







 超级会员免费看
超级会员免费看
 本文介绍了如何使用Python爬取信用中国网站上的企业行政许可、行政处罚和守信激励等内容,并将数据整理成Excel表格。示例查询了国网江苏省电力有限公司江阴市供电分公司的相关信息。
本文介绍了如何使用Python爬取信用中国网站上的企业行政许可、行政处罚和守信激励等内容,并将数据整理成Excel表格。示例查询了国网江苏省电力有限公司江阴市供电分公司的相关信息。
最近爬取了信用中国,输出里面的行政许可内容,行政处罚,守信激励的内容,并以excel形式显示
效果图:

第一个作业就是信用中国里面能够输入一个公司,输出里面的行政许可内容,行政处罚,守信激励,失信惩戒,重点关注,资质资格,风险提示,其他。里面的内容,并以excel形式显示
网址:https://www.creditchina.gov.cn/
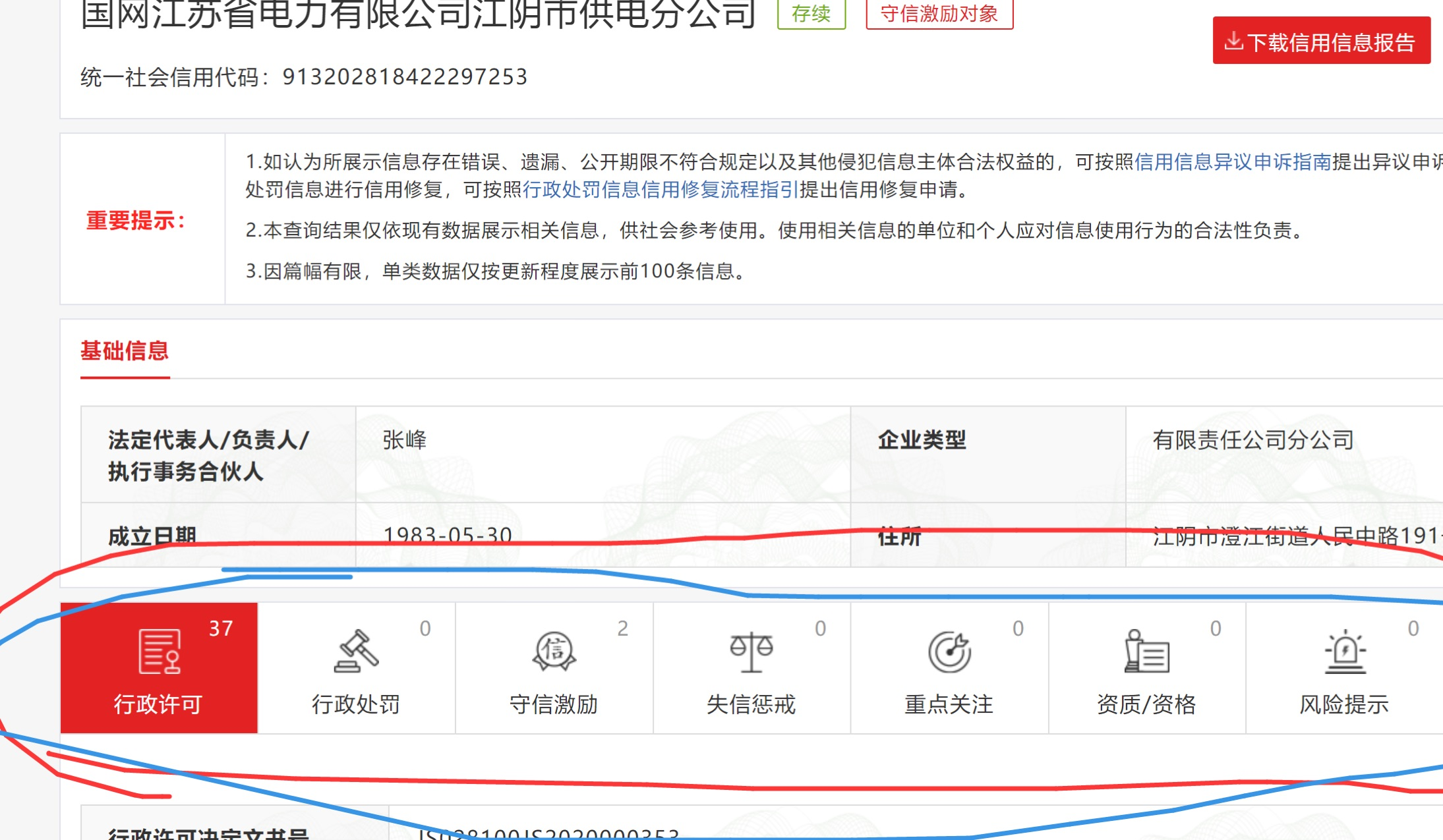
就比如查询:国网江苏省电力有限公司江阴市供电分公司
下面是我写的爬代码,逻辑不写了。
最近爬取了信用中国,输出里面的行政许可内容,行政处罚,守信激励的内容,并以excel形式显示
效果图:
第一个作业就是信用中国里面能够输入一个公司,输出里面的行政许可内容,行政处罚,守信激励,失信惩戒,重点关注,资质资格,风险提示,其他。里面的内容,并以excel形式显示
网址:https://www.creditchina.gov.cn/
就比如查询:国网江苏省电力有限公司江阴市供电分公司
下面是我写的爬代码,逻辑不写了。
 407
407

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文


























