







目 录
(1)用到的库(模块):requests/urllib/Urllib3
一、前言
编写本博客的目的在于通过结构化记录自学爬虫方向的过程,在锻炼自己的代码实战能力与学习逻辑输出的表达的同时,也为对于爬虫领域不知从何下手的学者提供思路借鉴,欢迎学者以及前辈们给出意见或一起探讨与交流。
由于爬虫领域存在许多条款与约束,且容易涉及到法律与版权问题,因此,作者在此做出承诺:本博客所用于示例的代码和爬取的内容将严格遵守Robots协议,爬取内容仅用于个人学习与参考。此外,在博客中出现的一切涉及到具体地址的内容都将被模糊处理,博客仅展示学习思路与代码的编写逻辑。
基于此,我将尽可能地用阅读性强的语言,将我所学习到内容的内在逻辑,结合图表以通俗易懂的方式表达。
本博客将长期不定期更新,如有错误或bug也将反复修正。
二、Python的方向介绍——爬虫
作为一门新兴的计算机语言,Python以其强大的能力、简介的语言及高效的输出,获得了极高的热度,不管是程序员还是其他领域的学者,都希望通过python来增强自己的个人综合能力,在学业或是职场中加分。如图1所示,Python下面存在的方向多样,且用到的库不相通,因此不同的方向可能存在较大差异。但不管学习哪个方向,都必须掌握Python的基础语法,如果缺少一定的语法基础,读者在阅读本博客的时候可能会容易遇到许多因语法不懂而产生的问题,因此,本博客内容适用于有一定Python语法基础的学者共同学习。
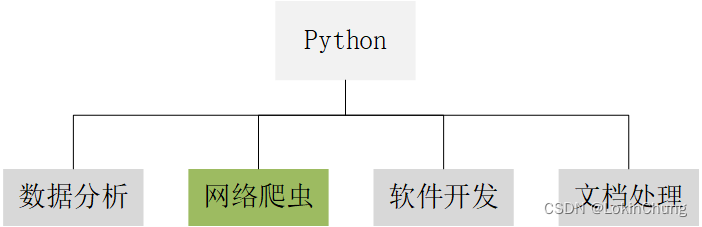
图1 Python方向
那么,Python爬虫是什么?为什么使用爬虫?爬虫的分类是什么?(参考其他学者的链接) 网络爬虫(又被称为网页蜘蛛,网络机器人),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。 通俗地讲,我们把互联网比作一张大蜘蛛网,每个站点资源比作蜘蛛网上的一个结点,爬虫就像一只蜘蛛,按照设计好的路线和规则在这张蜘蛛网上找到目标结点,获取资源。
三、开始学习爬虫
1. 搞懂爬虫的内在逻辑
写代码总是要根据其背后的逻辑编写,爬虫代码也一样。因此,在开始学习写代码之前,应该了解爬虫的逻辑。
不管是什么类型的爬虫代码,要进行什么样的操作,其本质都是模拟一个真实的人上网操作的过程。举个例子:假如A网页是一个公开的植物介绍网页,上面包含了成千上万种植物信息,而你需要收集1000种单叶子植物名称及其基本介绍信息,如果是手动来做的话,你的操作可以分为如下步骤:
①打开浏览器;
②输入A网页网址(即url);
③筛选单叶子植物;
④将页面显示的所有单叶子植物名字和简介复制下来;
⑤翻页,重复上一步骤,直至收集到一千种单叶子植物名字及其基本信息。
重复且单一的收集信息的工作,会造成大量不必要的浪费,而通过编写短短数行的爬虫代码,模拟上述行为,就能在几分钟内完成这一工作内容。通过观察上述步骤,可知我们在进行网页信息获取的操作时,主要可以概括为:登录网页(①②)、筛选信息(③)、获取信息(④⑤),据此,我们也可以获得爬虫代码的编写思路,但由于计算机语言的特殊性,内容与上述概括有些差异,爬虫代码的思路可以用图2表示。
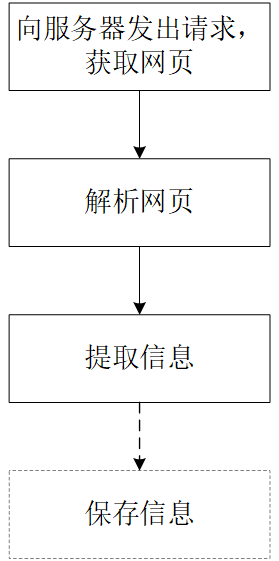
图2 Python爬虫代码编写思路
注:在图2中,前三个流程都是属于爬虫领域的流程,在“保存信息”的框用了虚线,是因为这部分内容是属于文档处理的内容,因为在提取信息后,通常需要将提取到的信息保存输出到一个文件中,而这部分内容不属于爬虫领域,却又经常和爬虫搭配使用,因此在后续的讲解中,这部分会给出代码和简要注释,有需要的同学也可以直接取用。
在了解了爬虫代码的编写逻辑后,就可以按步骤拆分代码了。值得注意的是,由于Python可以用到大量的库,而不同的库又有不同的功能,因此在图2的爬虫代码编写思路中,每一步都将用到不同的库。此外,同一种操作还可以使用不同的库——就类似于面对同一道题,有人喜欢用图解法,有人喜欢用函数法——不同的库所对应的方法与思路也不相同,而这也恰恰体现了编程的多样性。代码的思路成千上万,就如同条条大路通罗马,只要抓住背后的逻辑进行,就可以顺利前进。在后续的学习中,如果遇到有任何问题,那么找到问题的最快方式就是找到出现问题的地方所对应的逻辑点,一步步发现问题并解决。
2. 向服务器发出请求,获取网页
(1)用到的库(模块):requests/urllib/Urllib3
requests:Python中实现HTTP请求的一种方式,requests是第三方模块,该模块在实现HTTP请求时要比urllib模块简化很多,操作更加人性化。在使用requests模块时,需要通过执行pip install requests代码进行该模块的安装。
urllib:Python自带的模块,该模块中提供了一个urlopen()方法,通过该方法指定URL发送网络请求来获取数据。urllib提供了多个子模块,具体的模块名称如下表所示:
| 模块名称 | 描述 |
|---|---|
| urllib.requestt | 该模块定义了打开URL(主要是HTTP)的方法和类,例如,身份验证、重定向、cookie等 |
| urllib.error | 该模块中主要包含异常类,基本的异常类是URLError |
| urllib.parse | 该模块定义的功能分为两大类:URL解析和URL引用 |
| urllib.robotparser | 该模块用于解析robot.txt文件 |
(2)代码示例
示例1:
#requests模块
import requests
res1 = requests.get('这里输入网站url')
print(res1.status_code) #状态码
print(res1.url) #请求url
print(res1.headers) #头部信息
print(res1.cookies) #cookie信息
print(res1.text) #打印文本形式的网页代码
print(res1.content) #打印字节流形式的网页代码
输出结果(url以度娘大大在上为例):

示例2:
#urllib模块
import urllib.request
res2 = urllib.request.urlopen('这里输入网站url')
html = res2.read() #读取网页代码
print(html) #打印读取内容输出结果:

至此,爬虫的第一步已经迈出去了,我们成功向指定网页的服务器发起了请求并获得了网页的相关信息。更多关于模块的使用方法(如响应代码、头部信息等)的介绍可通过搜索引擎或者查找python相关手册可自行了解。
3.将获取到的网页内容进行解析
我们在使用相关的模块对指定网页的服务器发出获取的请求后,会得到服务器的响应。一般来说,我们能够正常打开的网页,使用上述两个模块方法都能够正常获取,因为爬虫的本质就是模拟人的操作(正常情况下,普通互联网用户能够打开的网页就是我们大多数人能够打开的网页,通常在Robots协议的范围内),敲黑板,这里是重点回顾。
在获得网页内容后,还不能够直接使用,因为通过相关模块和方法获取到的内容不是我们能够直接阅读的内容,他们是HTML格式的文本。那么什么是HTML格式呢?它是一种网页开发者在开发网页时使用的格式,它包括一系列标签,通过这些标签可以将网络上的文档格式统一,使分散的互联网资源资源连接为一个逻辑整体。我们能够看到的网页基本上是使用HTML格式进行设计与编写的,因此在本小节对网页内容的解析中,主要对HTML格式语言的文本进行解析。
为了使读者更好地理解,在这里我将简单介绍一下HTML语言。首先,最直观的方法就是在任意正在打开的网页按F12打开开发者工具(或在任意网页右键,单击“检查”;其他系统可自行搜索打开开发者工具的方法,这里不作过多赘述),选中“元素”,如下图所示。
接着就会看到类似以下内容的画面,这就是由HTML语言组成的网页内容。这时使用鼠标在上面滑动,可以发现左侧网页的内容会对应被指出。当我们向服务器发出获取网页的请求,获取到的网页内容就是这些内容。
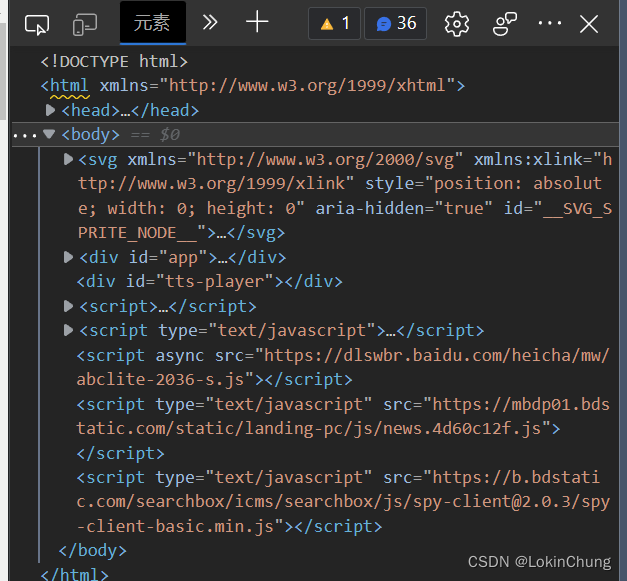
如果想要爬取某网页的某段话,使用下图所示的工具进行特定内容的检索。
点击红框的内容,再在左侧点击想要爬取的内容,此时开发者工具窗口栏内会快速转跳到某个地方。如果想要批量爬取,只需要观察HTML文本的格式规律就可以使用循环语言进行爬取。
在获得了HTMl文本并知道如何找到爬取的内容后,开始对文本进行解析。在对HTML文本进行解析中,最常用的是一个叫 Beautiful Soup 的Python库。
(1)HTML解析之Beautiful Soup
Bcautiful Soup 是一个用于从 HTML 和XMI 文件中提取数据的Python 库。Beautiful Soup 提供一些简单的、函数用来处理导航、搜素、修改分析树等功能。Bcautiful Soup 模块中的查找提取功能非常强大,而且非常便捷,它通常可以节省程序员大量的工作时问。
Beautfal Soup 自动将输入文档转换为 Unicode 编码,输出文档转换为 UTF-8 编码。我们不需要考编码方式,除非文指没有指定一个编码方式,这时,Bcauiful Sourp 就不能自动识别编码方式了,这时需要说明以下原始编码方式就可以了。
目前,Beautiful Soup库的发行已经到了第四个版本,在使用之前需要安装bs4(缩写)库,在控制台中使用命令 pip install bs4 可以快速安装。在安装完成后,就可以使用该库对网页内容进行解析了。
(2)代码示例
由于涉及到行文规范问题,先创建一个模拟HTML代码的字符串(网页爬取的内容也是类似):
html_doc =
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b>‹/p>
<p class="story">Once upon a time there were three little sisters; and their names were
< a href="http://example.com/elsie" class-"sister" id="link">Elsie</a>,
< a href="http://example.com/lacie" class="sister" id-"link2">Lacie</a> and
<a href-"http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story"›...</p >Python代码示例如下:
from bs4 import BeautifulSoup #导入Beautiful Soup库
#创建模拟HTML代码的字符串
html_1 = '''
<html><head><title>The Dormouse's story</title></head>
<body>
<p class="title"><b>The Dormouse's story</b>‹/p>
<p class="story">Once upon a time there were three little sisters; and their names were
< a href="http://example.com/elsie" class-"sister" id="link">Elsie</a>,
< a href="http://example.com/lacie" class="sister" id-"link2">Lacie</a> and
<a href-"http://example.com/tillie" class="sister" id="link3">Tillie</a>;
and they lived at the bottom of a well.</p>
<p class="story"›...</p >
'''
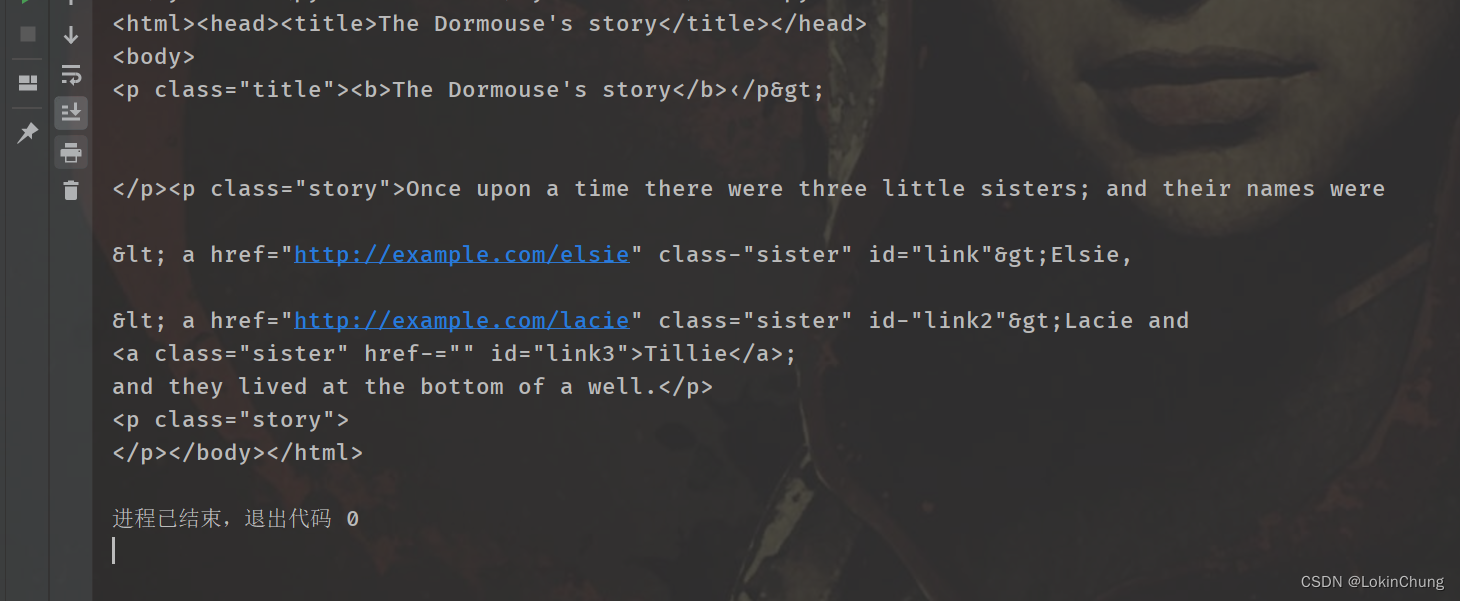
soup = BeautifulSoup(html_1,features="lxml")
print(soup)运行结果:
更多示例可以参考:python-代码实战-爬取新闻标题_LokinChung的博客-CSDN博客_python爬取新闻标题
在使用Beautiful Soup对HTML文本进行解析后,就可以使用find方法提取任意想要爬取的内容了,后续通过相应的文本处理就可以另存为一个文件,这些内容就属于爬虫的另一个分支了。
四、爬虫开发框架
爬虫框架就是一些爬虫项目的半成品,可以将一些爬虫常用的功能写好,然后留下一些接口。在不同的爬虫项目中,调用适合自己项目的接口,再编写少量的代码实现自己需要的功能。因为框架中已经实现了爬虫的常用功能,所以能够为开发人员节省很多精力和时间。
由于本博客仅仅只是对爬虫进行一个简单的入门教学,因此这部分也只是做一个简要介绍。下面介绍几个常用的爬虫框架。
1.Scrapy爬虫框架
Scrapy是一套比较成熟的Python爬虫框架,简单轻巧,可以高效爬取Web页面并从页面中提取结构化的数据。除此之外,它是一套开源的框架,所以在使用的时候不需要担心收取费用的问题。Scrapy官网的页面如下:
2.Crawley爬虫框架
Crawley也是使用python开发出来的一款爬虫框架,该框架致力于改变人们从互联网中提取数据的方式,让大家可以更高效地从互联网中爬取对应内容。
3.PySpider爬虫框架
相对于 Sorapy框架而言,PySprider框架还是渐秀。ryspider框架采用Python 语言编写,分后式梁构,支持多种数据库后路,组大的webUr 支持脚本编辑器,任务监视器,项目管理器以及结果查看器。
五、小结
至此,《Python爬虫从零基础到入门》终于到了结尾部分。最开始写这篇博客的目的除了进行知识的分享,也希望自己能够在不断学习的同时回过头来。直到现在,我去看我写的第一个爬虫代码,仍觉得很不可思议,由于我不是在这个方向上继续深入学习,因此相关模块和方法也会随着时间的痕迹变淡,这更需要我长期回过头来巩固自己的代码实战能力。
在本博客中,关于模块和方法的使用教程相对较少,因为这篇博客的重点在于阐述爬虫的思路,所以相关模块和库只做了最简要的介绍,具体模块和库的使用可以通过查询Python文档或其他学者的博客进行进一步的阅读学习。
















 2103
2103











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











