







GoogleNet
GoogLeNet是2014年Christian Szegedy提出的一种全新的深度学习结构,在这之前的AlexNet、VGG等结构都是通过增大网络的深度(层数)来获得更好的训练效果,但层数的增加会带来很多负作用,比如overfit、梯度消失、梯度爆炸等。inception的提出则从另一种角度来提升训练结果:能更高效的利用计算资源,在相同的计算量下能提取到更多的特征,从而提升训练结果。

GoogLeNet称下列这一部分为inception,整个GoogLeNet就是由多个不同的inception块构成的。inception结构的主要贡献有两个:一是使用1x1的卷积来进行升降维;二是在多个尺寸上同时进行卷积再聚合。
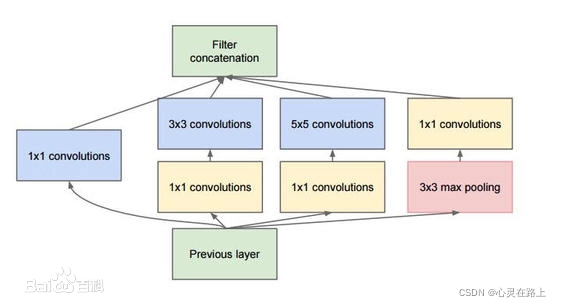
- 1x1卷积
- 作用1:在相同尺寸的感受野中叠加更多的卷积,能提取到更丰富的特征。
- 作用2:使用1x1卷积进行降维,降低了计算复杂度。
- 多个尺寸上进行卷积再聚合
- 在直观感觉上在多个尺度上同时进行卷积,能提取到不同尺度的特征。特征更为丰富也意味着最后分类判断时更加准确。
- 利用稀疏矩阵分解成密集矩阵计算的原理来加快收敛速度。
- Hebbin赫布原理.因为训练收敛的最终目的就是要提取出独立的特征,所以预先把相关性强的特征汇聚,就能起到加速收敛的作用。
代码实现
lass InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
#这里的1408可以注释掉下面这句以及forward中的最后两句,然后print(x.size())得到,也可以直接在这随便填一个数等着报错,然后再填进去
self.fc = nn.Linear(1408, 10) #1*28*28 → 10*24*24 → 10*12*12 → 88*12*12 → 20*8*8 → 88*4*4=1408
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
# print(x.size())
return x
model = Net()
实现案例
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./datasets/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./datasets/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class InceptionA(nn.Module):
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch3x3_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
#这里的1408可以注释掉下面这句以及forward中的最后两句,然后print(x.size())得到,也可以直接在这随便填一个数等着报错,然后再填进去
self.fc = nn.Linear(1408, 10) #1*28*28 → 10*24*24 → 10*12*12 → 88*12*12 → 20*8*8 → 88*4*4=1408
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
# print(x.size())
return x
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(2):
train(epoch)
test()
ResNet
概念
ResNet又名残差神经网络,指的是在传统卷积神经网络中加入残差学习(residual learning)的思想,解决了深层网络中梯度弥散和精度下降(训练集)的问题,使网络能够越来越深,既保证了精度,又控制了速度。
出发点
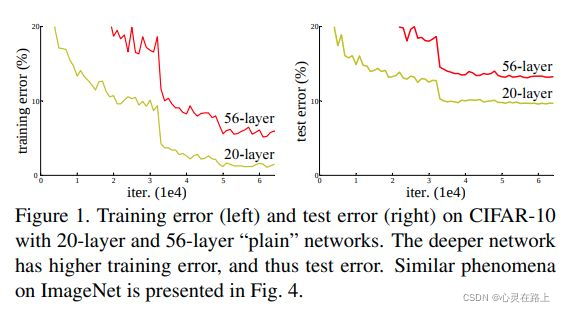
随着网络的加深,梯度弥散问题会越来越严重,导致网络很难收敛甚至无法收敛。通过包括网络初始标准化,数据标准化以及中间层的标准化(Batch Normalization)等办法进行解决梯度弥散问题。但是网络加深还会带来另外一个问题:出现训练集准确率下降的现象,如下图,
残差学习
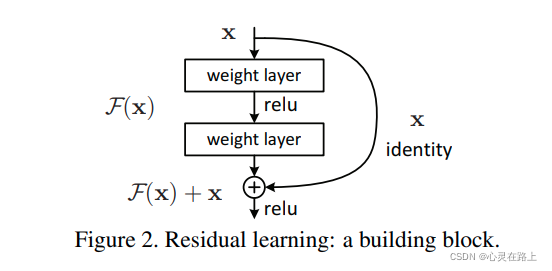
残差学习的思想就是上面这张图,可以把它理解为一个block,定义如下:
y = F ( x , W i ) + x y = F(x,W_i)+x y=F(x,Wi)+x
残差学习的block一共包含两个分支或者两种映射(mapping):
-
identity mapping,指的是上图右边那条弯的曲线。顾名思义,identity mapping指的就是本身的映射,也就是 x x x 自身;
-
residual mapping,指的是另一条分支,也就是 F ( x ) F(x) F(x)部分,这部分称为残差映射,也就是 y − x y-x y−x 。
维度不相同怎么办?
作者提出在identity mapping部分使用1x1卷积进行处理,表示如下:
y
=
F
(
x
,
W
i
)
+
W
s
x
y = F(x,W_i)+W_sx
y=F(x,Wi)+Wsx其中,
W
s
W_s
Ws指的是1x1卷积操作。
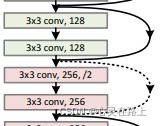
由上图,我们可以清楚的看到实线和虚线两种连接方式, 实线的Connection部分 (第一个粉色矩形和第三个粉色矩形) 都是执行3x3x64的卷积,他们的channel个数一致,所以采用计算方式: y = F ( x ) + x y = F(x)+x y=F(x)+x ,
虚线的Connection部分 (第一个绿色矩形和第三个绿色矩形) 分别是3x3x64和3x3x128的卷积操作,他们的channel个数不同(64和128),其中W是卷积操作,用来调整x的channel维度,目的就是为了降低参数的数目,
import torch
import torch.nn as nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./datasets/mnist/', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)
test_dataset = datasets.MNIST(root='./datasets/mnist/', train=False, download=True, transform=transform)
test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)
class ResidualBlock(torch.nn.Module):
def __init__(self, channels):
super(ResidualBlock, self).__init__()
self.channels = channels
self.cov1 = torch.nn.Conv2d(channels, channels,
kernel_size = 3, padding = 1)
self.cov2 = torch.nn.Conv2d(channels, channels,
kernel_size = 3, padding = 1))
def forward(self, x):
y = F.relu(self.cov1(x))
y = self.conv2(y)
return F.relue(x+y)
model = Model()
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 16, kernel_size=5)
self.conv2 = nn.Conv2d(16, 32, kernel_size=5)
self.mp = nn.MaxPool2d(2)
self.rblock1 = ResidualBlock(16)
self.rblock2 = ResidualBlock(16)
self.fc = nn.Linear(512, 10)
def forward(self, x):
in_size = x.size(0)
x = F.relu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.relu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
# print(x.size())
return x
model = Net()
criterion = torch.nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, target = data
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
if batch_idx % 300 == 299:
print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('accuracy on test set: %d %% ' % (100*correct/total))
if __name__ == '__main__':
for epoch in range(2):
train(epoch)
test()
这里分享下圣经和ResNet的PDF文件供大家下载。
https://www.aliyundrive.com/s/WpjJgDMqtfK
点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。















 2270
2270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









