







过拟合(高方差)
当我们的数据无法满足我们模型的复杂度时会过拟合,也就是我们的变量过多,模型很复杂,导致在我们的训练集中我们的将我们的训练样本拟合的非常好,但是在测试样本中测试的准确率比较低,模型的泛化能力差,就会出现过拟合的问题。
通俗一点地来说过拟合就是模型把数据学习的太彻底,以至于把噪声数据的特征也学习到了,这样就会导致在后期测试的时候不能够很好地识别数据,即不能正确的分类,模型泛化能力太差
解决方法:正则化,增加训练样本,清洗数据(数据可能不纯)
欠拟合(高偏差)
欠拟合就是模型没有很好地捕捉到数据特征,不能够很好地拟合数据
解决方法:添加其他特征项(可能因为特种项不足),添加多项式特征(例如将线性模型通过添加二次项或者三次项使模型泛化能力更强),减少正则化参数
欠拟合-过拟合与偏差-方差关系
名称 欠拟合 过拟合 备注
偏差 一定大 较大 主要针对验证机
方差 一定小 一定大 主要针对验证机
方差(Variance):
描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,数据的分布越分散,如下图右列所示。
偏差(Bias):
描述的是预测值(估计值)的期望与真实值之间的差距。偏差越大,越偏离真实数据,如下图第二行所示。
方差偏差图:
[外链图片转存失败(img-cwF6h2g8-1563508475983)(https://raw.githubusercontent.com/OneStepAndTwoSteps/data_mining_analysis/master/static/%E6%96%B9%E5%B7%AE%E3%80%81%E5%81%8F%E5%B7%AE/1-1.png)]
低偏差低方差时 ,是我们所追求的效果,此时预测值正中靶心(最接近真实值),且比较集中(方差小)。
低偏差高方差时 ,预测值基本落在真实值周围,但很分散,此时方差较大,说明模型的稳定性不够好。
高偏差低方差时 ,预测值与真实值有较大距离,但此时值很集中,方差小;模型的稳定性较好,但预测准确率不高,处于“一如既往地预测不准”的状态。
高偏差高方差时 ,是我们最不想看到的结果,此时模型不仅预测不准确,而且还不稳定,每次预测的值都差别比较大。
欠拟合-过拟合与偏差-方差关系
名称 欠拟合 过拟合 备注
偏差 一定大 较大 主要针对验证机
方差 一定小 一定大 主要针对验证机
解决方案 方差,偏差过高如何解决:
1.获得更多的训练实例——解决高方差
2.尝试减少特征的数量——解决高方差
3.尝试获得更多的特征——解决高偏差
4.尝试增加多项式特征——解决高偏差
5.尝试减少正则化程度 λ——解决高偏差
6.尝试增加正则化程度 λ——解决高方差
模型评估指标:准确率(Accuracy), 精确率(Precision), 召回率(Recall) 和 F1-Measure.
准确率(Accuracy), 精确率(Precision), 召回率(Recall) 和 F1-Measure.这四个评价指标常用来评估机器学习(ML), 自然语言处理(NLP), 信息检索(IR)等领域。
(注:相对来说,IR 的 ground truth 很多时候是一个 Ordered List, 而不是一个 Bool 类型的 Unordered Collection,在都找到的情况下,排在第三名还是第四名损失并不是很大,而排在第一名和第一百名,虽然都是“找到了”,但是意义是不一样的,因此更多可能适用于 MAP 之类评估指标.)
本文将简单介绍其中几个概念. 中文中这几个评价指标翻译各有不同, 所以一般情况下推荐使用英文.
现在我先假定一个具体场景作为例子.
假如某个班级有男生 80 人, 女生20人, 共计 100 人. 目标是找出所有女生. 现在某人挑选出 50 个人, 其中 20 人是女生, 另外还错误的把 30 个男生也当作女生挑选出来了. 作为评估者的你需要来评估(evaluation)下他的工作.
首先我们可以计算准确率(accuracy), 其定义是: 对于给定的测试数据集,分类器正确分类的样本数与总样本数之比. 也就是损失函数是0-1损失时测试数据集上的准确率[1].
这样说听起来有点抽象,简单说就是,前面的场景中,实际情况是那个班级有男的和女的两类,某人(也就是定义中所说的分类器)他又把班级中的人分为男女两类. accuracy 需要得到的是此君分正确的人占总人数的比例. 很容易,我们可以得到:他把其中70(20女+50男)人判定正确了, 而总人数是100人,所以它的 accuracy 就是70 %(70 / 100).
由准确率,我们的确可以在一些场合,从某种意义上得到一个分类器是否有效,但它并不总是能有效的评价一个分类器的工作.
举个例子, google 抓取了 100个特殊页面,而它索引中共有10,000,000个页面, 随机抽一个页面,分类下, 这是不是特殊页面呢?如果以 accuracy 来判断我的工作,那我会把所有的页面都判断为"不是 特殊页面", 因为我这样效率非常高(return false, 一句话), 而 accuracy 已经到了99.999%(9,999,900/10,000,000), 完爆其它很多分类器辛辛苦苦算的值, 而我这个算法显然不是需求期待的, 那怎么解决呢?
这就是 precision, recall 和 f1-measure 出场的时间了.
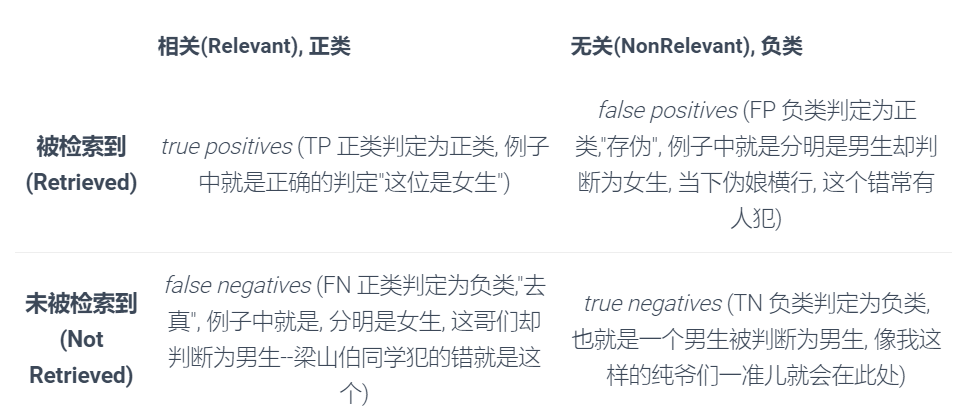
再说 precision, recall 和 f1-measure 之前, 我们需要先需要定义 TP, FN, FP, TN 四种分类情况.
这里先介绍下数据预测的四种情况:TP、FP、TN、FN。我们用第二个字母 P 或 N 代表预测为正例还是负例,P 为正,N 为负。第一个字母 T 或 F 代表的是预测结果是否正确,T 为正确,F 为错误。
按照前面例子, 我们需要从一个班级中的人中寻找所有女生, 如果把这个任务当成一个分类器的话, 那么女生就是我们需要的, 而男生不是, 所以我们称女生为"正类", 而男生为"负类".
相关(Relevant), 正类 无关(NonRelevant), 负类
被检索到(Retrieved) true positives false positives
未被检索到(Not Retrieved) false negatives true negatives
true positive: (TP 正类判定为正类, 例子中就是正确的判定"这位是女生")
false positives:(FP 负类判定为正类,"存伪", 例子中就是分明是男生却判断为女生, 当下伪娘横行, 这个错常有人犯)
false negatives:(FN 正类判定为负类,"去真", 例子中就是, 分明是女生, 这哥们却判断为男生--梁山伯同学犯的错就是这个)
true negatives: (TN 负类判定为负类, 也就是一个男生被判断为男生, 像我这样的纯爷们一准儿就会在此处)
代入这张表, 我们可以很容易得到这几个值:
相关(Relevant),正类 无关(NonRelevant), 负类
被检索到(Retrieved) TP=20 FP=30
未被检索到(Not Retrieved) FN=0 TN=50
精确率(precision)的公式是P = TP/(TP+FP),也称查准率。
它计算的是所有"正确被检索的结果(TP)"占所有"实际被检索到的(TP+FP)"的比例.对应上面就是判断为女生正确的人数在判断为女生的所有人数中的比例
在例子中就是希望知道:得到的所有人中, 正确的人(也就是女生)占有的比例. 所以其 precision 也就是40%(20女生/(20女生+30误判为女生的男生)).
召回率(recall)的公式是R =TP/(TP+FN), 也称查全率。
它计算的是所有"正确被检索的结果(TP)"占所有"应该检索到的结果(TP+FN)"的比例.对应上面是女生被正确识别出来的个数占女生总数的比例。
在例子中就是希望知道:得到的女生占本班中所有女生的比例, 所以其 recall 也就是100%(20女生/(20女生+ 0 误判为男生的女生))
为什么要将精确率和召回率结合起来考虑呢?
查全率为什么要结合查准率:
假如有这样一种状况,我们如果将所有的人都识别成了女生,此时我们的召回率公式中,我们的FN就是0,因为没有将正类判定为为负类。此时我们的召回率就是TP/(TP+0)=100%,但是此时我们的预判率会很高,所以我们需要加上精确率来帮助我们进行辅助判断。
查准率为什么要结合查全率:
假如现在我们教室有100人,男生为50人,女生为50人,经过模型预测之后识别出女生人数为30人(其中女生全部判断正确),男生人数为70人,我们将女生识别为正类,求我们该例子中的查准率和查全率。
此时根据公式: Precision=TP/TP+FP = 30/30+0=100% Recall=30/30+20=60% 需要结合查全率进行判断
F1 综合精确率和召回率,可以更好的评估模型的好坏。
F1值就是精确值和召回率的调和均值, 也就是 2/F1=1/P+1/R --> F1=2PR/(P+R)=2TP/(2TP+FP+FN) ,F1 作为精确率 P 和召回率 R 的调和平均,数值越大代表模型的结果越好。
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











