









本文首先介绍了Logistic模型的原理,然后尝试用Logistic曲线拟合疫情,虽然疫情已经接近尾声,模型的预测意义并不大,但仍然可以通过回溯过去发现有趣的现象。
文章目录
1. Logistic模型
逻辑斯蒂方程(Logistic function)由比利时数学家兼生物学家皮埃尔·弗朗索瓦·韦吕勒(Pierre Francois Verhulst)在研究人口增长模型时提出,是对马尔萨斯人口模型(Malthus, 1798)的改进。下图可以直观看出两者的区别,下面将对两种模型作详细介绍。
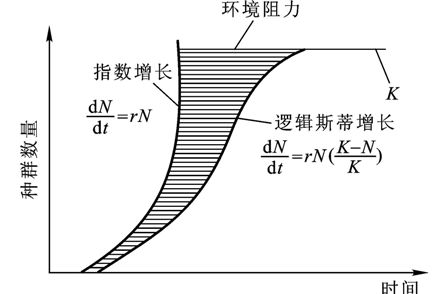
1.1 马尔萨斯人口模型
马尔萨斯人口模型假定人口增长率
r
r
r保持不变,
d
P
d
t
=
r
P
\frac{\mathrm{d}P}{\mathrm{d}t} = rP
dtdP=rP
其中 P P P表示人口数,是时间 t t t的函数。
求解微分方程可以得到人口随时间变化的函数,
P
(
t
)
=
P
0
e
r
t
P(t) = P_0 e^{rt}
P(t)=P0ert
其中 P 0 P_0 P0表示第0期人口。
不难发现,人口呈现指数增长,即J型曲线。然而现实中受到自然资源约束以及疾病等因素影响,人口增长率不可能一直保持不变。
1.2 Logistic增长模型
皮埃尔在马尔萨斯人口模型的基础上进行了改进,将人口增长率设为
r
(
1
−
P
K
)
r(1-\frac{P}{K})
r(1−KP),其中
K
K
K可以理解为环境最大允许的最大人口数量。此时,当人口
P
P
P越接近于
K
K
K时,增长率越低,即人口增长率随人口数量的增加而线性减少。
d
P
d
t
=
r
(
1
−
P
K
)
P
\frac{\mathrm{d}P}{\mathrm{d}t} = r(1-\frac{P}{K})P
dtdP=r(1−KP)P
求解微分方程可以得到人口随时间变化的函数,
P
(
t
)
=
K
1
+
(
K
P
0
−
1
)
e
−
r
t
P(t) = \frac{K}{1+(\frac{K}{P_0}-1)e^{-rt}}
P(t)=1+(P0K−1)e−rtK
其中 P 0 P_0 P0表示第0期人口。
如下左图,该曲线描述的人口增长呈现S型,增长速率随时间先增后减,在 P = K / 2 P=K/2 P=K/2处增长最快。注意到,增长速率( d P d t \frac{\mathrm{d}P}{\mathrm{d}t} dtdP)表示人口当期变化的绝对数值,而增长率( d P d t / P \frac{\mathrm{d}P}{\mathrm{d}t} /P dtdP/P)表示人口变化量与当期人口的比值。
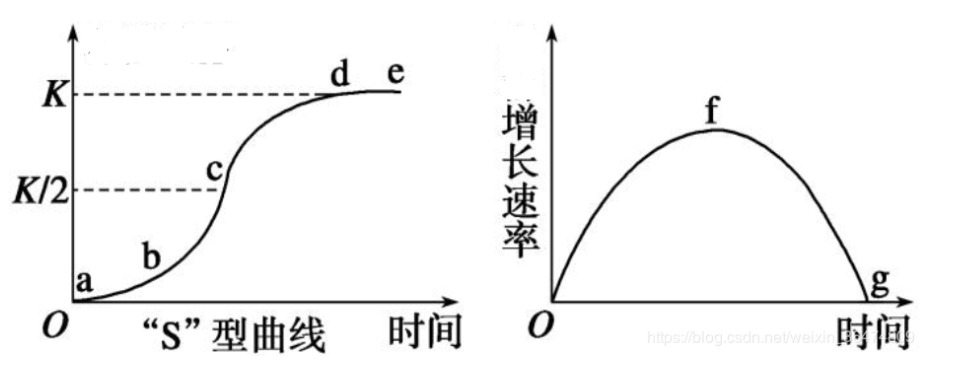
相比于马尔萨斯人口模型,Logistic增长模型更加符合实际,该模型常常被应用于描述种群、传染病增长以及商品销售量预测等领域。
2. 用Logistic模型拟合疫情
考虑到湖北省内与湖北省外存在异质性,下面将用Logistic模型分别对湖北省与湖北省外的累计确诊人数进行拟合。首先需要获取累计确诊人数,数据来源为WindQuant提供的Wind数据接口,更多数据下载方法见获取COVID-19疫情历史数据的n种方法。
然后使用Scipy.optimezi库的curve_fit函数对Logistic曲线进行非线性最小二乘拟合。待定参数包括
K
、
P
0
、
r
K、P_0、r
K、P0、r三个,根据最小化MSE准则,采用网格调参的方式寻找最优参数:对最大容量
K
K
K以步长1遍历(10000, 80000)区间,对增长率
r
r
r以步长0.01遍历(0, 1)区间。
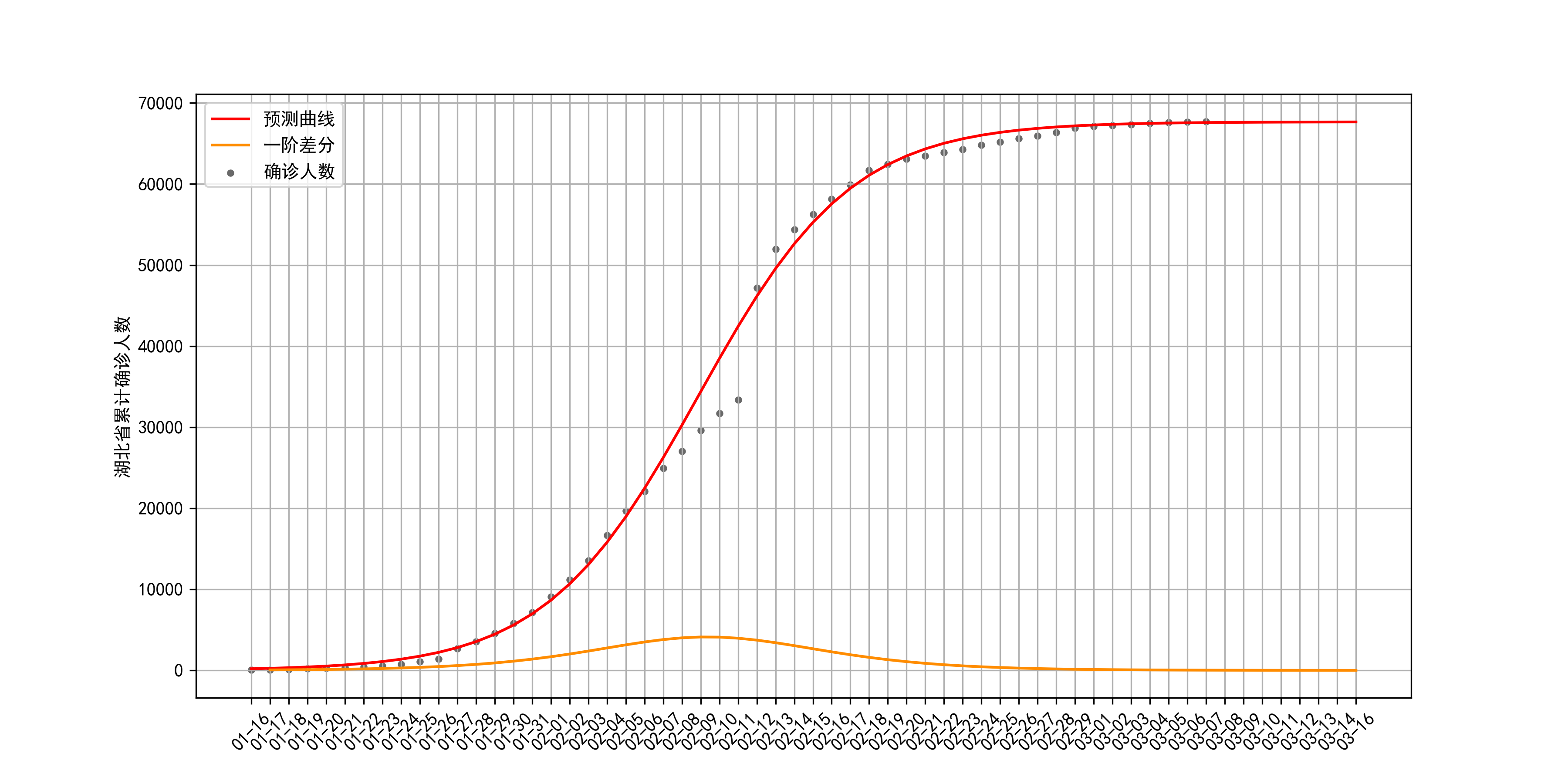
2.1 湖北省
湖北省疫情拟合结果:最大容量
K
K
K为67667,增长率
r
r
r为0.24。疫情的拐点发生在2月8日前后,这也是疫情增长最快一段时期,在这段时间内,由于疫情的快速增长和医疗资源的相对匮乏,官方公布的确诊人数失真严重。从拟合结果来看,当前疫情已经到达尾声。
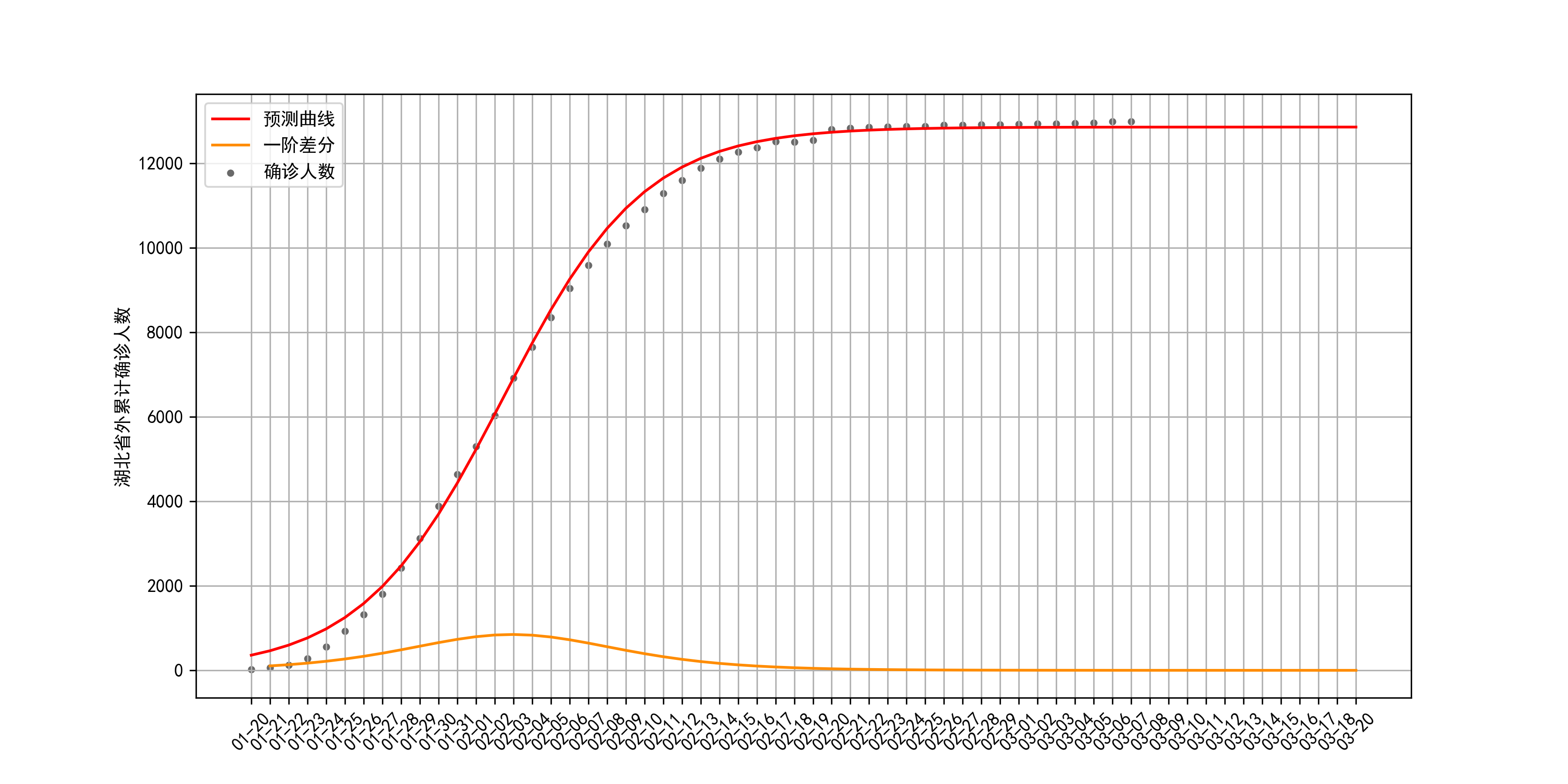
2.2 湖北省外
省外疫情拟合结果:最大容量
K
K
K为12857,增长率
r
r
r为0.26。疫情的拐点发生在2月3日前后,当前疫情也已经到达尾声。
3. Python实现
下面直接给出Python代码,注意第17行需要将userid修改为自己的WindQuant用户ID,当然也可以对代码略作修改后读取本地数据或者其他数据源。微信搜索公众号PurePlay,后台回复Logistic,即可获取完整的数据、代码以及结果文件。
import numpy as np
import pandas as pd
import datetime as dt
import time
import requests
import json
import matplotlib.pyplot as plt
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
mpl.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
from scipy.optimize import curve_fit
from sklearn.metrics import mean_squared_error
def load_data():
# 下载原始数据,数据来源为WindQuant提供的Wind数据接口
# "Nation","Hubei","Outside",分别表示全国、省内和省外的累计确诊人数
userid = "94ac606a-c220-46af-abf3" # 此处仅为无效id,需要改为自己的WindQuant用户ID
indicators = "S6274770,S6275447,S6291523"
factors_name = ["Nation","Hubei","Outside"]
startdate = "2020-01-16"
enddate = dt.datetime.strftime(dt.date.today() + dt.timedelta(-1),"%Y-%m-%d")# 数据的结束日期设置为昨天
url = '''https://www.windquant.com/qntcloud/data/edb?userid={}&indicators={}&startdate={}&enddate={}'''.format(
userid,indicators,startdate,enddate)
response = requests.get(url)
data = json.loads(response.content.decode("utf-8"))
try:
time_list = data["times"]
value_list = data["data"]
for i in range(len(time_list)):
time_list[i] = time.strftime("%Y-%m-%d", time.localtime(time_list[i]/1000))
result = pd.DataFrame(columns=factors_name, index = time_list)
for i in range(len(factors_name)):
result[factors_name[i]] = value_list[i]
print(result)
result.to_csv(r"Data\LogisticData.csv")
return result
except Exception as e:
print("服务异常")
def data_abstract(result,area):
# result:下载的原始数据
# area:“Hubei”或“Outside”,分别返回省内和省外的累计确诊人数
y_data = result[area]
# 删除缺失值并转换为float型
y_data[y_data == 'NaN'] = np.NAN
y_data = y_data.dropna()
y_data = y_data.astype(float)
global first_date # 后续数据可视化需要
first_date = dt.datetime.strptime(y_data.index[0],'%Y-%m-%d')
# 返回与数据集等长的从0开始的时间序列作为logistic函数的自变量
x_data = np.asarray(range(0,len(y_data)))
return x_data, y_data
hyperparameters_r = None
hyperparameters_K = None
def logistic_increase_function(t,P0):
# logistic生长函数:t:time P0:initial_value K:capacity r:increase_rate
# 后面将对r和K进行网格优化
r = hyperparameters_r
K = hyperparameters_K
exp_value = np.exp(r * (t))
return (K * exp_value * P0) / (K + (exp_value - 1) * P0)
def fitting(logistic_increase_function, x_data, y_data):
# 传入要拟合的logistic函数以及数据集
# 返回拟合结果
popt = None
mse = float("inf")
i = 0
# 网格搜索来优化r和K参数
r = None
k = None
k_range = np.arange(10000, 80000, 1000)
r_range = np.arange(0, 1, 0.01)
for k_ in k_range:
global hyperparameters_K
hyperparameters_K = k_
for r_ in r_range:
global hyperparameters_r
hyperparameters_r = r_
# 用非线性最小二乘法拟合
popt_, pcov_ = curve_fit(logistic_increase_function, x_data, y_data, maxfev = 4000)
# 采用均方误准则选择最优参数
mse_ = mean_squared_error(y_data, logistic_increase_function(x_data, *popt_))
if mse_ <= mse:
mse = mse_
popt = popt_
r = r_
k = k_
i = i+1
print('\r当前进度:{0}{1}%'.format('▉'*int(i*10/len(k_range)/len(r_range)),int(i*100/len(k_range)/len(r_range))), end='')
print('拟合完成')
hyperparameters_K = k
hyperparameters_r = r
popt, pcov = curve_fit(logistic_increase_function, x_data, y_data)
print("K:capacity P0:initial_value r:increase_rate")
print(hyperparameters_K, popt, hyperparameters_r)
return hyperparameters_K, hyperparameters_r, popt
def predict(logistic_increase_function, popt):
# 根据最优参数进行预测
future = np.linspace(0, 60, 60)
future = np.array(future)
future_predict = logistic_increase_function(future, popt)
diff = np.diff(future_predict)
diff = np.insert(diff, 0, np.nan)
return future, future_predict, diff
def visualize(area, future, future_predict, x_data, y_data, diff):
# 绘图
x_show_data_all = [(first_date + (dt.timedelta(days=i))).strftime("%m-%d") for i in future]
x_show_data = x_show_data_all[:len(x_data)]
plt.figure(figsize=(12, 6), dpi=300)
plt.scatter(x_show_data, y_data, s=35, marker='.', c = "dimgray", label="确诊人数")
plt.plot(x_show_data_all, future_predict, 'r', linewidth=1.5, label='预测曲线')
plt.plot(x_show_data_all, diff, "r", c='darkorange',linewidth=1.5, label='一阶差分')
plt.tick_params(labelsize=10)
plt.xticks(x_show_data_all)
plt.grid() # 显示网格
plt.legend() # 指定legend的位置右下角
ax = plt.gca()
for label in ax.xaxis.get_ticklabels():
label.set_rotation(45)
if area == "Hubei":
plt.ylabel('湖北省累计确诊人数')
plt.savefig(r"Data\Hubei.png",dpi=300)
else:
plt.ylabel('湖北省外累计确诊人数')
plt.savefig(r"Data\Outside.png",dpi=300)
plt.show()
if __name__ == '__main__':
# 载入数据
result = load_data()
for area in ["Outside", "Hubei"]:
# 从原始数据中提取对应数据
x_data, y_data = data_abstract(result, area)
# 拟合并通过网格调参寻找最优参数
K, r, popt = fitting(logistic_increase_function, x_data, y_data)
# 模型预测
future, future_predict, diff= predict(logistic_increase_function, popt)
# 绘制图像
visualize(area, future, future_predict, x_data, y_data, diff)
参考文献
[1] Verhulst, P. E., Corresp. Math. Phys., 10, 113, 1838.
[2] 马尔萨斯.人口原理[M].北京:商务印书馆,1992.6.
[2] 宋波, 玄玉仁, 卢凤勇, et al. 浅评逻辑斯蒂方程[J]. 生态学杂志, 1986(03):59-64.
[3] 徐荣辉. 逻辑斯蒂方程及其应用[J]. 山西财经大学学报,2010,32(S2):311-312.
相关文章
以上是本篇的全部内容,欢迎关注我的知乎|简书|CSDN|微信公众号PurePlay , 会不定期分享研究与学习干货。


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









