







【尺度不变性】An Analysis of Scale Invariance in Object Detection – SNIP 论文解读
前言
本来想按照惯例来一个overview的,结果看到1篇十分不错而且详细的介绍,因此copy过来,自己在前面大体总结一下论文,细节不做赘述,引用文章讲得很详细,另外这篇paper引用十分详细,如果做detection可以从这篇文章去读更多不同类型的文章。
论文概述
卷积网络具有较好的平移不变性,但是对尺度不变性有较差的泛化能力,现在网络具有的一定尺度不变性、平移不变性往往是通过网络很大的capacity来“死记硬背”,小目标物体难有效的检测出来,主要原因有:1.物体尺度变化很大,CNN学习尺度不变性较难。2.通常用分类数据集进行预训练,而分类数据集物体目标通常相对较大,而检测数据集则较小。这样学习到的模型对小物体更难有效的泛化,存在很大的domain-shift。3.有的CNN的卷积核stride过大,小尺度中的小物体很容易被忽略,下图可以很好的体现这一问题。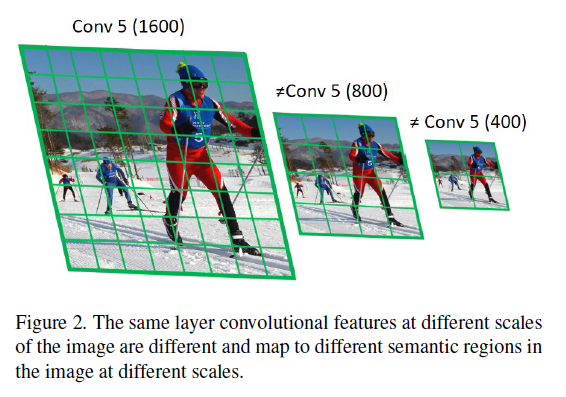
人们提出了一些解决小目标识别的问题,作者也分别进行分析,实验:
- 使用空洞卷积(dilated/atrous convolution)。减小stride的,增加feature map大小,但不会减小感受野的大小。这样做不影响检测大目标的性能
- 训练时将图像放大1.5到2倍,预测时,放大4倍
- 使用CNN中不同层的特征分别进行预测,浅层负责检测小目标,深层负责检测大目标
- 深浅层特征结合进行预测,使浅层特征结合深层的语义特征,如FPN。但当目标尺寸较小时,如25x25,特征金字塔生成的高层语义特征也可能对检测小目标帮助不大
作者的第一个实验证明了当训练图片的尺度与测试图片的尺度相差较大时性能会很差,越接近性能越好,具体可以看下图。另外作者比较了一个新的网络(CNN-S)来专门针对小目标检测(如小卷积核,减少stride)与在低分辨率的数据集上来fine-tuning高分辨率训练训练的检测器之间的性能,发现与其设计针对小物体的网络不如按到传统pre-trained模型在低分辨率的数据集进行微调(这个实验好像对文章主旨没什么用?),实验结果具体如下:
对于小目标检测困难的原因,最容易想到的解决方法就是放大图片,让小物体变大,从而不在卷积过程中丢失太多信息,作者也就此做了实验,发现提升并不明显,作者分析原因是放大图片小物体变大,中-大的物体也变大了,从而较难分类,所以整个分类器性能下降。因此,作者又设计了一组实验。使用1400分辨率进行训练,同时忽略原图中的中大目标(大于80像素)。然而,结果更差了。作者分析,这样做忽略了很多中-大目标(30%左右)的外形特征,pose之类的特征,特征减少对网络的学习能力产生了影响。作者又尝试训练具有尺度不变特性的检测器。随机采样图像,用不同分辨率的图像进行训练(Multi-Scale Training, MST),虽然包含了各类物体的各种尺度,物体特征较多,然而效果也不太好,原因是随机采样,会出现极大极小的样本,影响训练效果,又回到了最初的问题。因此作者得出结论:图像缩放后,使用尺度接近的目标来训练分类器很重要。
然后SNIP登场了!
作者提出,在训练时,既希望训练数据有尽可能多的外观变化以及多种不同的尺度来提高大/小物体的检测能力,又想训练的尺度与预训练的尺度较为接近从而提高检测器的性能同时减少domain-shift。因此作者提出了SNIP训练方法,使用MST(多尺度图像训练)方法时,只训练目标尺度在特定范围(与预训练的图像尺寸接近)的图像,在反向传播时,忽略其他过大过小的图像。实验表明,效果比其他训练方法都好。
网络图如下: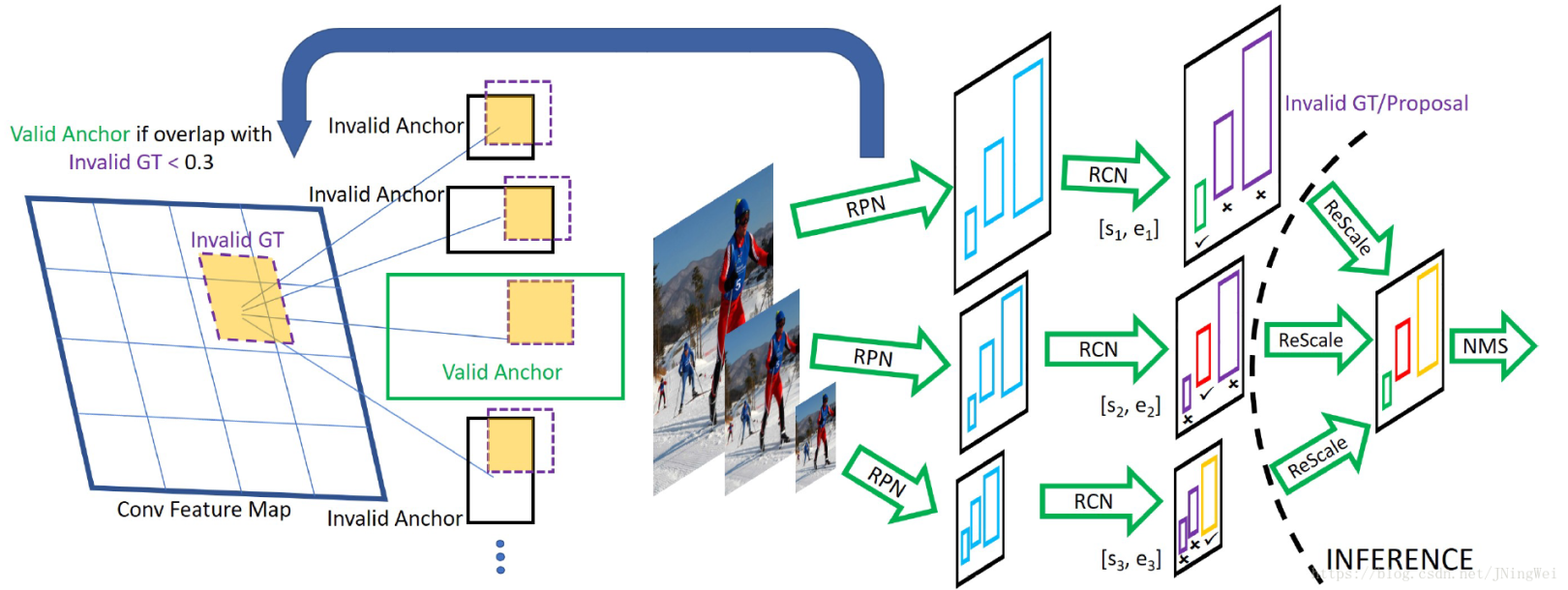
从上图可以发现:(转自:点击打开)
- 每个pipe-line的RPN只负责一个scale range的proposal生成。
- 对于大size的feature map,对应的RPN只负责预测被放大的小物体;对于小size的feature map,对应的RPN只负责预测被缩小的大物体;这样的设计保证了每个CNN分支在判别proposal是否为前景时,只需针对最易分类的中等range的proposal进行训练。
- 在Image Pyramid的基础上加入了 每层scale 的 proposal有效生成范围,发扬本scale的优势,回避其他scale的劣势,大大降低了前景分类任务的难度,从而“作弊式”地实现了Scale Invariance。
two-stage的检测器,包括RPN提取proposals,对proposals分类和bbox回归两个阶段,规则如下:
- 在分类阶段,训练时,不选择那些proposals和GT boxes在特定大小范围外的。
- RPN阶段,和无效GT boxes(大小不在范围内)的IoU大于0.3的anchor认为是无效的,忽略这些anchor。
- 在测试阶段,使用多个分辨率的图像进行检测;在分类阶段,去除那些回归后bboxes大小不在特定范围的检测结果。然后使用Soft-NMS将不同分辨率图像的检测结果合并。
训练图像采样方法
为了降低训练对GPU内存的要求,作者将原图进行裁剪,处理过程如下。
目标是在原图裁剪尽可能少的1000x1000的区域,并且这些裁剪区域包含所有的小目标
具体方法:
- 选择一幅图像
- 随机生成50个1000x1000的裁剪区域
- 选择包括目标最多的裁剪区域
- 如果所有裁剪区没有包含原图所有的目标,继续 (2)
- 由于很多目标在原图边界,再加上是随机裁剪,为了加快速度,裁剪时,保证裁剪区域的至少一个边在原图边界上。对于分辨率小于1000*1000的,或者不包含小目标的图像,不处理。
并且作者通过实验证明,裁剪原图不是提高精度的原因。
训练细节
对于预训练的分类器,通常训练图像大小为224x224。为了尽可能减少domain-shift,训练检测器时,我们期望proposals的大小与预训练时差不多。因此作者设定了如下的有效范围,注意的是COCO数据集中的图像大多在480x640左右。
左为训练图像分辨率,右为原图中有效尺寸的范围,使用了三种尺度进行训练:
1400x2000,[0,80]
800x1200,[40,160]
480x800,[120,∞]
假设原图短边尺寸为480,经过简单计算可知,有效尺寸映射到训练图像的分辨率上,边长为200左右,与预训练图像尺寸接近。
本文提出了一种训练方法:图像金字塔尺度归一化(Scale Normalization for Image Pyramids, SNIP),该方法使用图像金字塔来训练网络,并根据目标大小选择性的反向传播梯度,使得训练时的scale与原始图片的scale相近,从而提高准确率减少domain-shift。
引用文章1
以下内容来自:http://lowrank.science/SNIP/
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2268
2268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









