









在学习渲染的过程中接触到了OpenMP,真的是非常容易使用(一行编译原语),然后带来了非常大的速度提升(1h30m -> 12m),下面就总结一下OpenMP比较入门的知识
多线程
我觉得你可以不知道一些复杂的底层知识,但至少要清楚为什么多线程可以使得程序运行速度得到很大的提升。
一个很重要的原因是,现在的 CPU 往往拥有多个核心,比如我笔记本的 i7-8750H,有 6 个内核。
内核可以简单理解为计算单元,我们可以想我们的程序基本就是在做计算嘛,那如果只是串行执行,那么我们一次不就只能使用一个内核吗。而多线程就可以让我们同时使用多个内核进行计算,那么我们程序的运行速度是不是就被大幅度提升了。
除此之外,多线程在进程 I/O 时也有用,单线程情况,如果进行 I/O 那么这时就不会占用 CPU 资源,但其实我们有的计算任务并不依赖于这个 I/O,那么我们就可以利用多线程在 I/O 时执行其他任务(也可以想想如果用户使用你的程序读取一个文件,如果单线程是不是此时点击其他按钮就不会产生任何响应了)
OpenMP
那么 OpenMP 和多线程有什么关系呢,下面截自百度百科。

简单理解,我们使用 OpenMP 就可以非常简单地实现多线程。有多简单呢,我们从 OpenMP 的简单用法入手,了解之后你就会发现,多线程编程 so easy!
查看是否支持 OpenMP
在使用 OpenMP 完成多线程任务时,首先得查看当前编译器是否支持 OpenMP,我在 Linux 上的 GCC 编译器是默认支持 OpenMP 的,只需在生成可执行文件的命令中加入 -fopenmp 即可。
下面的代码也可以查看当前编译器是否支持 OpenMP
check_openmp.c
#include <stdio.h>
int main()
{
#if _OPENMP
printf("support openmp\n");
#else
printf("not support openmp\n");
#endif
return 0;
}
然后编译执行

Hello World
我们使用 OpenMP 输出 Hello World
#include <stdio.h>
int main(void)
{
#pragma omp parallel
{
printf("Hello, world. \n");
}
return 0;
}
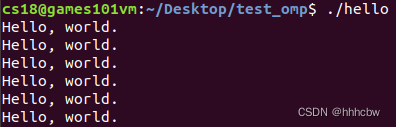
输出结果如下,因为没有指定线程数,所以默认使用 CPU 核心数量的线程,这里在虚拟机(cpu四个核心)

当然我们也可以指定核心数量,代码如下
#include <stdio.h>
int main(void)
{
#pragma omp parallel num_threads(6)
{
printf("Hello, world. \n");
}
return 0;
}
输出结果如下,你可能会想为啥可以指定大于核心的线程数,不是只有四个核心吗,其实不影响的,CPU也不看你的核心数,只是知道该取指令进行计算,一般使用大于等于核心数的线程。
循环
下面我们实现一个循环,一行编译原语实现循环的多线程!
loop.c
#include <stdio.h>
#include <omp.h>
#include <stdlib.h>
int main(void) {
#pragma omp parallel for
for (int i=0; i<12; i++) {
printf("OpenMP Test, th_id: %d\n", omp_get_thread_num());
}
return 0;
}
这里的 omp.h 主要包括一些 openmp 的库函数,比如 omp_get_thread_num() 获取当前线程 id

下面使用多线程完成加法
loop_add.c
#include <stdio.h>
#include <omp.h>
#include <stdlib.h>
int main(void) {
int sum = 0;
#pragma omp parallel for
for (int i=1; i<=100; i++) {
sum += i;
}
printf("%d", sum);
return 0;
}
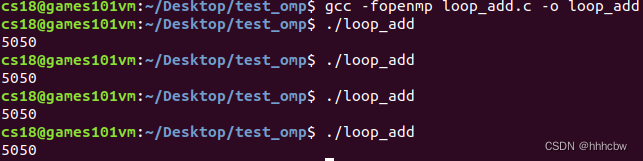
执行多次,其结果如下。我们可以发现结果每次都不一样。原因是线程对同一个资源产生了竞争,sum += i; 这一行如果多个线程同时写,可能会发生写冲突。因为 sum+=i 可以展开为 sum=sum+i。所以,如果一个线程计算完了 sum+i 但还没赋值过去,这时就会产生问题。

那么 OpenMP 为了解决这个冲突,可以使用 reduction
#include <stdio.h>
#include <omp.h>
#include <stdlib.h>
int main(void) {
int sum = 0;
#pragma omp parallel for reduction(+:sum)
for (int i=1; i<=100; i++) {
sum += i;
}
printf("%d", sum);
return 0;
}
这样不管我们执行多少次,结果都是正确的。
private和shared
private 私有变量表示对于该变量,每个线程都拿到其一个复制,shared 则表示所有线程共同使用这个变量,默认未在线程中定义的变量为 shared
#include <stdio.h>
#include <omp.h>
int main (int argc, char *argv[]) {
int th_id, nthreads;
#pragma omp parallel private(th_id)
{
th_id = omp_get_thread_num();
printf("Hello World from thread %d\n", th_id);
}
}
输出结果如下,可见 th_id 不会被线程相互影响

补充知识
共享内存模型
OpenMP 是为多处理器或多喝共享内存机器设计的。
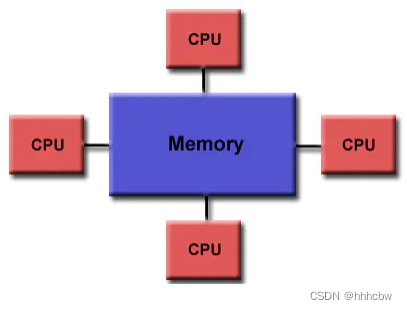
OpenMP 在很大程度上局限于单节点并行性。通常,节点上处理元素(核心)的数量决定了可以实现多少并行性。
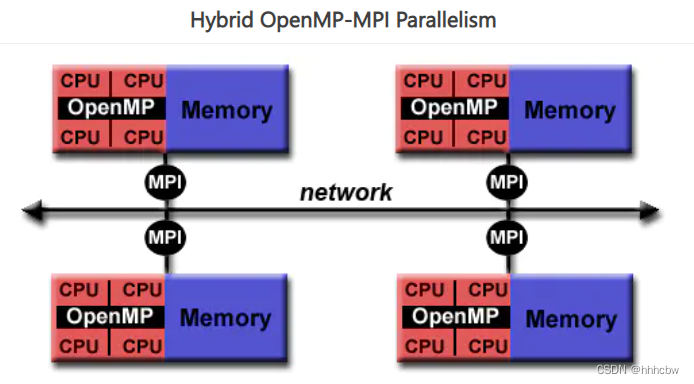
混合并行编程
OpenMP 用于单节点并行,MPI 与 OpenMP 相结合实现分布式内存并行。这通常被称为混合并行编程。
- OpenMP 用于每个节点上的计算密集型工作
- MPI 用于实现节点之间的通信和数据共享
这使得并行性可以在集群的整个范围内实现,
Fork-Join 模型
OpenMP 使用并行执行的 Fork-Join 模型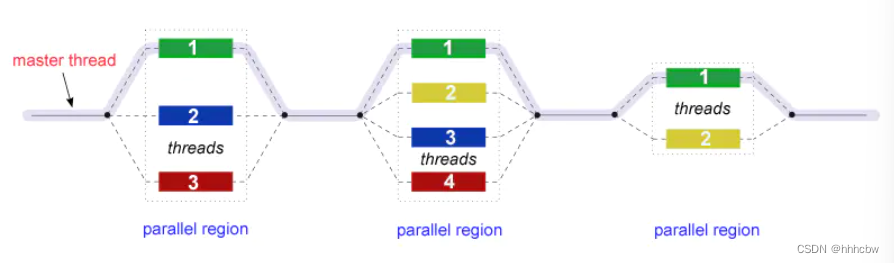
- 所有 OpenMP 程序都开始于一个主线程。主线程按顺序执行,直到遇到第一个并行区域结构。
- FORK:主线程然后创建一组并行线程。
- 之后程序中由并行区域结构封装的语句在各个团队线程中并行执行。
- JOIN:当团队线程完成并行区域结构中的语句时,它们将进行同步并终止,只留下主线程。
- 并行区域的数量和组成它们的线程是任意的。
我们可以使用 barrier 让所有线程在此处停下,等到所有线程都执行到此处,之后各自线程再往下执行
#include <stdio.h>
int main(void)
{
int th_id, nthreads;
#pragma omp parallel private(th_id)
{
th_id = __builtin_omp_get_thread_num();
printf("Hello World from thread %d\n", th_id);
#pragma omp barrier
if (th_id == 0) {
nthreads = __builtin_omp_get_num_threads();
printf("There are %d threads\n", nthreads);
}
}
return 0;
}
















 5202
5202











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









