我们将它与所有没有出现在知识图中的负三元组![]() 进行排序。我们报告了知识图谱补全的平均秩(MR),平均倒数秩(MRR)和HITS在N (H@N)。对于归纳关系预测,我们遵循[55],为每个正三元组绘制50个负三元组,并使用上述过滤后的排序。我们报告HITS@10的归纳关系预测。对于齐次图链接预测,我们遵循[32],将正边与相同数量的负边进行比较。我们报告了接收者工作特征曲线(AUROC)下的面积和均匀图的平均精度(AP)。
进行排序。我们报告了知识图谱补全的平均秩(MR),平均倒数秩(MRR)和HITS在N (H@N)。对于归纳关系预测,我们遵循[55],为每个正三元组绘制50个负三元组,并使用上述过滤后的排序。我们报告HITS@10的归纳关系预测。对于齐次图链接预测,我们遵循[32],将正边与相同数量的负边进行比较。我们报告了接收者工作特征曲线(AUROC)下的面积和均匀图的平均精度(AP)。
基线。我们将nbnet与基于路径的方法、嵌入方法和gnn进行了比较。其中包括11条知识图补全基线、10条同构图链接预测基线和4条归纳关系预测基线。注意,归纳设置仅包括基于路径的方法和gnn,因为现有的嵌入方法无法处理此设置。
4.2 Main Results
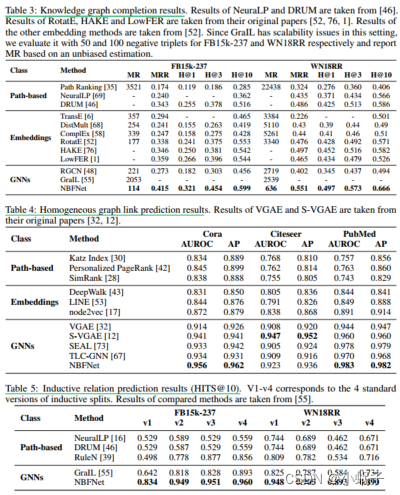
表3总结了知识图谱补全的结果。nbbfnet在所有指标和两个数据集上都明显优于现有方法。在两个数据集上,与基于最佳路径的方法DRUM[46]相比,nbbfnet在HITS@1上的平均相对增益为21%。由于DRUM是NBFNet的一个特殊实例,具有自然的求和和乘法运算符,这表明了在NBFNet中学习MESSAGE和AGGREGATE函数的重要性。nbbfnet也优于最佳嵌入方法LowFER[1],在两个数据集上,HITS@1的平均相对性能提高了18%。同时,nbbfnet需要的参数比嵌入方法少得多。NBFNet在FB15k-237上只使用3M参数,而TransE需要30M参数。参数数量详见附录D。
表4显示了同构图链接预测的结果。nbnet在Cora和PubMed上取得了最好的成绩,同时在CiteSeer上取得了竞争的成绩。注意,CiteSeer是非常稀疏的(附录E),这使得很难用nbbfnet学习良好的表示。这里需要注意的一点是,与其他GNN方法不同,nbbfnet不使用数据集提供的节点特征,但仍然能够优于大多数其他方法。我们将如何有效地结合节点特征和结构表示进行链接预测作为我们未来的工作。
表5总结了归纳关系预测的结果。在两个数据集的所有归纳分割上,NBFNet都取得了最好的结果。nbnet优于之前的最佳方法GraIL[55],在HITS@10中平均相对性能提高22%。请注意,GraIL显式地编码每个节点对周围的局部子图,并且具有很高的时间复杂度(附录C)。通常,GraIL最多可以编码一个2跳子图,而我们的nbbfnet可以有效地探索更长的路径。
4.3 Ablation Study
MESSAGE & AGGREGATE Functions.
表6a显示了不同MESSAGE和AGGREGATE函数的结果。一般来说,nbnet受益于高级嵌入方法(DistMult、RotatE > TransE)和聚合函数(PNA > sum、mean、max)。在简单的AGGREGATE函数(sum, mean, max)中,满足广义Bellman-Ford算法的半循环假设7的MESSAGE和AGGREGATE函数(TransE & max, DistMult & sum)的组合可以实现局部最优性能。与简单的同类算法相比,PNA有了显著的改进,这凸显了学习更强大的AGGREGATE函数的重要性。
Number of GNN Layers.
表6b比较了不同层数下nbbfnet的结果。虽然有报道称深层gnn通常会导致显著的性能下降[36,77],但我们观察到nbbfnet没有这个问题。随着层数的增加,性能单调增加,6层后达到饱和。我们推测其原因是较长的路径贡献可以忽略不计,长度不超过6的路径就足以进行链接预测。
Performance by Relation Category.
我们通过查询关系的类别来分解nbnet的性能:一对一、一对多、多对一和多对多。表6c显示了每个类别的预测结果。观察到nbnet不仅在简单的一对一情况下有所提高,而且在查询有多个正确答案的困难情况下也有所提高。

4.4 Path Interpretations of Predictions
nbbfnet的一个优点是我们可以通过路径来解释它的预测,这对于用户理解和调试模型可能很重要。直观地说,解释应该包含对预测![]() .遵循局部解释方法[3,72],我们使用所有路径集合上的线性模型(即一阶泰勒多项式)近似NBFNet的局部景观。我们将路径的重要性定义为它在线性模型中的权重,它可以通过预测的偏导数来计算。形式上,
.遵循局部解释方法[3,72],我们使用所有路径集合上的线性模型(即一阶泰勒多项式)近似NBFNet的局部景观。我们将路径的重要性定义为它在线性模型中的权重,它可以通过预测的偏导数来计算。形式上,![]() 定义为
定义为
![]()
注意,这个公式将逻辑规则的定义推广到非线性模型[69,46]。虽然直接计算所有路径的重要性是棘手的,但我们用边的重要性来近似它们。具体来说,每条路径的重要性由该路径上的边的重要性之和来近似,其中边的重要性是通过自动微分获得的。然后,top-k路径解释等价于边缘重要性图上的top-k最长路径,可以通过Bellman-Ford-style光束搜索来求解。更好的近似是未来的工作。
表7显示了FB15k-237测试集的可视化路径解释。虽然用户可能对可视化有不同的见解,但以下是我们的理解。1)在第一个例子中,nbnet学习软逻辑蕴涵soft logical entailment,,例如impersonate - 1 ^ nationality => nationality and ethnicity - 1 ^ distribution => nationality。2)在第二个例子中,NBFNet利用Florence is similar to Rome的事实进行类比推理。3)在最后一个例子中,NBFNet提取了更长的路径,因为Pearl Harbor (film) and Japanese language之间没有明显的联系。

5 Discussion and Conclusion
局限性。nbbfnet有一些限制。首先,广义Bellman-Ford算法的假设要求算子![]() 。由于神经网络中的非线性激活函数,这一假设不适用于nbbfnet,并且我们对这种松弛所造成的损失没有理论上的保证。其次,nbnet仅在简单的边缘预测上进行验证,而还有其他的链路预测变体,例如带有
。由于神经网络中的非线性激活函数,这一假设不适用于nbbfnet,并且我们对这种松弛所造成的损失没有理论上的保证。其次,nbnet仅在简单的边缘预测上进行验证,而还有其他的链路预测变体,例如带有![]() 连接(^)和析取()的复杂逻辑查询[18,45]。在未来,我们希望NBFNet如何逼近路径公式,以及将NBFNet应用于其他链路预测设置。
连接(^)和析取()的复杂逻辑查询[18,45]。在未来,我们希望NBFNet如何逼近路径公式,以及将NBFNet应用于其他链路预测设置。
社会影响。链接预测具有广泛的有益应用,包括推荐系统、知识图谱完成和药物再利用。然而,也有一些潜在的负面影响。首先,nbbfnet可能会对训练数据中存在的偏见进行编码,当预测应用于社交或电子商务平台上的用户时,这会导致刻板印象的预测。其次,一些有害的网络活动可以通过强大的链接预测模型来增强,例如,垃圾邮件、网络钓鱼和社会工程。我们希望未来的研究能够缓解这些问题。
结论。我们提出了一种基于路径的表示学习框架用于链接预测。我们的路径公式推广了几种传统的方法,并且可以通过广义Bellman-Ford算法有效地求解。为了提高路径规划的能力,我们提出了NBFNet,它通过学习到的INDICATOR、MESSAGE、AGGREGATE函数对广义Bellman-Ford算法进行参数化。在知识图和同构图上的实验表明,nbnet在转换和归纳设置上都优于许多方法。


















 1987
1987

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











